
2019年北航OO第一次博客总结
一、基于度量对程序结构的分析
1. 第一次作业
1.1 基于类的分析的度量
首先,基于类的属性个数,方法个数,每个方法的规模,每个方法的控制分支数目,类总代码规模等特征对本次作业的结构进行分析。

1.2 基于类间内聚和耦合的度量
我使用了MetricsReloaded插件来对代码的复杂度进行了分析。
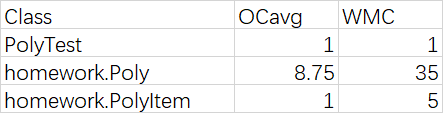
还有对于方法的复杂度分析由于篇幅原因没有贴出来,主要的指标为ev,iv,v三个指标,分别代表基本复杂度、模块设计复杂度以及模块判定结构复杂度,ev大代表代码非结构化程度高,难以模块化和维护。iv大代表模块间耦合度高,模块间难以隔离与复用,v大表示代码独立路径条数多,难于测试和维护。在做面向对象度量时,我们经常采用ck度量(Chidamber Kemerer)来度量耦合,内聚,封装等等特征。上表中wmc代表的是类的方法权重,表示一个类中所有方法的复杂度之和。显然越大说明越复杂。
1.3 UML图及结构点评
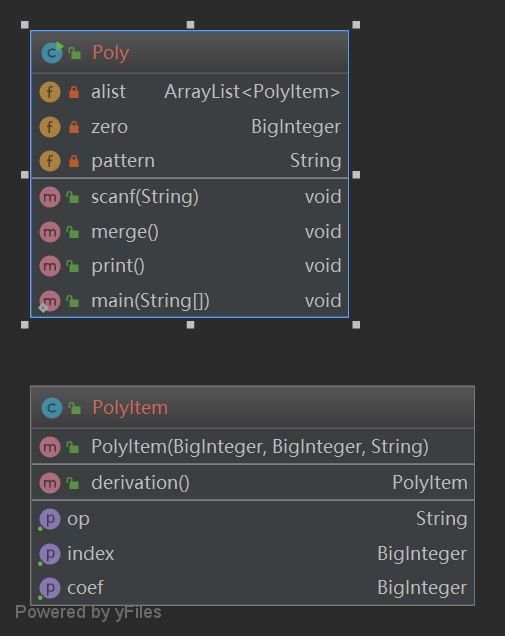 由于是第一次作业,因此对于面向对象的思想还不是特别熟悉,我这次将main类与Poly类写到了一起,其实应该分离,一个多项式的类,一个项的类,一个main入口类。整体来讲结构不是很好,而且有两个比较长的方法同时分支较多,同时也就造成了它们的独立路径数较多,模块复杂度较高。
由于是第一次作业,因此对于面向对象的思想还不是特别熟悉,我这次将main类与Poly类写到了一起,其实应该分离,一个多项式的类,一个项的类,一个main入口类。整体来讲结构不是很好,而且有两个比较长的方法同时分支较多,同时也就造成了它们的独立路径数较多,模块复杂度较高。
2. 第二次作业
2.1 基于类的分析的度量
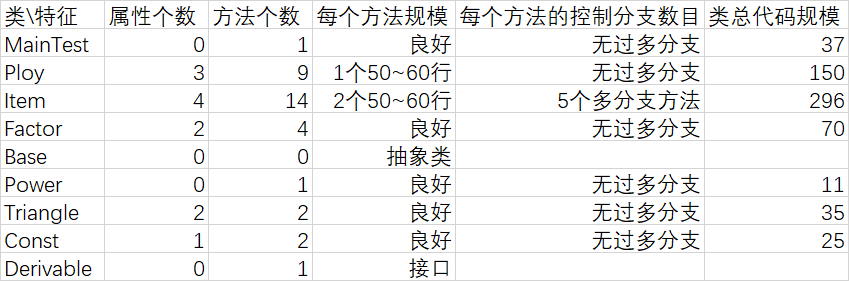
2.2 基于类间内聚和耦合的度量

我的高复杂度方法体现在输入处理,输出处理以及化简上,这次作业如何有效的化简是一个难点。
2.3 UML图及结构点评
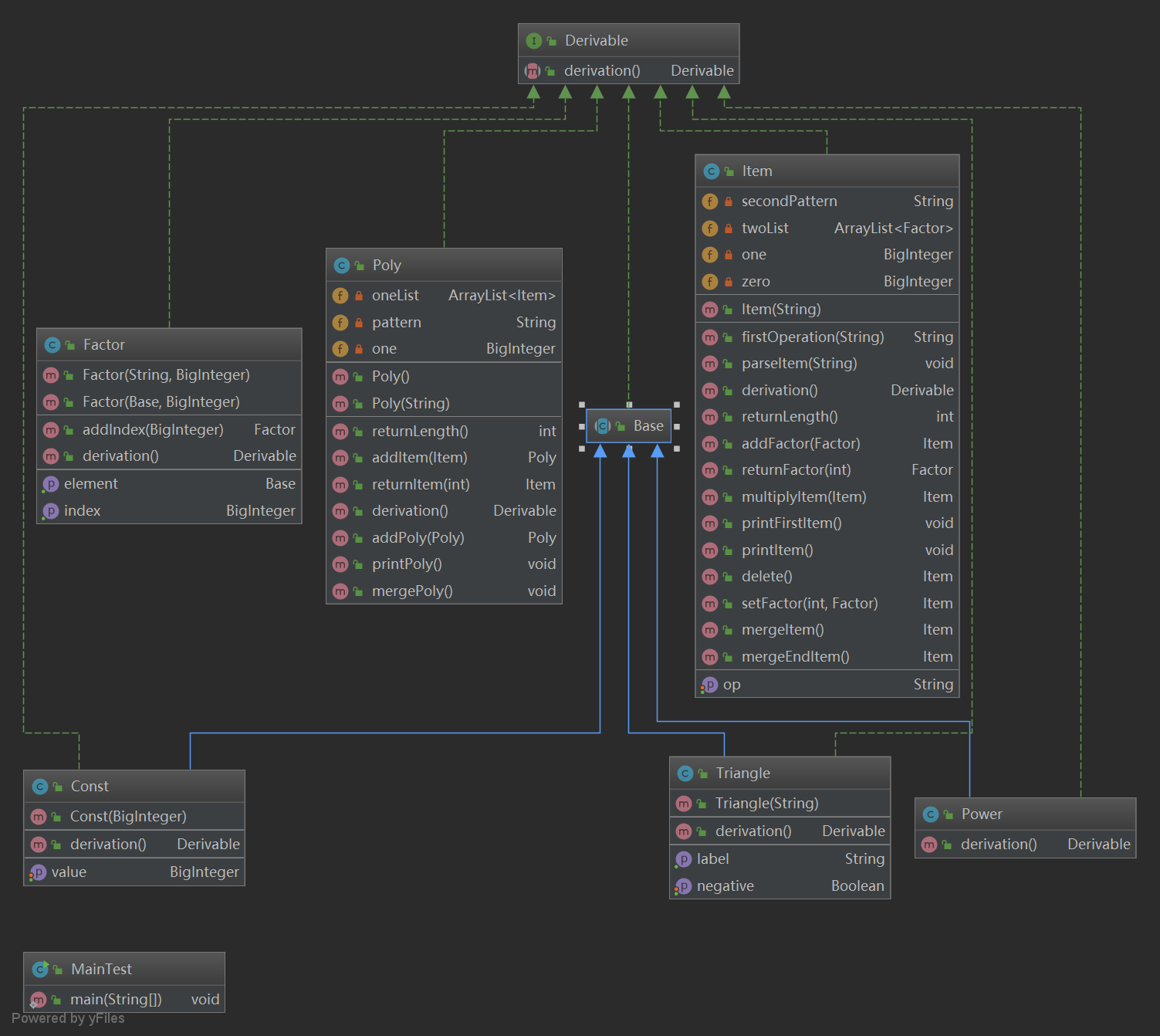 本次作业的设计较为体现了面向对象的思想,设计了一个main入口类,多项式类,项类,因子类,以及其中由于因子是由底数和指数组成的,而指数又有多种形式,故设计了一个底数的抽象类base,将常数类const,幂函数类power,三角函数类triangle作为了base的子类,这样就可以将一个多项式一点点解析成项,因子,底数,指数等等。同时,由于每一个类都有共同的特点就是可求导,因此我设计了一个求导的接口Derivable,所有的类都实现了这个接口,这符合了java面向接口编程的思想,同时也提升了代码的规范性。
本次作业的设计较为体现了面向对象的思想,设计了一个main入口类,多项式类,项类,因子类,以及其中由于因子是由底数和指数组成的,而指数又有多种形式,故设计了一个底数的抽象类base,将常数类const,幂函数类power,三角函数类triangle作为了base的子类,这样就可以将一个多项式一点点解析成项,因子,底数,指数等等。同时,由于每一个类都有共同的特点就是可求导,因此我设计了一个求导的接口Derivable,所有的类都实现了这个接口,这符合了java面向接口编程的思想,同时也提升了代码的规范性。
3. 第三次作业
3.1 基于类的分析的度量
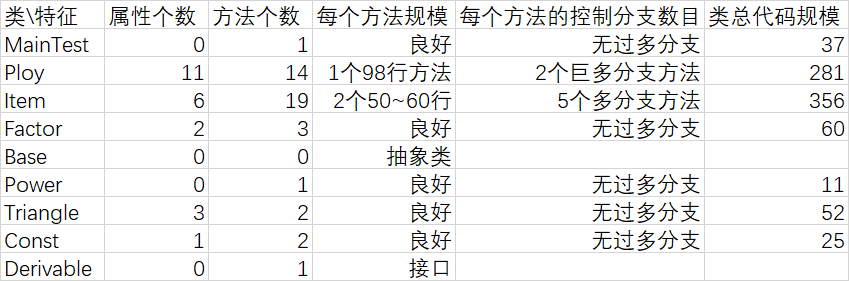
3.2 基于类间内聚和耦合的度量

发现我的高复杂度的方法全部都是对于输入处理上,由此可见我的输入处理的不太好,写的十分面向过程且十分容易出错。
3.3 UML图及结构点评
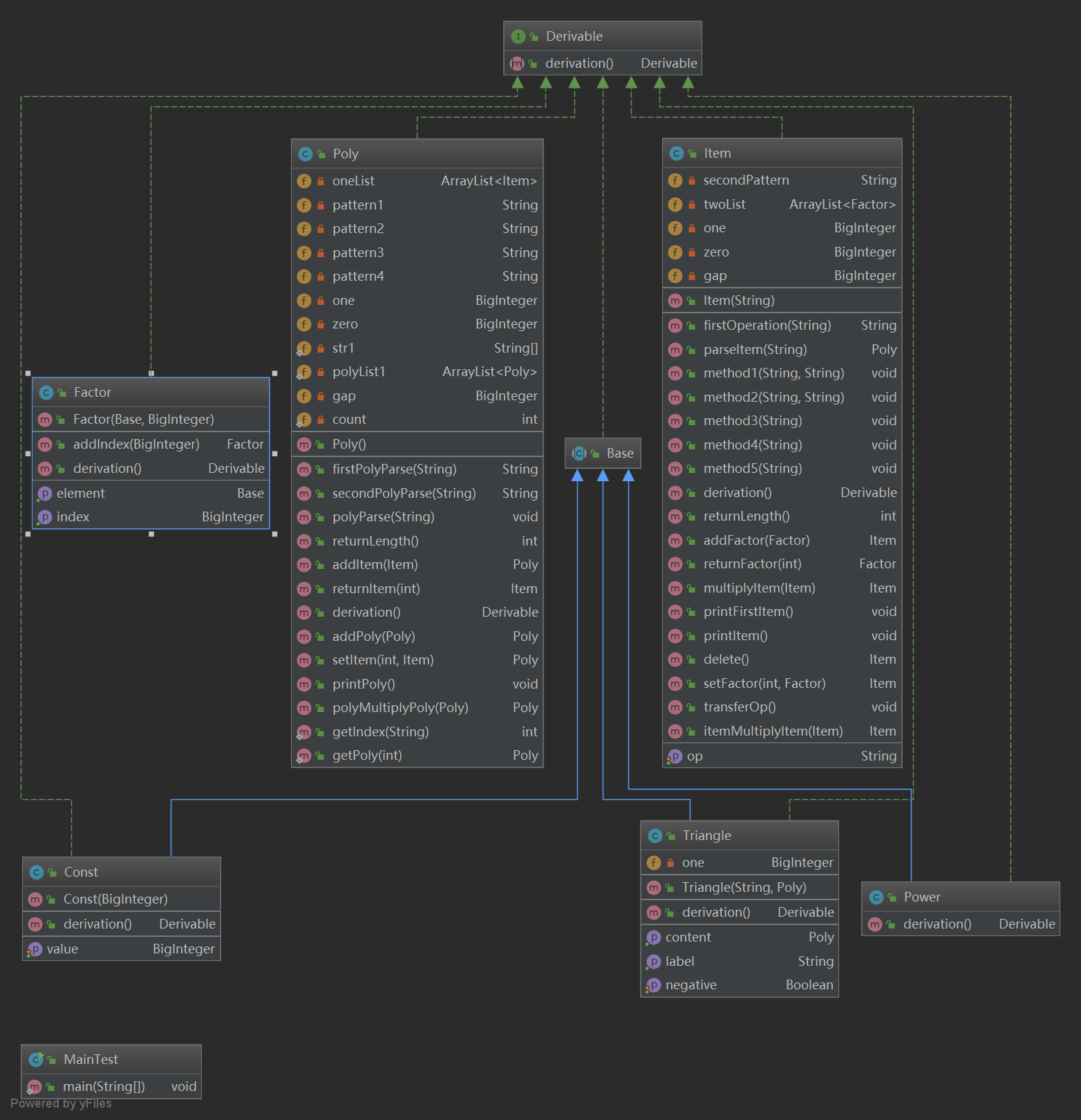 本次作业的架构和上一次作业是完全一致的,因为上次作业时我就考虑到了程序可扩展性的特点。然而本次作业在加了表达式因子和嵌套因子后显得这个架构有一些问题。求导部分利用递归向下求导的方式倒是不难实现,此次作业最难的输入部分我处理的不是很好。这次输入的难点主要是出现了表达式因子和嵌套,我们如何用正则表达式来正确的识别和解析。我的想法是先找到所有非三角函数括号中最内层的括号,将其解析为一个多项式,这时再解析出该多项式内部的三角函数,把三角函数括号中嵌套的多项式因子解析到三角函数的属性中去,重复这个步骤直到没有括号为止。整个过程虽然可以实现但是十分复杂,十分面向过程且会有多分支,行数非常多的方法,复杂的正则表达式的存在。后来在讨论课上听说的用工厂模式或一个parser的类可以更好的实现该输入解析过程,parser类里面分别有对poly,item,factor的解析方法,高内聚低耦合避免了一大串if-else的出现。
本次作业的架构和上一次作业是完全一致的,因为上次作业时我就考虑到了程序可扩展性的特点。然而本次作业在加了表达式因子和嵌套因子后显得这个架构有一些问题。求导部分利用递归向下求导的方式倒是不难实现,此次作业最难的输入部分我处理的不是很好。这次输入的难点主要是出现了表达式因子和嵌套,我们如何用正则表达式来正确的识别和解析。我的想法是先找到所有非三角函数括号中最内层的括号,将其解析为一个多项式,这时再解析出该多项式内部的三角函数,把三角函数括号中嵌套的多项式因子解析到三角函数的属性中去,重复这个步骤直到没有括号为止。整个过程虽然可以实现但是十分复杂,十分面向过程且会有多分支,行数非常多的方法,复杂的正则表达式的存在。后来在讨论课上听说的用工厂模式或一个parser的类可以更好的实现该输入解析过程,parser类里面分别有对poly,item,factor的解析方法,高内聚低耦合避免了一大串if-else的出现。
二、Bug分析
1. 第一次作业
第一次作业我的强测没有出现WA的情况,但是被hack了12次(2同质),分别是\\s+匹配到\t和空格外的字符的情况、以及直接输入空格程序crash的情况,程序crash的原因是我在得到字符串之后直接进行了input.trim()操作,导致输入input变为空串程序crash,有两种更改方式,一种是直接把main方法里面的所有内容用try-catch保住,确保程序不会出现crash(这也是我后面两次作业的写法),另一种方法是在trim()后面再判断一次串是否为空。对于另外一个bug,我的正则里面写的是[ \\t]*然而还是出现了bug,这与我程序的设计结构密切相关,因为我再刚刚读入input的时候就用trim()去掉了两边的空白符,这样导致输入字符串两边的\v和\f无法有效的识别WF,造成了bug的出现。我的修改方式是先看所有的输入字符是否有非法字符,如果有的话直接输出WF即可。
2. 第二次作业
第一次作业我的强测没有出现WA的情况,但是也被hack了3次(2同质),分别是在输入符号处理中的if表达式中的||手误写成了&&,和对于输入错误的匹配没有识别出WF。仔细想想,这与我的设计结构也有着千丝万缕的联系。我对于输入的处理是在去掉了输入两边的空白字符后依据此时input.CharAt(0)来确定在前面添加"+"或者"+0",然而我没考虑到*x若在前面"+0"会造成本来是WF的数据变成合法,因此导致了bug。另外一个bug就是典型的一大段if-else造成的键盘误操作,这也体现了减少分支数量降低代码复杂度的必要性。
3. 第三次作业
第三次作业我的强测WA两个点,被hack了10次(强互测加起来2同质),分别是输入匹配时正则表达式少了一个[ \\t]*造成的有空格导致不匹配以及一个符号出现了问题。这两个问题的产生就与我的设计非常密切的相关了。我写了4个正则,其中最大的正则有6行,如此长的正则难免会不小心失误,写小正则把问题分开分析是避免这类错误的一个很好的方式。而另外一个符号错误则完全是由于我的输入写得太过复杂,括号来回匹配的逻辑,比如解析一个item,会返回一个poly.解析一个factor也会返回poly,而每个item都有其固定的符号,这次Bug的出现就是因为在解析item返回poly的时候没有考虑原来item的符号,而默认"+"造成了错误。由此可见,面向对象的设计模式,封装的好处就是减少耦合,减少出错点。
三、Hack策略
1. WF
前两次作业错误主要集中在WF上,这时候就可以手动设计测试样例,比如全空格,空串,只输入常数,输入x^0,0*x,si n(x),sin ( x ),+++1,++ 1,\f\v,BigInteger,爆栈,......等等,因为前两次作业正确性的实现上并不难,主要大家的出错点在对WF的处理上,因此我的这种策略有效性也很高,前两次作业共提交7个测试样例hack18人次。
2. 正确性问题
第三次作业强调正确性的问题,我也从正确性的问题入手,具体方法就是对于指导书上对本次实验要求的所有功能,先分别构造测试数据,在将各种模式组合起来,比如sin()里面有表达式,里面还有嵌套的sin(),再加一些项乘起来之类的。覆盖所有的情况覆盖所有的功能就能找出bug。由于第三次作业大家基本都没怎么优化,所以直接看输出结果很难看出正误,因此可以把每位被测者的输出结果赋上一个x值(比如x=1.1)比较不同被测者输出结果的值是否相等,若不相等显然是出现了问题。
3. 根据程序找bug
这种方法难度较大,主要原因是部分代码可读性较差,结构不清晰,等等。当然如果能看懂对方程序的话肯定是更容易从根源处找到bug。通过白盒测试,对复杂的类进行单元测试来寻找bug。
四、Applying Creational Pattern
1. 工厂模式
工厂模式(Factory Pattern)是Java中最常用的设计模式之一,这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。因此,对于本次作业可以使用工厂模式来创建表达式,项,因子,我们只需定义一个创建对象的接口,让实现了该接口的子类自己决定实例化哪一个工厂类。在我们明确地计划不同条件下创建不同实例时,工厂模式将十分管用。
2. 抽象工厂
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。超级工厂又称为其他工厂的工厂,在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。系统的产品有多于一个的产品族,而系统只消费其中某一族的产品时,可以使用抽象工厂作为所有工厂的抽象父类,这样我们就不用花费时间在选择接口上了。
五、总结与展望
1. 总结
4周时间过去了,OO也过去了第一单元,早就听说了OO的恐怖,如今也确实是体验了一番。总体来讲第一单元的学习还算满意,测试方面仍需加强,另外就是面向对象的思想还需不断的培养。第一单元其实主要还是java的入门,帮助我们更加熟悉java的使用。还有就是感觉今年的OO确实感觉要比往届好了不少,公测分占主要的情况下大体上保证了课程的公平,分ABC组互测也避免了一些悲惨的情况,总体来讲OO课在不断变好,在此感谢助教和老师的付出!
2. 展望
前路漫漫,道阻且长。后面还有多线程等等很难的知识和作业在等着我们,希望我们能继续努力,在本学期结束时能真正有很大的收获。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号