

DDP
Distributed data parallel
1. Preface
首先了解DP(data parallel),DP的本质是先将整个batch加载到主线程上,然后将batch分成小块传输到别的GPU进行工作。(其batchsize为总batchsize)
DP将模型参数默认放在GPU-0上,本质上是将训练参数从GPU-0拷贝到其他GPU训练,用GPU-0进行梯度的汇总和模型的更新,因此GPU-0的使用内存、使用率会出现负载不均衡现象。
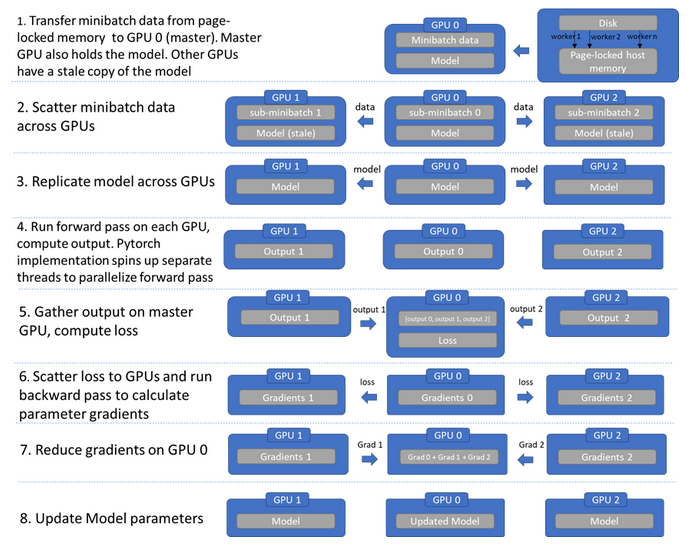
流程:
1. 主线程将batch data切分为小块传输到其他GPU,同时将GPU-0的model也**浅拷贝**到其他GPU上。
2. 每个GPU在各自线程上独立并行前向传播,将模型输出传输到GPU-0上,随后GPU-0计算loss。
3. GPU-0将loss分散给子GPU,每个GPU反向传播计算梯度。
4. GPU-0 汇总梯度(reduce gradient),进行梯度下降,更新GPU-0上的模型参数。
5. GPU-0将模型参数复制到其他GPU,开始下一轮训练。
缺点:
1. 数据复制冗余\线程创建销毁麻烦\每次forward前都需要复制模型到GPU,速度慢、消耗大。
2. 主GPU负荷过重(收集output/分发loss/汇总梯度/主GPU上更新参数) 。
2. Distributed data parallel
DDP(分布式数据并行),通过提高batchsize增加并行度,通过ring-reduce的数据交换方法提高通信效率,启动多个进程来突破GIL的限制,从而提高训练速度。
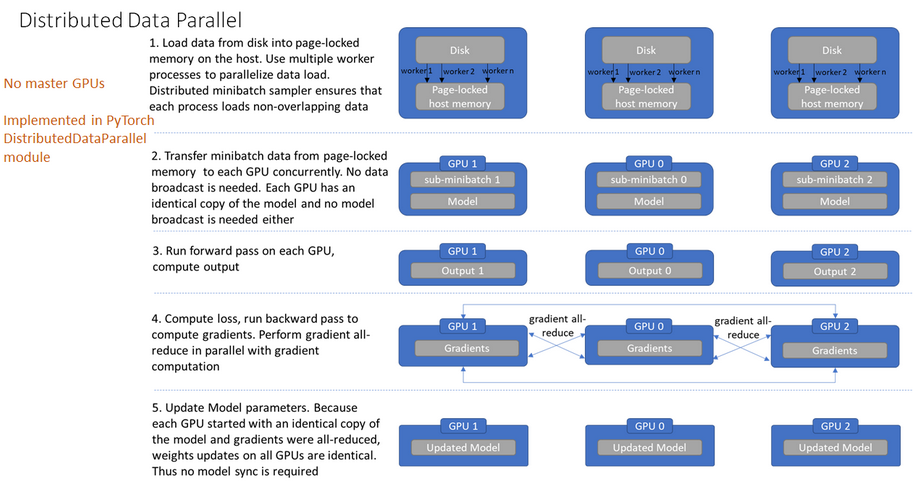
流程:
-
启动多进程,将batch data按进程数切分(sampler确保各进程读取的数据不同),每块GPU上加载各自的模型。
-
由于每个进程都有minibatch data及model copy,因此这种方法不需要进行data broadcast。
-
每块GPU前向传播,计算输出结果。
-
每块GPU计算loss,反向传播计算梯度,随后通过ring-reduce方法同步更新梯度。
(各进程汇总平均梯度后,主GPU负责将梯度broadcast到所有进程,各进程用该梯度更新参数。)
-
每块GPU各自更新模型参数,继续下一步训练。
(由于forward/compute loss/gradient descent都是在每个GPU上独立进行的,且模型的初始参数相同,更新的梯度通过ring-reduce后也相同,所以更新出的模型参数也相同)
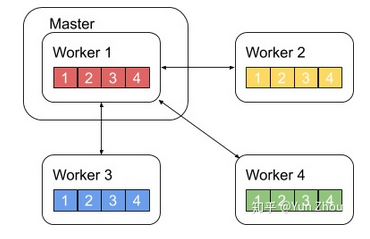
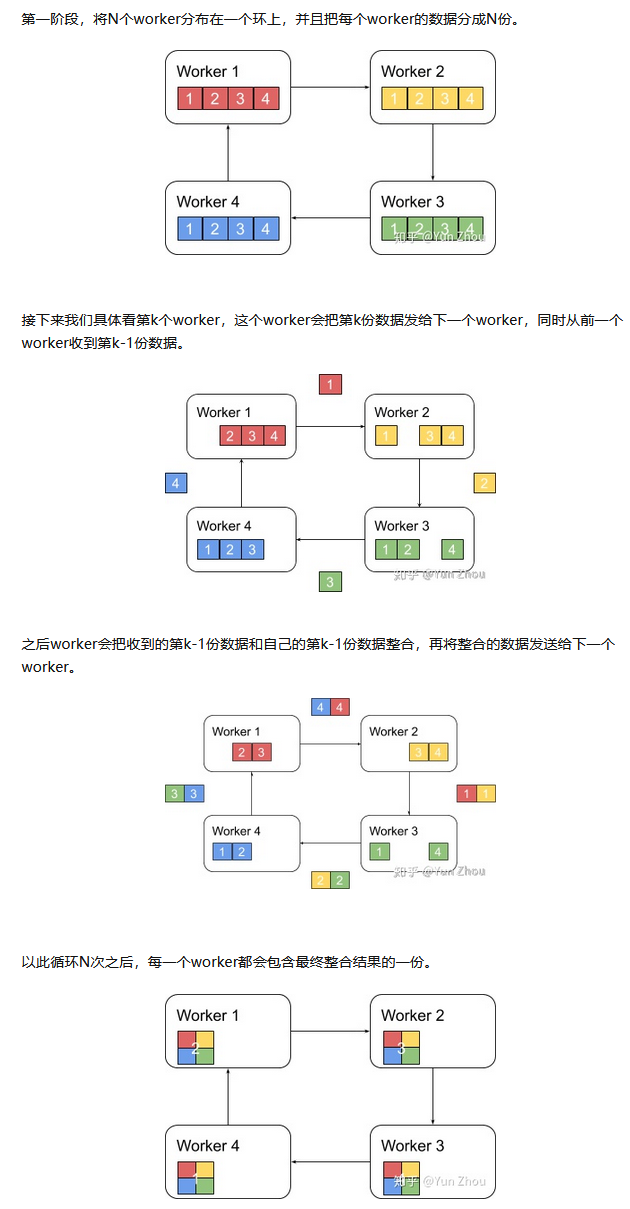
ring-reduce梯度合并
与DP的梯度更新方法不同,DDP采用的是一种分布式的通信方法,每个进程只和上下游进程通信,缓解了通信阻塞现象。
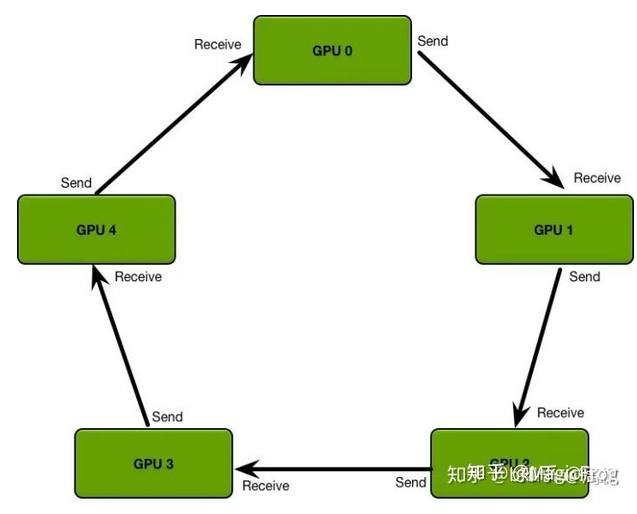
流程:各进程独立计算梯度,每个进程将梯度传递给下个进程后,再将上个进程拿到的梯度传递给下个进程,循环进程数量后,所有进程可以得到全部梯度。
3. DDP Usage
-
重要参数:
参数 意义 group 进程组,默认1 world size 并行GPU数 rank 进程ID local_rank 当前进程ID -
code
import torch import argparse import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP # 从外面得到local_rank参数,在调用DDP的时候,其会自动给出这个参数 parser = argparse.ArgumentParser() parser.add_argument("--local_rank", default=-1) FLAGS = parser.parse_args() local_rank = FLAGS.local_rank nprocs = torch.cuda.device_count() # DDP backend初始化 torch.cuda.set_device(local_rank) # 初始化DDP,使用默认backend(nccl) dist.init_process_group(backend='nccl') dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:33456', world_size=nprocs, rank=local_rank) # 定义并把模型放置到单独的GPU device = torch.device("cuda", local_rank) model = nn.Linear(10, 10).to(device) model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model) # 同步BN model = DDP(model, device_ids=[local_rank], output_device=local_rank, find_unused_parameters=True) # dataloader & sampler inputDatasets = ... train_sampler = torch.utils.data.distributed.DistributedSampler(inputDatasets, shuffle=True) dataloaders = DataLoader(inputDatasets, batch_size=batch_size, shuffle=False, drop_last=True, sampler=train_sampler,num_workers=4, prefetch_factor=2, pin_memory=True, worker_init_fn=worker_init_fn) for epoch in range(num_epochs): # 设置sampler的epoch,DistributedSampler需要这个来维持各个进程之间的相同随机数种子 trainloader.sampler.set_epoch(epoch) for data, label in trainloader: prediction = model(data) loss = loss_fn(prediction, label) loss.backward() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.step()# 多进程启动方法 # 1. Bash launch 运行(假设只在一台机器上运行,可用卡数是8) python -m torch.distributed.launch --nproc_per_node 8 main.py # 2. torch.multiprocessing.spawn调用,推荐! mp.spawn(demo_fn, args=(world_size), nprocs=world_size, join=True) -
注意事项
-
保存和读取模型,只用一个进程保存。
-
注意使用dist.barrier()来对进程进行同步。
-
loss的汇总计算
def reduce_tensor(tensor: torch.Tensor, proc): default_device = torch.device('cuda', proc) rt = tensor.clone().to(default_device) dist.all_reduce(rt, op=dist.reduce_op.SUM) rt /= dist.get_world_size() return rt
-
4. Reference
https://zhuanlan.zhihu.com/p/178402798

 浙公网安备 33010602011771号
浙公网安备 33010602011771号