
BP神经网络回归的三种python实现
BP神经网络回归的三种python实现
前言
BP神经网络(Back Propagation)是基于误差反向传播算法训练的多层前馈网络,能学习存储大量的输入-输出模式映射关系。它的优化方法是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络误差平方和最小。其实际就是多层感知机,拓扑结构(单隐藏层)如下图所示。
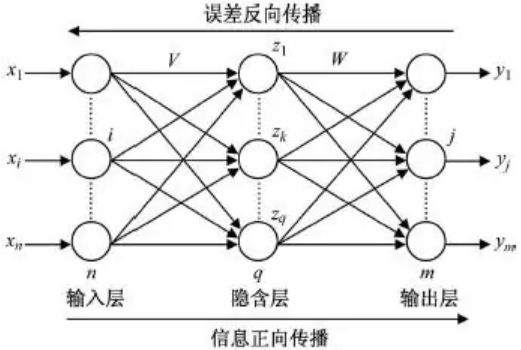
BP神经网络与梯度下降法的关系
BP神经网络用来计算损失函数相对于神经网络参数的梯度,待求的是最小化损失函数的参数,是一种建模思想;而梯度下降法是一种优化算法,用于寻找最小化损失函数的参数。(https://www.zhihu.com/question/396352046)
三种实现
分别基于python-sklearn/pytorch/tf2.0实现BP神经网络的多变量回归模型。
模型的输入是有着两个自变量的二维数组(列=2),随机生成一组正态分布的数组后,乘以权重w/b,然后再添加正态扰动,得到输出值,最后将这两个值进行回归分析。
这里建立的BP模型的隐藏层神经元个数分别为10-4-1,共有4层网络。
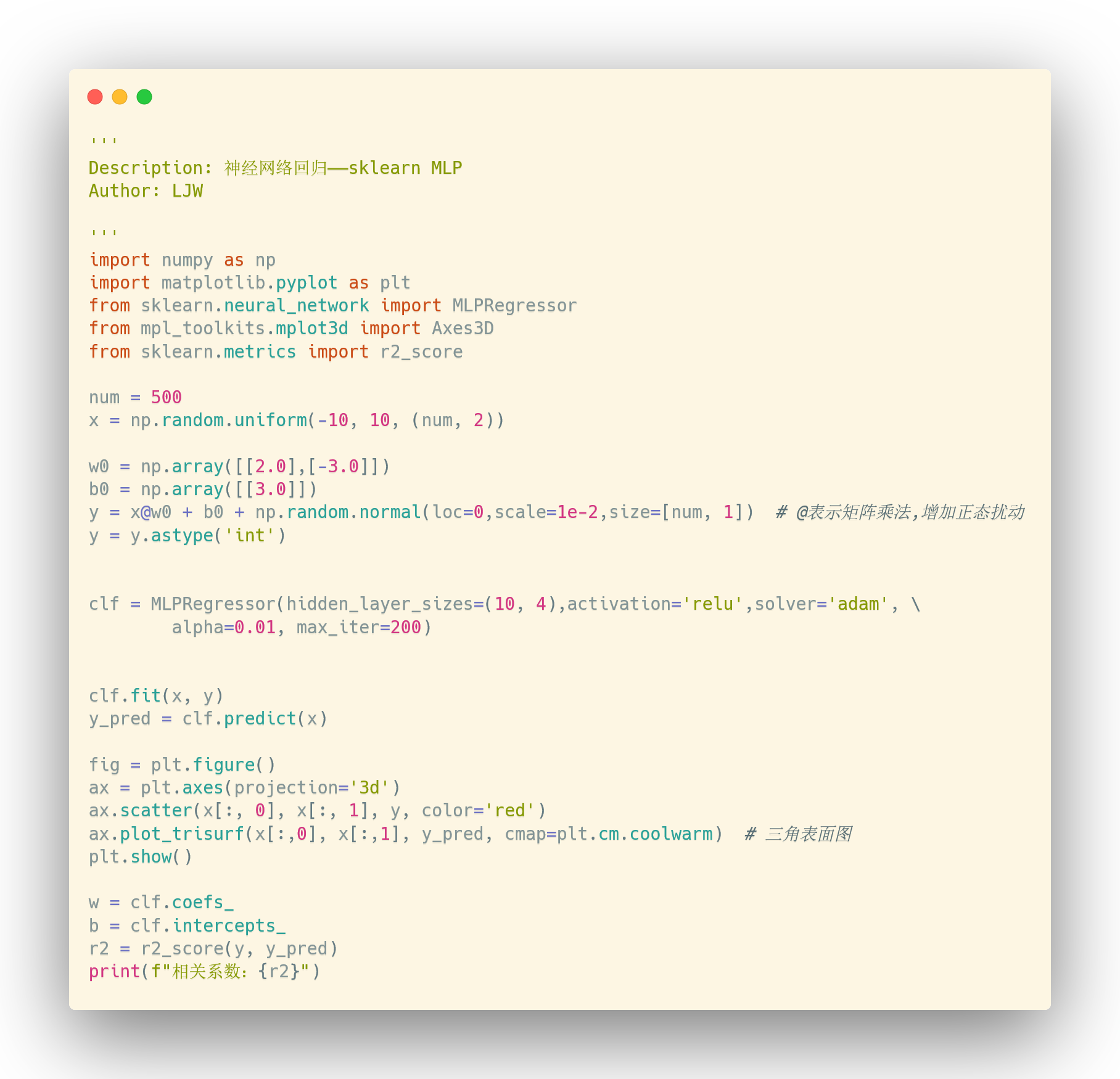
1. sklearn
BP神经网络在sklearn中的api如下:
MLPRegressor(hidden_layer_sizes=100, activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)
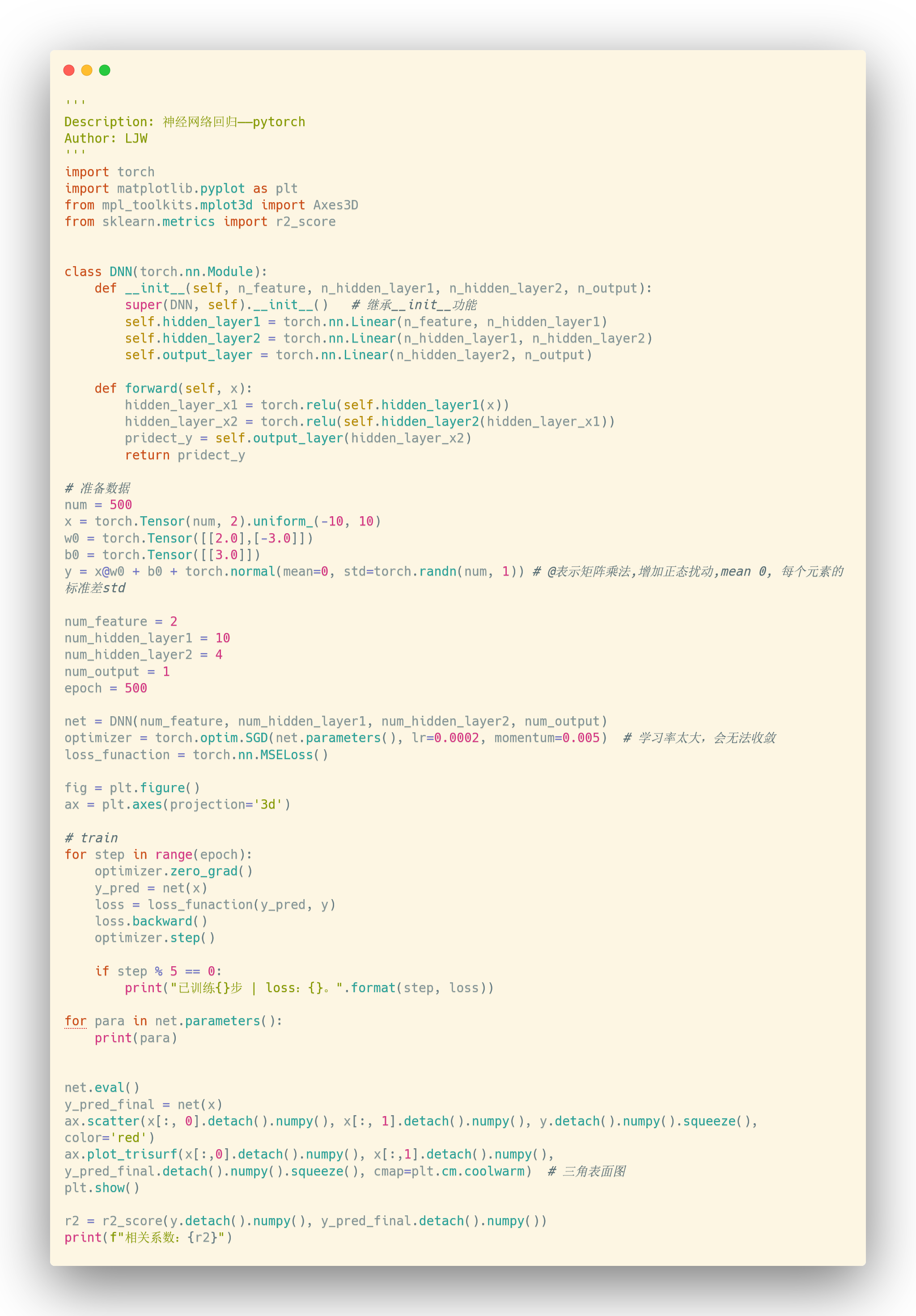
2. pytorch
3. tf2.0

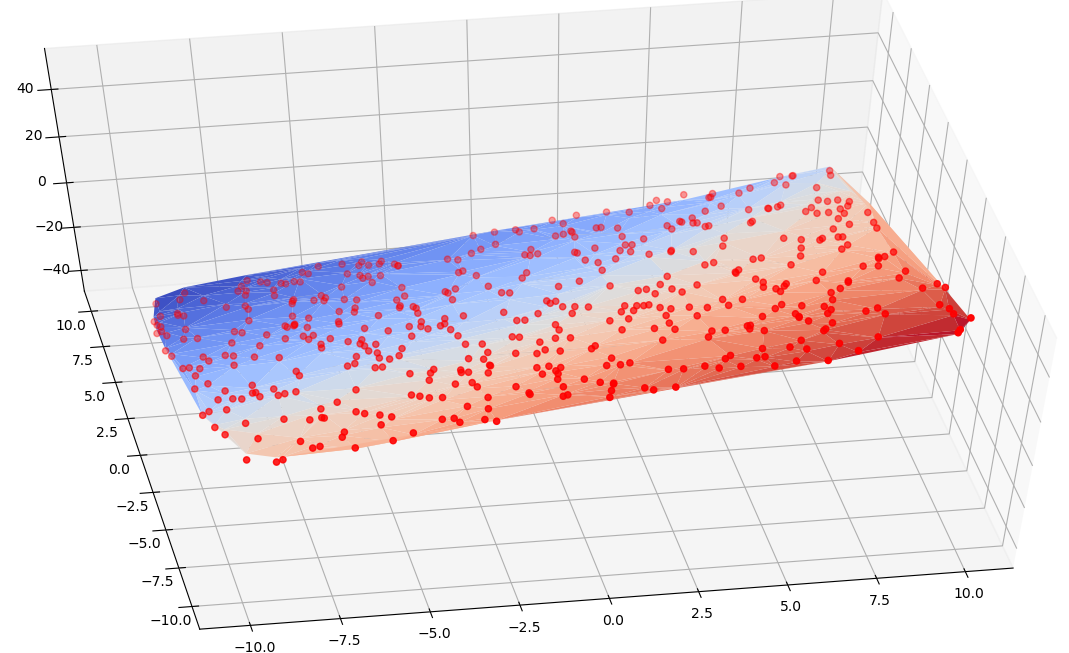
结果
模型的预测值网格与实际值对比图如下,从上到下依次对应sklean/pytorch/tf2.0,R²均在0.99上下:

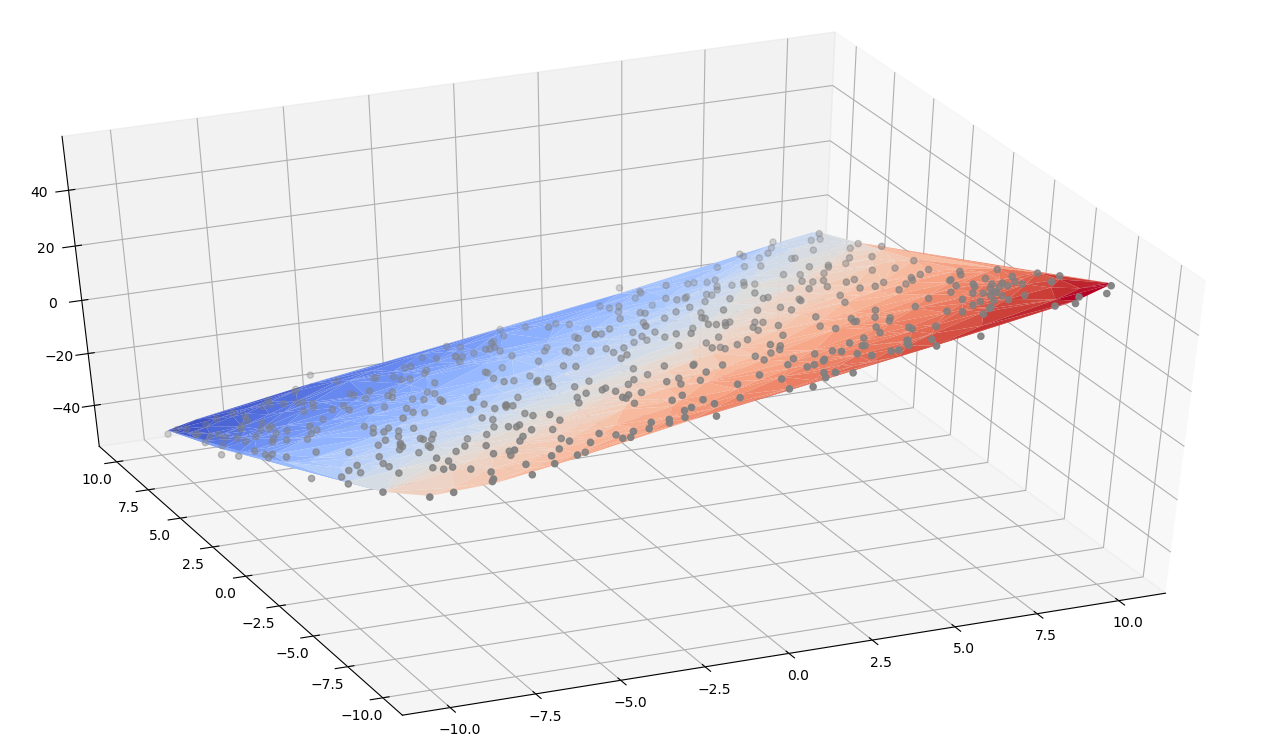
后记
- 三种api中,sklearn的最简单易用,但也最不灵活。pytorch、tf2.0虽然稍微复杂一点,但是对于网络架构的设定和参数的调整都灵活许多,个人更倾向于sklearn + pytorch结合操作。
- pytorch/tf2.0的api中,learning rate的调整至关重要,不适合的lr会导致拟合效果很差。
- 以上是二元变量的回归,也可以推广至多元变量的回归中,但隐藏层和lr的设定需要慢慢去调整。
- 数组构造部分,如
np.random.uniform()在torch(torch.Tensor(num, 2).uniform_(-10,10))和tf2.0(tf.random.uniform())中都有各自对应的api。建议使用这些api,如果使用numpy有时候会出现一些麻烦(如tf2.0)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号