
Flink中的CEP复杂事件处理 (源码分析)
其实CEP复杂事件处理,简单来说你可以用通过类似正则表达式的方式去表示你的逻辑,表现能力非常的强,用过的人都知道
开篇先偷一张图,整体了解FlinkCEP中的 一种重要的图 NFA
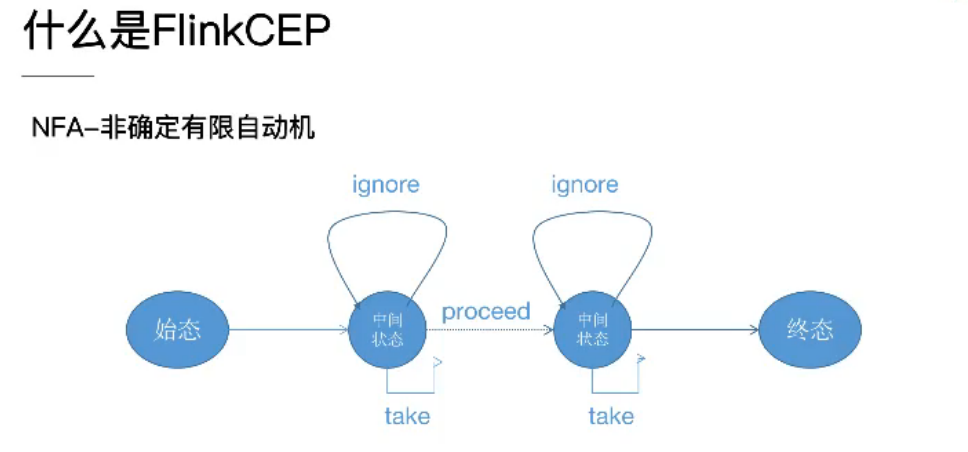
FlinkCEP在运行时会将用户的逻辑转化成这样的一个NFA Graph (nfa对象)
graph 中包含状态(Flink中State对象),以及连接状态的边(Flink中StateTransition对象)
当从一个State跳变到另一个State时需要通过一条边StateTransition,这条边中包含一个Condition对象包含了用户的逻辑就是我们用户代码中.where()中返回Boolean的方法
也就是说Condition对象中包含是否可以完成状态跳变的条件,A状态要跳变到B状态就必须满足连接AB的边中的条件(边StateTransition对象属于B state)
其中边StateTransition分为三种
take: 状态满足跳变条件后直接跳变到B状态
ignore: 状态满足跳变条件以后又回到原来状态,状态保持不变
process: 这条边可以忽略也可以不忽略
后面源码分析的时候可以看到他们之间的区别
接着从源码来看一下如何用这个NFA图实现Flink中的CEP复杂事件处理的
因为CEP在Flink中被设计成算子的一种而不是单独的计算引擎,所以直接找到CepOperator.java中
来看一下它的初始化Open()

这里看到有一个NFAFactory的工厂创建了一个NFA,这里的这个工厂是在Driver端通过用户编写的代码返回的Patten对象转换得到的,也就是用户env.exection()的时候解析的,工厂对象还包含了用户所有的State集合
继续,在createNFA()方法中
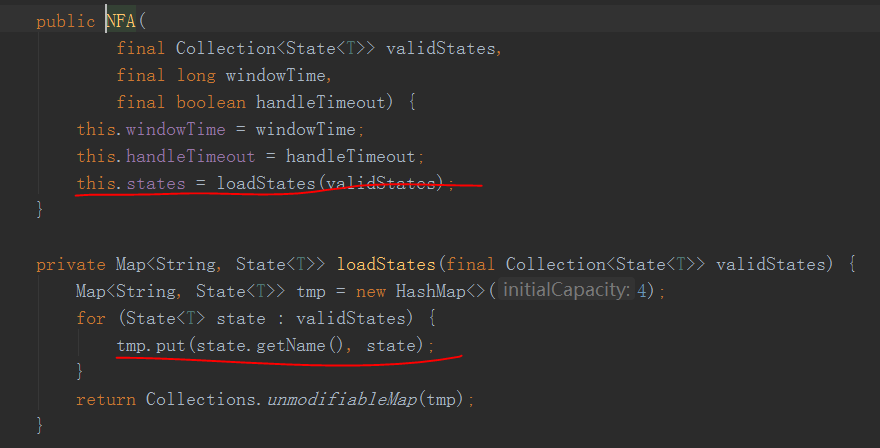
将工厂中的所有顶点也就是状态States放到了NFA对象的一个Map中

Key为这个States的Name(其实就是用户代码中的.next("Name"))
接着看CepOperator.java中接收到数据processElement()方法做了什么

这里是处理时间的,这里其实就是直接执行了,这里就不看了,直接看事件时间是如何处理的
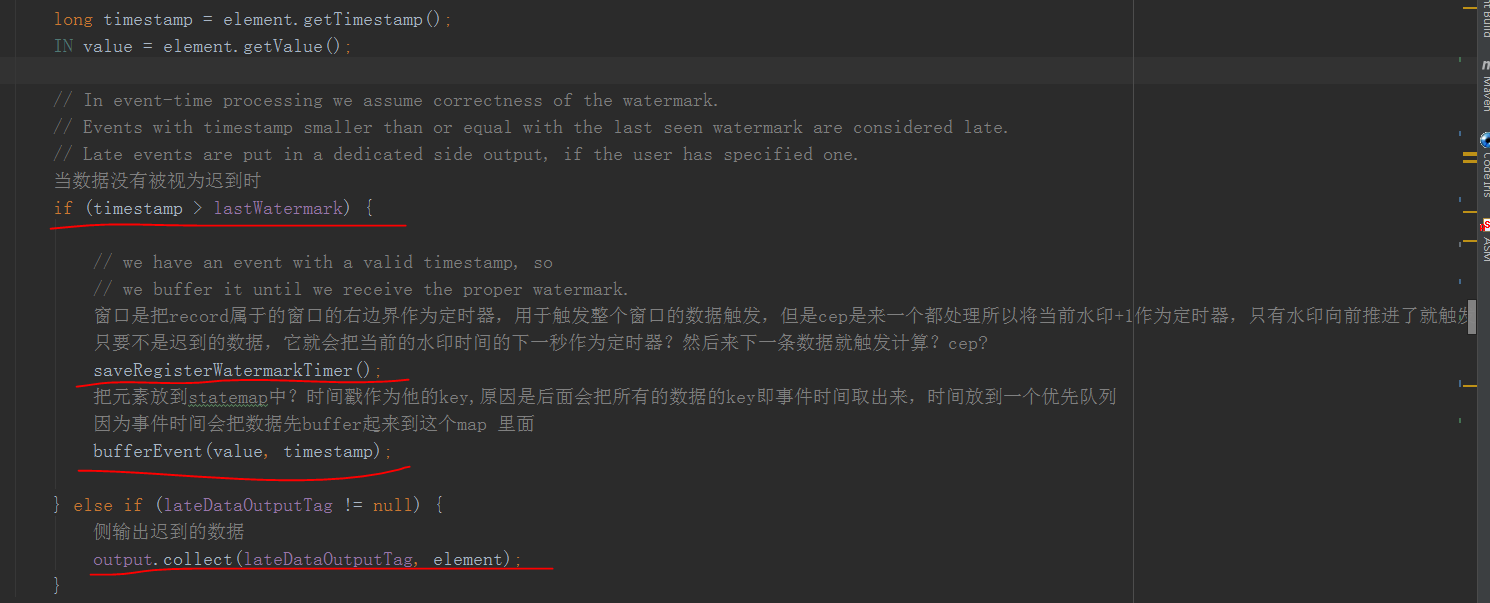
先是取出数据的事件时间,判断是不是小于当前水印了,小于这条数据就证明迟到太久了,如果有侧输出丢给侧输出处理,没有就直接丢弃了,和WindowOperater一样
然后看saveRegisterWatermarkTimer()方法

将 (当前水印+1) 注册成了一个定时器timer用于触发计算,和window原理一样(不知道的可以看看前面的文章)
这里主要是因为窗口是一批一批触发而CEP需要逐个触发,所以用(当前水印+1)当做定时器,也就是说只要水印往前推进了就触发推进这段时间的所有计算
然后bufferEvent()将这条数据加入到了一个Queue中
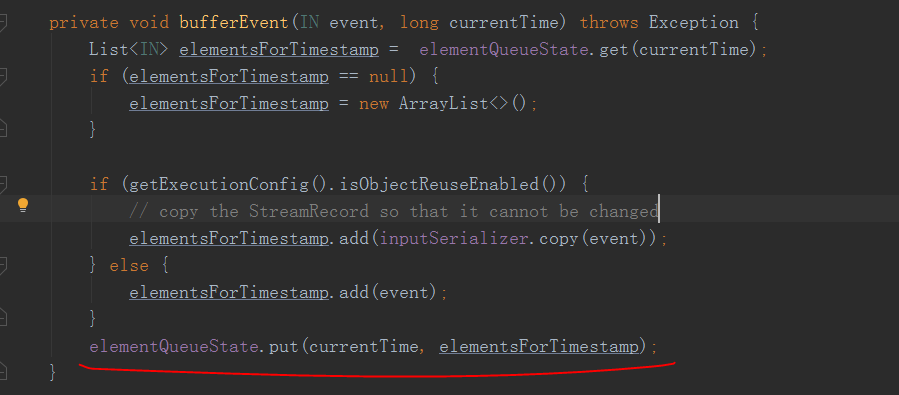
现在来看触发计算的具体逻辑
来到onEventTime()方法中
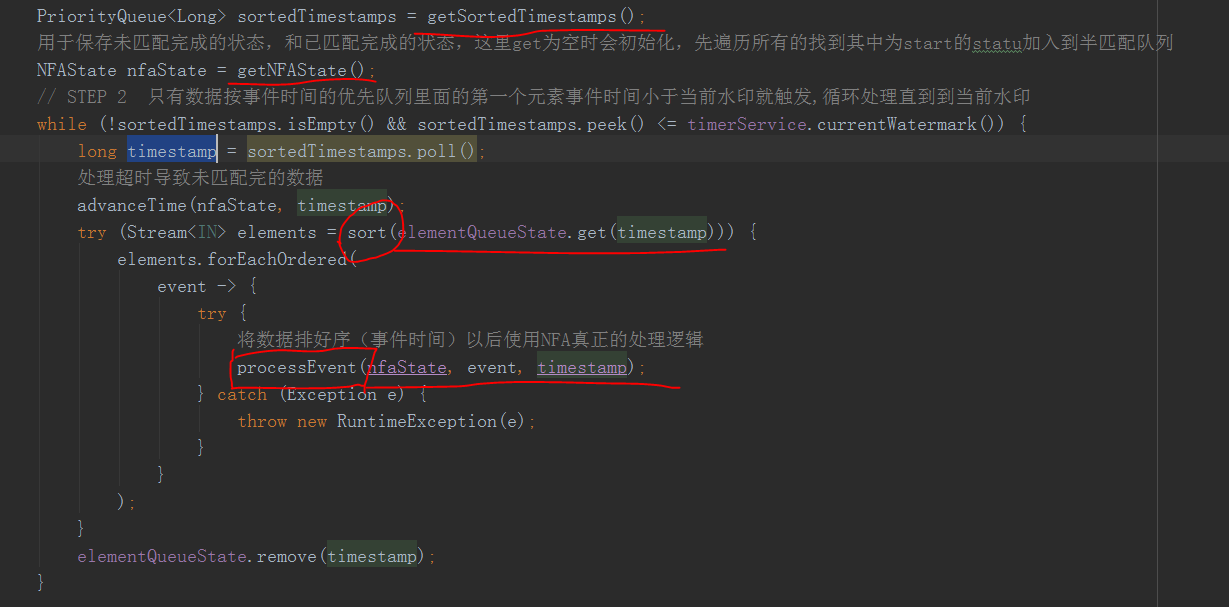
先是拿到一个用时间排序的优先队列PriorityQueue里面就是排序的事件时间
getNFAState()这里比较重要,这里通过nfa得到了一个nfaState具体来看一下

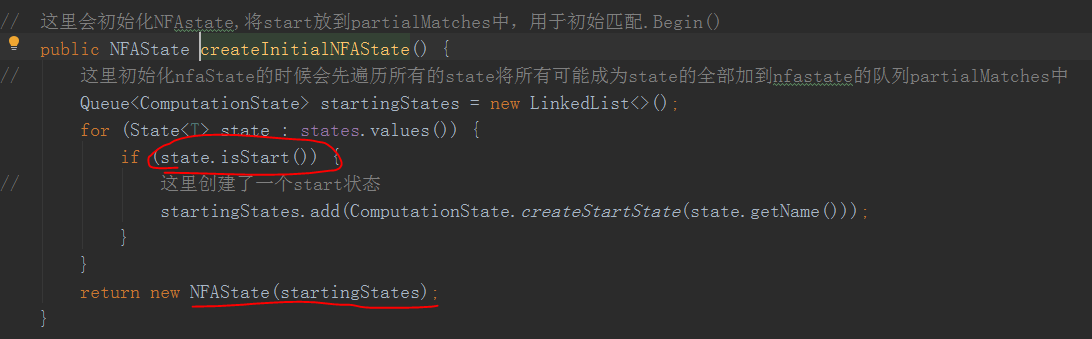

这里这个NFAstate会初始化,NFAstate里面包含了一个ComputationState的queue,主要目的是用于每条数据来的时候都会去遍历这个queue,看这条数据是否能匹配上里面的state如果匹配上了就更新下一个准备匹配的状态
这里就知道他为什么NFAstate初始化的时候会把用户所有的State中可以作为开始start的状态放queue了吧
因为一开始没数据,当来数据的时候我要判断这条数据是不是属于我CEP的Begin头,这个state也就是我们用户的begin()方法,所以才把所有的可以作为开始的状态都放到这个PartialMatches这个queue中去,这个PartialMatches后面计算的时候会用到,注意
NFAState的初始化就讲完了
继续,回到处理逻辑
然后根据事件时间作为key拉取前面将数据放入的那个queue中数据,返回的是一个List包含这个事件时间的所有数据
然后排序,这里是二次排序,第一次排序是用的事件时间,二次排序排的是同一时间的数据按什么顺序处理
然后这里ProcessEvent()方法就是具体执行的逻辑了,这里同时会把刚刚初始化好的NFAState传递进去

一开始会获取一个共享的缓冲区主要是为了减小CEP重复数据存储的内存占用,这里不讲了因为CEP论文里面有,比较复杂
这里process()方法就是具体逻辑了,返回了一个map这个map包含了process()方法这条数据匹配成功结束的数据也就是结果,而processMatchedSequences(patterns, timestamp)就是执行用户的.select()逻辑了
既然这里就得到了CEP匹配的结果,来看下具体计算逻辑nfa.process()

这里又初始化两个优先队列
分别用于
newPartialMatches 装nfa匹配到一半没有结束数据,也就是半匹配,
potentialMatches 装成功匹配完成的数据,用于返回,调用用户的方法去处理结果
接着
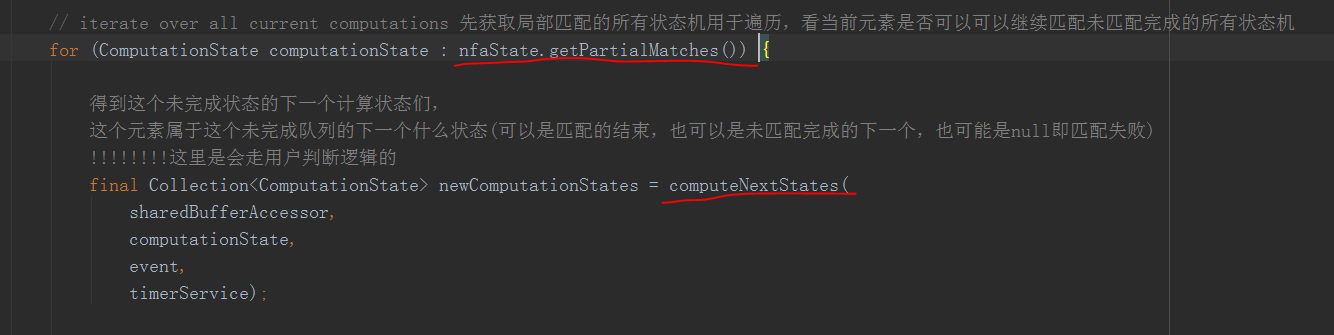
这里就直接去初始化好的NFAState中拿刚刚的那个PartialMatches,并且遍历它,通过传入这个computeNextStates()方法,用于判断这条数据是否可以满足这个ComputationState完成匹配
注意! 一开始时初始化里面只有所有可作为CEP匹配头的ComputationState,可想而知当后面匹配上了以后肯定会更新这个用于看数据是否匹配的queue
这里就可以知道了整个CEP的处理方式了:
一开始会把所有可以作为CEP匹配头的状态State先放入queue,每来一条数据就会遍历queue中所有state,看这条数据是否能能匹配上,能匹配上就在queue中加入下一个用于匹配的状态, 用于看下一条数据能否继续匹配上
比如一个正则"abc"用于CEP匹配 当来了一条a数据,就匹配上CEP头了,会把b state加入queue中,接着来了一条b数据,又继续匹配上了,又把c state加入queue 直到来了一条c数据整个就匹配完成,返回结果
总结 : 处理过程就是两步
1.来一条数据,遍历queue中所有state,看哪些state能匹配上就匹配
2.根据1的结果更新queue,用于下一条数据的匹配
而判断是否能匹配上就是这个computerNextStates()方法中

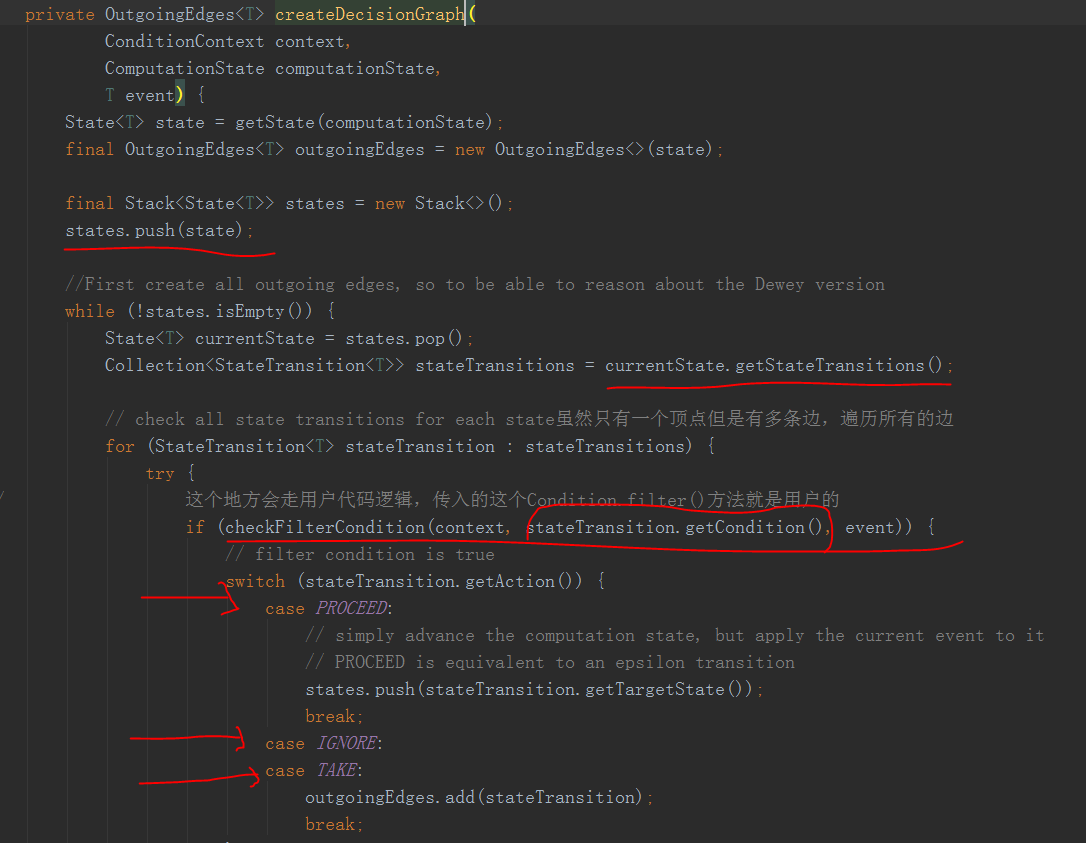
先把这个状态state压栈
从栈中取state遍历它所有的边 StateTransitions
调用用户的方法看是否能满足边条件,也就是说是否能跳变到这个状态
当满足时,会根据边
ignore: 啥都不做
take: 加入结果集中
process: 又把这个状态的下一个状态state压栈了,继续循环处理
结果返回这条数据匹配上的状态们,于是
遍历所有匹配上的状态得结果集,会把匹配上的状态的下一个(target)用于匹配的状态加进queue去




如果是结束,默认NFAstate中是有一个自带"&end"的结束state
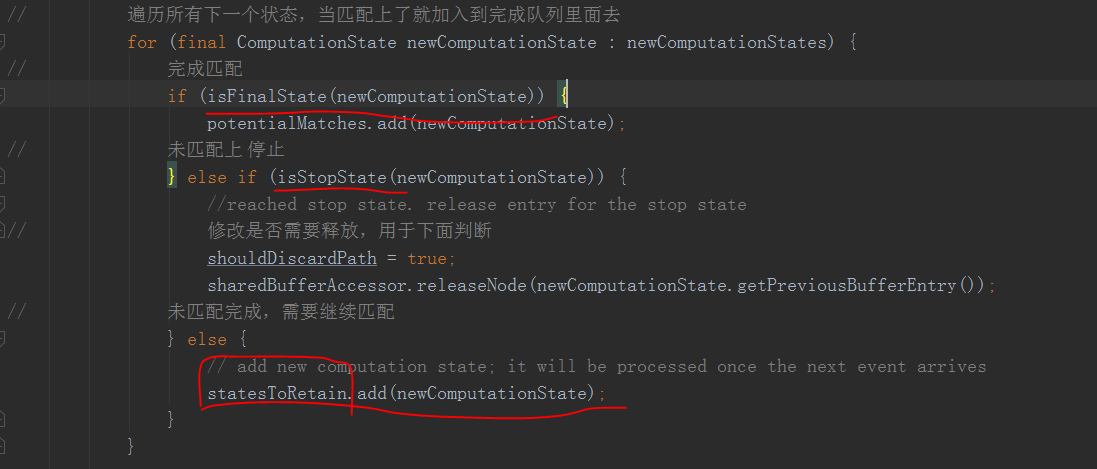
遍历所有完成的状态,当匹配上最后一个状态时就是上面说的“&end”就证明完成了,丢到完成queue中
当匹配失败了就清空状态
当匹配上了但还没有结束就丢到半匹配queue
接着

会先执行跳过策略把结果筛选一遍
然后

就是用我们前面说的那个半匹配queue了,用它又继续更新了NFAState中的PartialMatches了
下一条数据来了以后就会用遍历这个新queue集合来判断是否可以继续匹配了
然后返回这次匹配成功的数据,调用用户select方法处理结果了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号