老冯课堂笔记MySQL数据库
数据的基本知识
1.什么是数据库
保存数据的仓库,它体现在我们电脑中,就是一个软件或者文件系统,然后把数据都保存在特殊的文件中。并且需要使用固定的语言(SQL语言/语句)去操作文件中的数据。数据库(DataBase,简称DB)
2.数据库管理系统
管理数据库的大型软件,英文名:DataBase Management System,简称DBMS
比如:MySQL
3.SQL
英文Structured Query Language,简称SQL
结构化查询语言,是操作关系型数据库的编程语言
定义了操作所有关系型数据库的统一标准
多于同一需求,每一个数据库操作的方式可能会存在一些不一样的地方,我们称之为“方言”
4.数据的存储方式
需求:开发一个学生选课系统,这个系统中还有学生信息,老师信息,课程信息。需要将关系和数据进行保存,保存到哪里合适呢?
(1)数据保存在内存
Student s = new Student("张三",18,"上海");
Teacher t = new Teacher("李老师",25,"上海");
Course c = new Course("音乐鉴赏",90);
new出来的对象存储在堆中,堆是内存中的一块小空间
优点:存储速度快
缺点:断电/程序退出,数据就丢失了
(2)使用I/O流基础将数据保存在硬盘的普通文件中
优点:永久保存
缺点:I/O流进行数据查找,新增,修改,删除比较麻烦。同时使用I/O流技术需要频繁调用系统资源和将系统资源归还给系统,这样操作效率比较低。
(3)数据保存在数据库
优点:永久保存,通过SQL语句能够比较方便的操作数据库。可以解决上面两种方式的缺点。
5.常见的数据库
Oracle(甲骨文公司)
MySQL(甲骨文公司)
DB2(IBM公司)
SQLServer(微软)
6.关系型数据库
在开发软件的时候,软件中的数据之间必然会有一定的关系存在。比如商品和客户之间的关系,一个客户可以购买多种商品,而一种商品可以被可多个客户购买。
需要把这些数据保存在数据库中,同时也要维护数据之间的关系,这时就可以直接使用上述的那些数据库(参考常见数据库)。而上述的所有数据库都属于关系型数据库。
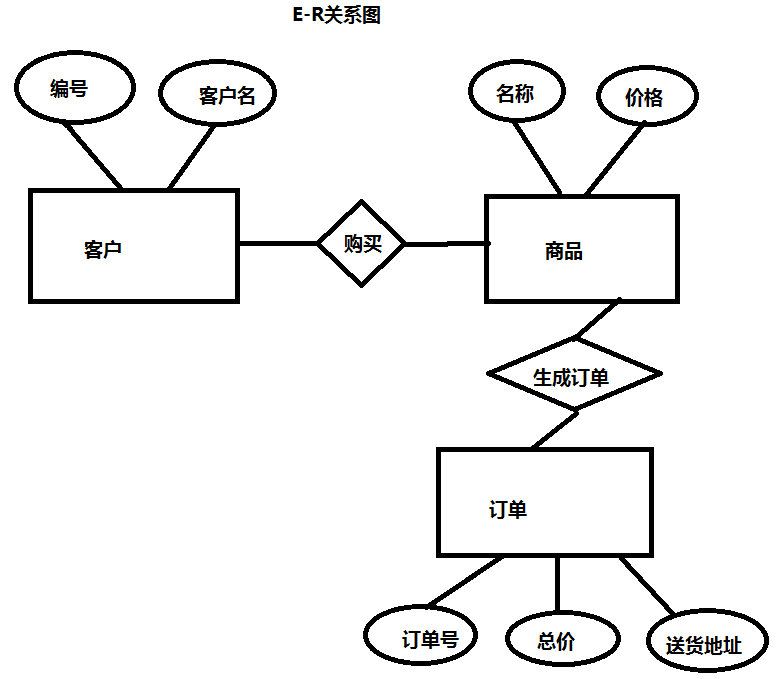
关系型数据:设计数据库的时候,需要使用E-R实体关系图来描述。E-R是两个单词的首字母,E表示Entity(实体),R表示Relationship(关系)。
实体:可以理解成我们Java程序中的一个对象,比如商品,客户都是一个实体对象,在E-R图中使用矩形(长方形)表示
关系:实体和实体之间的关系,在E-R图中使用菱形表示
属性:实体对象中是含有属性的,比如商品名,商品价格等。针对一个实体中的属性,我们称之为这个实体的数据,在E-R图中使用椭圆表示
需求:使用E-R图描述客户、商品、订单之间的关系。
7.数据的安装
你可以去下载小皮(比较方便) https://www.xp.cn/
去mysql官网下载
连接MySQL
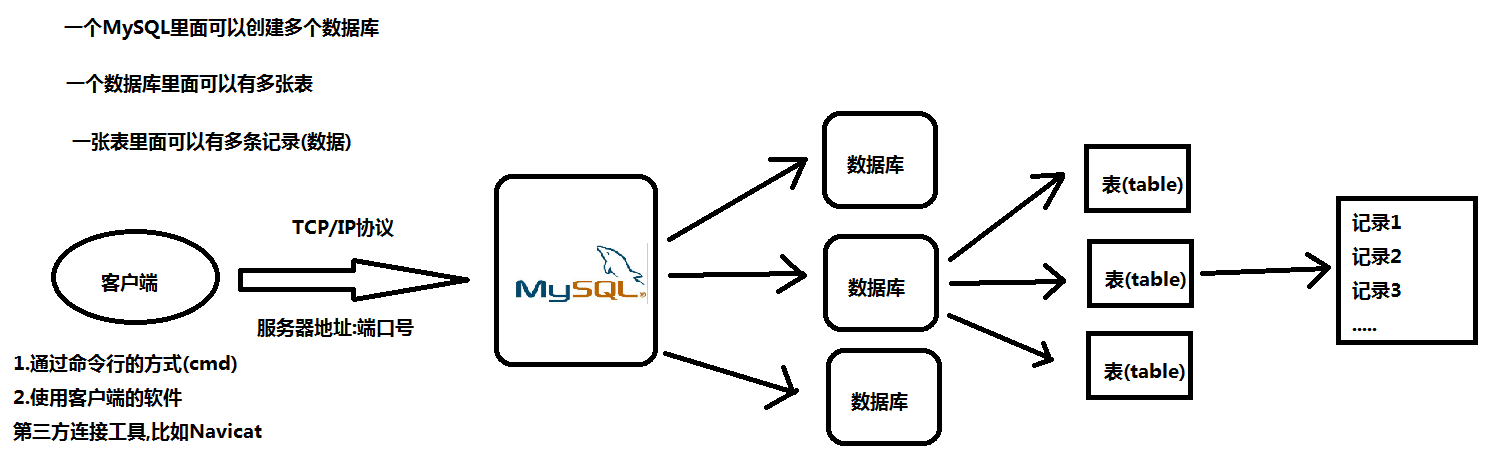
MySQL是一个需要账户名和密码登陆的数据库,默认账户名和密码都是root。
(1)登陆格式1: mysql -u用户名 -p密码
mysql -uroot -proot
mysql -u root -p
下一行输入密码
(2)登陆格式2
mysql [-h 连接的主机ip -P 端口号] -u用户名 -p密码
例如:
-- 一般情况下用于在本机去连接其他机器上的MySQL
mysql -h 127.0.0.1 -P 3306 -uroot -proot
如果连接的是本机,可以省略-h -P(主机IP和端口号)。
实体类与表的对应关系
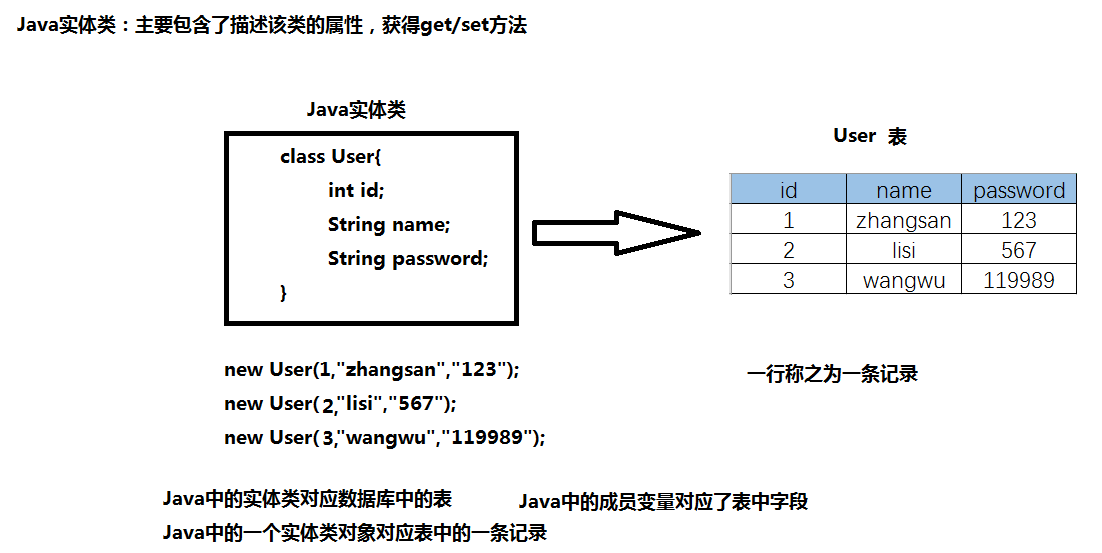
SQL语句的分类和语法
1.什么是SQL
英文Structured Query Language,简称SQL
结构化查询语言,是操作关系型数据库的编程语言
定义了操作所有关系型数据库的统一标准
多于同一需求,每一个数据库操作的方式可能会存在一些不一样的地方,我们称之为“方言”
2.SQL的作用
SQL语句主要是操作数据库,数据表,数据表中的数据记录的。
3.SQL语句的分类
SQL是用来存取关系型数据库的语言,具有定义、操作、控制和查询关系型数据库的四方面功能。所以针对四方面功能,我们将SQL进行了分类。
(1)DDL(Data Definition Language): 数据定义语言。用来定义数据库对象:数据库,表,列(字段)等。
涉及到的关键字:create,drop,alter,truncate,show等。
(2)DML(Data Manipulation Language): 数据库操作语言。在数据库表中更新,新增和删除记录。
涉及到的关键字:update(更新)、insert(插入),delete(删除)等,不包含查询。
(3)DCL(Data Control Language): 数据库控制语言。是用来设置或更改数据库用户或角色权限的语句
涉及到的关键字:grant(设置权限),revoke(撤销权限),begin transaction(开启事物)等。
(4)DQL(Data Query Language): 数据查询语言。用于数据表记录的查询。
涉及到的关键字:select(查询)等。
4.SQL同用语法
(1)SQL语句可以单行或者多行书写,以分号结尾
(2)可以使用空格和缩进来增强语句的可读性
(3)MySQL数据库的SQL预计不区分大小写,官方建议用户大写,但是我们实际习惯用小写
(4)关于SQL的注释
单行注释 --
多行注释 /* 和Java一样 */
#注释内容(这种注释方式是MySQL特有的单行注释)
数据库操作
1.创建数据库
(1)直接创建数据库
create database 数据库名;
(2)判断是否存在并创建数据库
create database if not exists 数据库名;
(3)创建数据库并指定字符集(编码表)
create database 数据库名 character set 字符集;
-- 说明:字符集就是编码表,比如在mysql在中的utf8,gbk
(4)具体操作:
- 直接创建数据库db1
create database db1;
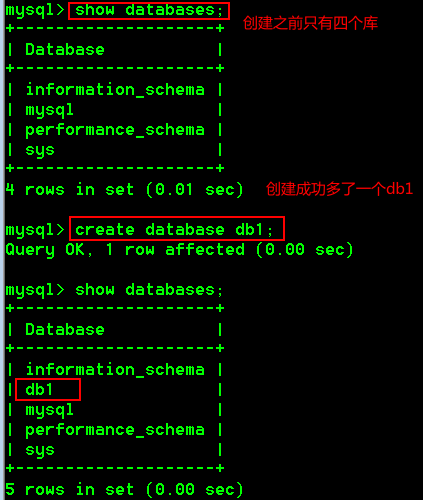
- 判断是否存在并创建数据db2
create database if not exists db2;
-- 这句话的意思是如果db2数据库存在就不创建了,不存在才创建。
- 创建数据库db3并指定字符集为gbk
create database db3 character set gbk;
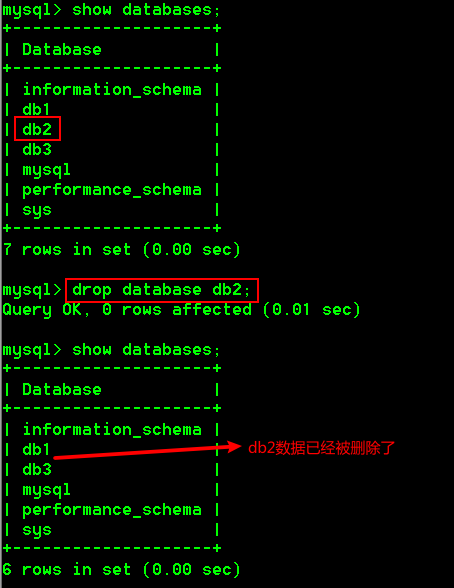
2.查看数据库
(1)查看所有数据
show databases;
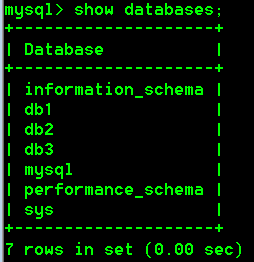
(2)查看指定的某个数据库的定义信息
show create database 数据库名;

3.修改和删除数据库
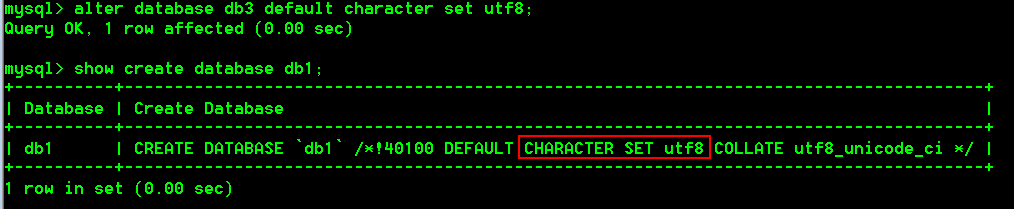
3.1 修改数据库字符集
alter database 数据库名 default character set 要修改的新的字符集;
-- alter表示修改
具体操作:
- 将db3数据的字符集由原来的gbk改成utf8
alter database db3 default character set utf8;
注意:如果修改数据库指定的编码表是utf8,记住就不能写成utf-8, mysql不认识utf-8
Java中的常用编码:UTF-8,GBK,GB2312,ISO-8859-1
对应mysql数据库中的编码:utf8,gbk,gb2312,latin1
3.2 删除数据库
drop database 数据库名;
-- drop 表示删除数据库或者表
具体操作
- 删除数据库db2
drop database db2;
4.使用数据库
(1)使用/切换数据库
use 数据库名;
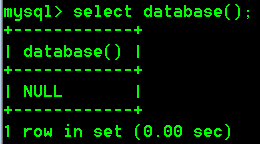
(2)查看正在使用的数据库
select database();
-- select 代表查询
(3)具体操作
- 查看正在使用的数据库
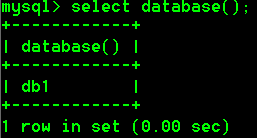
- 使用db1数据库

- 再次查看正在使用的数据库
注意:以后如果你想操作某个数据库的某张表的数据记录,一定要记得先通过use去使用该数据库,否则不能操作!!!
也就是先使用数据库才能够操作数据库中的表
数据库的表的操作
创建表的前提得使用某个数据库,比如:use db1(代表使用db1这个库,表也会创建在这个库下)
1.创建表
create table 表名(
字段名1 字段类型1,
字段名2 字段类型2,
...
);
-- create 表示创建
-- table 表示表
2.MySQL字段类型
整数
tinyint 微整型,很小的整数(占8个二进制),1个字节
samllint 小整型,小的整数(占16个二进制),2个字节
mediumint 中整型,中等长度的整数(占24个二进制),3个字节
int(integer) 整型,整数类型(占32个二进制),4个字节,默认长度为11
bigint 大整型,占64个二进制,8个字节
--------------------------------------------------------------------------
小数
float 单精度浮点数,占4个字节
double 双精度浮点数,占8个字节
decimal(m,n)
数值类型,m表示数值的长度,n表示小数的位数。它既可以表示整数,也可以表示小数
比如:decimal(10),decimal(10,2)
--------------------------------------------------------------------------
日期
time 只表示时间类型,比如:10:39:09
date 只表示日期类型,比如:2022-05-30
datetime
表示日期和时间类型,比如:2022-05-30 10:39:09
时间范围为:“1000-01-01 00:00:00”到“9999-12-31 23:59:59”
timestamp
表示日期和时间类型(时间戳)
时间范围为:“1970-01-01 00:00:01”到“2038-01-19 03:14:07”
--------------------------------------------------------------------------
字符串
char(m)
固定长度的字符串,无论使用几个字符都占满全部,M为0-255之间的整数
varchar(n)
可变长度的字符串,使用几个字符就占用几个,M为0-65535之间的整数
如果你能确定内容大小就用char,否则就用varchar
创建表的具体操作
创建student表,包含id,name,birthdat字段
create table student(
id int,
name varchar(20),
birthday date
);
3.查看表
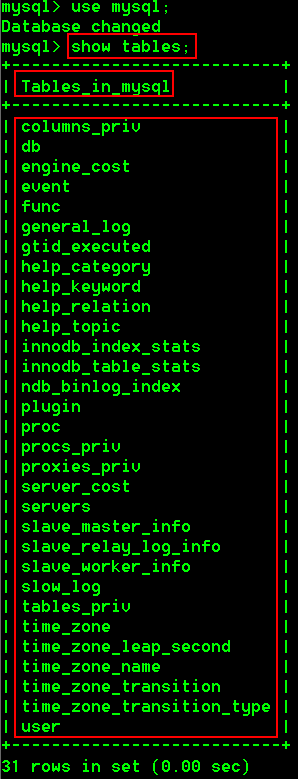
1.查看某个数据库中的所有表
show tables;
2.查看表结构
desc 表名;
3.查看创建表的SQL语句
show create table 表名;
具体操作:
- 查看mysql这个库中的所有表
show tables
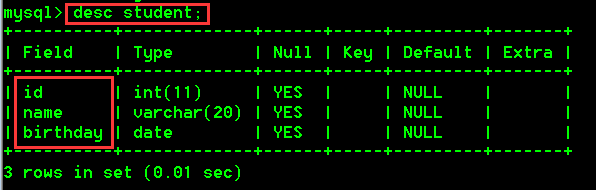
- 查看student表的结构
desc student;
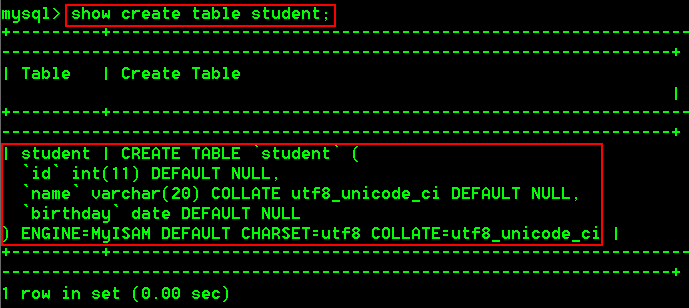
- 查看student的创建表的SQL语句
show create table student;
4.删除表
快速创建一个表结构相同的表
create table 新表的名称 like 被复制的表的名称;
具体操作:
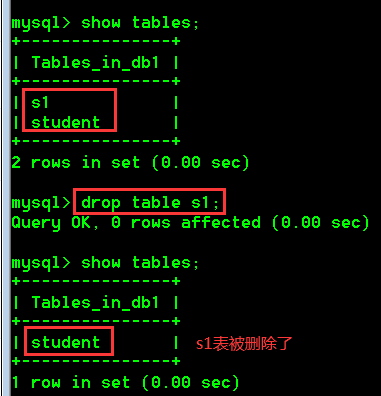
- 创建s1表,s1表结构和student表结构相同
create table s1 like student;
删除表
1.直接删除表
drop table 表名;
2.判断表是否存在并删除表
drop table if exists 表名;
-- 如果表存在就删除,不存在就不管它
具体操作:
- 直接删除s1表
drop table s1;
- 判断表是否存在并删除s1表
drop table if exists s1;

5.修改表结构
1.给表添加一个字段
alter table 表名 add 字段名/列名 类型;
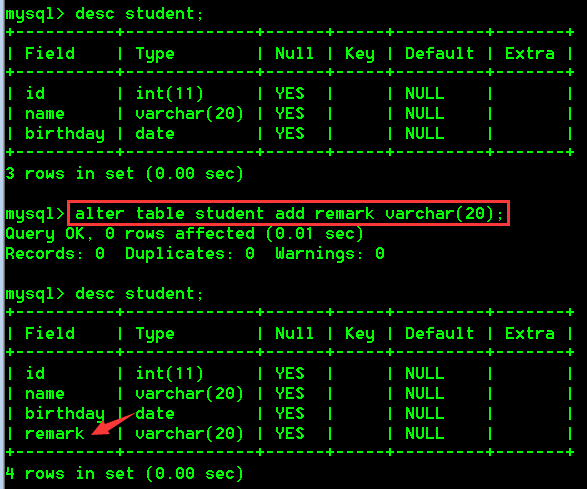
具体操作:
- 为学生表添加一个新的字段remark,类型为varchar(;20)
alter table student add remark varchar(20);
2.修改字段类型
alter table 表名 modify 字段名 新的类型;
具体操作:
- 将student表中的remark字段的类型由原来的varchar(20)改为varchar(100)
alter table student modify remark varchar(100);
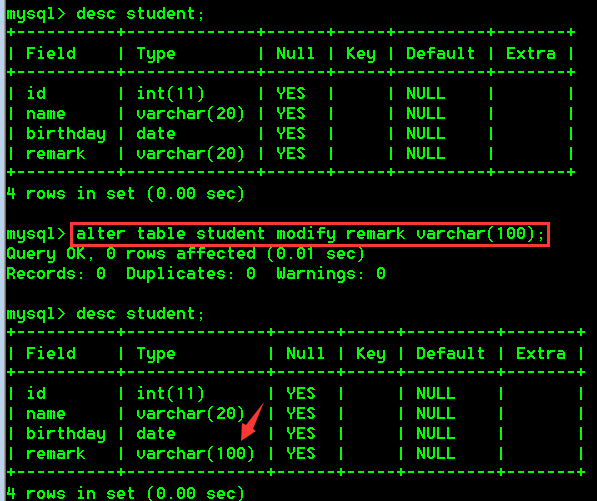
3.修改字段名
alter table 表名 change 旧的字段名 新的字段名 类型;
具体操作:
- 将student表中的remark字段名改为info,类型为varchar(30)
alter table student change remark info varchar(30);
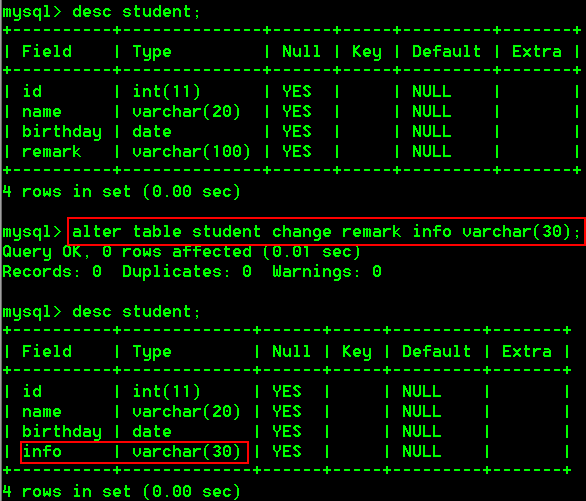
4.删除字段
alter table 表名 drop 字段名;
具体操作:
- 删除student表中的字段info
alter table student drop info;
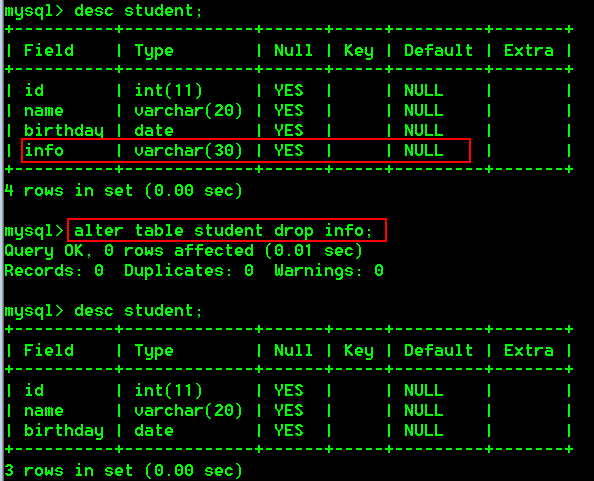
5.修改表名
rename table 旧表名 to 新表名;
具体操作:
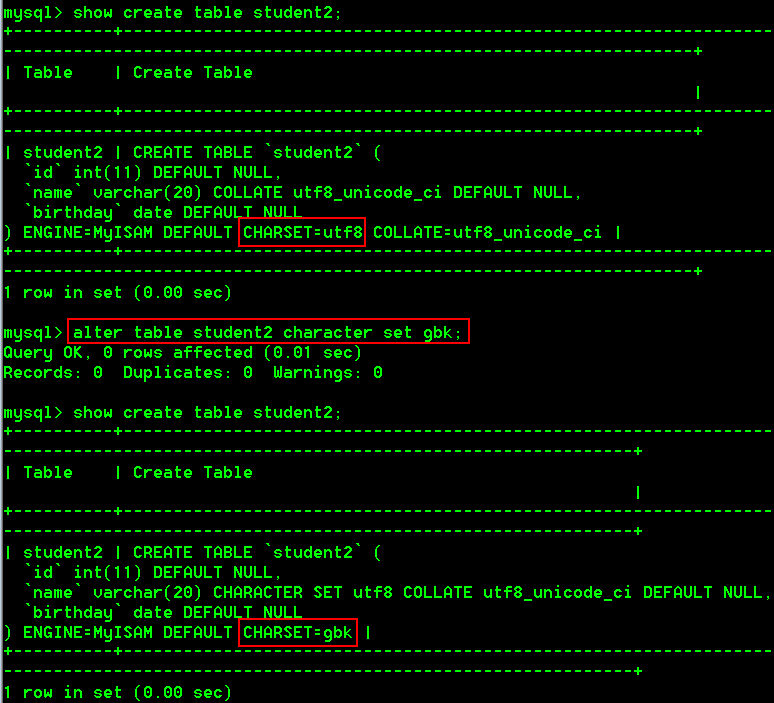
- 将学生表student改名为student2
rename table student to student2;
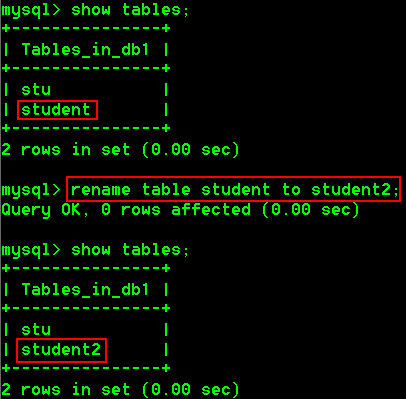
6.修改表的字符集编码
alter table 表名 character set 字符集编码;
具体操作:
- 将student2这张表的字符集编码修改为gbk
alter table student2 character set gbk;
给表插入记录的操作
创建student表,包含id,name,age,sex,address字段
create table student(
id int,
name varchar(20),
age int,
sex char(2),
address varchar(50)
);
1.给全部字段插入数据
- 所有字段名都写出来
insert into 表名(字段名1,字段名2,...) values(字段值1,字段值2,...);
- 不写字段名
insert into 表名 values(字段值1,字段值2,...);
说明:给所有字段插入数据,要不你就把所有字段名都写出来,要一个字段都不要写。
2.给部分字段插入数据
insert into 表名(字段名1,字段名2,...) values(字段值1,字段值2,...);
说明:给部分字段插入数据的时候,字段名一定要写出来,但是不是全部都写,你想给哪些字段插入数据就写哪些字段。
3.批量插入数据
insert into 表名 values(字段值1,字段值2,...),(字段值1,字段值2,...),(字段值1,字段值2,...);
-- 批量插入是给所有字段插入
具体操作:
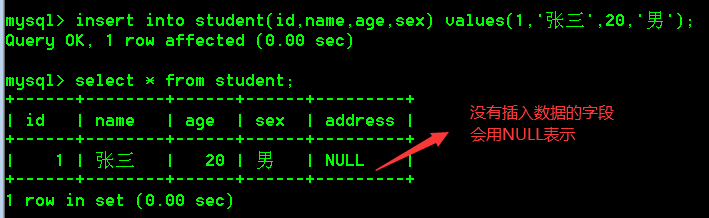
- 给部分字段插入数据,往student表中id,name,age,sex的字段插入数据
insert into student(id,name,age,sex) values(1,'张三',20,'男');
-
给全部字段插入数据
- 所有字段名都写出来
insert into student(id,name,age,sex,address) values(2,'李四',23,'女','上海');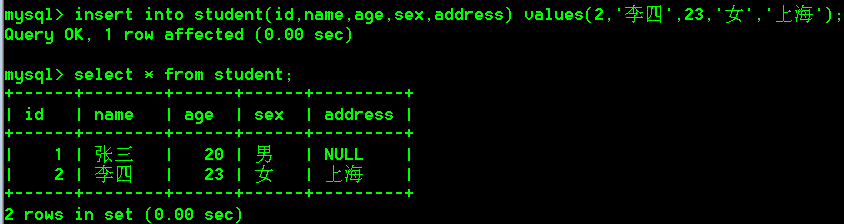
- 不写字段名
insert into student values(3,'王五',18,'男','北京');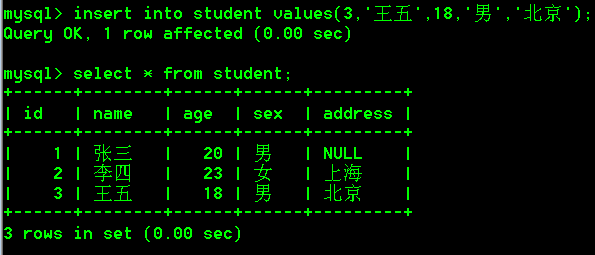
-
批量插入数据
insert into student values(4,'马六',18,'男','北京'),(5,'田七',20,'男','杭州');
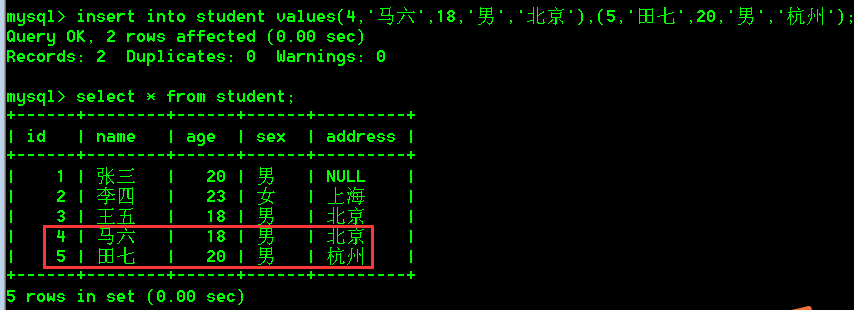
4.注意
- 值的数据类型,与字段被定义的数据类型要匹配,并且值的长度,不能超过定义的字段的长度。
- 值与字段一一对应,有多少个字段,就需要写多少个值,如果某一个字段没有值,可以使用null。表示插入空。
- 插入字符类型的数据(varchar,char),需要用英文的单引号包裹起来,在MySQL中,使用单引号表示字符串
- date时间类型的数据也得用英文的单引号包裹起来,比如:'2022-05-30'
更新(修改)表中的记录的操作
1.不带条件修改数据
update 表名 set 字段名1=新的值,字段名2=新的值,...;
2.带条件的修改数据
update 表名 set 字段名1=新的值,字段名2=新的值,... where 条件;
3.关键字说明
update:表示修改记录(数据)
set:要改哪个字段的记录
where:设置条件
4.具体操作
- 不带条件修改数据,如果不带条件,那么指定的字段下的所有条数的记录值都会被改变
update student set sex='女';

- 带条件修改数据,将id为2的学生的性别改为男
update student set sex='男' where id=2;
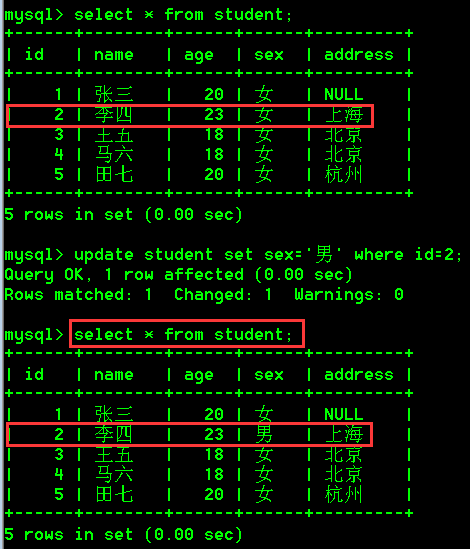
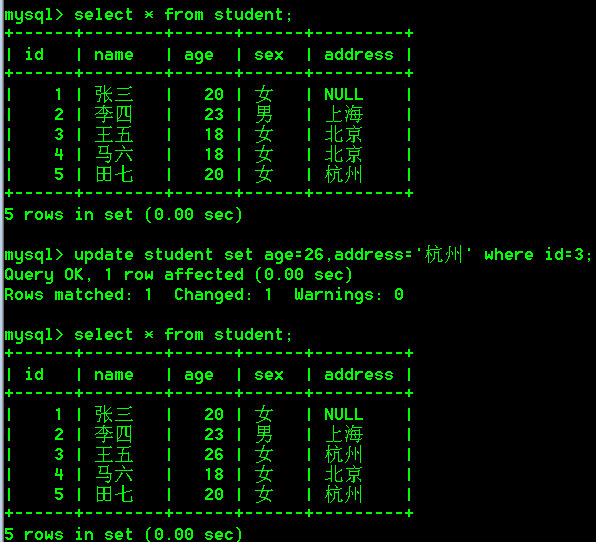
- 一次性修改多个列,把id为3的学生,年龄改为26岁,address改为杭州
update student set age=26,address='杭州' where id=3;
删除(delete)表中的记录的操作
1.不带条件删除数据
delete from 表名;
2.带条件删除数据
delete from 表名 where 条件;
3.truncate删除表记录,属于DDL语句
truncate table 表名;
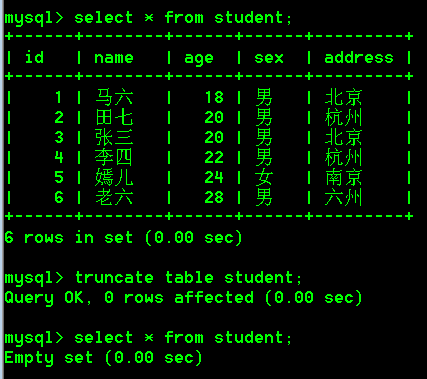
truncate与delete的区别
- delete是将表中的数据一条一条删除
- truncate是将整个表摧毁,重新创建一个新的表,新的表结构和原来被摧毁的表结构一模一样
4.具体操作:
- 带条件删除数据,删除student表中id为3的记录
delete from student where id = 3;
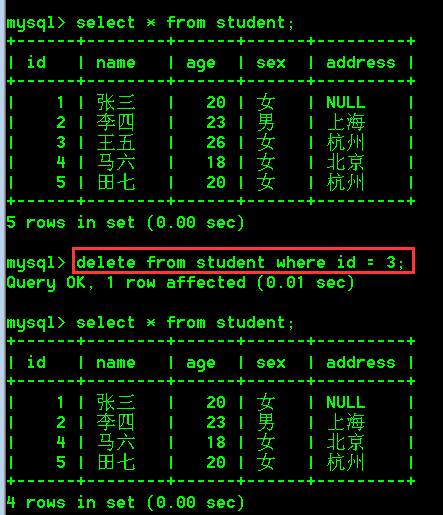
- 删除带条件的数据,删除student表中id为1和2的记录
delete from student where id in(1,2);
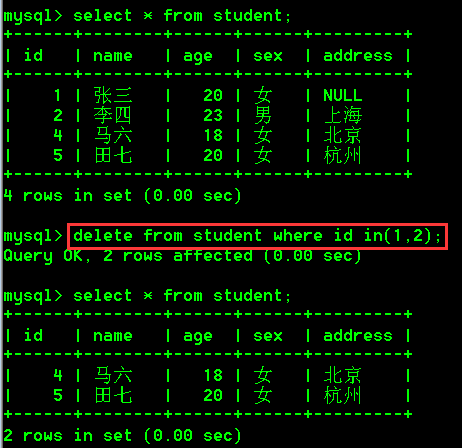
- 不带条件删除数据,不带条件会把表中所有的数据都删除掉
delete from student;
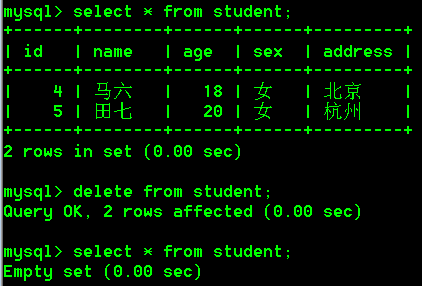
没有条件的简单查询操作(select)
1.查询表中所有的数据
1.查询所有字段的数据
-- select表示查询
select 字段名1,字段名2,...(所有字段名) from 表名;
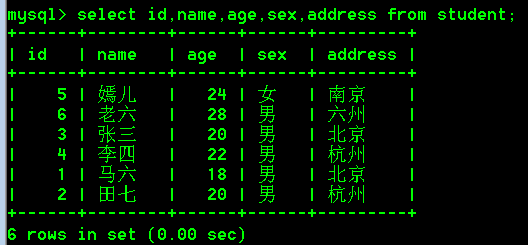
具体操作:
select id,name,age,sex,address from student;
2.使用*号表示所有列
select * from 表名;
具体操作:
select * from student;
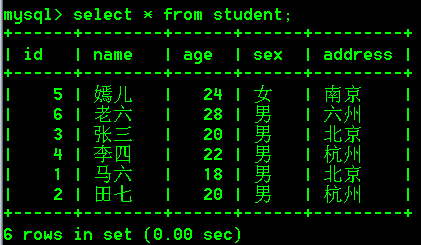
2.查询表中指定字段的数据
查询指定字段的数据,多个字段之间用英文逗号隔开
select 字段名1,字段名2 from 表名;
具体操作:
- 查询student表中name和age字段的数据
select name,age from student;
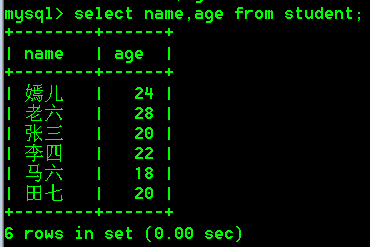
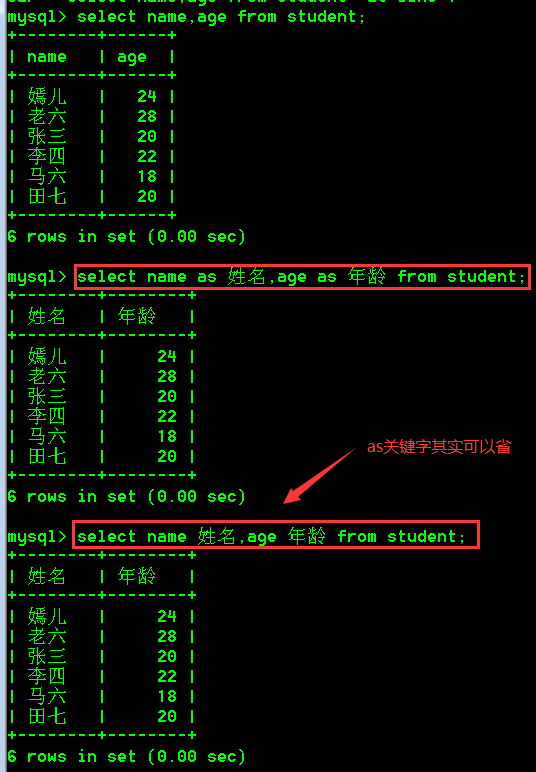
3.别名查询
1.查询时给字段、表指定别名需要使用as关键字
2.使用别名的好处是方便观看和处理查询到的数据
3.格式为:
select 字段名1 as 别名,字段名2 as 别名,字段名3 as 别名,... from 表名;
select 字段名1 as 别名,字段名2 as 别名,字段名3 as 别名,... from 表名 as 表别名;
4.在使用别名的时候,as关键字其实可以省略
5.具体操作:
- 查询student表中name和age列,name列的别名为"姓名",age列的别名为"年龄"。
select name as 姓名,age as 年龄 from student;
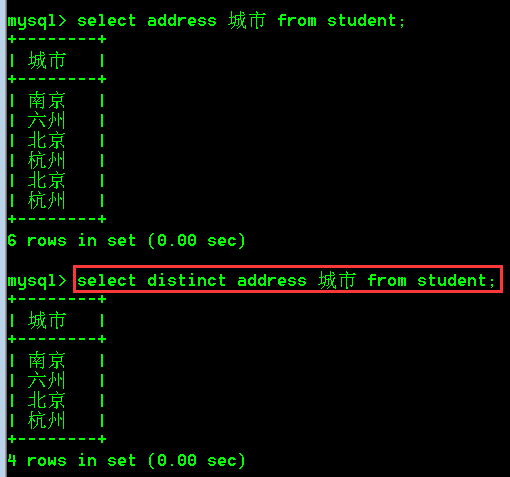
4.去除重复值
1.查询指定列并且结果不能出现重复值
select distinct 字段名,字段名,... from 表名;
2.具体操作:
- 查询student表中address列并且结果不能出现重复的address
select distinct address 城市 from student;
5.查询结果参与运算
1.某列数据和固定值进行运算
select 列名1 from 表名;
select 列名1 + 固定值 from 表名;
2.某列数据和其他列数据进行运算
select 列名1 + 列名2 from 表名;
注意:参与运算的必须是数值类型
3.需求:
- 添加数学,英语成绩列,给每条记录添加对应的数学和英语成绩
- 查询的时候将数学和英语的成绩相加
4.实现:
- 修改student表结构,添加数学和英语成绩列
alter table student add math int;
alter table student add english int;
- 给每条记录添加对应的数学和英语成绩
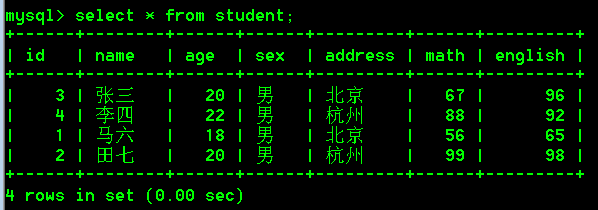
- 查询每行数据中math + english的和
select math + english from student;
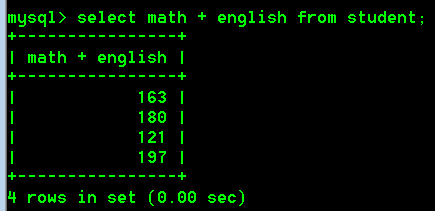
结果确实将每条记录的math和english相加了,但是效果不好看
- 查询每行数据中math + english的和,使用别名“总成绩”
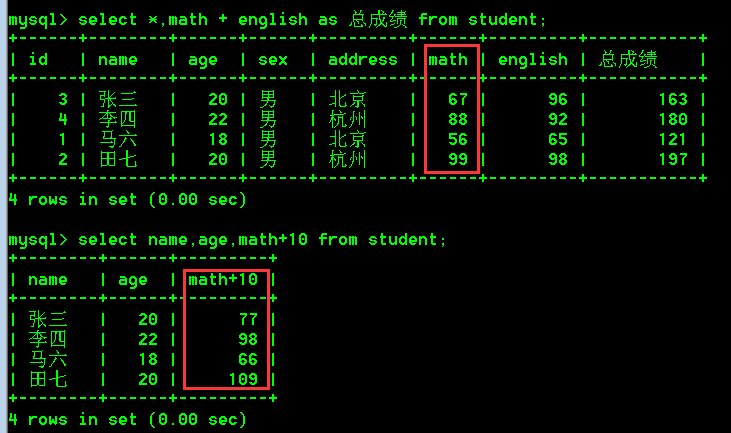
select math + english as 总成绩 from student;
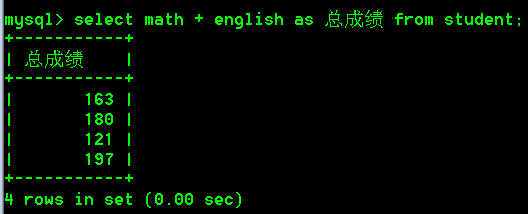
- 查询所有列与每行数据中math + english的和,使用别名“总成绩”(列名值 + 列名值)
select *,math + english as 总成绩 from student;
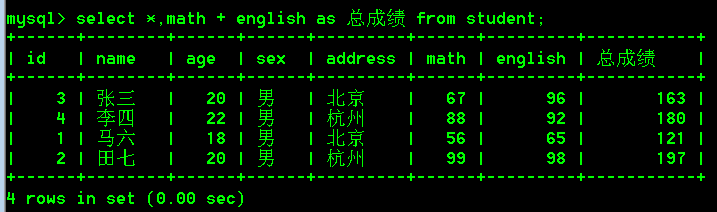
- 查询姓名,年龄,将每个人的数学成绩增加10分(列名值 + 固定值)
select name,age,math+10 from student;
蠕虫复制
什么是蠕虫复制:在已有的数据基础之上,将原来的数据进行复制,插入到对应的表中,语法格式:
insert into 表名1 select * from 表名2;
-- 作用:将表名2中的数据复制到表名1中
具体操作:
- 复制student表的表结构,生成一张名为student2的表,但是没有数据
create table student2 like student;
- 将student表中的数据添加到student2表中
insert into student2 select * from student;
注意:如果只想复制student表中name,age字段数据到student2表中使用如下格式
insert into student2(name,age) select name,age from student;
条件查询操作
前面我们的查询都是将所有数据都查询出来,但是有时候我们只想获取到满足条件的数据,语法格式:
select 字段名... from 表名 where 条件;
流程:取出表中的每条数据,满足条件的记录就返回,不满足条件的记录就不返回。
1.准备数据
CREATE TABLE student3 (
id int,
name varchar(20),
age int,
sex varchar(5),
address varchar(100),
math int,
english int
);
INSERT INTO
student3(id,NAME,age,sex,address,math,english) VALUES
(1,'马 云',55,'男','杭州',66,78),(2,'马化腾',45,'女','深圳',98,87),
(3,'马景涛',55,'男','香 港',56,77),(4,'柳岩',20,'女','湖南',76,65),
(5,'柳青',20,'男','湖南',86,NULL),(6,'刘德 华',57,'男','香港',99,99),
(7,'马德',22,'女','香港',99,99),(8,'德玛西亚',18,'男','南 京',56,65);
2.比较运算符
> 大于
< 小于
<= 小于等于
>= 大于等于
= 等于
<>、!= 不等于
具体操作:
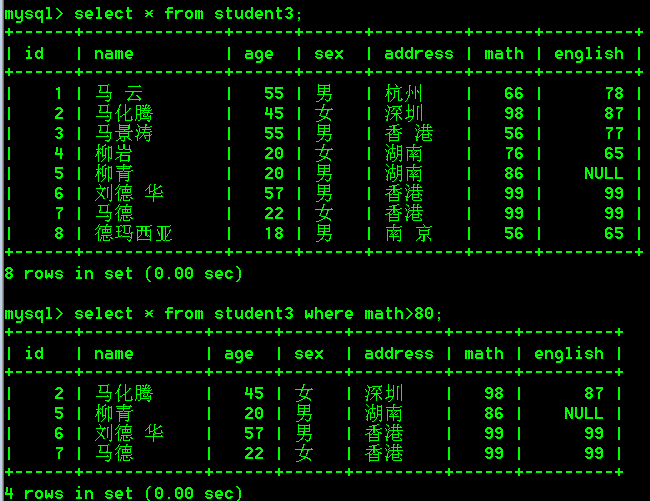
- 查询math分数大于80分的学生
select * from student3 where math>80;
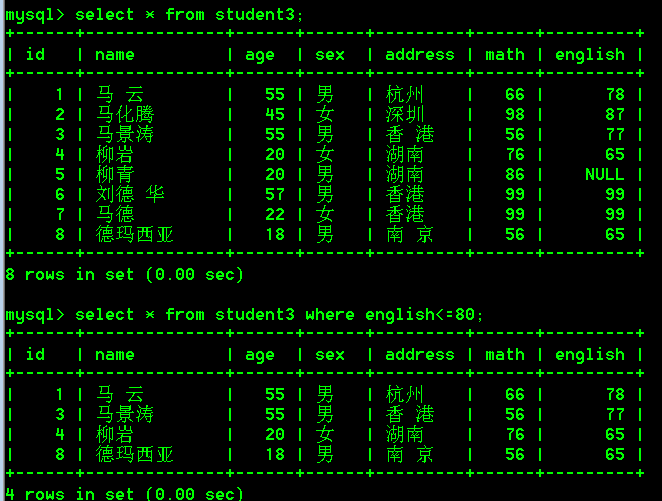
- 查询english分数小于或等于80分的学生
select * from student3 where english<=80;
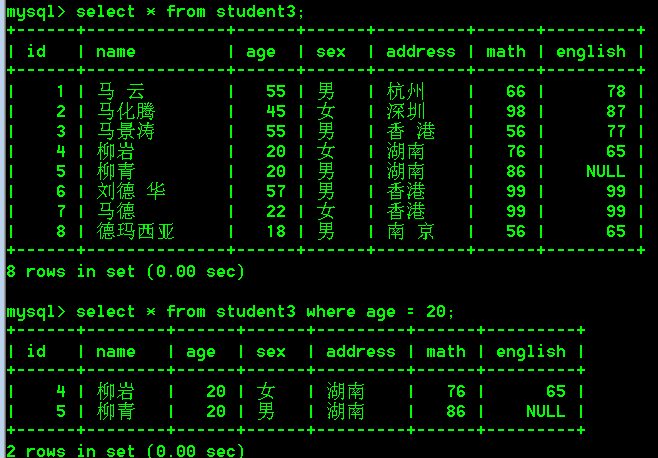
- 查询age等于20岁的学生
select * from student3 where age = 20;
- 查询age不等于20岁的学生
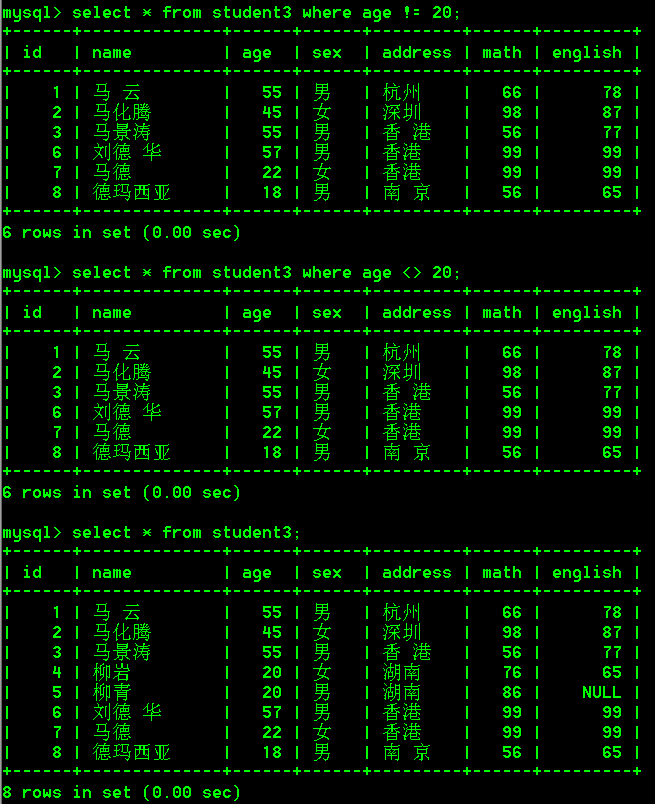
select * from student3 where age != 20;
select * from student3 where age <> 20;
3.逻辑运算符
and(&&)多个条件同时满足
or(||)多个条件有一个满足即为满足
not(!)取反,不满足取反为满足,满足取反为不满足
具体操作:
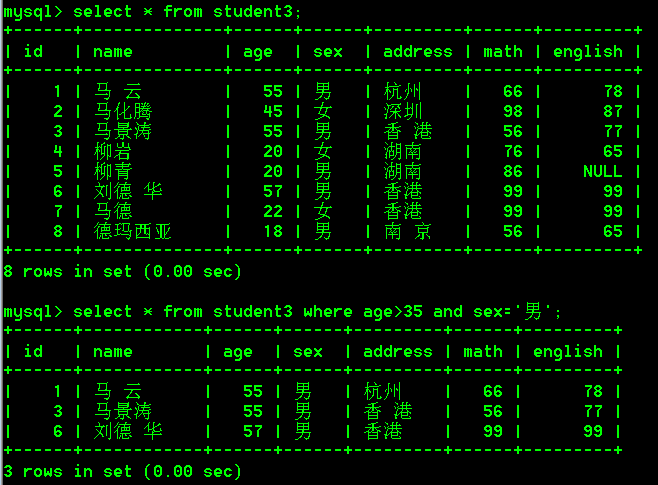
- 查询age大于35且性别为男的学生(两个条件同时满足)
select * from student3 where age>35 and sex='男';
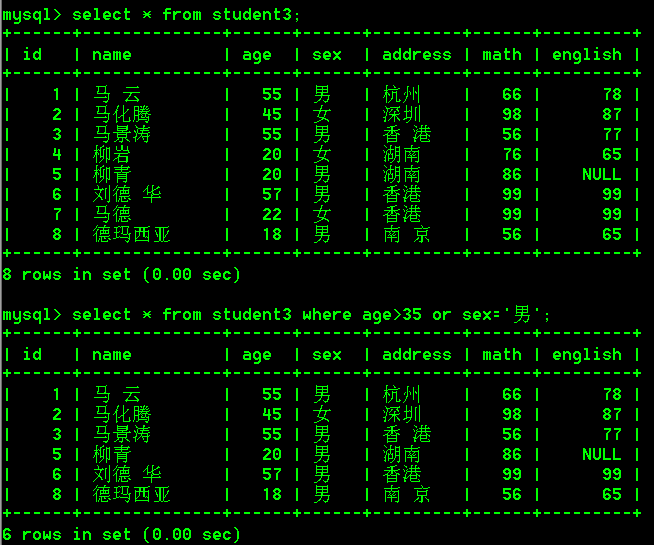
- 查询age大于35或性别为男的学生(两个条件满足其中一个即可)
select * from student3 where age>35 or sex='男';
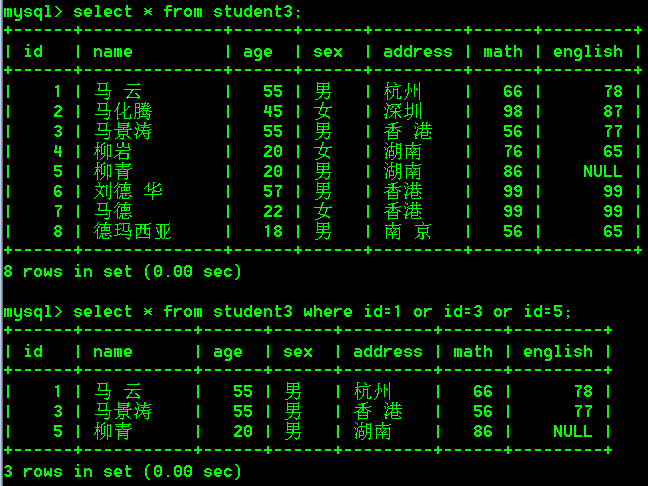
- 查询id是1或者3或者5的学生
select * from student3 where id=1 or id=3 or id=5;
in关键字语法格式:
select * from 表名 where 字段 in(值1,值2,值3,...);
in里面的每个数据都会作为一次条件,只要满足条件的就会显示,in(判断某个字段的值在...里面)
具体操作:
- 查询id是1或者3或者5的学生
select * from student3 where id in(1,3,5);
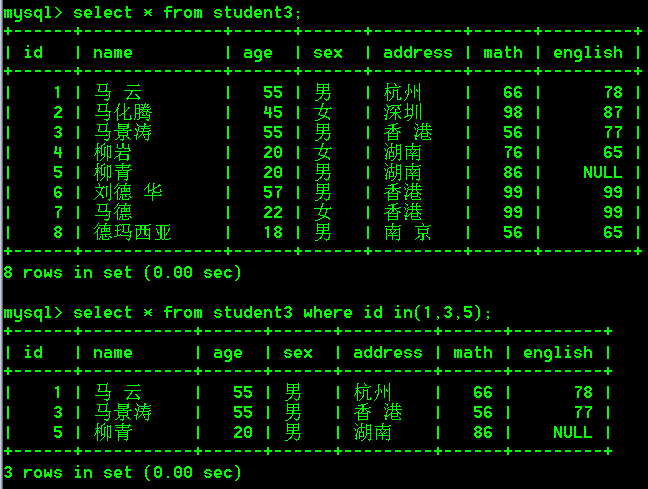
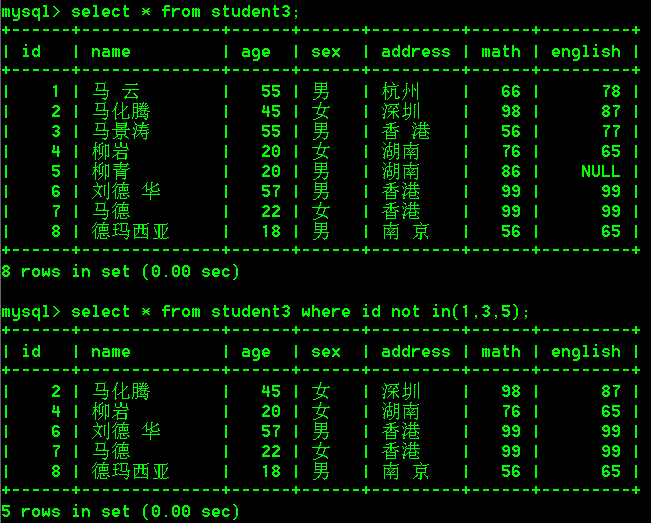
- 查询id不是1或者3或者5的学生
select * from student3 where id not in(1,3,5);
3.范围
字段 between 值1 and 值2 --表示从值1到值2的范围,包头又包尾
比如:age between 80 and 100相当于age>=80 && age<=100
具体操作:
- 查询english成绩大于等于75,且小于等于90的学生
select * from student3 where english between 75 and 90;
select * from student3 where english >= 75 and english <= 90;
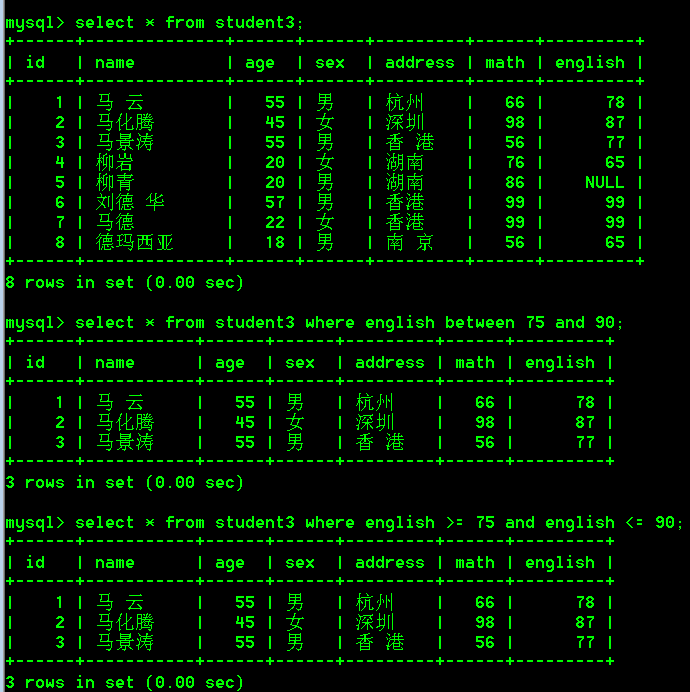
4.模糊查询
like表示模糊查询
select * from 表名 where 字段名 like '通配符字符串';
满足通配符字符串规则的数据就会显示出来,所谓的通配符字符串就是含有通配符的字符串
MySQL的通配符有两个:
%,表示零个,一个或多个字符(任意多个字符)
_,表示一个字符
例如:
name like '张%'; 匹配所有名字姓张的人
name like '%张%'; 匹配名字中含有张的人
name like '张_'; 匹配名字姓张且只有两个字的人
name like '_张_'; 匹配名字只有三个字且中间那个字为张的人
具体操作:
- 查询姓马的学生
select * from student3 where name like '马%';
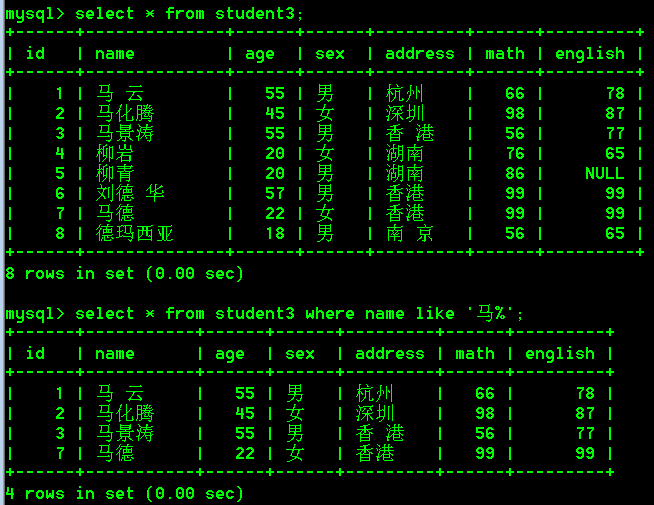
- 查询姓名中包含'德'字的学生
select * from student3 where name like '%德%';
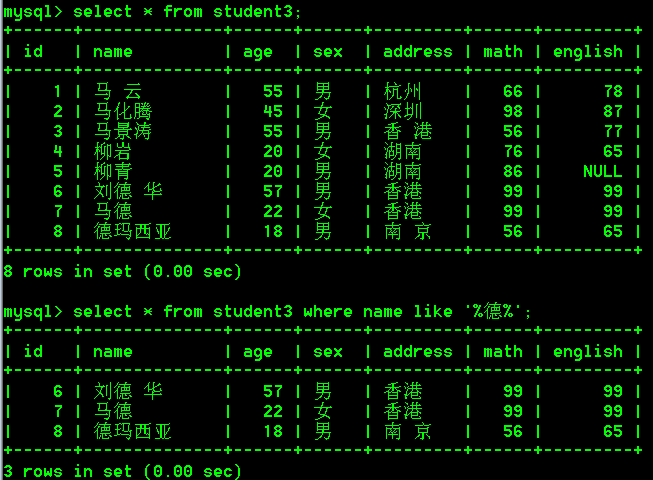
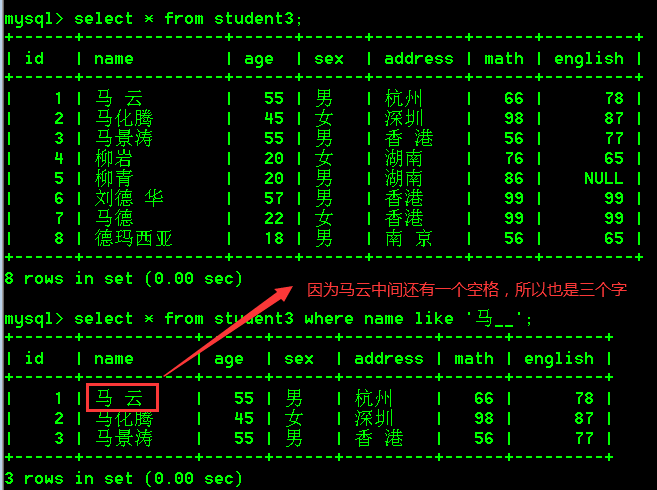
- 查询姓马,且姓名只有三个字的学生
select * from student3 where name like '马__';
查询操作之排序
通过order by子句,可以将查询出来的结果进行排序(排序只是查询结果的显示方式,并不会影响到数据库中数据的实际顺序)
select 字段 from 表名 order by 要排序的字段 [asc|desc]
-- asc代表升序排序,由小到大(默认)
-- desc代表降序排序,由大到小
1.单列排序
单列排序就是使用一个字段排序
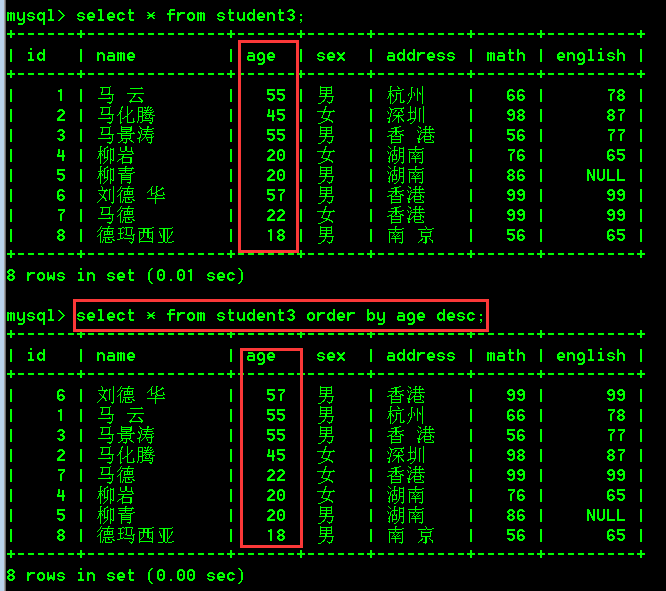
具体操作:
- 查询student3的所有数据,根据年龄降序排序
select * from student3 order by age desc;
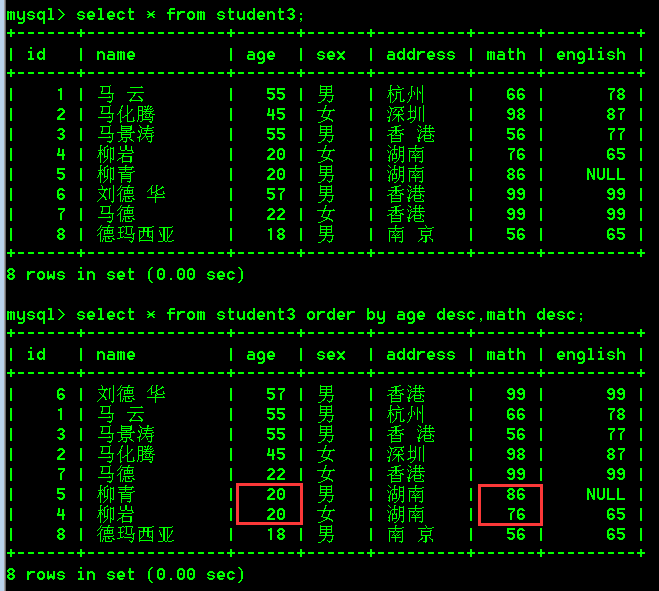
2.组合排序
组合排序就是先按照第一个字段进行排序,如果第一个字段相同,才按照第二个字段进行排序,以此类推。比如上面的例子中,年龄是有相同的,当年龄相同再根据math进行排序。
具体操作:
- 查询student3表中所有数据,在年龄降序排序的基础上,如果年龄相同再根据数学成绩降序排序
select * from student3 order by age desc,math desc;
查询操作之聚合函数
之前我们做的查询都是横向查询。它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。另外聚合函数会忽略空值,对于NULL不作统计。
五大聚合函数:
- count:在根据指定的列统计的时候,如果这一列中有NULL的行,该行不会被统计在其中。按照列去统计有多少行数据。(统计有多少行)
- sum:计算指定列的数值和,如果不是数值类型,那么计算结果为0。
- max:计算指定列的最大数值。
- min:计算指定列的最小数值。
- avg:计算指定列的数值的平均值。
聚合函数写在SQL语句select后面,也就是字段名的地方
select 字段名... from 表名;
select 聚合函数(字段) from 表名;
具体操作:
- 查询student3表中的学生的总数
select count(english) from student3;
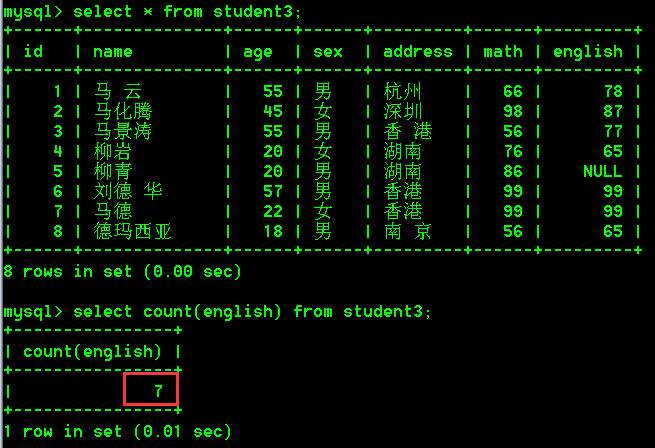
我们发现对于NULL的记录并不会进行统计,所以导致结果为7而不是8。
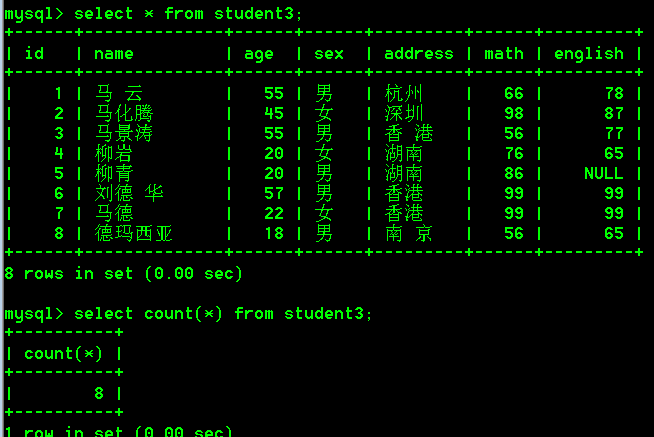
统计数量常用写法:
select count(*) from student3;
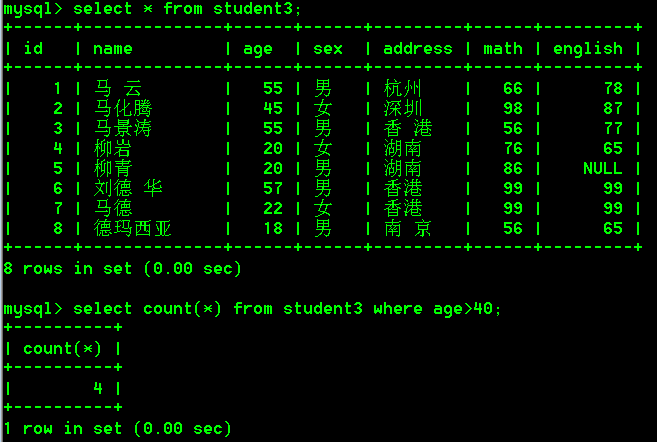
- 查询student3表中年龄大于40的人的总数
select count(*) from student3 where age>40;
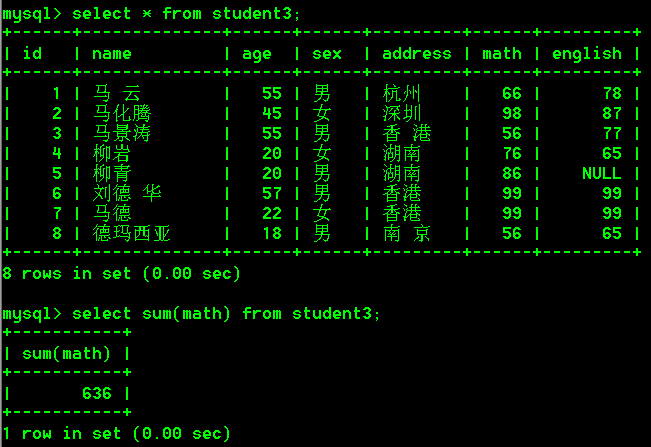
- 查询student3表中数学成绩的总分
select sum(math) from student3;
- 统计student3表中所有数学与英语成绩的总和(所有数学成绩+所有英语成绩)
方式一:
select sum(math) + sum(english) from student3;
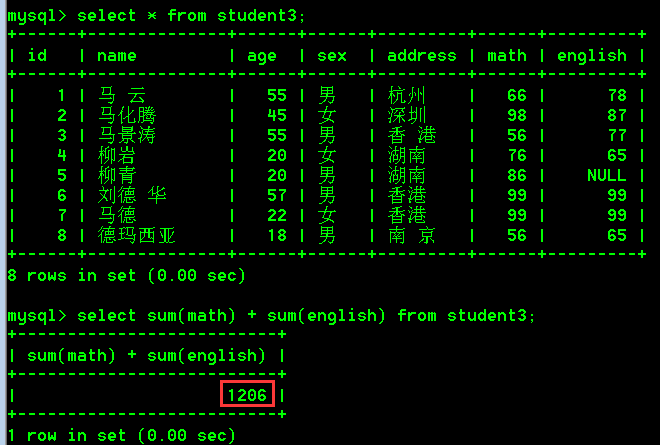
方式二:
select sum(math+english) from student3;
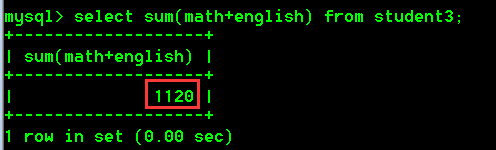
我们发现按照方式二的做法,结果是有问题的,结果少了86。
产生问题的原因:
上述写法会先将每一行的数学分数值和英语分数值进行相加,然后再把每一行的数学分数值和英语分数值加出来的结果进行求和。但是这样些会出现一个问题,因为在mysql中NULL值和任何值相加都为NULL,导致在进行柳青的数学和英语相加的时候结果变为了NULL。而最后sum求和的时候,就把柳青的数学和英语相加的结果值NULL给排除了,因此缺少了柳青86分成绩。
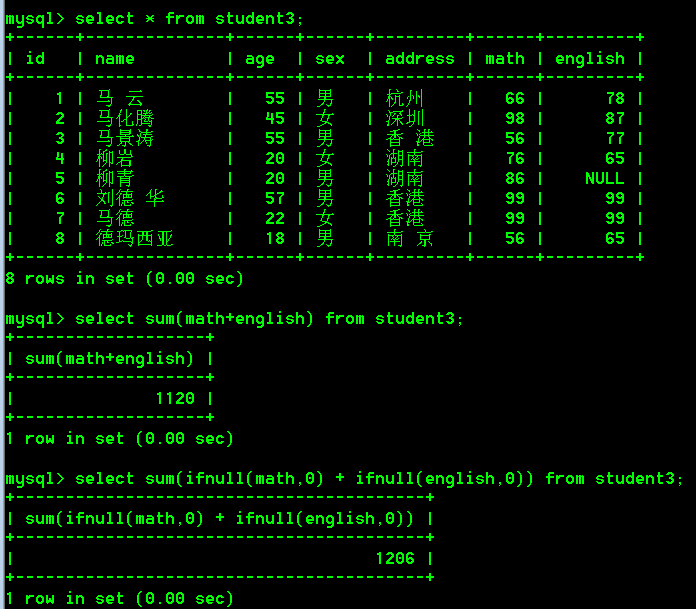
解决方案:
在SQL语句中我们可以使用数据库提供的函数ifnull(列名,默认值)来解决上述问题。ifnull(列名,默认值)函数表示判断该列名是否为null,如果为null,返回默认值,如果不为null,返回实际值。
例子:
english的值是null
ifnull(english,2),english列的值为null,所以返回2
english的值是3
ifnull(english,2),english列的值不为null,返回实际值3
select sum(ifnull(math,0) + ifnull(english,0)) from student3;
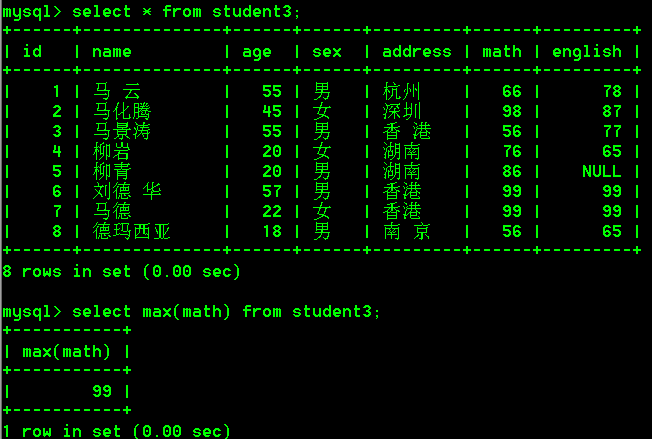
- 查询student3表中数学成绩最高分
select max(math) from student3;
- 查询student3表中数学成绩最低分
select min(math) from student3;
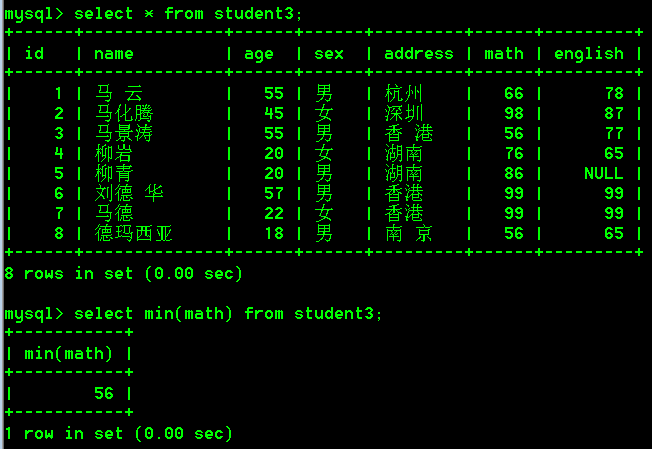
- 查询student3表中数学成绩的平均分
select avg(math) from student3;
查询操作之分组查询
1.官方定义:分组,按照某一列或者某几列,把相同的数据,进行合并输出
2.完整写法:select ... from ... group by 列名,列名...
按照某一列进行分组
目的:仍然是统计使用
3.分组其实就是按照列进行分类,然后可以对分类完的数据使用聚合函数进行计算
4.准备数据
create table orders(
id int,
product varchar(20),
price float
);
insert into orders values(1,'纸巾',16);
insert into orders values(2,'纸巾',16);
insert into orders values(3,'红牛',5);
insert into orders values(4,'洗衣粉',60);
insert into orders values(5,'苹果',8);
insert into orders values(6,'洗衣粉',60);
5.具体操作:
- 查询购买的每种商品的名称以及其总价
分析查询的内容:product,sum(price),按照商品名称进行分组
按照商品分组,应该分为如下好几组数据:
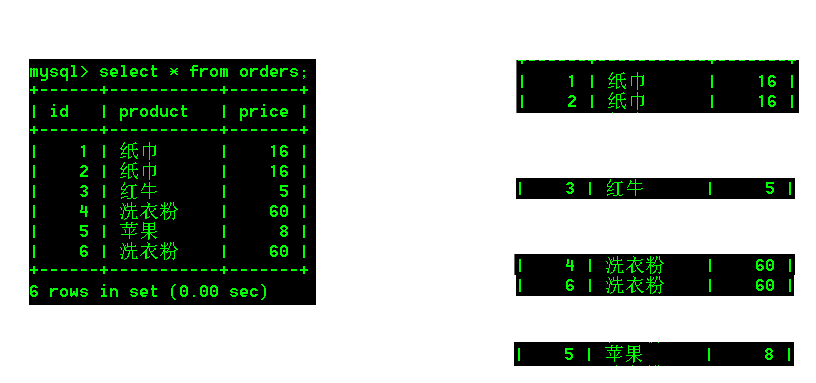
分组之后查询的结果应该是:
纸巾 32
红牛 5
洗衣粉 120
苹果 8
select product,sum(price) from orders group by product;
-- 先按照product进行分组,分组完成之后再给每一组的数据进行求和(组内求和)
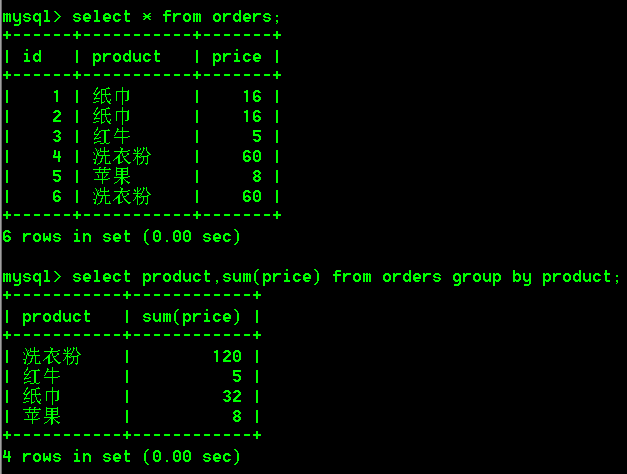
- 根据多个字段分组
首先将id为2的纸巾的价格由16改为了20
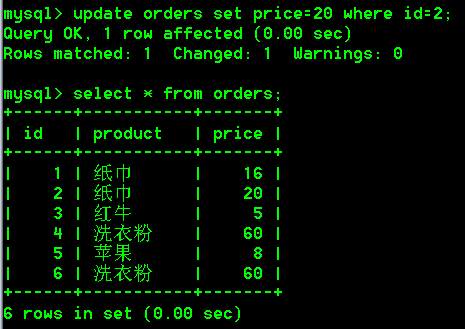
然后先按照商品名进行分组,再按照价格进行分组,查询购买的每种商品的名称以及其总价
select product,sum(price) from orders group by product,price;
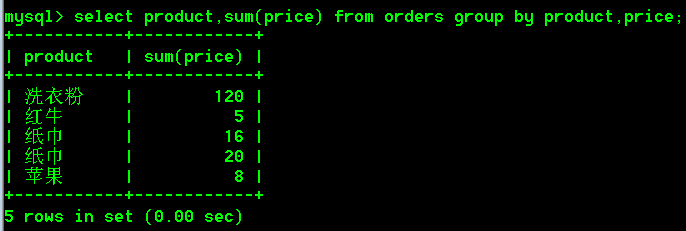
我们发现两个纸巾竟然没有被分为一组,为什么?

- 查询每一种商品的总价大于30的商品,并显示总价。
select product,sum(price) from orders group by product where sum(price) > 30;
上述SQL语句执行,会报错,主要原因是:在SQL语句中where后面不允许添加聚合函数。
那么既然这里不能使用where来解决问题,但是我们依然要进行数据过滤,所以在SQL语句中,如果分组之后,还需要一些条件,那么可以使用having条件,表示分组之后的条件,在having后面可以写聚合函数。
关于having的用法解释:
having必须和group by一起使用,having和where的用法一模一样,where怎么使用having就怎么使用,但是where后面不能跟聚合函数,having可以。
select product,sum(price) from orders group by product having sum(price) > 30;
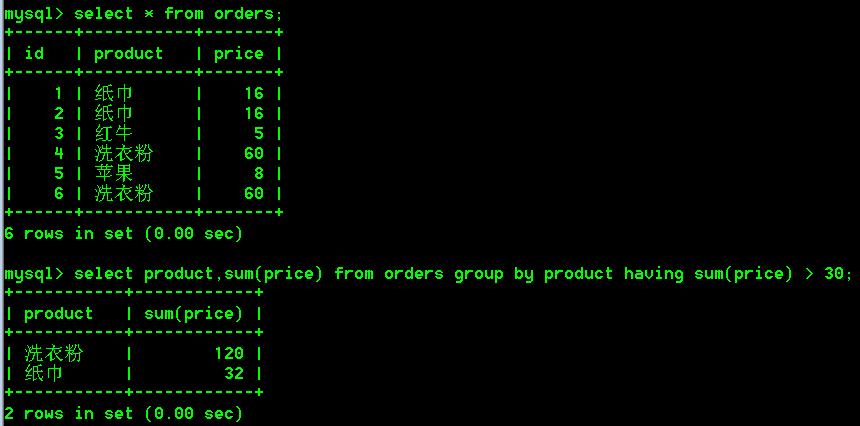
- 强化学习
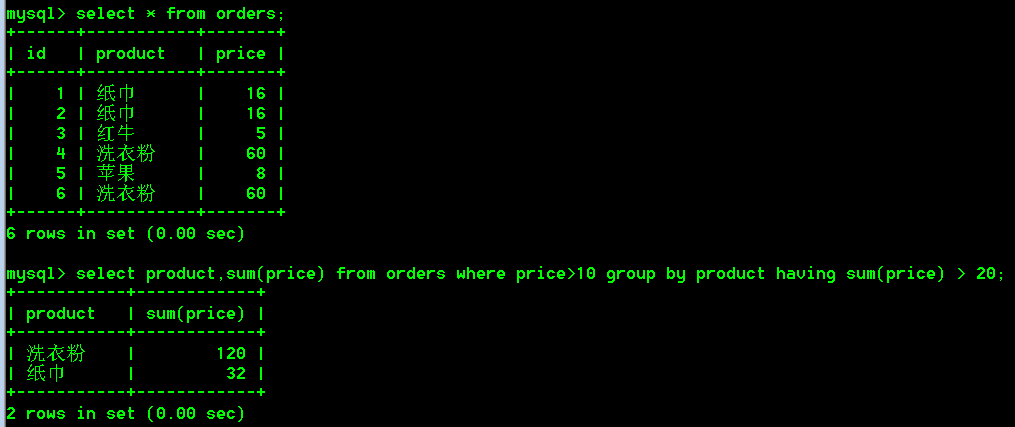
上图的结果分析:
where是在分组之前进行过滤数据的,having是在分组之后进行过滤数据的。所以先执行where price > 10的条件,这样就把红牛和苹果这两个商品给过滤掉了(因为红牛和苹果的价格都小于10),只剩下两条纸巾16,两条洗衣粉60的数据。然后再进行分组聚合(select 语句后面的sum(price)使用和group by product一起运行的,也就是分组和聚合一起的),两条纸巾16的数据分为了一组,两条洗衣粉60的数据分为了一组。得到纸巾32,洗衣粉120这两条数据。然后分完组之后就轮到having这个过滤条件开始执行了,但是此时having过滤条件已经变得没什么意义了,因为在最开始分组之前,where price>10 就已经把要过滤的数据都给过滤了。总而言之就是先走whre条件,再分组聚合,最后走having条件。
查询操作之limit
limit是限制的意思,所以limit的作用就是限制查询记录的条数
limit语句格式
select * from 表名 limit index,count;
-- mysql中的limit的用法:返回前几条或者中间某几条数据
-- 例如:select * from 表名 limit 1,4;
-- 1表示索引,注意这里的索引从0开始,这里的1对应表中第二行数据
-- 4表示查询的记录数
-- 综合来说表示从第2条记录开始查询,一共查询4条,2-5
具体操作:
- 查询student3表中的数据,跳过前面1条,显示4条
select * from student3 limit 1,4;
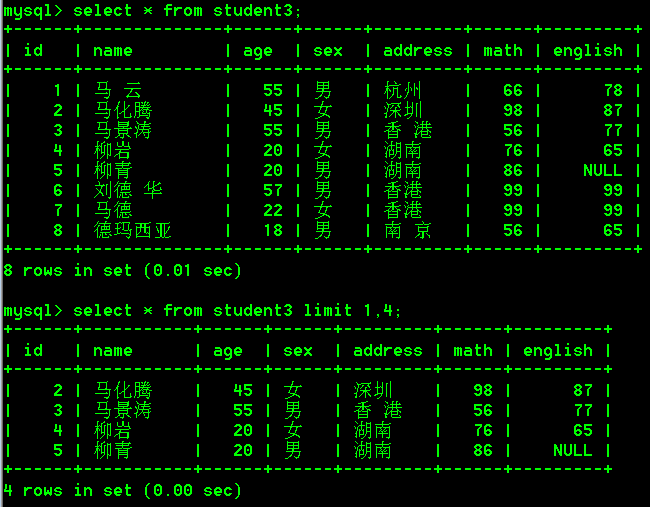
limit的使用场景:分页
比如我们登录京东,淘宝等网站返回的商品信息可能有几万条,不是一次性全部显示出来的,是一页显示固定的条数。假设我们每一页显示5条记录的方式来分页。
假设我们每一页显示5条记录的方式来分页,SQL语句如下:
-- 每页显示5条
-- 第一页 limit 0,5; 跳过0条,显示5条
-- 第二页 limit 5,5; 跳过5条,显示5条
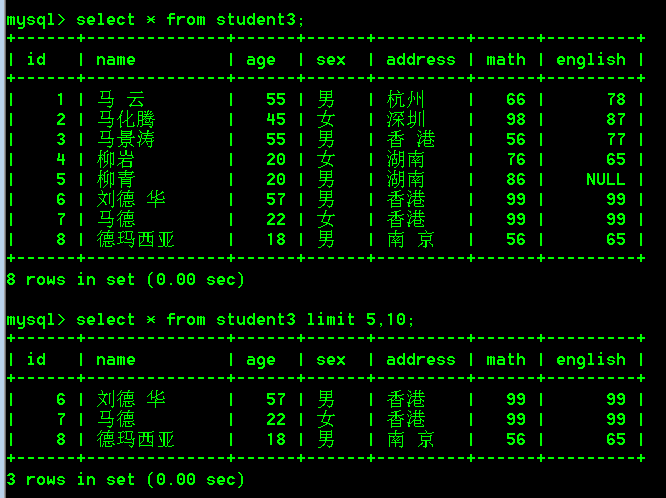
-- 第三页 limit 10,5; 跳过10条,显示5条
注意:limit 5,10; 不够10条,那么有多少显示多少,比如下图:
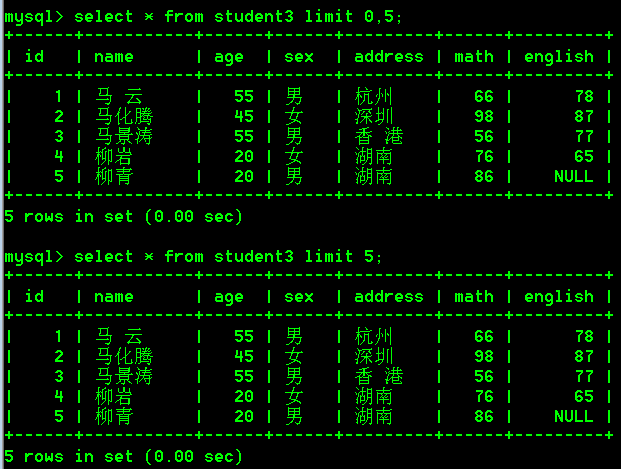
注意:在进行limit分页操作的时候,如果第一个参数为0, 那么这个参数可以省略,比如下图:
数据库约束
1.数据库约束的作用
对表中的数据进行进一步的限制,保证数据的正确性,有效性和完整性。
2.约束种类
- primary key:主键约束
- unique:唯一约束
- not null:非空约束
- default:默认值
- foreign key:外键约束
3.主键约束
主键约束的作用是用来标识某个字段的,每张表都应该有一个主键,并且每张表只能有一个主键。
主键的特点是:
- 主键必须是唯一的值
- 主键列不能包含NULL值
到底给哪个字段设立主键?
通常不用业务字段(用户用得到的字段)作为主键,单独给每张表设计一个id字段,把id作为主键。主键是给数据库和程序使用的,不是给最终的用户使用的。所以主键没有含义没关系,只要不重复,非空就行。
创建主键的方式
- 在创建表的时候给字段添加主键
字段名 字段类型 primary key
- 在已有的表中给字段添加主键
alter table 表名 add primary key(将要作为主键字段的字段名);
具体操作:
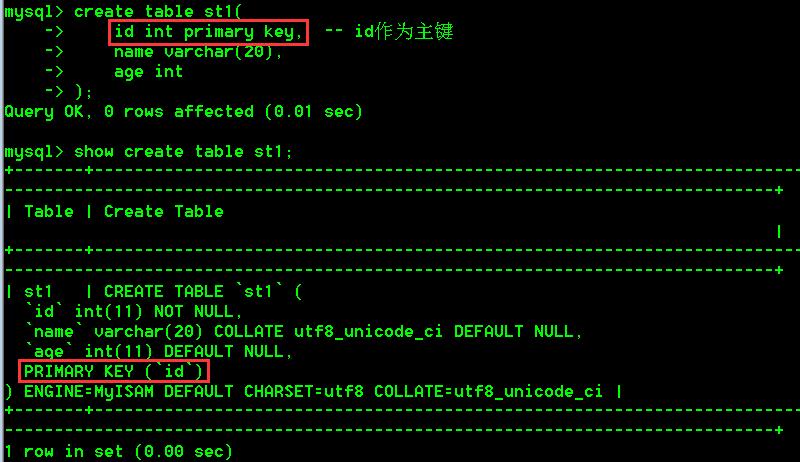
- 创建学生表st1,包含字段(id,name,age),将id作为主键
create table st1(
id int primary key, -- id作为主键
name varchar(20),
age int
);
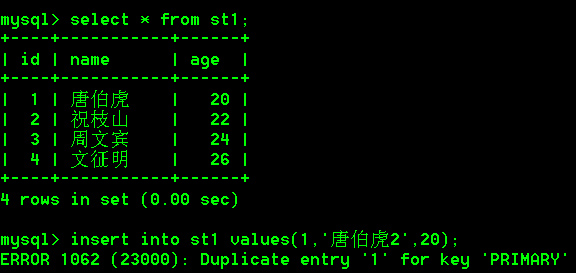
- 添加数据
insert into st1 values(1,'唐伯虎',20);
insert into st1 values(2,'祝枝山',22);
insert into st1 values(3,'周文宾',24);
insert into st1 values(4,'文征明',26);
- 插入重复的主键值
insert into st1 values(1,'唐伯虎2',20);
-- 主键是唯一的不能重复,所以会报错ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
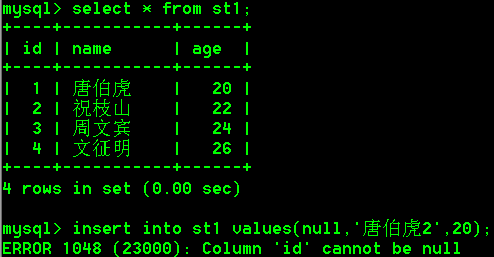
- 插入NULL的主键值
insert into st1 values(null,'唐伯虎2',20);
-- 主键是不能为空的,所以会报错ERROR 1048 (23000): Column 'id' cannot be null
4.主键自增
主键自增顾名思义就是能够设置主键为自动增长,主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值。
字段名 字段类型 primary key auto_increment
-- auto_increment表示自动增长(字段类型必须是整数类型),注意主键自增必须和主键设置在一起,而且字段的类型一定要是整数型
具体操作:
- 创建学生表st2,包含字段(id,name,age)将id作为主键并且自动增长
create table st2(
id int primary key auto_increment,
name varchar(20),
age int
);
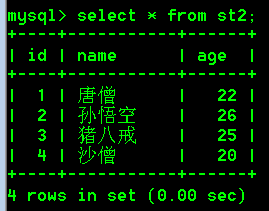
- 插入数据
-- 设置了主键自动增长以后,主键默认就从1开始自动增长
insert into st2(name,age) values('唐僧',22);
insert into st2(name,age) values('孙悟空',26);
insert into st2(name,age) values('猪八戒',25);
insert into st2(name,age) values('沙僧',20);
delete和truncate操作关于主键自增的区别
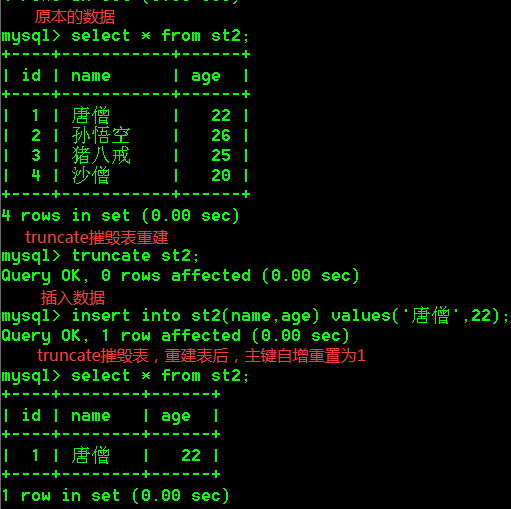
- delete删除表中的数据,但是不重置主键自增的值。(删除全部数据也好,还是删除一条数据也好都不重置)

- truncate摧毁表,重建表,主键自增被重置为了1(重置的原因是,表被删了意味着,主键自增操作也失效了,重建表后,又是新的主键自增,而delete操作没有删除表,所以主键自增操作一直生效)
5.唯一约束
唯一约束可以让表中的某个字段的值不重复(唯一)
基本格式
字段名 字段类型 unique
具体操作
- 创建学生表st3,包含字段(id,name),name这一列设置唯一约束,不能出现同名的学生
create table st3(
id int,
name varchar(20) unique
);
- 添加一些学生
insert into st3 values(1,'貂蝉');
insert into st3 values(2,'西施');
insert into st3 values(3,'杨玉环');
insert into st3 values(4,'王昭君');
-- 插入相同的名字出现name字段值重复,ERROR 1062 (23000): Duplicate entry '王昭君' for key 'name'
insert into st3 values(5,'王昭君');
-- 出现多个null的时候会怎么? 因为null是没有值,所以不存在重复问题
insert into st3 values(5,null);
insert into st3 values(6,null);

6.非空约束
非空约束的作用是可以让表中的指定字段的值不能为null
基本格式
字段名 字段类型 not null
具体操作
- 创建学生表st4,包含字段(id,name,gender),其中name不能为null
create table st4(
id int,
name varchar(20) not null,
gender char(2)
);
- 添加一些学生
insert into st4 values(1,'黎明','男');
insert into st4 values(2,'张学友','男');
insert into st4 values(3,'刘德华','男');
insert into st4 values(4,'郭富城','男');
-- 姓名不能为null,所以会报错ERROR 1048 (23000): Column 'name' cannot be null
insert into st4 values(5,null,'男');
7.默认值
默认值的作用可以让你往表中添加数据时,如果不指定字段的数据,默认会有一个值
基本格式
字段名 字段类型 default 默认值
具体操作
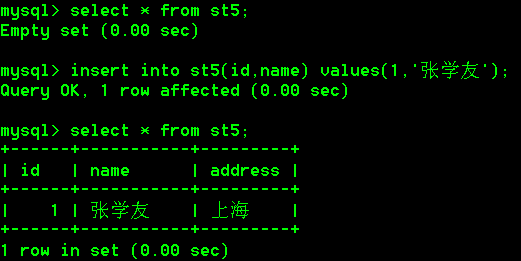
- 创建学生表st5,包含字段(id,name,address),地址默认值是上海
create table st5(
id int,
name varchar(20),
address varchar(20) default '上海'
);
- 添加一条记录,使用默认的地址
insert into st5(id,name) values(1,'张学友');
表关系的概念和外键约束
在真实的项目开发中,一个项目中的数据,一般都会保存在同一个数据库中,但是不同的数据需要保存在不同的数据表中,这时不能把所有的数据都保存在同一张表中。
那么在设计保存数据的数据表时,我们就要根据具体的数据进行分析,然后把同一类数据保存在同一张表中,不同的数据进行分表处理。
数据之间必然会有一定的联系,我们把不同的数据保存在不同的数据表中之后,同时还需要在数据表中维护这些数据之间的关系。这时就会导致表和表之间必然会有一定的联系。这时要求设计表的人员,就需要考虑不同表之间的具体关系。
在数据中,表总共存在三种关系,这三种关系如下:
多对多关系,一对多(多对一)关系,一对一(很少)关系
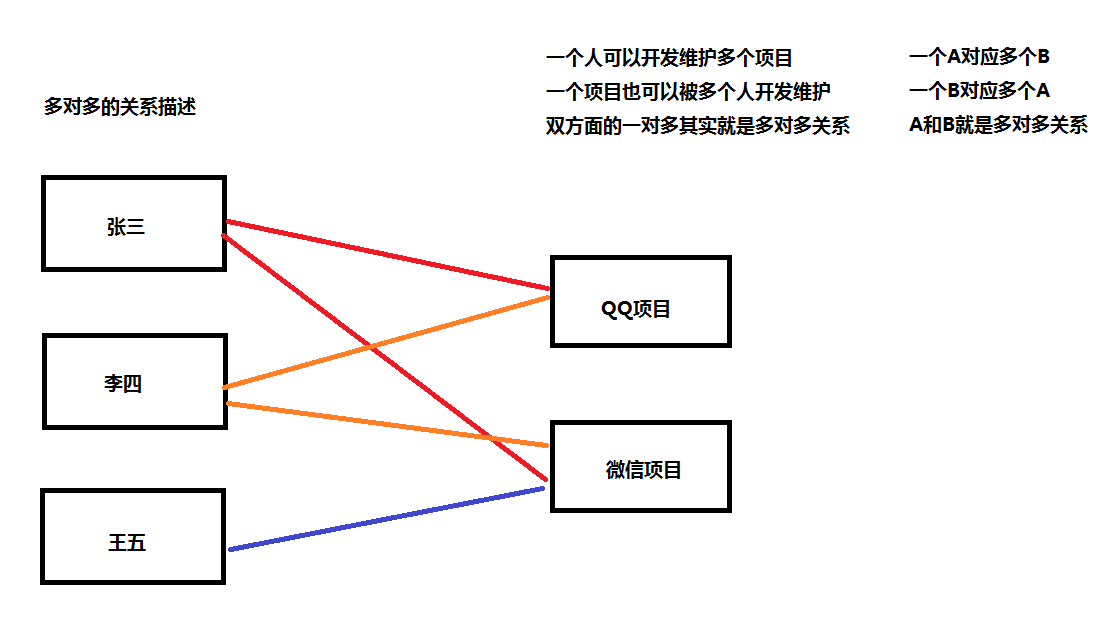
1.多对多关系
例如:程序员和项目的关系,老师和学生,学生和课程,顾客和商品的关系等。
分析:
程序员和项目:
一个程序员可以参与多个项目的开发,一个项目可以由多个程序员来开发,这种关系就成为多对多关系。
当我们把数据之间的关系分析清除之后,一般需要通过E-R图(实体-关系图)来展示。
一个java对象,可以对应数据库中的一张表,而java中类的属性(成员变量),可以对应表中的字段。
而在E-R图中:
一张表,可以称之为一个实体,使用矩形表示,每个实体的属性(表的字段字段),使用椭圆表示。
表和表之间的关系,使用菱形表示。
实体(程序员):编号,姓名,薪资。
实体(项目):编号,名称。
程序员和项目存在关系:一个程序员可以开发多个项目,一个项目可以被多个程序员开发
说明:如果两张表是多对多的关系,需要创建第三张表,并在第三张表中增加两个字段,引入其他两张表的主键作为自己的外键
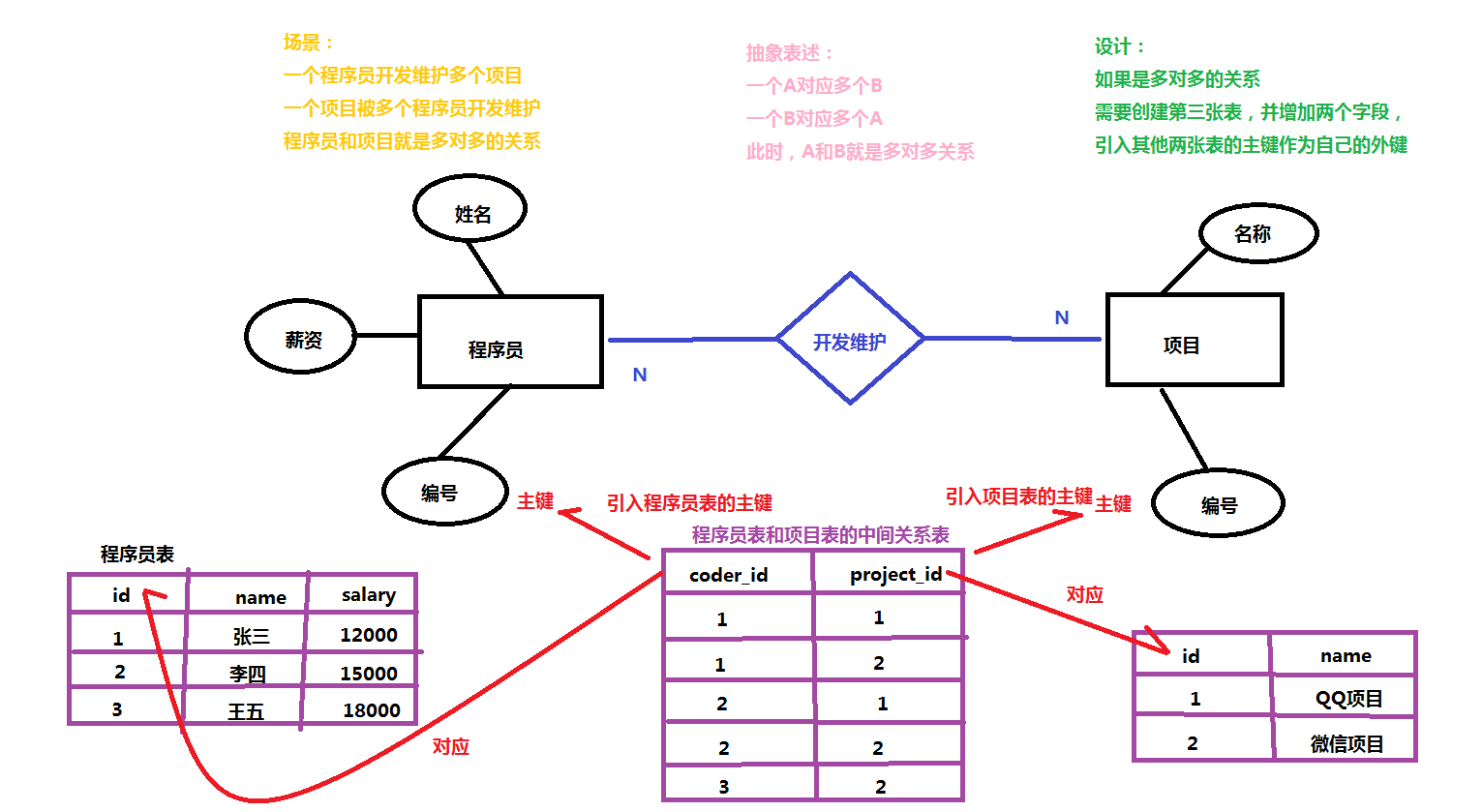
根据上图创建表
-- 创建db2这个库
create database db2;
-- 使用db2这个库
use db2;
-- 创建程序员表
create table coder(
id int primary key auto_increment,
name varchar(20),
salary double
);
-- 创建项目表
create table project(
id int primary key auto_increment,
name varchar(20)
);
-- 创建中间关系表
create table coder_project(
coder_id int,
project_id int
);
-- 添加数据
insert into coder values(1,'张三',12000);
insert into coder values(2,'李四',15000);
insert into coder values(3,'王五',18000);
insert into project values(1,'QQ项目');
insert into project values(2,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,2);
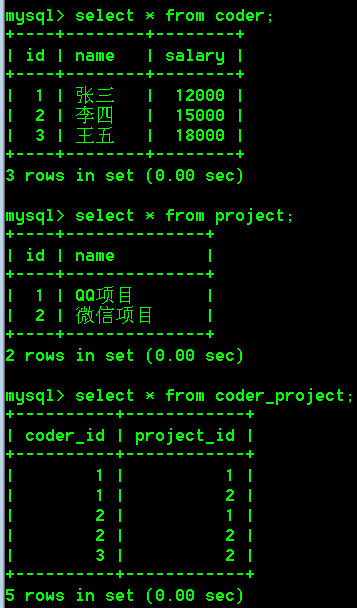
2.外键约束
创建第三张关系表即中间表,来维护程序员表和项目表之间的关系。
使用中间表的目的是维护两张表多对多的关系:
1.中间表插入的数据,必须在多对多的主表(主键表)中存在。(比如:中间表coder_project插入的id,coder表和project表中必须有与之对应的id存在)
2.如果主表的记录在中间表维护了关系,就不能随意删除。如果可以删除,中间表就找不到对应的数据了,这样就没有意义了。(比如:coder_project表中有一条数据,coder_id字段的值为1,project_id字段的值为2。那么对应的coder表中id为1的这条数据不能被删除,project表中id为2的这条数据不能被删除,因为如果删除了那么中间表维护的关系就没有意义了)
上述就是中间表存在的意义,可是我们这里所创建的中间表并没有起到上述的作用,而是存在缺点:
缺点1:我们是可以向中间表插入不存在的程序员编号和项目编号的。
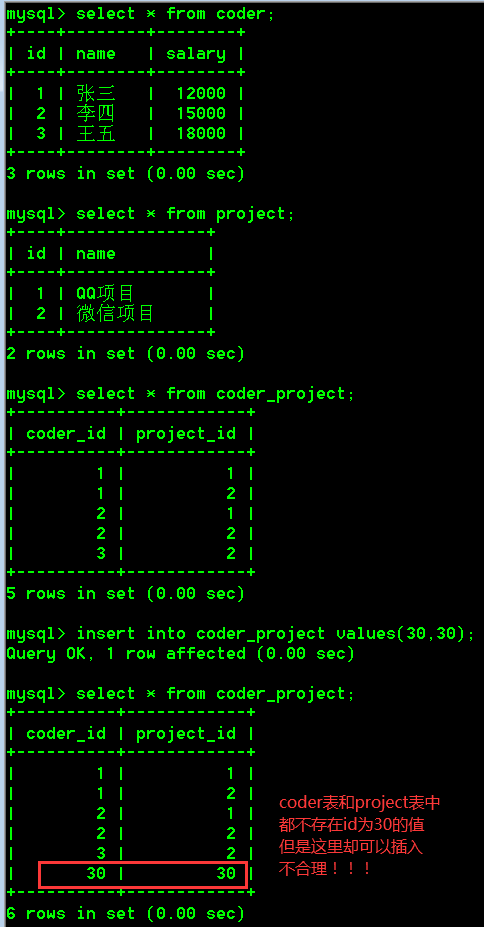
说明:在程序员和项目表中是不存在编号30和30的,但是这里依然可以插入不存在的编号,这样做事不可以的,失去了中间表的意义。
缺点2:如果中间表存在程序员的编号,我们还是可以删除程序员表对应的记录的。
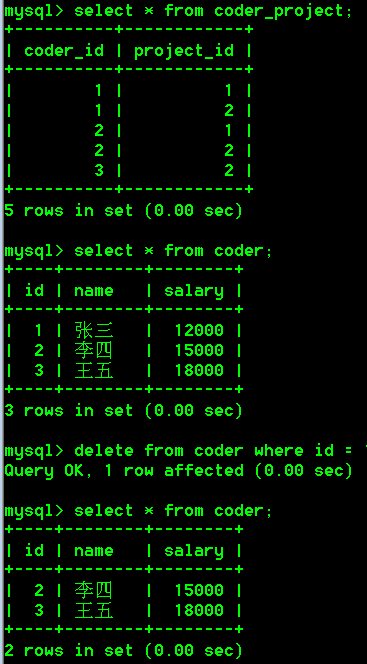
说明:编号为1的程序员张三已经被我们删除了,但是在中间表coder_project中仍然还存在编号为1的程序员,这样对于中间表来说已经没有意义了。
采用外键约束去解决上述问题
我们在创建第三张关系表时,表中的每一列,都在使用其他两张表中的列,这时我们需要对第三张表中的列进行相应的约束。
当前第三张表中的列由于都是引用其他表中的主键列,那么我们把第三张表中的这些列称之为引用其他表的外键约束。
给某个表中的某一列添加外键约束的语法:
foreign key(要设为外键的列名) references 被引用的主键表名(被引用的主键表中的主键名);
constraint 外键约束的名称(自定义且唯一) foreign key(要设为外键的列名) references 被引用的主键表名(被引用的主键表中的主键名);
注意:
- 在主外键约束中,存在外键的表叫做外键表(从表),存在主键的表叫做主键表(主表)
- 外键引用的必须是主键(一定要遵守的)
关键字解释:
- constraint ---> 添加约束,可以不写
- foreign key(要设为外键的列名) ---> 将某个字段作为外键
- references 被引用的主键表名(被引用的主键表中的主键名) ---> 外键引用主表的主键
添加外键的两种方式:
- 第一种方式:给已经存在的表添加外键约束:
-- 中间表与程序员表的主键外键约束
alter table coder_project add constraint c_id_fk foreign key(coder_id) references coder(id);
-- 中间表与项目表的主键外键约束
alter table coder_project add constraint p_id_fk foreign key(project_id) references project(id);
- 第二种方式:创建表时就添加外键约束:
-- 可以自定义外键约束名
create table coder_project(
coder_id int,
project_id int,
constraint c_id_fk foreign key(coder_id) references coder(id),
constraint p_id_fk foreign key(project_id) references project(id)
);
-- 省略了constraint,会默认生成一个外键约束名
create table coder_project(
coder_id int,
project_id int,
foreign key(coder_id) references coder(id),
foreign key(project_id) references project(id)
);
注意:如果说某一个外键引用了某一个主键,那么那个外键的字段类型一定要和主键的字段类型一致,哪怕是大小也得一致。
例如:外键字段A引用了主键字段B,那么外键字段A为int(11)类型,那么主键字段B也一定要为int(11)类型。
3.外键的级联
在修改和删除主表的主键时,同时更新或删除从表的外键值,称之为级联操作
on update cascade --> 级联更新,主键发生更新时,外键也会更新
on delete cascade --> 级联删除,主键发生删除时,外键也会删除
具体操作:
- 删除中间表coder,coder_project,project表
- 重新创建三张表,添加级联更新和级联删除
drop table coder_project;
drop table coder;
drop table project;
-- 创建程序员表
create table coder(
id int primary key auto_increment,
name varchar(20),
salary double
);
-- 创建项目表
create table project(
id int primary key auto_increment,
name varchar(20)
);
-- 创建中间关系表
create table coder_project(
coder_id int,
project_id int,
-- 添加外键约束,并且添加级联更新和级联删除
constraint c_id_fk foreign key(coder_id) references coder(id) on update cascade on delete cascade,
constraint p_id_fk foreign key(project_id) references project(id) on update cascade on delete cascade
);
-- 添加数据
insert into coder values(1,'张三',12000);
insert into coder values(2,'李四',15000);
insert into coder values(3,'王五',18000);
insert into project values(1,'QQ项目');
insert into project values(2,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,2);
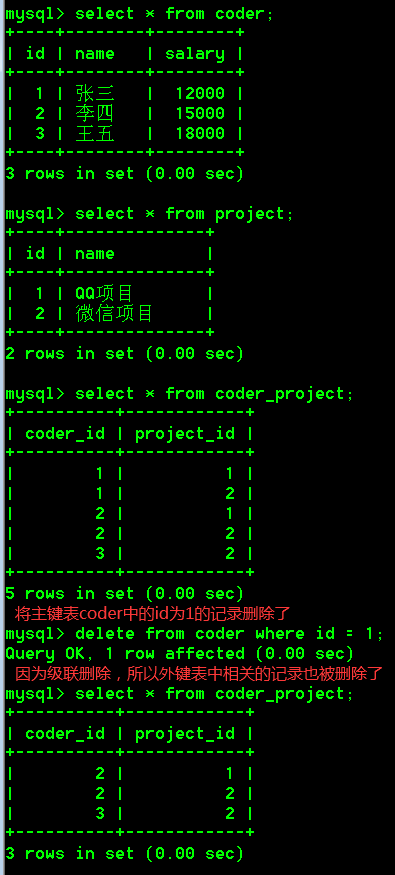
4.一对多关系
一对多的关系表:其中也有2个实体(表),但是其中A实体中的数据可以对应另外B实体中的多个数据,反过来B实体中的多个数据只能对应A实体中的一个数据。
例如:作者和小说,班级和学生,部门和员工,客户和订单
分析:作者和小说
一个作者可以写多部小说,但每一部小说,只能对应具体的一个作者
具体的关系如下图所示:
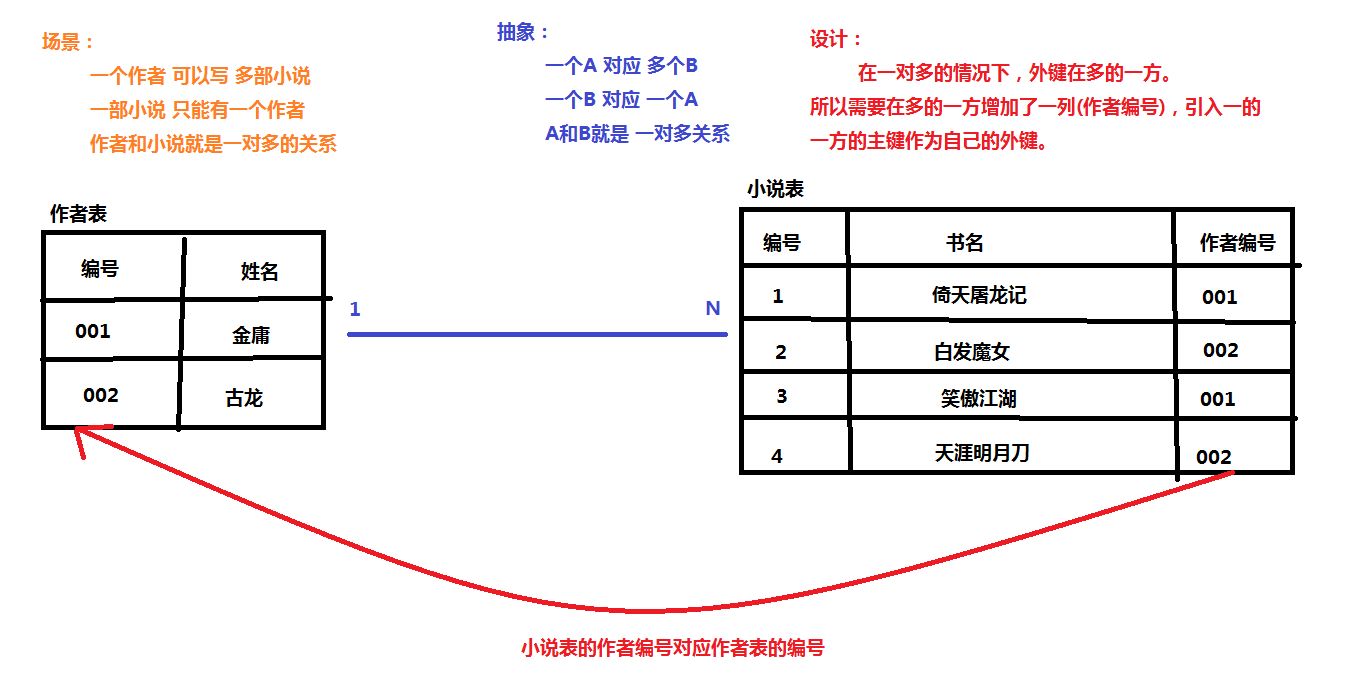
5.一对一
一对一关系表在实际开发中使用的并不多(基本没有),其中也是2个实体(表),其中A实体中的数据只能对应B实体中的一个数据,同时B实体中的数据也只能对应A实体中的一个数据。
例如:人和身份证,老公和老婆
因为一 一对应,所以再分为两张表已经没有意义了,其实一张表就搞定了!!!
多表查询
1.什么是多表查询
同时查询多张表获取到需要的数据,比如:我们想查询水果的对应价格,需要将水果表和价格表同时进行查询
一种水果一种价格
一种价格多种水果
价格和水果属于一对多
将一的一方即价格的主键作为多的一方即水果的外键。
2.多表查询的分类
多表查询
1.表连接查询
内连接
显示内连接
隐式内连接
外连接
左外连接
右外连接
2.子查询
3.笛卡尔积现象
准备数据
有两张表,一张是水果表fruit,一张是价格表price。
价格和水果是一对多
建表
create database db4;
use db4;
-- 价格 1
create table price(
id int primary key auto_increment,
price double
);
-- 水果 n
create table fruit(
id int primary key auto_increment,
name varchar(20) not null,
price_id int,
foreign key(price_id) references price(id)
);
insert into price values(1,2.30);
insert into price values(2,3.50);
insert into price values(4,null);
insert into fruit values(1,'苹果',1);
insert into fruit values(2,'橘子',2);
insert into fruit values(3,'香蕉',null);
需求:查询两张表中关于水果的信息,要显示水果名称和水果价格。
具体操作:
-- 多表查询语法
select * from fruit,price;
查询结果:
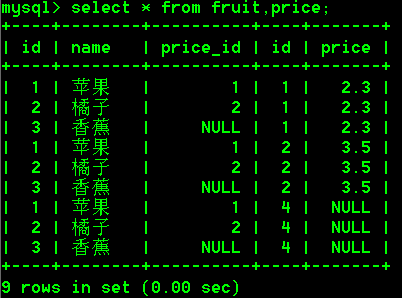
说明:
fruit表中的每一条记录,都和price表中的每一条进行匹配链接。所得到的最终结果是:fruit表中的条目数乘以price表中的数据的条目数。将fruit表的每行记录和price表的每行记录组合的结果就是笛卡尔积。
笛卡尔积产生的问题:把多张表放在一起,同时去查询,会得到一个结果,而这个结果并不是我们想要的数据,这个结果称之为笛卡尔积。
笛卡尔积的缺点:查询到的数据冗余了,里面有很多错误的数据,需要过滤。
举例:上述图中的笛卡尔积结果中只有两行结果是正确的
1 苹果 1 1 2.3
2 橘子 2 2 3.5
结论:笛卡尔积的数据,对于程序而言是没有意义的,我们需要对笛卡尔积中的数据再次进行过滤。对于对多表查询操作,需要过滤出满足条件的数据,就需要把多张表进行连接,连接之后再加上过滤条件。总的来说就是要避免笛卡尔积的出现。
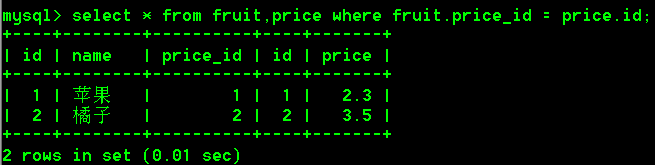
4.如何消除笛卡尔积现象的影响
在查询两张表的同时添加条件进行过滤,比如fruit表的id必须和price表的id相同
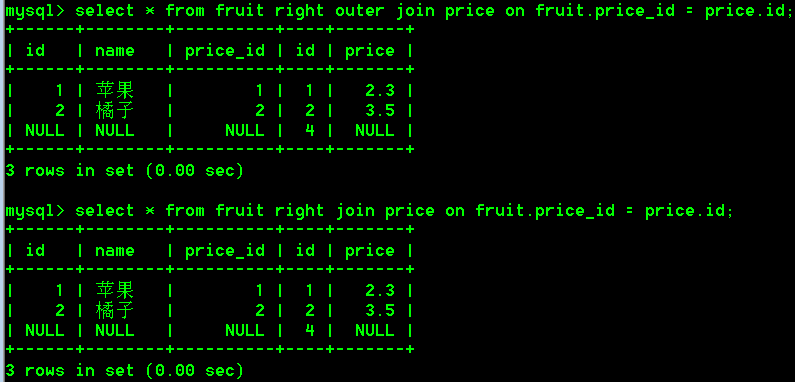
select * from fruit,price where fruit.price_id = price.id;
5.内连接
什么是内连接
用左边表的记录去匹配右边表的记录,如果符合条件的则显示。内连接查询的结果:两表的公共部分
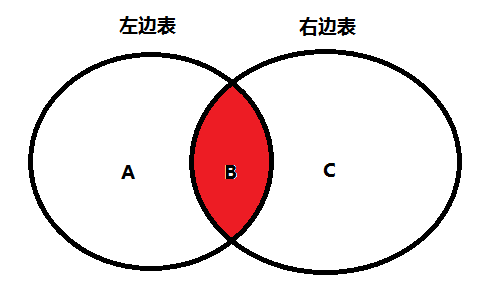
5.1隐式内连接
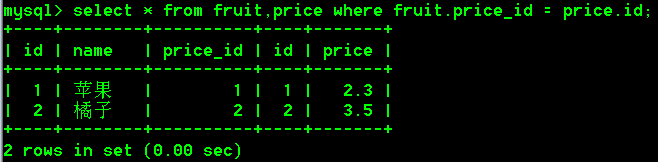
看不到join关键字,条件使用where指定
语法:
select 列名,列名,... from 表名1,表名2,... where 表名1.列名 = 表名2.列名;
select * from fruit,price where fruit.price_id = price.id;
说明:在产生两张表的笛卡尔积的数据之后,通过条件筛选出正确的结果。
5.2 显示内连接
使用inner join ... on语句,但是可以省略inner
语法
select * from 表名1 inner join 表名2 inner join 表名3 inner join 表名4 ...... on 多个条件;
或者
select * from 表名1 join 表名2 on 条件
具体操作:
- 使用显示内连接解决上述的笛卡尔积问题
select * from fruit join price on fruit.price_id = price.id;
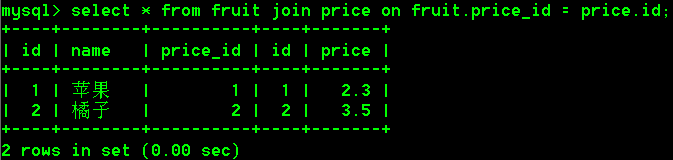
说明:显示的内连接,一般称为标准的内连接,有inner join,查询到的数据为两张表经过on条件过滤后的笛卡尔积。
6.外连接
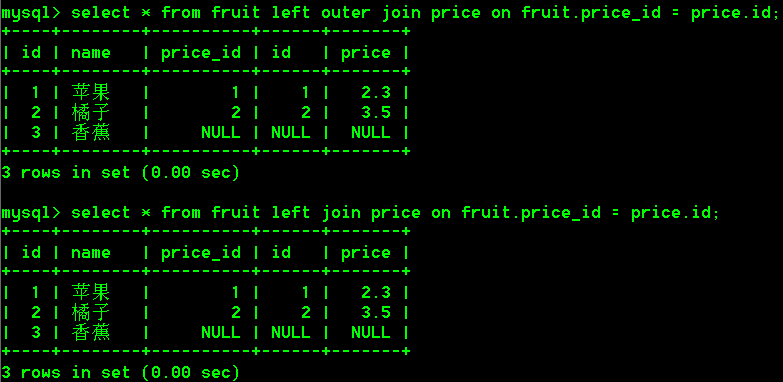
6.1 左外连接
左外连接可以理解为:用左边表去右边表中查询对应的记录,不管是否找到,都将显示左边表中全部记录。(左边表全查,右边表只查符合条件的)
举例:上述案例中虽然右表没有香蕉对应的价格,也要把它查询出来
左外连接:使用left outer join ... on,outer可以省略
select * from 表1 left outer join 表2 on 条件;
-- 把left关键字之前的表,是定义为左侧;left关键字之后的表,是定义为右侧。
-- 查询的内容,以左侧的表为主,如果左侧有数据,右侧没有对应的数据,仍然会把左侧数据进行显示。
具体操作
- 不管能否查到水果对应的价格,都要把水果显示出来。
select * from fruit left outer join price on fruit.price_id = price.id;
-- outer 可以省略
select * from fruit left join price on fruit.price_id = price.id;
6.2 右外连接
用右边表去左边表查询对应记录,不管是否能找到,右边表全部记录都将显示。
举例:上述案例中不管在左方表能否找到右方表价格对应的水果,都要把右边的价格显示出来。(右边表全查,左边表只差符合条件的)
右外连接:使用right outer join ... on,outer可以省略
语法:
select * from 表1 right outer join 表2 on 条件;
说明:
如果右侧有数据,左侧没匹配到,把右侧的数据全部显示出来,左侧只显示匹配到的
right之前的是左侧,right之后的是右侧
具体操作
- 不管能否查到价格对应的水果,都要把价格显示出来
select * from fruit right outer join price on fruit.price_id = price.id;
-- outer 可以省略
select * from fruit right join price on fruit.price_id = price.id;
7.子查询
准备数据
create database db5;
use db5;
-- 创建部门表 1
CREATE TABLE dept (
id INT PRIMARY KEY AUTO_INCREMENT, -- 部门编号
NAME VARCHAR(20) -- 部门名称
);
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
-- 创建员工表 n
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10), -- 员工姓名
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT,
foreign key(dept_id) references dept(id)
);
-- 上述部门表和员工表存在一对多的关系
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);
什么是子查询
-- 一条查询语句的结果作为另一条查询语句的一部分
select 查询字段 from 表 where 条件;
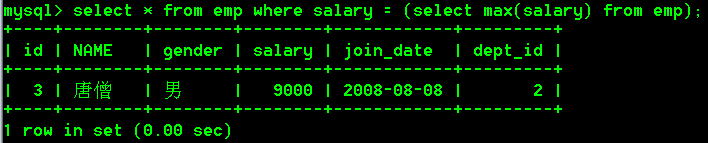
-- 举例:查询薪资最高的那个人的所有信息
select * from emp where salary = (select max(salary) from emp);
-- 注意:子查询需要放在括号内

8.子查询的结果是单行单列的时候
子查询结果是单行单列,在where后面作为条件
select 查询字段 from 表 where 字段 = (子查询);
具体操作
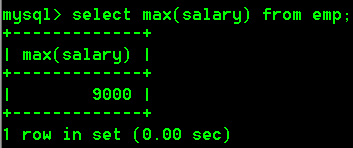
- 查询最高工资是多少
select max(salary) from emp;
- 根据最高工资到员工表查询到对应的员工信息
select * from emp where salary = (select max(salary) from emp);
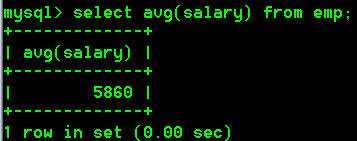
- 查询平均工资是多少
select avg(salary) from emp;
- 到员工表查询小于平均工资的员工信息
select * from emp where salary < (select avg(salary) from emp);
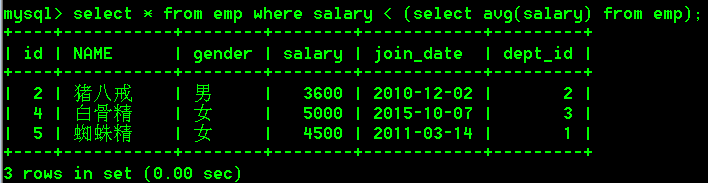
9.子查询的结果是多行单例的时候
子查询结果是多行单例,结果集类似于一个数组,在where后面作为条件,父查询使用in来运算
select 查询字段 from 表 where 字段 in (子查询);
- 查询大于5000的员工所在的部门id
select dept_id from emp where salary > 5000;
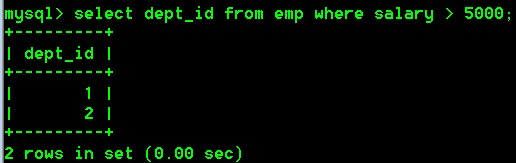
- 查询大于5000的员工所在的部门的名字(使用子查询)
select dept.name from dept where dept.id in (select dept_id from emp where salary > 5000);

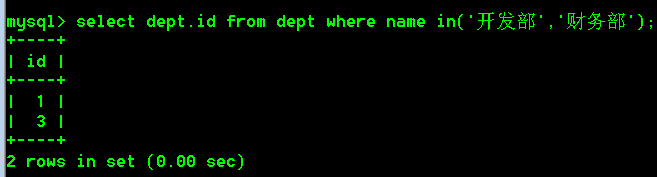
- 查询开发部与财务部的id
select dept.id from dept where name in('开发部','财务部');
- 查询开发部与财务部中有哪些员工
select * from emp where dept_id in (select dept.id from dept where name in('开发部','财务部'));

10.子查询的结果是多行多列
子查询结果是多行多列,在from后面作为表
select 查询字段 from (子查询) 表别名 where 条件;
注意:子查询作为表时需要取别名,使用as,但是可以省略as,否则这张表没有名称将无法访问表中的字段
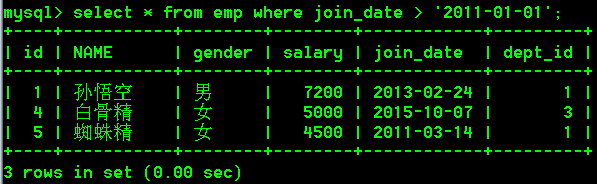
- 在员工表中查询2011-01-01以后入职的员工
select * from emp where join_date > '2011-01-01';
- 查询出2011年以后入职的员工信息,包括部门名称
-- 隐式内连接 + 子查询
select e.*,d.name from dept as d,(select * from emp where join_date > '2011-01-01') as e where e.dept_id = d.id;
-- 显示内连接 + 子查询
select e.*,d.name from dept as d join (select * from emp where join_date > '2011-01-01') as e on e.dept_id = d.id;
-- 左外连接 + 子查询,这样不行,不符合需求,因为部门表全查,子查询生成的表只查符合条件的,会产生错误数据,市场部我们是不需要查出来的。
select e.*,d.name from dept as d left join (select * from emp where join_date > '2011-01-01') as e on e.dept_id = d.id;
-- 右外连接 + 子查询
select e.*,d.name from dept as d right join (select * from emp where join_date > '2011-01-01') as e on e.dept_id = d.id;

数据库备份和还原
1.数据库备份
格式:
mysqldump --no-defaults -u root -p 备份的数据库名 > 硬盘SQL文件的绝对路径
注意:
这个操作不用登录,直接在cmd下执行。
具体操作:
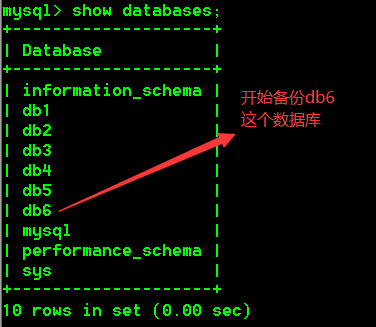

2.数据库还原
格式:
mysql -uroot -proot 导入库名 < 硬盘sql文件的绝对路径
注意:
这个操作不用登录,直接在cmd下执行。
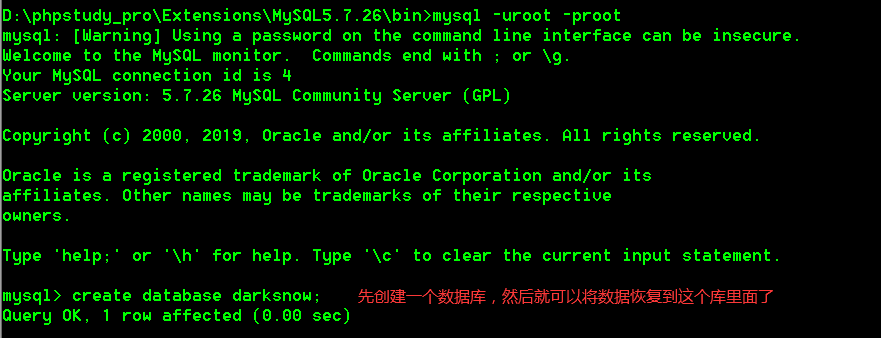
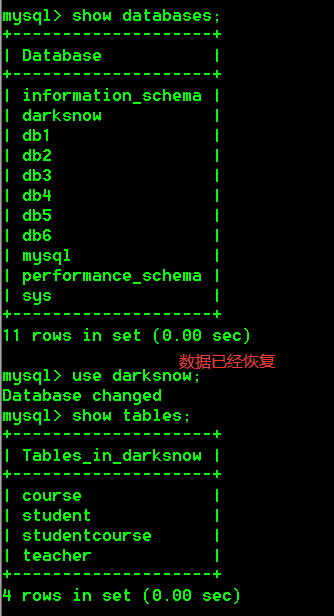
恢复数据库,需要手动创建数据库,然后再将数据恢复到你创建的那个数据库里面
具体操作:

多表查询练习(子查询)
准备数据
create database db6;
use db6;
-- 教师表
create table teacher (
id int(11) primary key auto_increment,
name varchar(20) not null unique
);
-- 学生表
create table student (
id int(11) primary key auto_increment,
name varchar(20) NOT NULL unique,
city varchar(40) NOT NULL,
age int
);
-- 课程表
create table course(
id int(11) primary key auto_increment,
name varchar(20) not null unique,
teacher_id int(11) not null,
foreign key(teacher_id) references teacher (id)
);
-- 选课表,学生和课程的中间关系表
create table studentcourse (
student_id int NOT NULL,
course_id int NOT NULL,
score double NOT NULL,
foreign key (student_id) references student (id),
foreign key (course_id) references course (id)
);
insert into teacher values(null,'关羽');
insert into teacher values(null,'张飞');
insert into teacher values(null,'赵云');
insert into student values(null,'小王','北京',20);
insert into student values(null,'小李','上海',18);
insert into student values(null,'小周','北京',22);
insert into student values(null,'小刘','北京',21);
insert into student values(null,'小张','上海',22);
insert into student values(null,'小赵','北京',17);
insert into student values(null,'小蒋','上海',23);
insert into student values(null,'小韩','北京',25);
insert into student values(null,'小魏','上海',18);
insert into student values(null,'小明','广州',20);
insert into course values(null,'语文',1);
insert into course values(null,'数学',1);
insert into course values(null,'生物',2);
insert into course values(null,'化学',2);
insert into course values(null,'物理',2);
insert into course values(null,'英语',3);
insert into studentcourse values(1,1,80);
insert into studentcourse values(1,2,90);
insert into studentcourse values(1,3,85);
insert into studentcourse values(1,4,78);
insert into studentcourse values(2,2,53);
insert into studentcourse values(2,3,77);
insert into studentcourse values(2,5,80);
insert into studentcourse values(3,1,71);
insert into studentcourse values(3,2,70);
insert into studentcourse values(3,4,80);
insert into studentcourse values(3,5,65);
insert into studentcourse values(3,6,75);
insert into studentcourse values(4,2,90);
insert into studentcourse values(4,3,80);
insert into studentcourse values(4,4,70);
insert into studentcourse values(4,6,95);
insert into studentcourse values(5,1,60);
insert into studentcourse values(5,2,70);
insert into studentcourse values(5,5,80);
insert into studentcourse values(5,6,69);
insert into studentcourse values(6,1,76);
insert into studentcourse values(6,2,88);
insert into studentcourse values(6,3,87);
insert into studentcourse values(7,4,80);
insert into studentcourse values(8,2,71);
insert into studentcourse values(8,3,58);
insert into studentcourse values(8,5,68);
insert into studentcourse values(9,2,88);
insert into studentcourse values(10,1,77);
insert into studentcourse values(10,2,76);
insert into studentcourse values(10,3,80);
insert into studentcourse values(10,4,85);
insert into studentcourse values(10,5,83);
练习
- 查询获得最高分的学生信息
-- 在中间表找到最高分
select max(score) from studentcourse;
-- 在中间表找最高分对应的学生编号
select student_id from studentcourse where score = (select max(score) from studentcourse);
-- 在学生表根据学生编号找到学生信息
select * from student where id in (select student_id from studentcourse where score = (select max(score) from studentcourse));
- 查询编号是2的课程比编号是1的课程的最高成绩还要高的学生信息(学生信息只是学生表的内容,不包含成绩)
-- 在中间表找编号是1的课程的最高成绩
select max(score) from studentcourse where course_id = 1;
-- 在中间表找编号是2的成绩 > 编号是1的最高成绩的学生id
select student_id from studentcourse where course_id = 2 and score > (select max(score) from studentcourse where course_id = 1);
-- 在学生表根据编号找到对应的学生信息
select * from student where id in (select student_id from studentcourse where course_id = 2 and score > (select max(score) from studentcourse where course_id = 1));
- 查询编号是2的课程比编号是1的课程的最高成绩高的学生姓名和成绩(查的是学生的名字和成绩)
-- 在中间表找编号是1的课程的最高成绩
select max(score) from studentcourse where course_id = 1
-- 在中间表找编号是2的成绩 > 编号是1的最高成绩的学生id,成绩
select student_id,score from studentcourse where course_id = 2 and score > (select max(score) from studentcourse where course_id = 1);
-- 将上述查询出来的内容作为临时表和学生表关联(关联查询),查询姓名和成绩
select student.name,temp.score from student,(select student_id,score from studentcourse where course_id = 2 and score > (select max(score) from studentcourse where course_id = 1)) as temp where student.id = temp.student_id;
- 查询每个同学的学号、姓名、选课数,总成绩
-- 在中间表中查询每个学生的选课数和总成绩,遇到每个,按照学生学号进行分组
select student_id,count(*),sum(score) from studentcourse group by student_id;
-- 由于还得显示姓名,并且姓名在student表中,所以我们将上述结果作为临时表和学生表进行关联查询
select student.id,student.name,temp.courses,temp.scores from student,(select student_id,count(*) as courses,sum(score) as scores from studentcourse group by student_id) as temp where student.id = temp.student_id;
多表查询练习(连接查询)
准备数据
create database db7;
use db7;
-- 部门表
CREATE TABLE dept (
id INT PRIMARY KEY PRIMARY KEY, -- 部门id
dname VARCHAR(50), -- 部门名称
loc VARCHAR(50) -- 部门位置
);
-- 添加4个部门
INSERT INTO dept(id,dname,loc) VALUES
(10,'教研部','北京'),
(20,'学工部','上海'),
(30,'销售部','广州'),
(40,'财务部','深圳');
-- 职务表,职务名称,职务描述
CREATE TABLE job (
id INT PRIMARY KEY,
jname VARCHAR(20), -- 职务名称
description VARCHAR(50) -- 职务描述
);
-- 添加4个职务
INSERT INTO job (id, jname, description) VALUES
(1, '董事长', '管理整个公司,接单'),
(2, '经理', '管理部门员工'),
(3, '销售员', '向客人推销产品'),
(4, '文员', '使用办公软件');
-- 员工表
CREATE TABLE emp (
id INT PRIMARY KEY, -- 员工id
ename VARCHAR(50), -- 员工姓名
job_id INT, -- 职务id
mgr INT , -- 上级领导
joindate DATE, -- 入职日期
salary DECIMAL(7,2), -- 工资
bonus DECIMAL(7,2), -- 奖金
dept_id INT, -- 所在部门编号
CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),
CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);
-- 添加员工
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,'孙悟空',4,1004,'2000-12-17','8000.00',NULL,20),
(1002,'卢俊义',3,1006,'2001-02-20','16000.00','3000.00',30),
(1003,'林冲',3,1006,'2001-02-22','12500.00','5000.00',30),
(1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20),
(1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30),
(1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30),
(1007,'刘备',2,1009,'2001-09-01','24500.00',NULL,10),
(1008,'猪八戒',4,1004,'2007-04-19','30000.00',NULL,20),
(1009,'罗贯中',1,NULL,'2001-11-17','50000.00',NULL,10),
(1010,'吴用',3,1006,'2001-09-08','15000.00','0.00',30),
(1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20),
(1012,'李逵',4,1006,'2001-12-03','9500.00',NULL,30),
(1013,'小白龙',4,1004,'2001-12-03','30000.00',NULL,20),
(1014,'关羽',4,1007,'2002-01-23','13000.00',NULL,10);
-- 工资等级表
CREATE TABLE salarygrade (
grade INT PRIMARY KEY,
losalary INT, -- 最低薪资
hisalary INT -- 最高薪资
);
-- 添加5个工资等级
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);
- 查询所有员工信息,显示员工编号,员工姓名,工资,职务名称,职务描述。
select e.id,e.ename,e.salary,j.jname,j.description from emp e inner join job j on e.job_id = j.id;
- 查询所有员工信息,显示员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置。
select
e.id,e.ename,e.salary,j.jname,j.description,d.dname,d.loc
from emp e
inner join job j
inner join dept d
on e.job_id = j.id and e. dept_id = d.id;
- 查询所有员工信息,显示员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级。
select
e.ename,e.salary,j.jname,j.description,d.dname,d.loc,s.grade
from emp e
inner join job j
inner join dept d
inner join salarygrade s
on e.job_id = j.id and e. dept_id = d.id
and e.salary between s.losalary and s.hisalary;
- 查询经理的信息,显示员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级。
select
e.ename,e.salary,j.jname,j.description,d.dname,d.loc,s.grade
from emp e
inner join job j
inner join dept d
inner join salarygrade s
on e.job_id = j.id and e. dept_id = d.id
and e.salary between s.losalary and s.hisalary and j.jname = '经理';
- 查询出每个部门的部门编号,部门名称,部门位置,部门人数。
-- 去员工表中找到每个部门的人数和部门id
select count(*),dept_id from emp group by dept_id;
-- 在和部门表连接查询
select d.id,d.dname,d.loc,temp.humans from dept d inner join (select count(*) as humans,dept_id from emp group by dept_id) as temp on d.id = temp.dept_id;
数据连接工具
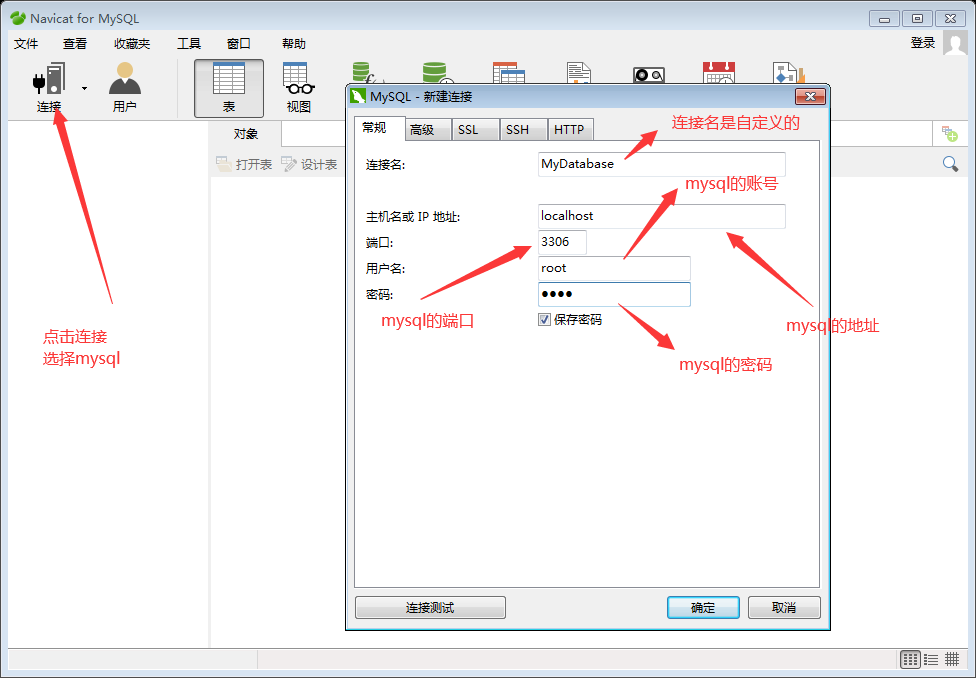
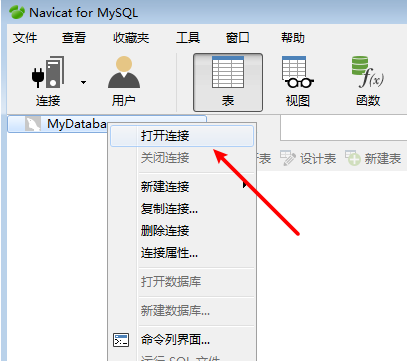
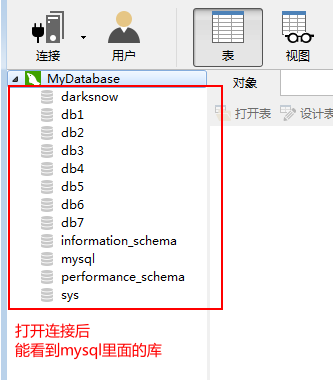
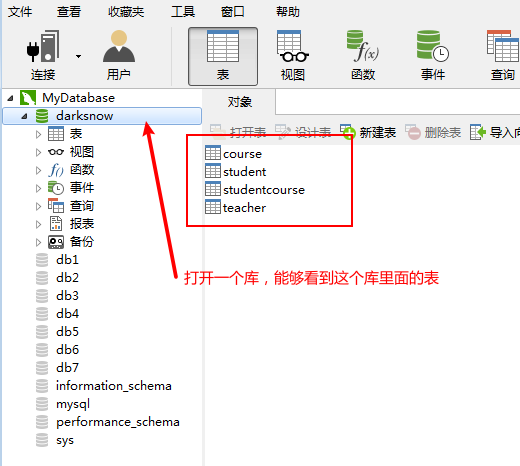
MySQL的运算符
1.算术运算符
加:select 8+6;
减:select 8-6;
乘:select 8*6;
除:select 10/3; 结果精确到小数点后四位
商:select 5 div 2; div做除法,结果为整数
取余:select 5%2; 5÷2=2......1(取得是1这个余数),在写法上还能 select mod(5,2); 这么去写
2.比较运算符
"单纯的做比较,结果总是1(代表true),0(代表false),null"
(1) select 1 = 2; 等于
(2) select 1 <=> 2;
'<=>'类似于'=',区别是当符号两边出现null值时,=操作符会返回null,而<=>会返回1(两边操作数都为null时)或者0(一边操作数为null时)
(3) select 1 <> null; 不等于,不能用于空值null判断。
(4) <,<=,>,>= 不能用于空值null判断。
(5)★ is null 判断一个值是否为null,"isnull(字段名)" 等价于 "字段名 is null"
例子(写法一):mysql> select * from student where age is null; (查询年龄为null的学生的信息)
+----+--------+--------+------+
| id | name | city | age |
+----+--------+--------+------+
| 1 | 小王 | 北京 | NULL |
| 2 | 小李 | 上海 | NULL |
| 3 | 小周 | 北京 | NULL |
| 8 | 小韩 | 北京 | NULL |
+----+--------+--------+------+
例子二(写法二):mysql> select * from student where isnull(age);
+----+--------+--------+------+
| id | name | city | age |
+----+--------+--------+------+
| 1 | 小王 | 北京 | NULL |
| 2 | 小李 | 上海 | NULL |
| 3 | 小周 | 北京 | NULL |
| 8 | 小韩 | 北京 | NULL |
+----+--------+--------+------+
(6)★ is not null 判断一个值是否不为null
例子:mysql> select * from student where age is not null; (查询年龄不为null的学生信息)
+----+--------+--------+------+
| id | name | city | age |
+----+--------+--------+------+
| 4 | 小刘 | 北京 | 21 |
| 5 | 小张 | 上海 | 22 |
| 6 | 小赵 | 北京 | 17 |
| 7 | 小蒋 | 上海 | 23 |
| 9 | 小魏 | 上海 | 18 |
| 10 | 小明 | 广州 | 20 |
+----+--------+--------+------+
(7) least 当有两个值或多个值,就返回其中的最小值
例子:mysql> select least(120,110,130,95,415);
+---------------------------+
| least(120,110,130,95,415) |
+---------------------------+
| 95 |
+---------------------------+
(8) greatest 当有两个值或多个值,就返回其中的最大值
(9) regexp 用来匹配字符串的
例子:select 'darksnow' regexp '^d';
规则:
'^',匹配以该字符后面的字符开头的字符串
'$',匹配以该字符后面的字符结尾的字符串
'.',匹配任何一个单字符
'[...]',匹配括号中内的任意字符
3.逻辑运算符
not或者! 逻辑非
and或者&& 逻辑与
or或者|| 逻辑或
xor或者^ 逻辑异或
4.位操作运算符
& 位与
| 位或
^ 位异或
<< 位左移
>> 位右移
~ 位取反
MySQL中的函数
1.数学函数
select pi(); "3.141593,返回圆周率的值,精确到6位,最后一位是四舍五入得来的"
select abs(-10); "结果为10,返回绝对值"
select sqrt(4); "结果为2,返回平方根(开方)"
select pow(2,3); "结果为8,返回2的3次方"
select truncate(3.1415926,4); "结果为3.1415,返回3.1415926截取4位小数的结果"
2.日期函数
select now(); "返回系统的当前日期和时间"
select sysdate(); "sysdate()函数等价于now()函数"
select curdate(); "返回当前系统的日期"
select curtime(); "返回当前系统的时间"
select year('2022-12-12'); "参数需要你传入一个字符串,返回字符串中的年份"
select month(now()); "参数需要你传入一个字符串,返回字符串中的月份"
select day(now()); "参数需要你传入一个字符串,返回字符串中的日"
select week(now()); "参数需要你传入一个字符串,返回字符串中的日是这一年的第几周"
3.字符串函数
例子:select char_length(name) from student;
char_length(str) 返回字符串str所包含的字符个数
length(str) 返回字符串str中的字符的字节长度
ascii(str) 返回字符的ASCII码值
concat(s1,s2,sn) 将字符串s1,s2,sn拼接成一个字符串,此函数允许传入多个参数,类似于可变参
concat_ws(',',s1,s2,sn) 将字符串s1,s2,sn拼接成一个字符串,并且用','号隔开
lcase(str)或者lower(str) 将字符串str转成小写
ucase(str)或者upper(str) 将字符串str转成大写
left(str,x) 返回字符串str中最左边的x个字符
right(str,x) 返回字符串str中最右边的x个字符
position(substr in str) 返回子串substr在字符串str中第一次出现的位置,从1开始计数
reverse(str) 返回字符串str颠倒后的值
trim(str) 取出字符串str的首尾所有空格
substring_index(str,splitStr,num) 返回字符串str根据splitStr进分割,num代表显示分割后的几个数据
例子:mysql> select substring_index('15,151,152,16',',',2);
+----------------------------------------+
| substring_index('15,151,152,16',',',2) |
+----------------------------------------+
| 15,151 |
+----------------------------------------+
substring(s,n,len) 从字符串s的第n位截取len个长度的字符串,从1开始计数,如果n为负数则从末尾开始截取
例子:mysql> select substring('darksnow',5,4);
+---------------------------+
| substring('darksnow',5,4) |
+---------------------------+
| snow |
+---------------------------+
replace(s,s1,s2) 使用字符串s2替代字符串s中所有的字符串s1
例子:mysql> select replace('darksnow','snow','ness');
+-----------------------------------+
| replace('darksnow','snow','ness') |
+-----------------------------------+
| darkness |
+-----------------------------------+
4.case_when函数
此函数具有两种格式:
(1)简单case函数,将某个表达式与一组简单表达式进行比较来确定结果
(2)case搜索函数,计算一组布尔表达式来确定结果
类似于Java中的switch多分支语句
格式一:简单case函数
case 表达式1
when 表达式2 then 表达式3
when 表达式4 then 表达式5
......
else 表达式6
end
格式一文字说明:
1.当case后面的表达式1和下面when后面任何的表达式相等
就会返回对应then后面的表达式,然后接下来的语句都将不执行。
2.如果case后面的表达式1和下面when后面任何的表达式
都不相等就会返回else后面的表达式。
格式一的例子:
case sex
when '1' then '男'
when '2' then '女'
else '妖'
end
------------------------------------------------------------------
格式二:case搜索函数
case
when 条件表达式1 then 表达式2
when 条件表达式3 then 表达式4
......
else 表达式5
end
格式二文字说明:
1.当when后面的条件表达式的值为true,则返回对应then后面的表达式,然后接下来的语句都将不执行。
2.当when后面的条件表达式的值为false,则继续向下执行when语句,
如果when后面的条件表达式都为false,则返回else后面的表达式
格式二的例子:
case
when sex = '1' then '男'
when sex = '2' then '女'
else '妖'
end
------------------------------------------------------------------
注意:如果上述两种格式都不指定else,并且都不满足条件则返回null
建表语句:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) COLLATE utf8_unicode_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `user` VALUES ('1', '张三', '18', '1');
INSERT INTO `user` VALUES ('2', '李四', '28', '1');
INSERT INTO `user` VALUES ('3', '王五', '38', '0');
INSERT INTO `user` VALUES ('4', '马六', '8', '0');
"需求:查询所有用户的信息去,将sex字段中值为1的数据显示为男,值为0的数据显示为女"
select id,name,age,
case sex
when 1 then '男'
when 0 then '女'
else '妖'
end as sex -- as sex代表取个别名
from user;
表设计练习
设计学生选课管理系统数据表(按照给定需求设计即可)
-
每个教师可以教多门课程
-
每个课程由一个老师负责
-
每门课程可以由多个学生选修
-
每个学生可以选修多门课程
-
学生选修课程要有成绩
(1)分析
当我们拿到一个需求后,首先应该分析这个需求中到底有多少名词,或者当前这个需求中可以抽象出具体几个E-R图中的实体对象。
分析需求中存在的实体使用矩形表示。
实体有:学生、课程、老师
当分析清除具体的实体之后,接着要分析实体具备哪些属性?属性使用椭圆形表示。
- 学生:学号,姓名等。
- 课程:课程编号,课程名称等。
- 老师:工号,姓名等。
最后就要考虑实体和实体之间的关系问题:
- 老师和课程之间:一对多关系,一个老师可以教授多门课程,一个课程只能由一个老师负责。
- 学生和课程之间:多对多关系,每个学生可以选修多门课程,每门课程可以被多个学生选修。
(2)关于设计学生选课管理系统的数据库表的E-R关系图如下所示

(3)创建表的SQL语句
画完E-R关系图之后,接下来我们就根据E-R图来创建具体的数据库表了。
学生选课管理系统的表创建:
思考:先创建哪张表?
不能先创建课程表,因为课程表需要有教师的工号,也不能创建中间表,因为中间表需要课程表和学生表的id,所以我们可以创建表的顺序如下:
1.教师表
2.课程表
3.学生表
4.学生课程表(中间关系表,但是记得要有成绩属性)
创建表的语句如下:
-- 1.教师表
create table teacher(
id int primary key auto_increment,
name varchar(20)
);
-- 2.课程表
create table course(
id int primary key auto_increment,
name varchar(20),
teacher_id int,
foreign key(teacher_id) references teacher(id)
);
-- 3.学生表
create table student(
id int primary key auto_increment,
name varchar(20)
);
-- 4.学生课程表(中间关系表,但是记得要有成绩属性)
create table student_course(
student_id int,
course_id int,
score double,
foreign key(student_id) references student(id),
foreign key(course_id) references course(id)
);
课堂作业
需求:设计一张学生表,请注意字段类型,长度的合理性
1.编号
2.姓名,姓名最长不超过10个汉字
3.性别,因为取值只有两种可能,因此最多一个汉字
4.生日,取值年月日
5.入学成绩,小数点后保留两位
6.邮箱地址,最大长度不超过64
7.家庭联系电话,不一定是手机号码,可能会出现"-"等字符
8.学生状态(用数字表述,正常,休学,毕业...)
create table stu(
id int,
name varchar(10),
sex char(1),
birthday date,
score decimal(5,2),
email varchar(64),
tel varchar(20),
status tinyint
-- 学生状态,微整型,0表示正常,1表示休学,2表示毕业
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号