


Redis一:概述和常见数据结构
1 概述
介绍
- Redis是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如string、hash、list、set、zset、bitmap、hyperloglog、geo等。Redis内置了复制(replication),LUA脚本(Luascripting),LRU驱动事件(LRUeviction),事务(transactions)和不同级别的磁盘持久化(persistence),并通过Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)
特点
- 内存数据库,速度快,也支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等多种数据结构的存储。
- Redis支持数据的备份(master-slave)与集群(分片存储),以及拥有哨兵监控机制。
- 支持事务
优势
-
性能极高 — Redis能读的速度是110000次/s,写的速度是81000次/s。
-
丰富的数据类型 — Redis支持String、List、Hash、Set、SortedSet 等数据类型操作。
-
原子操作 — Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行(事务)。
-
丰富的特性 — Redis还支持publish/subscribe、通知、key过期等特性。
对比
-
下面这三个中间件都可以应用于缓存,但目前市面上使用Redis的场景会更多,更广泛,其原因是:Redis性能高、原子操作、支持多种数据类型,主从复制与哨兵监控,持久化操作等
Ehcache Memcached Redis 许可证 开源免费 开源免费 开源免费 实现语言 Java C C 服务器系统 有JVM的系统 FreeBSD、Linux、OSX、Unix、Windows FreeBSD、Linux、OSX、Unix、Windows 数据类型 支持 不支持 支持多种,如string、hash、list等 客户端语言 Java Java、C、C++、.Net、Python、PHP等 Java、C、C++、.Net、Python、PHP、Go等
Redis的高并发
-
官方的
bench-mark数据:测试完成了50个并发执行100000个请求。设置和获取的值是一个256字节字符串。结果:读的速度是110000次/s,写的速度是81000次/s。Redis尽量少写多读,符合缓存的适用要求。单机redis支撑万级,如果10万+可以采用主从复制的模式。 -
高并发原理
-
Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
-
Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
-
Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
-
Redis存储结构多样化,不同的数据结构对数据存储进行了优化,如压缩表,对短数据进行压缩存储;再如,跳表,使用有序的数据结构加快读取的速度。
-
Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
-
Redis的单线程
- 原因
- 不需要各种锁的性能消耗:Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
- 单线程多进程集群方案:单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
- CPU消耗:采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU。但是如果CPU成为Redis瓶颈,或者不想让服务器其他CPU核闲置,那怎么办?可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
- 优劣
- 单进程单线程优势:(1)代码更清晰,处理逻辑更简单;(2)不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;(3)不存在多进程或者多线程导致的切换而消耗CPU。
- 单进程单线程弊端:(1)无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善。
IO多路复用技术
- redis采用网络IO多路复用技术来保证在多连接的时候,系统的高吞吐量。
- "多路"指的是多个socket连接,"复用"指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
- 这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路I/O复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈,补充:redis执行一条指令所用的时间是微秒级别的,即非常非常快),主要以上两点造就了Redis具有很高的吞吐量。
安装步骤
- 参考以前的一篇文章 Linux三:软件部署,软件可从该文章末尾链接获取。
2 数据结构
2.1 String
-
命令
- 给出时间复杂度,主要是将来考虑慢查询时,在 O(n) 的命令中排查(如
keys *),O(1) 的肯定不会产生慢查询。
命令 含义 时间复杂度 set key value
get key
del key设置 key-value
获取 key
删除 keyO(1) incr key
decr keykey 自增1,若 key 不存在,自增后 get(key) = 1
key 自减1,若 key 不存在,自减后 get(key) = -1O(1) incrby key n
decrby key nkey 自增 n,若 key 不存在,自增 后 get(key) = n
key 自减 n,若 key 不存在,自减 后 get(key) = -nO(1) set key value
set key value xx
setnx key value
setex key seconds valuekey 无论是否存在都设置
key 存在才设置(可以变相理解为 update 操作)
key 不存在才设置(可以变相理解为 insert 操作)
key 设置为 value,且 seconds 秒后过期O(1) mget key1 key2 key3 ...
mset key1 value1 key2 value2 key3 value3 ...批量获取 key (原子操作)
批量设置 key-valueO(n) getset key newValue 设置 newValue 并返回 oldValue O(1) append key newValue 向 oldValue 中追加 newValue O(1) strlen key 返回该key对应的value字符串长度 (注意中文) O(1) incrbyfloat key n 把 key 对应的 value 增加 n
(没提供浮点数自减命令,但传个负数就可以达到效果)O(1) getrange key start end 获取key对应value字符串指定下标 的所有值 O(1) setrange key index value 设置key对应value字符串指定下标 所对应的值 O(1) - 给出时间复杂度,主要是将来考虑慢查询时,在 O(n) 的命令中排查(如
-
"发送 n 次 get 命令" 与 "直接 mget 后面 n 个key" 的区别
- n次get时间 = n次网络时间 + n次命令时间
- mget时间 = 1次网络时间 + n次命令时间
- 因为大部分情况下,redis在远程服务器,n次网络时间开销比较大。
- 尽量避免发送 n 次 get/set 请求,特别是 for 循环中有 set/get 操作!正确做法是使用 mget/mset 或者管道 pipeline。
2.2 Hash
-
命令
-
所有 hash 命令均以 h 开头 !
-
牢记 redis 单线程, hgetall 尽量少用。若是有一万个 field ,那么 hgetall 则会很慢导致 后面命令也无法执行,一般只取所需 field 即可,使用 hmget 命令完成。
命令 说明 时间复杂度 hset key field value 设置 hash key 对应的 field 的 value O(1) hget key field 获取 hash key 对应的 field 的 value O(1) hdel key field 删除 hash key 对应的 field 的 value O(1) hexists key field 判断 hash key 是否有 field O(1) hlen key 获取 hash key field 的数量 O(1) hmget key field1 field2 ... 批量获取 hash key 的一批 field 对应的值 O(n) hmset key field1 value1 field2 value2 ... 批量设置 hash key 的一批 field value O(n) hgetall key 返回 hash key 对应所有的 field 和 value O(n) hvals key 返回 hash key 对应所有 field 的 value O(n) hkeys key 返回 hash key 对应所有的 field O(n) hsetnx、hincrby、hincrbyfloat 同string用法,略 -
-
用户信息存储三种方案对比
方案 所用数据类型 优点 缺点 key 为 userId,value 为 json 串或者 xml 等,反正就是 value 直接存一大坨内容 string 编程简单,可能节约内存 序列化开销,设置某个属性要操作整个数据 key 为 userId + 属性拼接的字符串,value为值
(如user1:name lisi, user1:age 20)string 直观,可以部分更新 内存占用较大,key较为分散 key 为 userId,field 为 属性(姓名、年龄),value 为对应的值 hash 直观,节约空间,可以部分更 新 编程稍微复杂,TTL 不好控制
2.3 List
-
命令
l代表从左边操作,r代表从右边操作
命令 含义 时间复杂度 lpush / rpush key value1 value2 ... valueN 从左边/右边列表插入 1~N 个值 O(1~N) linsert key before / after value newValue 在 list 指定的 value 前/后 插入 newValue O(n) lpop/rpop key 从列表左边/右边弹出一个 item O(1) lrem key count value 根据 count 值,从列表中删除所有 value 相等的项
count > 0,从左到右,删除最多count个 value相等的项
count < 0,从右到左,删除最多 Math.abs(count)个value相等的项
count = 0,删除所有 value 相等的项O(n) ltrim key start end 按照索引范围修剪列表 O(n) lrange key start end 获取列表指定索引范围所有 item,该命令中 start end 均包含,即 [start,end] O(n) lindex key index 获取列表指定索引的 item O(n) llen key 获取列表长度 O(1) lset key index newValue 设置列表指定索引值为 newValue O(n) blpop/brpop key timeout lpop/rpop阻塞版本,timeout是阻塞超时时间,timeout=0为永远不阻塞 O(1)
2.4 Set
-
set特点:无序、无重复、支持集合间操作
-
命令
- set命令均以 "s" 开头
- spop 从集合中弹出一个元素, srandmember 随机取一个元素但不会破坏集合结构
命令 含义 时间复杂度 sadd key element 向集合key添加element (如果element已存在添加失败) O(1) srem key element 将集合key中的element移除掉 O(1) scard key 计算集合 key 中元素个数 O(1) sismember key element 判断 element 是否在集合 key 中 srandmember key 从集合 key 中随机取出一个元素 smembers key 取出集合 key 所有元素 spop key 从集合 key 中弹出一个元素 sdiff 差集 sinter 交集 sunion 并集
2.5 ZSet
-
set、zset 和 list 对比
set zset list 无重复元素 无重复元素 有重复元素 无序 有序 有序 element element + score element -
命令
-
zset 命令都以 "z" 开头
命令 说明 时间复杂度 zadd key score element 添加(可以多个) O(logN) zrem key element 删除(可以多个) O(1) zscore key element 获取分数 O(1) zincrby key incrScore element 增减元素的分数 (传负值即为减少) O(1) zcard key 元素的总个数 O(1) zrank key element
zrevrank key element获取元素从小到大 的排名
获取元素从大到小 的排名zrange key start end withScores
zrevrange key start end withScores获取指定范围内从 小到大的元素
获取指定范围内从 大到小的元素O(logN + m)
N是元素个数
m是要获取的范 围内元素个数 (如3个、5个)zrangebyscore key start end withScores zrevrangebyscore 返回指定分数范围 内的升序元素 降序 zcount key minScore maxScore 获取指定范围内的 元素个数 O(logN + m) zremrangebyrank key start end 删除指定排名内的 升序元素 O(logN + m) zremrangebyscore key minScore maxScore 删除指定分数内的 升序元素 O(logN + m) zinterstore 交集 zunionstore 并集
-
2.6 Bitmap
-
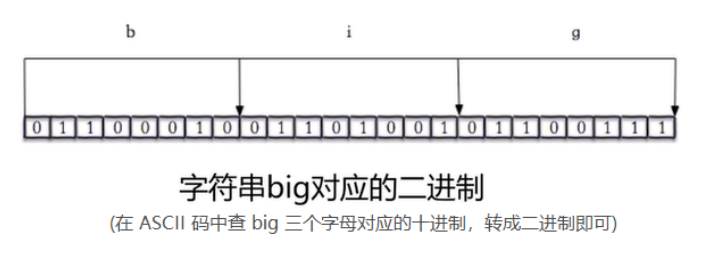
英文单词
big对应的二进制![]()
# # 设置一个 string 型 key-value,key = mystr,value = big 127.0.0.1:6379> set mystr big OK 127.0.0.1:6379> getbit mystr 0 # 由图片可知,偏移量(可以理解成下标)为0时对应的bit为0 (integer) 0 127.0.0.1:6379> getbit mystr 2 # 由图片可知,偏移量为2时对应的bit为1 (integer) 1 -
命令
命令 说明 getbit key offset 获取位图指定索引的值 setbit key offset value 给位图指定索引设置值(此处 value 只能为 0 或者 1) bitcount key [start end] 获取位图指定范围内位值为1的个数(start 到 end,单位为字 节,如果不指定就是获取全部) bitop op destkey key [key ... ] 做多个位图的 and(交集)、or(并集)、not(非)、xor(异或)操作并 将结果保存在 destkey 中 bitops key targetBit [start] [end] 计算位图指定范围第一个偏移量对应的值等于 targetBit 的位置
(start 到 end,单位为字节,如果不指定就是获取全部)
案例:独立用户统计
-
案例一:假设某网站一亿用户,每天5千万人独立访问。统计独立用户。
-
可以使用 set 和 bitmap 解决,现两者对比如下
数据类型 每个 userId 占用空间 需要存储的用户量 全部内存量 set 32位(假设userId是整形,实际很多网站 用的是长整型) 五千万 32位 * 五千万 = 200MB bitmap 1位 一亿 1位 * 一亿 = 12.5MB -
上面是一天的对比,若是扩大到一年,见下图
一天 一月 一年 set 200M 6G 72G bitmap 12.5M 375M 4.5G
-
-
案例二:假设某网站一亿用户,每天100万人独立访。统计独立用户。
数据类型 每个 userId 占用空间 需要存储的用户量 全部内存量 set 32位 一百万 32位 * 一百万 = 4MB bitmap 1位 一亿 1位 * 一亿 = 12.5MB - 此时 Set 占用的空间又比 BitMap 的少了
-
总结::综上可以看出,set 与 bitmap 没有优劣之分,要看实际情况选择方案。
2.7 HyperLogLog
-
基于 HyperLogLog 算法:极小空间完成独立数量统计。
-
HyperLogLog 数据类型本质还是字符串
-
命令
命令 说明 pfadd key element [element ... ] 向 hyperloglog 添加元素 pfcount key [key ... ] 计算 hyperloglog 的独立总数 pfmerge destKey sourceKey [sourceKey ...] 合并多个 hyperloglog -
样例
127.0.0.1:6379> pfadd myHyperLogLog "uuid-1" "uuid-2" "uuid-3" "uuid-4" (integer) 1 127.0.0.1:6379> pfcount myHyperLogLog (integer) 4 127.0.0.1:6379> type myHyperLogLog string # 返回类型是 string ,验证上面"本质还是字符串"这句话 -
统计独立用户内存消耗:假设某网站一亿用户,每天100万人独立访。统计独立用户。(即百万独立用户案例,条件同上面的案例二)
数据类型 一天 一月 一年 HyperLogLog 15KB 450KB 15KB * 365 ≈ 5MB - 一天消耗 15KB ,比 set 和 bitmap 消耗要少的多。
-
使用经验
- 是否能容忍错误?(错误率:0.81%)
- 是否需要单条数据?
- 总结:HyperLogLog 也不是最优的,要根据实际情况选择。能否容忍错误、是否需要单条数据、 是否需要很小的内存来解决问题?
2.8 Geo
-
GEO 是什么
- GEO(地址信息定位):存储经纬度,计算两地距离,范围计算等
- 可以用来做微信摇一摇、按照距离推荐周围酒店等等
- 补充:geo 是 redis 3.2+ 版本才提供的功能
- 补充:geo 是使用 zset 集合实现的
-
命令
命令 说明 geoadd key longitude latitude member
[longitude latitude member ...]添加地理位置信息
longitude:经度,latitude:纬度geopos key member [member ... ] 获取地理位置信息 geodist key member1 member2 [unit]
unit: m(米)、km(千米)、mi(英里)、ft(尺)获取两个地理位置 georadius
georadiusbymember
(命令比较长,详情见下面图片)获取指定经纬度范围内的地理位置信息集合
获取指定member范围内的地理位置信息集合zrem key member 删除
geo 没有提供删除api,因为是使用zset实 现的,因此使用zset命令即可![]()

2.9 发布订阅
-
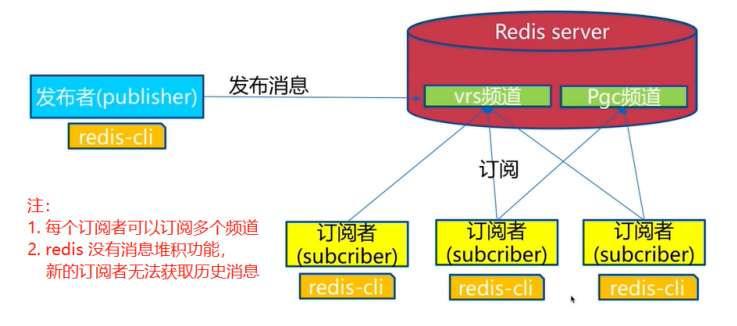
包含三种角色 发布者(publisher)、订阅者(subscriber) 和 频道(channel) 【类似于生产者—消费者模型 】
-
图解
![]()
-
命令
命令 说明 publish channel message 发布者在频道中发布消息 subscribe [channel ...] 订阅者订阅一个或多个频道 unsubscribe [channel ...] 订阅者取消订阅一个或多个频道 psubscribe [pattern ...] 订阅模式 punsubscribe [pattern ...] 退订指定模式 pubsub channels 列出至少一个订阅者的频道 pubsub numsub [channel ...] 列出指定频道的订阅者数量 pubsub numpat 列出被订阅模式的数量
2.10 通用命令
- 通用命令有很多,常见的几个如下
| 命令 | 含义 | 时间复杂度 |
|---|---|---|
| keys | keys * 查看所有key |
O(n) |
| dbsize | 查看 key 的个数 | O(1) |
| exists key | 判断 key 是否存在 | O(1) |
| del key [key2 key3 ...] | 删除 key | O(1) |
| expire key seconds | 设置 key 几秒后过期 | O(1) |
| persist key | 持久化 key (让将过期的 key 变为永不过期) | O(1) |
| type key | 判断 key 的数据类型 | O(1) |
- 更多命令详解,见redis官网 Redis 命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号