

在做客户经营、精准营销、推荐等业务场景中往往会遇到数据稀疏,样本选择偏差的问题
一、《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》 简称:ESMM,paper下载地址:https://arxiv.org/pdf/1804.07931.pdf。
这篇文章主要介绍在电商推荐、广告等领域经常会需要对点击之后的转化(CVR)进行预估,而在预测CVR的过程中,会出现数据稀疏和样本选择偏差的问题:如下图所示:
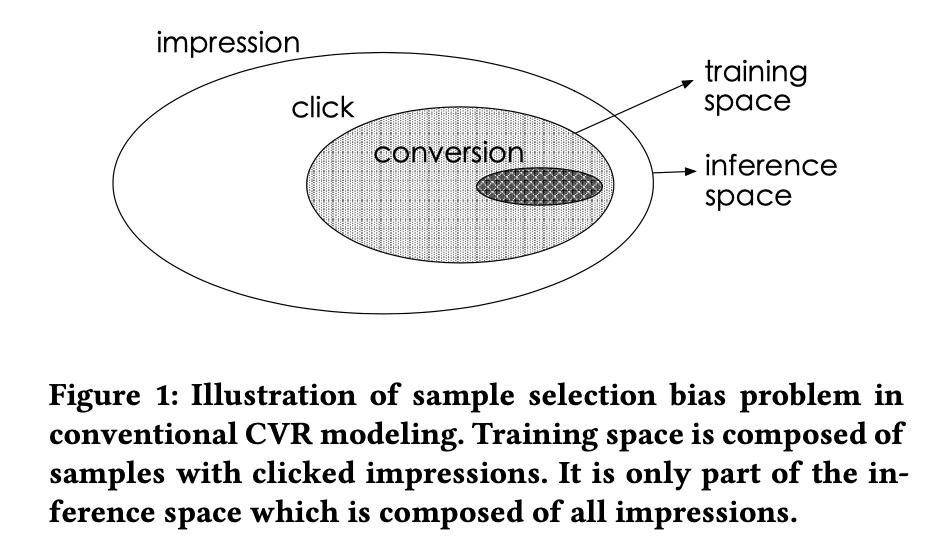
所谓样本选择偏差指的是:训练样本与预测样本的分布不一致,从上图可以清楚看出,训练样本是用户点击之后的样本(点击之后转化作为正样本,未转化作为负样本),这样的样本选择空间就局限于用户点击之后的样本空间,但我们最后在预测的时候往往是需要预测全量样本空间。
所谓数据稀疏指的是:推荐系统展现给用户的商品数量要远远大于被用户点击的商品数量,同时有点击行为大部分都是活跃用户贡献的,占所有用户非常小的一部分。这就是所谓的训练数据稀疏的问题,高度稀疏的训练数据使得模型的学习变得相当困难。
在这样的背景下,阿里的工程师们提出如下解决方案:
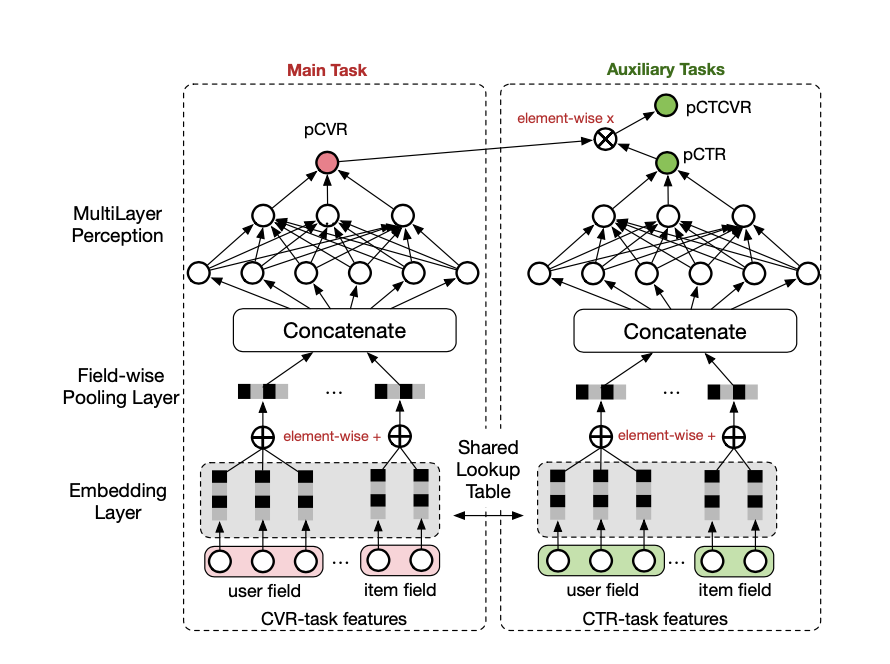
主要思路就是缺什么补什么,前面分析不是说CVR模型训练样本相比全量样本空间小的吗,所以就引入曝光到点击的CTR过程来辅助训练,网络中通过共享底层的Embedding来进行信息共享。个人理解是将整个用户转化链路能够形成end to end的模型进行拟合。
二、MMOE【https://dl.acm.org/doi/pdf/10.1145/3219819.3220007】
如下图所示,我们经常简单的多任务模型往往是如下(a)所示,通过共享Embedding层来实现信息共享。图(b)则是针对不同的任务,有多个专家进行学习,并通过一个门控制(Attention机制貌似也可以,后面实现PLE我采用的是Attention机制替代gate),门控制机制可以决定不同的任务哪些专家作用的程度。图(c)表示的意思是说多个任务有多个专家进行学习,最终每个任务都有一个专门的gate门控制控制每个专家对不同任务的贡献程度。
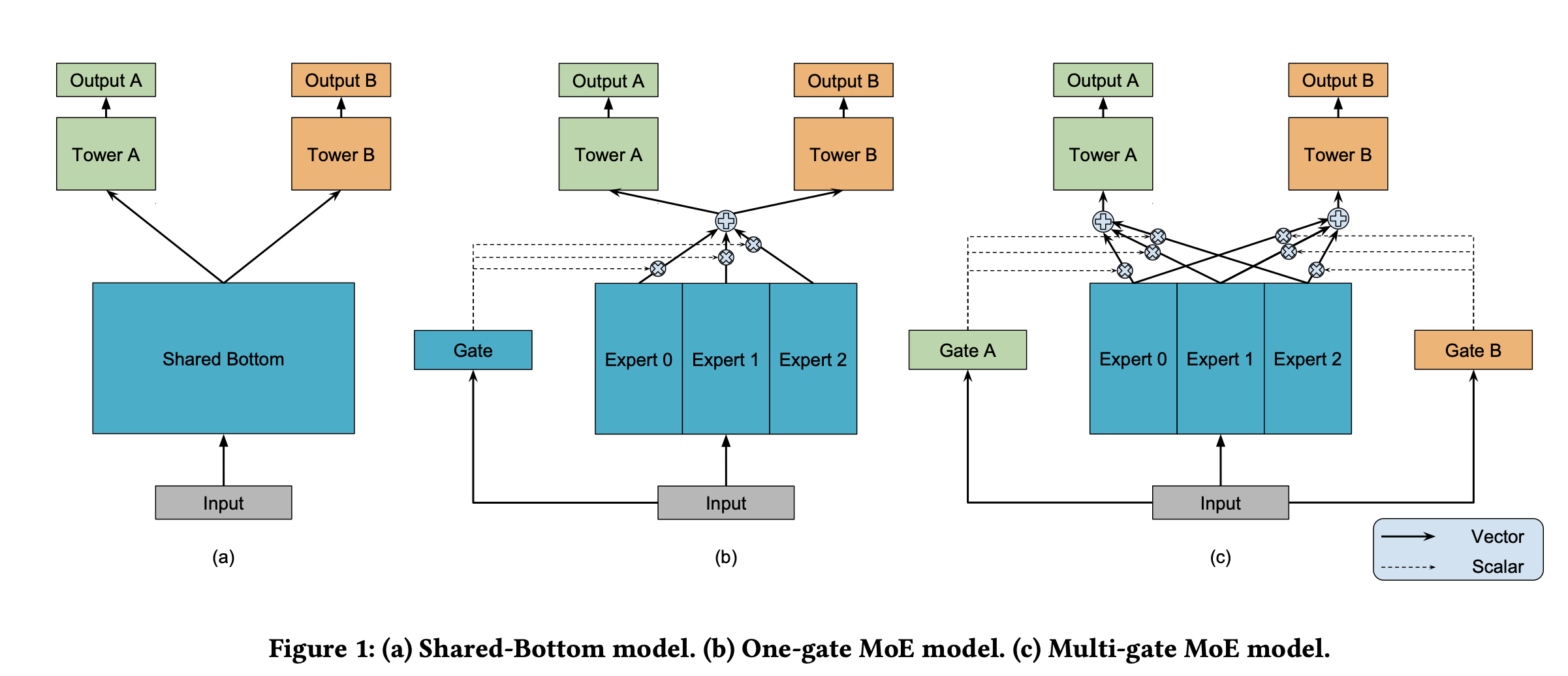
图C就是MMOE的主要思想。但是我们不难发现,
1、图C中专家在学习的时候,不同的任务可以update的参数只有一个门控制来提高,其他参数更新的话,必然还是引起其他任务的性能。所示MMOE还是存在一定程度“跷跷板”现象。
2、图a,b,c都是共享层的专家学习,并把所有的专家都用于不同的任务学习,各任务之间特有的信息就很难去表征。
MOE、MMOE存在的问题是说底层的专家都是作为不同的任务输入,若某个任务更新了专家的参数,则会影响到其他任务的学习。
三、PLE
针对MMOE存在的跷跷板的问题,主要原因是每个专家都作为所有任务的输入,导致单个任务调整参数对其他任务造成的影响,于是,腾讯的专家们提出了CGC和PLE两个框架。其中PLE是基于CGC的基础之上,增加了全联接层提取不同专家之间交叉特征。而CGC的主要核心思想是说每个任务都有特有的专家部分和不同任务之间共享的专家部门,由这两个部分最终决定某一个任务的结果。模型在学习的时候可以同时更新特有的专家和公共部分的专家,从而达到消除跷跷板的影响。下面可以详细介绍如下:
1、CGC的网络结构
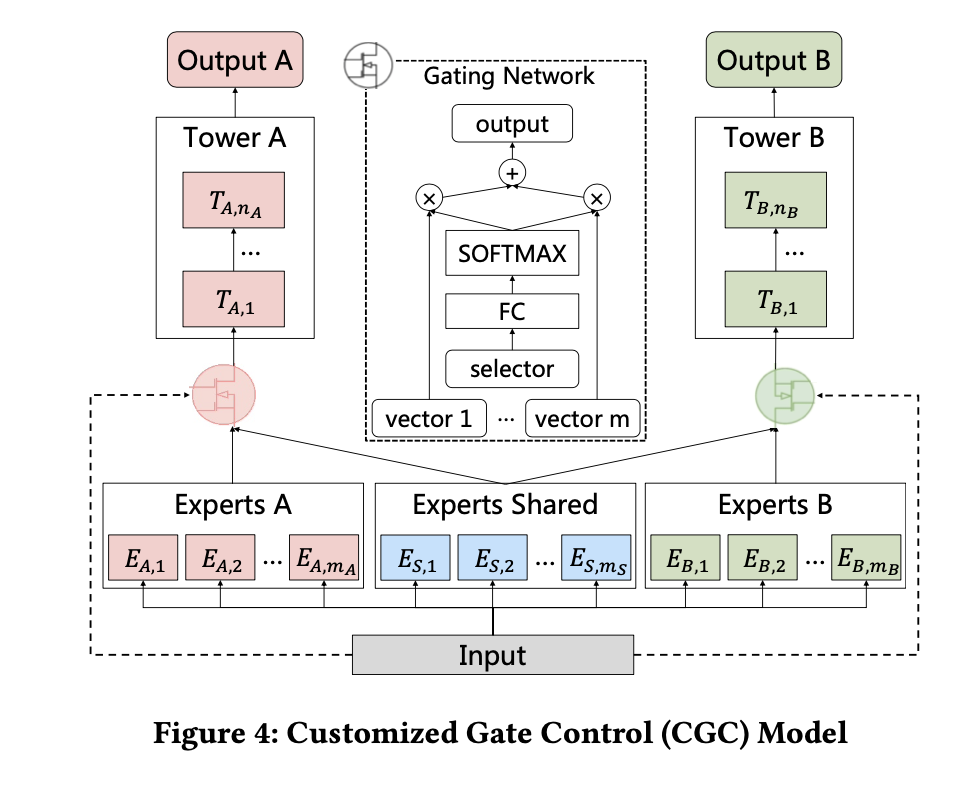
从CGC的网络结构图可以看出,TaskA主要通过ExpertsA 和Experts Shared两个部分决定,TaskB则由ExpertsB和Experts Shared两个部分决定。Experts外接门控制(softmax)作为结果,这个部分称之为Tower,最终,多个Tower决定最终的结果。
2、PLE网络
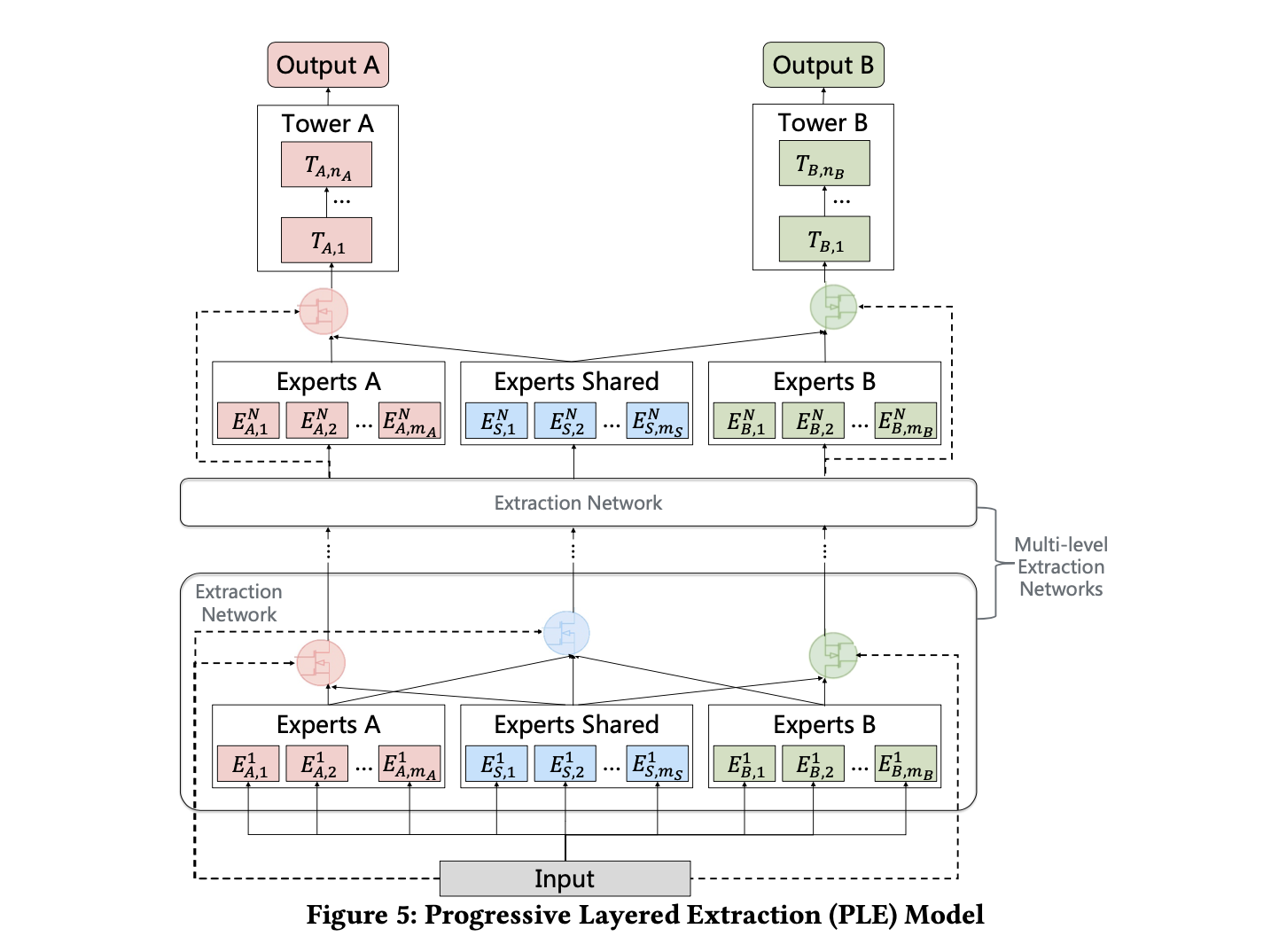
PLE与CGC最主要的区别就是在CGC的基础之上,增加了Multi-level Extraction Networks(多层特征提取网络),所谓多层提取网络则是多个专家提取特征模块。即多个下面的模块:

3、个人思考
针对上面的网络模块,个人认为,门控制改成Attention是不是会更好一些,Attention是否会更加聚焦单任务,于是我在PLE的基础上,针对门控制部分做了一些修改,改成Attention的方式。最终将其应用到实际的业务场景中,模型能带来28%的提升。
四、多任务学习模型训练的坑:不同任务之间梯度大小差异较大引起模型训练速度不一致,最终导致模型无法有效的学习。
多任务在学习的时候,一般都是通过不同任务之间的Loss加权求和得到最终的Loss,模型在更新的时候,则通过对该Loss求导去更新不同的任务。这里面可能存在的问题是有些任务对应的梯度较大,学习速度较快,很快收敛;有些任务梯度较小,学习速度较慢,收敛速度较慢。如下所示:

问题:在实际模型训练过程中,往往会不同任务的loss差异大导致模型更新不平衡的本质原因在于梯度大小;
解决办法:
1、通过修改不同任务的权重W可以改善问题
2、通过对不同任务的梯度进行处理,从而改善不同任务更新速度不一致的问题。常用的方法是梯度归一化(grad Norm)
梯度归一化的主要目的让不同任务对应的梯度差异控制在一定范围内,从而控制多任务网络的训练,训练的模型才可以以相同的速度学习。最终可以避免某个单个任务收敛了,另外一个任务还在收敛的路上的问题。该问题会导致:
(1)模型训练的效率低,最终运行时间由最复杂的任务决定。
(2)复杂任务收敛的过程中,已收敛的任务对应最优解可能会变差。
下面主要讲一下GradNorm具体的实现方法:【论文地址:https://arxiv.org/pdf/1711.02257.pdf】

如上图右边所示,我们需要计算Lgrad对应的grad norm之后的loss的值,并作用到不同任务中去。下面分部讲解一下如何计算,以及如何不同任务不同步长的方式更新参数:
(1)计算不同任务对应的Gw(t)值。该值是对应每个任务的loss加权之后,并计算L2范数。每个任务对应一个
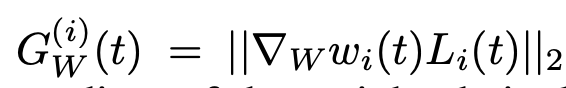
(2)计算上面对应的平均值
![]()
(3)定义不同任务训练步长(训练速度)
![]()
![]()
(4)最后计算grad norm之后的梯度
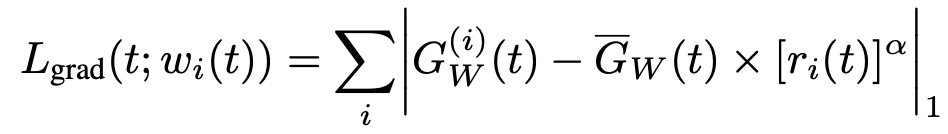
整体的训练过程如下图所示:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号