

其实Embedding技术发展相对比较早,随着深度学习框架的发展,如tensorflow,pytorch,Embedding技术显得越来越重要,特别在NLP和推荐系统领域应用最为广泛。下面主要讲讲我认识的Embedding技术。本文目录:
一、Embedding技术发展时间轴关键点
二、word2vec
补充:fastText算法
三、Item2Vec
四、Youtube基于Embedding的召回算法
五、DSSM算法
六、Wide-Deep算法
七、DeepFM算法
到这一步是一个转折点,上面的一些算法主要是围绕这特征工程在神经网络中做一些文章,下面的算法则从另外一个纬度来提取用户的特征并且提取用户的注意力机制。
八、transformers
九、ELMO
十、GPT
十一、BERT
下面开始主要内容:
一、Embedding技术发展时间轴关键点

二、Word2Vec算法【https://arxiv.org/pdf/1310.4546.pdf】
该算法主要包含两个算法:Skip-gram和CBOW,其中Skip-gram是CBOW的逆过程。其网络结构分别如下所示:
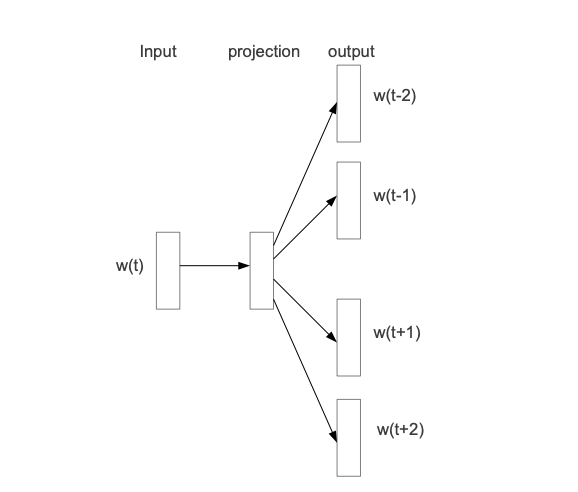
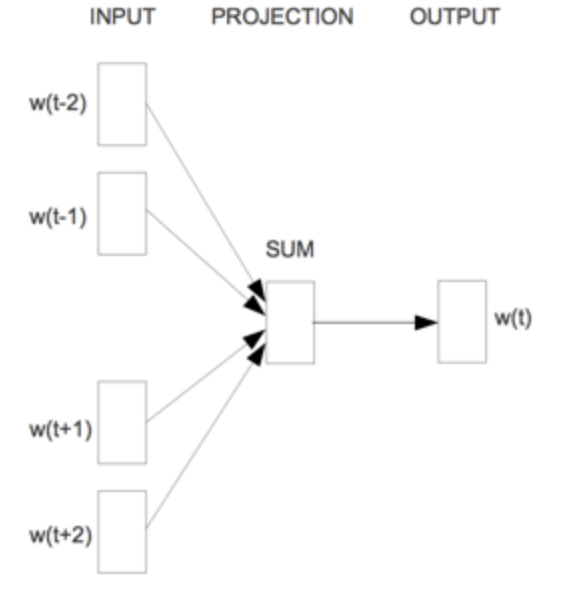
Skip-gram CBOW
这里重点讲一下Skip-gram算法,因为后面Item2Vec等算法都是基于算法来实现的。Skip-gram的主要思想是根据当前目标词预测其上下文对应的词。主要包含输入层和隐藏层和输出层,输出层是词表所有词,而我们知道词表非常大,若直接作为输出,则输出纬度非常大,模型很大概率是欠拟合。于是google那些大佬们提出了两个办法来解决:(1)Hierarchical Softmax (分层softmax)和(2)Negative Sampling(负采样)。下面分别说一下这两个方法具体实现方法:
(1)Hierarchical Softmax (分层softmax)
该方法主要是对输出的词表进行压缩编码,主要用到的是Huffman编码,即根据词表当中词的词频构建一个Huffman编码树,树中非叶子结点都是输出节点,叶子结点是词表中的词。通过训练学习语料并训练得到每个词表示。
缺点:由于Huffman编码树是根据词频来构建的,距离根结点越远,对应的学习参数越多。所以分层softmax对低频词具有一定的偏向。
(2)Negative Sampling (负采样)
该方法主要思想是通过构造正负样本的方式来进行训练,我们知道输出层对应的context词是有限的,通过负采样对非Context进行词进行采样来构建正负样本,从而实现提高训练的效率和效果。
缺点:负采样的策略对训练的效果影响很大,所以google开源了集中采样策略,如均匀采样,基于词频的采样等。
补充:fastText算法的原理及其与word2vec的区别【https://arxiv.org/pdf/1607.01759.pdf】
fastText是2016年Facebook大神提出来的算法,该算法借助与word2vec算法CBOW思想原理,并在此基础之上,也是一个三层的神经网络,其中输入层是target词上下文字符级的n-gram特征的embedding,隐藏层对多个词向量进行叠加平均,输出层输出文档对应的类别,是一个分层的softmax。
1、增加了字符级n-gram的特征来获取不同词之间的position的信息。:
这带来两点好处:
(1)对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
(2)对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
2、Huffman编码树对应的叶子结点是label(即该词所属文档的label),即fasttext在预测输出时,会计算所有叶子节点中对应label概率(对应树中每个路径概率之积),选择概率最大的叶子结点作为该sentence的label;而word2vec对应的叶子结点是每个目标词(即词表中所有词)。
3、fastText是一个有监督的学习算法
4、fastText输入一般是整个sentence上下文词对应的embedding,word2vec是输入词对应的one-hot之后的结果。
三、Item2Vec【https://arxiv.org/pdf/1603.04259.pdf】
该篇文章主要的思想是利用Word2Vec中的Skip-gram算法,并且Skip-gram采用Negative Sampling负采样的方式进行训练。训练的思路是将Item看作是Word,用户浏览或者点击的Item构建成一个Sentences,从而可以将Word2Vec迁移到推荐系统中。
四、Youtube基于Embedding的召回算法
2016年YouTube提出《Deep Neural Networks for YouTube Recommendations》论文,该论文主要讲述Youtube借助神经网络训练用户的向量和videos向量。模型主要框架如下:

从网络的架构我们很容易看出,网络的输入层是用户的信息,主要包括:用户浏览历史,用户搜索历史,用户地理位置,用户基本属性等。输出层是所有的Videos,即有多少个Video就有多少个输出。这里我们是不是有点似曾相识的感觉,我们的Word2Vec的Skip-gram模型也是输出层是所有的词表。对的,你猜对了,这里也是借助Word2Vec负采样的方法进行训练的。
然而,我们发现网络的输入只有用户的信息,却没有Video的输入,而最后输出层softmax层权重是输出Video Embedding。这里可能有很多人优点难以理解,也确实存在一些争议。争议的点是:User Embedding与Video Embedding可否同时同处于一个空间来学习。
优缺点:
优点:
1、将用户浏览历史和用户搜索历史利用神经网络学习用户的特征
缺点:
1、显然,并没有将Video信息输入,训练时无法学习到Video信息
2、既然没有Video信息的输入,也就没有学习到用户与Video的交叉信息
五、DSSM算法
2016年《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》论文提出双塔模型,其距离说明如下所示,Query与Document之间计算相关性的方法。
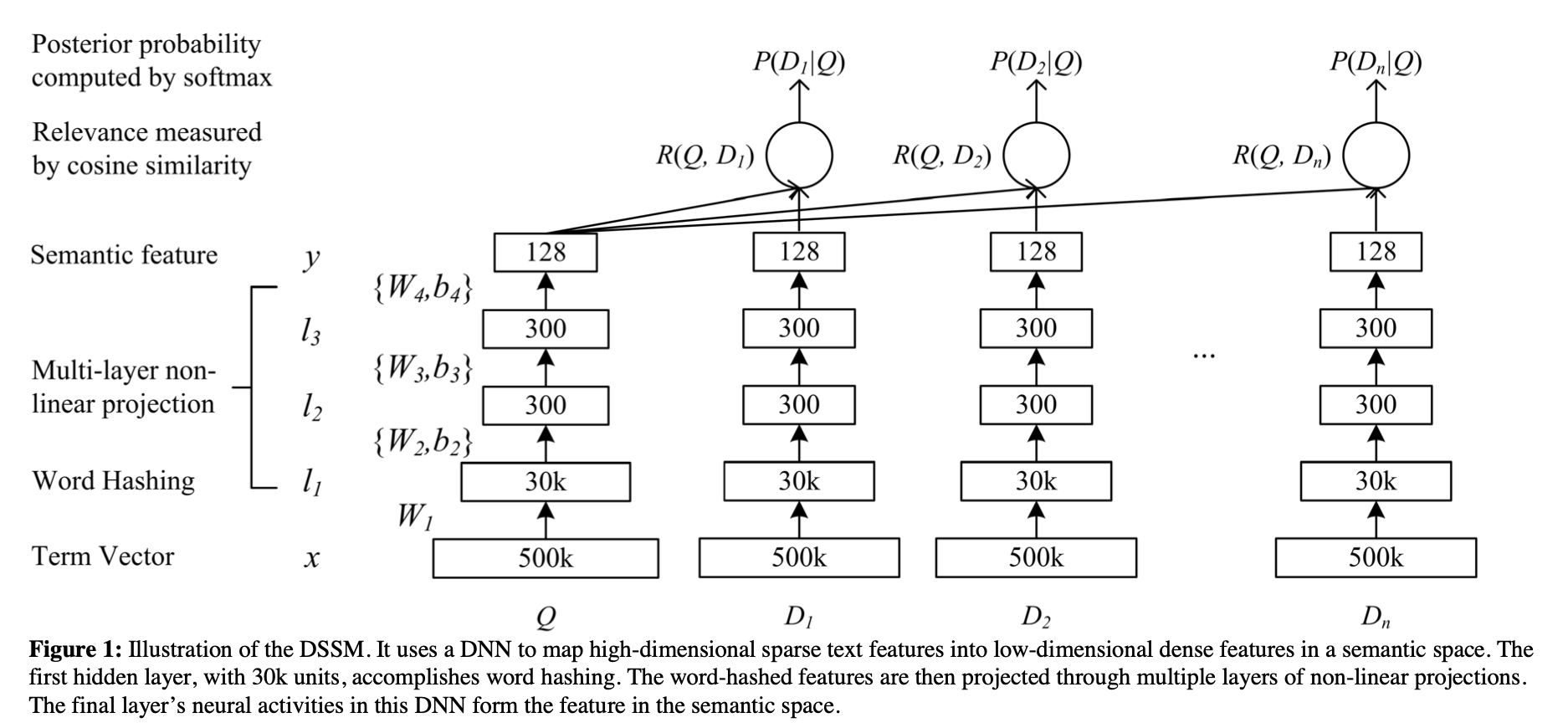
而工业届使用的双塔模型如下所示:

我们可以看出工业界的双塔模型主要特点是左边是学习User的网络,右边是学习Item的网络,两个网络可以独立的训练学习,最后进行concat。适合工业界线上分用户和Item进行分别加载。
优缺点:
优点:左右两边网络可以独立训练,并且得到的用户向量和Item向量可以分别缓存起来供线上使用。
缺点:很明显,左右两边的网络独立训练九无法获取用户与Item之间的交叉特征。
六、Wide-Deep算法【https://arxiv.org/pdf/1606.07792.pdf】
2016年google提出《Wide & Deep Learning for Recommender Systems》算法,其网络结构如下:
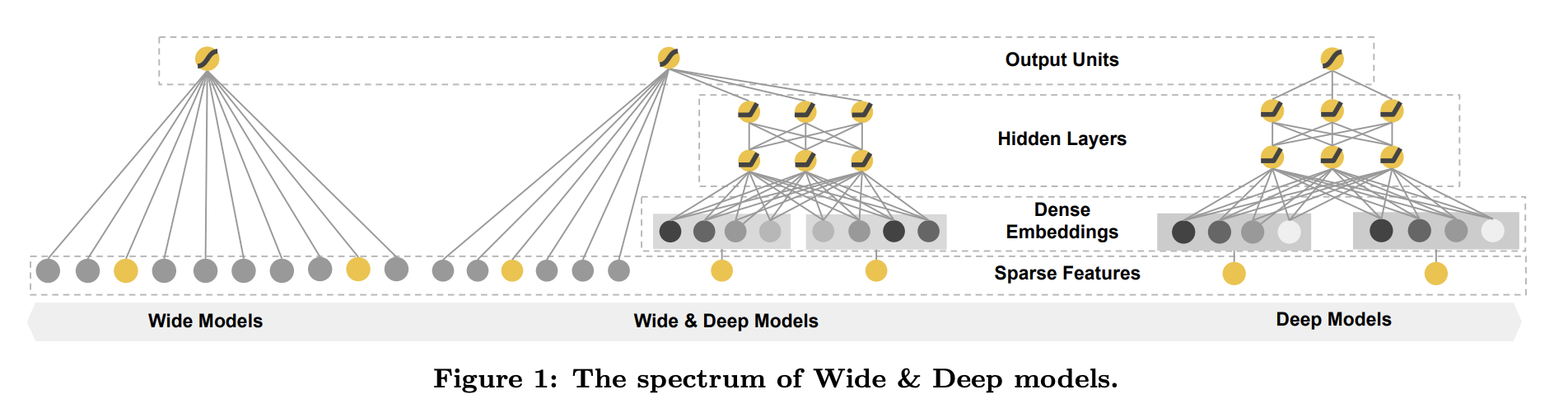
文中提到对于系数特征Sparse Feature利用非线性特征输入到线性模型是比较广泛使用的,但是这需要大量的特征工程。而对于Deep网络可以用比较少的特征,通过网络可以学习到比较高阶的特征,可以自动进行特征工程。于是Google 的大牛们就提出了融合这两个优势的网络——Wide&Deep网络。其中,Wide是我们说的需要进行人工特征工程的部分,属于强记忆特征;Deep部分是DNN部分,通过神经网络学习我们unseen的特征进行训练。
优缺点:
优点:可以结合人工特征工程与DNN的网络各自的优势
缺点:还是需要进行人工特征工程。
七、DeepFM算法
上面我提到Wide&Deep网络缺点是中Wide部分还是需要人工进行特征工程,论文《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》针对这个问题提出利用FM进行替代Wide部分,利用FM替代人工特征工程。其网络结构如下所示:
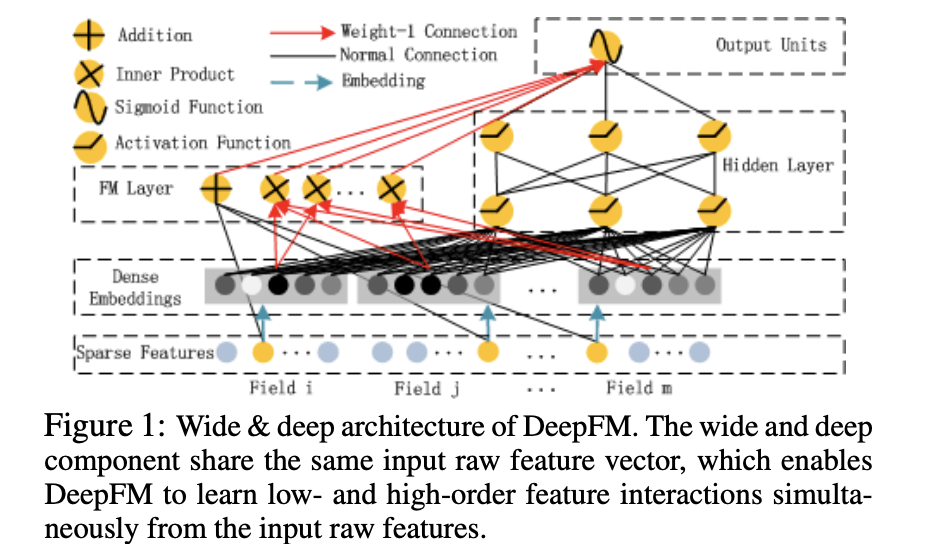
其也是有两部分组成,一个FM部分,一个是Deep部分。FM部分是采用NN实现的FM算法(具体的FM算法可以查阅一下相关的资料,主要是实现特征俩俩交叉的算法)。
优缺点:
优点:很显然,Wide部分一定程度取代了人工特征工程。
缺点:FM智能提取一阶交叉特征,对于高阶交叉特征可能无法生成。
八、transformers【https://arxiv.org/pdf/1706.03762.pdf】
2017年Google大神们提出了《Attention Is All You Need》paper,主要提出了基于Attention的思想,将其应用于Seq2Seq语言翻译模型当中,其主要网络结构如下所示:
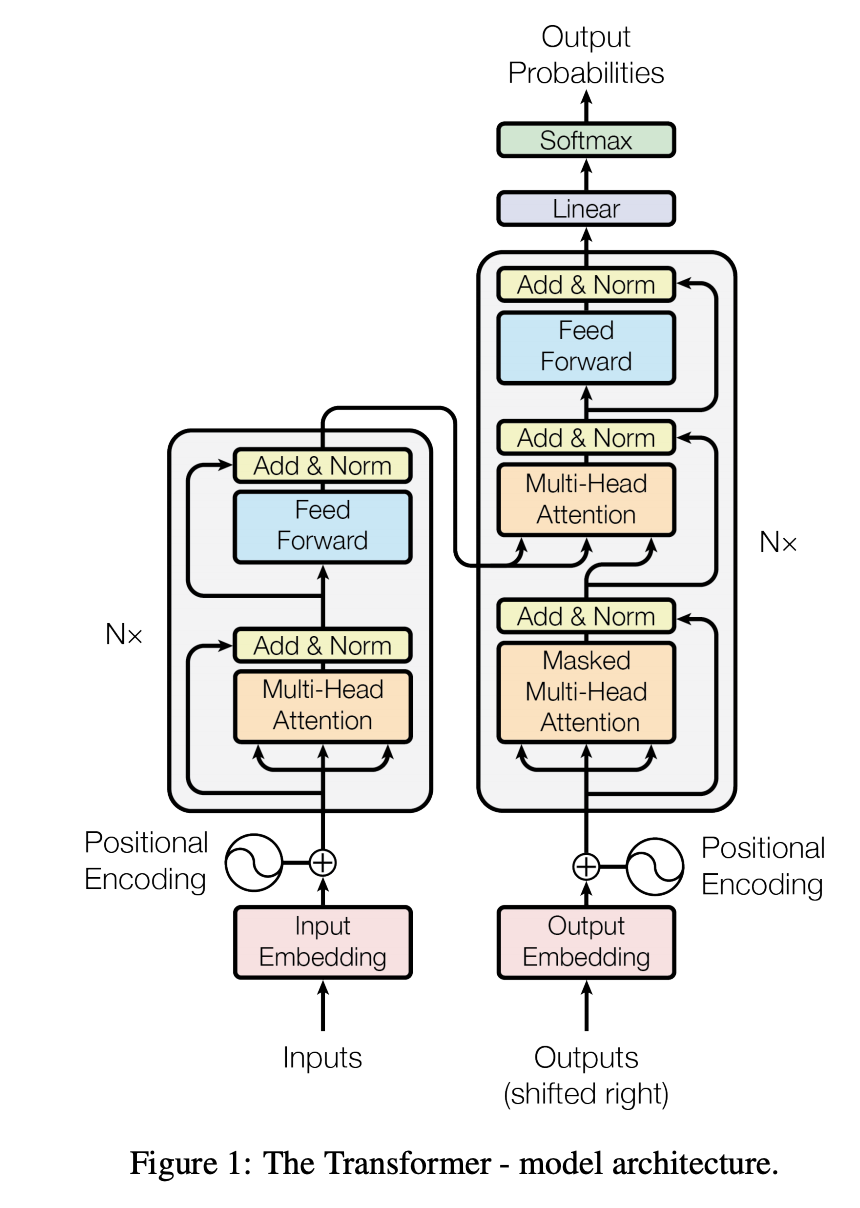
可以看出网络主要包含Encoding和Decoding两个部分,其中输入部分src Inputs、target Outputs,输出output 。其中Encoding和Decoding都包含Multi-Head Attention和FFN(前馈神经网络),这里重点讲一下Attention部分,主要包含两个部分:Scaled Dot-Product Attention 和 Multi-Head Attention consists of several attention layers running in parallel。如下所示:
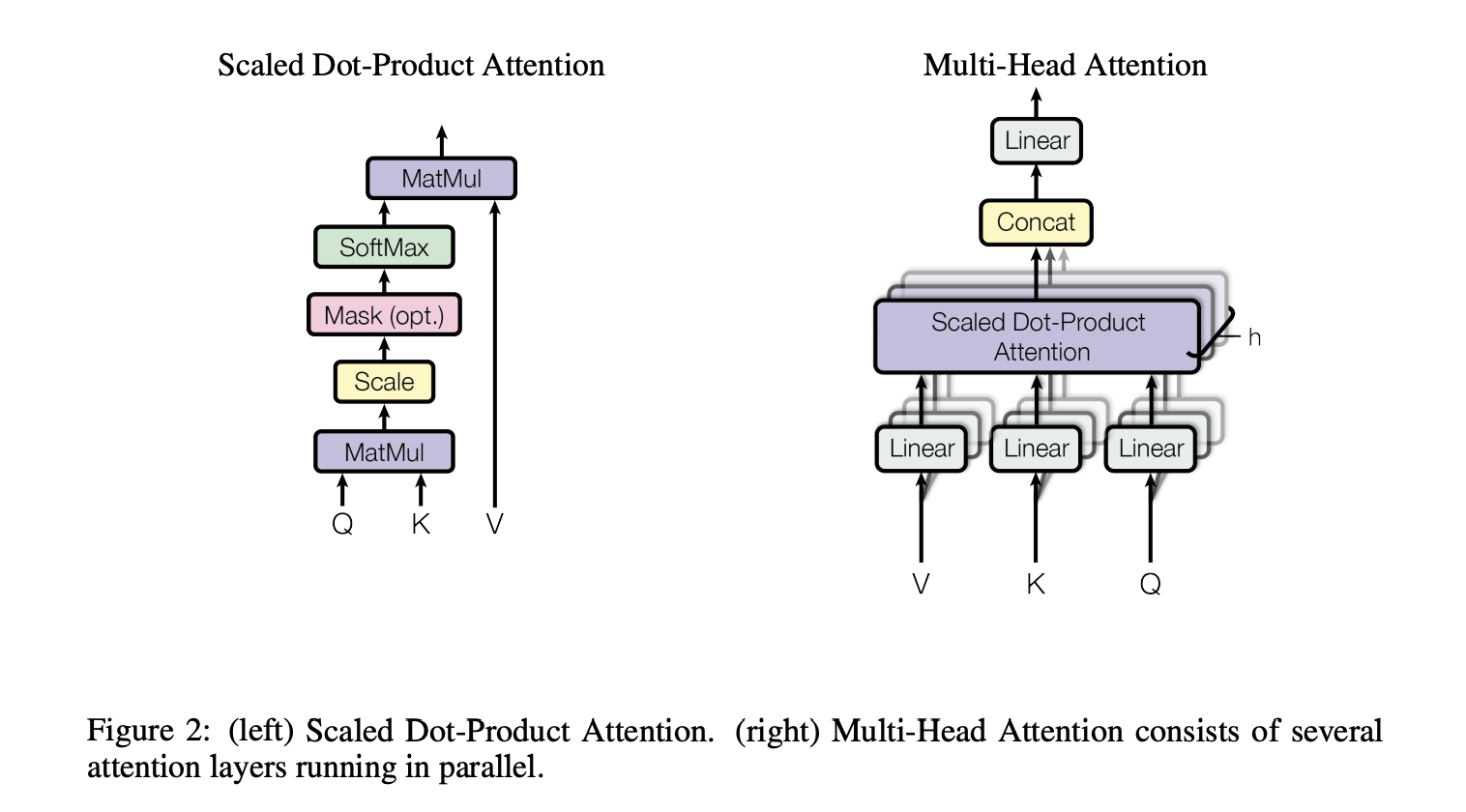
Self-Attention与RNN之间的优势:
1、每层的计算复杂度较低
2、可以并行计算,RNN由于依赖前一层所以无法并行
3、long-range dependencies长范围依赖问题在传统RNN比较严重,Attention可以很好的聚焦关注的内容,从而解决长范围依赖问题。
九、ELMO【https://arxiv.org/pdf/1802.05365.pdf】
ELMO(所谓ELMO算法全称是Embedding from Language Model)的网络结构主要是由双层深度(Deep)字符级卷积+BiLMs(双向语言模型)构成【two-layer biLMs with character convolutions】。本篇文章主要思想是基于Word2Vec算法中提炼出来的词向量往往是训练一次就得到某个词的向量,并且该词向量是应用在不同的场景下都是一样的。这种情况对于歧义词可能无法很好的表征。而我们的歧义词往往又是通过上下文语境才能推断的出来,于是本文在这样的背景下,提出了《Deep contextualized word representations》。算法的主要使用方法:
1、首先通过语料学习带有字符级卷积的BILSTM网络
2、通过特定领域的语料进行fine-tuning微调网络
3、通过拼接的方式进行融合,最终构成【X,ELMO】的向量输入到目标模型中。其中ELMO是通过输入X的context即可得到。另外也可以在目标模型中的隐藏层中添加ELMO输出向量【Hk,ELMO】
优缺点:
优点:
1、改善了word2vec词向量没考虑不同context不同含义的问题 。ELMo的假设前提一个词的词向量不应该是固定的,所以在一词多意方面ELMo的效果一定比word2vec要好。
2、word2vec的学习词向量过程中是单向训练的,ELMO采用的是BILSTM+CNN。
3、ELMo还有一个优势,就是它建立语言模型的时候,可以运用非任务的超大语料库去学习,一旦学习好了,可以平行的运用到相似问题。
缺点:
模型使用BILSTM训练,还是存在长依赖没有办法很好的学习问题。
十、GPT【https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf】
上面讲到ELMO算法使用的BILSTM模型进行训练模型,在训练的过程,而LSTM对于长依赖的问题表现不是很好。于是openAI的大神们就将LSTm用Transformer替换。对应算法的主要步骤如下:
We employ a two-stage training procedure.
First, we use a language modeling objective on the unlabeled data to learn the initial parameters of a neural network model.
Subsequently, we adapt these parameters to a target task using the corresponding supervised objective.
即:
1、首先用未标注的大语料对模型进行预训练,得到网络的初始权重weights
2、在通过有标注的语料进一步训练调整网络的参数。
优缺点:
优点:1、可以解决对应长而广的文章依赖问题
缺点:训练语料是单向的训练的,对于逆向的信息无法学习。
十一、BERT 【https://arxiv.org/pdf/1810.04805.pdf】
BERT模型的全称是Bidirectional Encoder Representations from Transformers,从算法的名称可能很显然的知道算法是基于GPT基础上进行优化,引入了双向Transformers进行训练语料。BERT不仅是从模型的角度提出了双向Tranformer,而且在训练的过程提出了两个新的训练方法。【这里重新提一下,在Word2Vec中,作者提出了CBOW和Skip-gram的方式进行训练模型】,BERT文章中提出了Masked LM和Next Sentence Prediction方法进行训练。具体原理如下:
Masked LM:
我们知道,word2vec在训练的过程中,是遍历语料,从左往右的方式进行训练。而对于双向Tranformer模型在训练的过程需要利用目标词上下文信息,所以将文中15%的关键词进行Mask【遮掩】,并预测被遮掩的词,称之为Masked Language Model。这里需要注意的是:
1、首先15%Masked的词是随机进行遮掩的,所以在训练的过程中,并不是从左往右训练,而是根据被遮掩的context进行预测。这是与我word2vec的区别之一。
2、由于是双向Tranformers,在训练的过程中,从过学习context信息,从而体现出双向Tranformer的重要性。同时也体现出BERT算法的效果好的原因。
Next Sentence prediction :
由于很多NLP任务是句子级别的,比如QA,自然语言推理等任务。本训练方法是将训练语料随机分成两等份,一份语料对应语句对是上下文连续的,一份语料对应语句对是上下文不连续的,然后通过BERT来是通过判断那些语句对是否连续的方式来训练模型的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号