
豆瓣TOP250爬取及分析
一、数据采集
1、代码展示
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
import time
paiming=[]
juming=[]
shijian=[]
daoyan=[]
pingfen=[]
pingren=[]
jianjie=[]
urllist=[]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
for i in range(0,10):
a=i*25
url='https://movie.douban.com/top250?start={}&filter='.format(a)
try:
r=requests.get(url,timeout=30,headers=headers)
r.encoding=r.apparent_encoding
uu=re.compile(r'href="https://movie.douban.com/subject/(.*?)/"')
uus=uu.findall(r.text)
uus=set(uus)
uus=list(uus)
for i in uus:
rr='https://movie.douban.com/subject/'+i+'/'
urllist.append(rr)
except:
print('url获取失败')
for i in urllist:
url=i
print(i)
try:
r=requests.get(url,timeout=30,headers=headers)
r.encoding='utf-8'
soup = BeautifulSoup(r.text, "html.parser")
pm = soup.select('span["class=top250-no"]')[0] #匹配排名
p = str(pm.get_text())
m = re.compile(r'[0-9]+')
mm = m.findall(p)[0]
paiming.append(eval(mm)) #将排名转换为数字类型
a=soup.select('#content')
bt=a[0].h1.span
juming.append(str(bt.string)) #匹配电影名字
sj=a[0].h1.select("span[class=year]")
t = re.compile(r'\((.*?)\)')
tt = t.findall(sj[0].string)[0]
shijian.append(eval(tt)) #匹配电影时间并且转换为数字类型
dy=a[0].select("span[class=attrs]")
daoyan.append(str(dy[0].get_text())) #匹配导演
pf=a[0].select('#interest_sectl')[0].select('strong[class="ll rating_num"]')[0]
pingfen.append(eval(str(pf.string))) #匹配评分
pj=a[0].select('#interest_sectl')[0].select('.rating_people')[0].span
pingren.append(eval(str(pj.string))) #匹配评价人数
jj=soup.select('#link-report')[0]
ww=str(jj.span.get_text())
out = "".join(ww.split())
jianjie.append(out) #匹配简介
time.sleep(2)
except:
print('爬取失败')
m = {"剧名": juming,"时间": shijian,"排名":paiming,"导演":daoyan,"评分":pingfen,"评价人数":pingren,"简介":jianjie}
file=pd.DataFrame(m)
df=file.sort_values(by='排名',ascending=True)
df.to_csv("./豆瓣.csv", encoding="utf-8",index=False)
2、网页结构分析
在分析网页结构的同时考虑到后期的数据分析及展示,所以直接将拿到的数据进行清理整合
(1)、 电影排名都在class="top250-no"的span标签里,这里用select方法拿到电影排名,拿到排名后将排名转换为整数型

(2)、然后开始获取接下来的内容电影名字、上映时间、导演名字、评分、评论人数,发现这些内容的ID属性都一样都是id="content",然后就可以分步获取
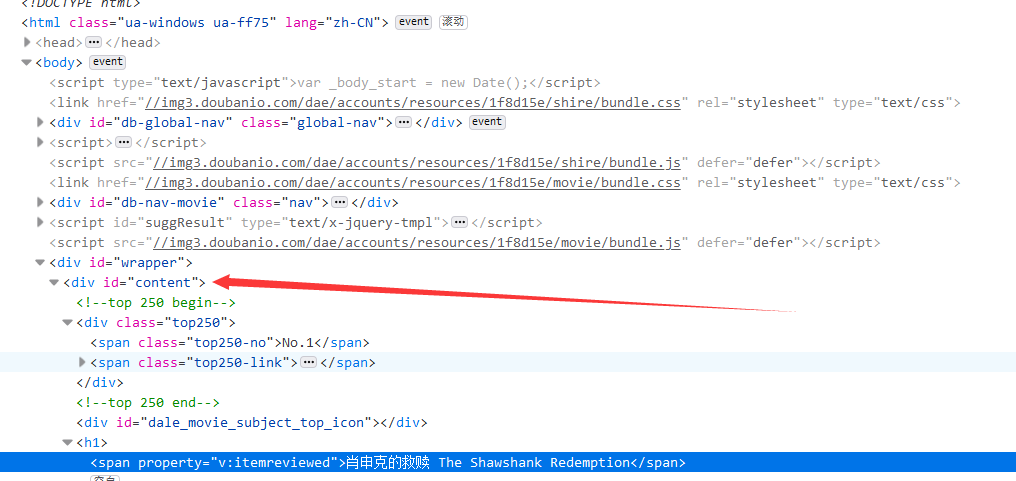
(3)、电影名字都在h1标签下的span标签

(4)、匹配导演名字

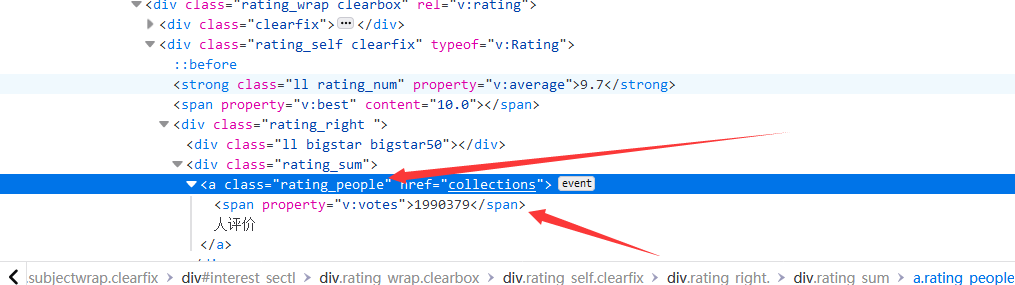
(5)、匹配评价人数
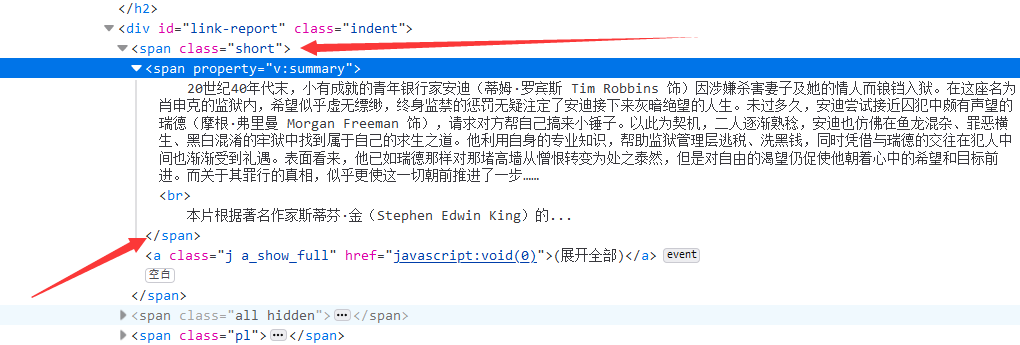
(6)、匹配电影简介
到此为止单个的网页解析已经完毕,下面要拿到所有电影的URL
3、拿到所有的电影的url
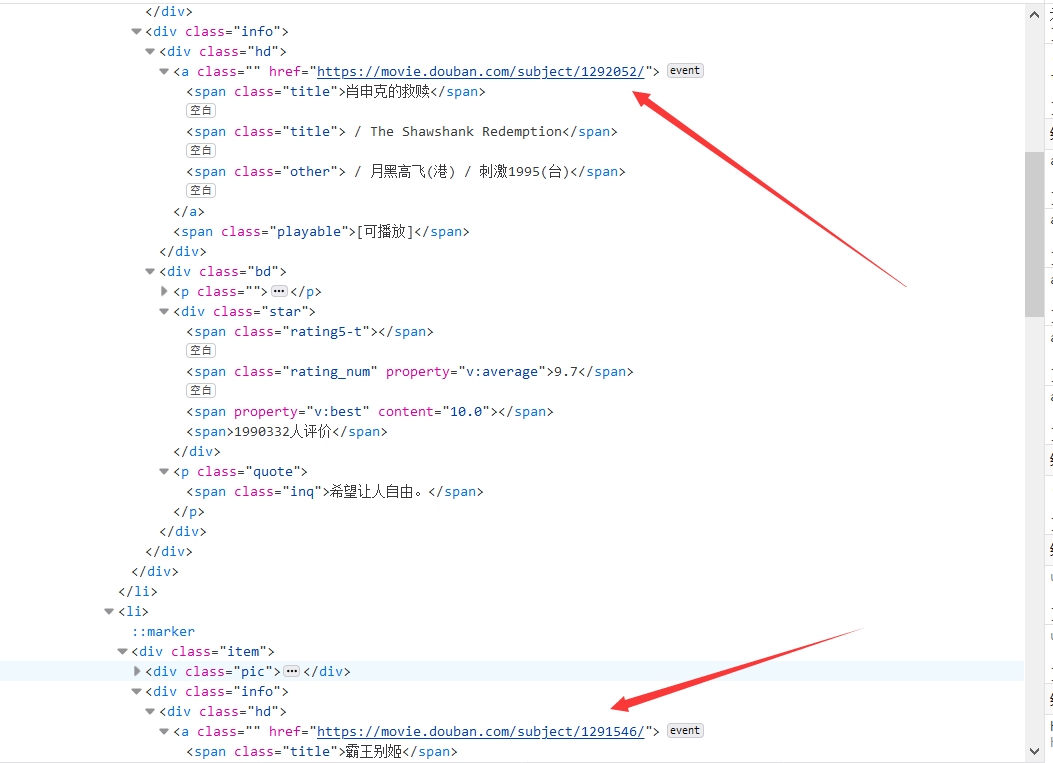
每一页25个电影的URL,用正则匹配出来
一共十页,观察每页URL的规律
二、分析
1、词云图
(1)代码
import re # 正则表达式库
import collections # 词频统计库
import pandas as pd
import jieba # 结巴分词
import wordcloud # 词云展示库
import matplotlib.pyplot as plt
num=eval(input('请输入电影排名:'))
datapath = './豆瓣.csv'
df = pd.read_csv(datapath,encoding='utf-8')
a=list(df['简介'])
string_data=a[num-1] #
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"')
string_data = re.sub(pattern, '', string_data)
seg_list_exact = jieba.cut(string_data, cut_all = False)
object_list = []
path = 'stoplist.txt'
file_in = open(path, 'r', encoding='utf-8')
content = file_in.read()
remove_words = list(content)
for word in seg_list_exact:
if word not in remove_words:
object_list.append(word)
word_counts = collections.Counter(object_list)
word_counts_top10 = word_counts.most_common(10)
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf',
max_words=50,
max_font_size=100,
scale=5
)
wc.generate_from_frequencies(word_counts)
# image_colors = wordcloud.ImageColorGenerator(mask)
# wc.recolor(color_func=image_colors)
plt.imshow(wc)
plt.axis('off')
plt.show()
(2)效果
排名第二的“霸王别姬”’词云效果图

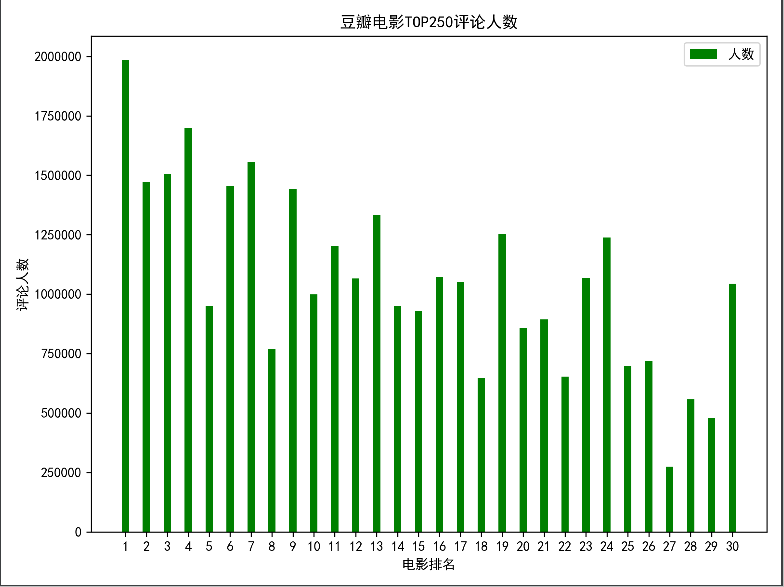
2、评论人数图
(1)代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
datapath = './豆瓣.csv'
df = pd.read_csv(datapath,encoding='utf-8')
a=list(df['排名'])[0:30]
b=list(df['评价人数'])[0:30]
plt.figure(figsize=(8, 6), dpi=300)
plt.title('豆瓣电影TOP250评论人数')
plt.xlabel('电影排名')
plt.ylabel('评论人数')
values = b
width = 0.35
p2 = plt.bar(a, values, width,label='人数', color="green")
plt.xticks(tuple(a))
plt.legend()
plt.show()
3、效果
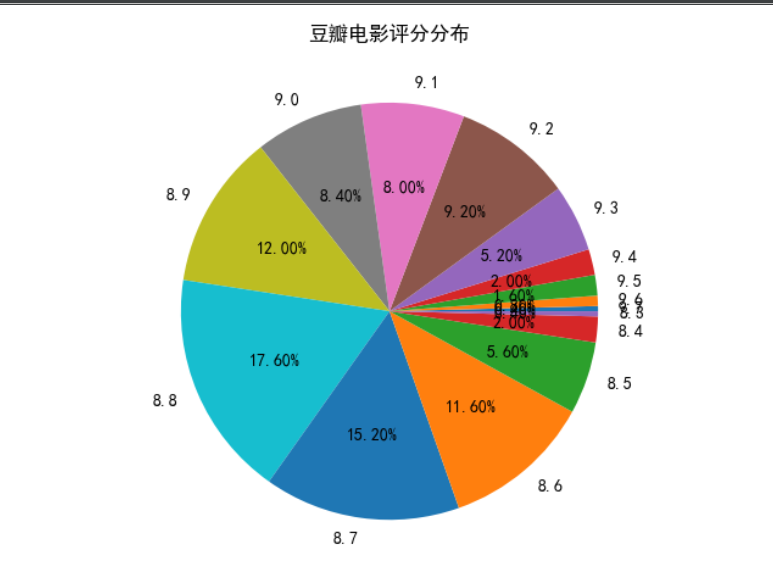
3、电影评分布图
(1)代码
import pandas as pd
import matplotlib.pyplot as plt
import collections # 词频统计库
datapath = './豆瓣.csv'
df = pd.read_csv(datapath,encoding='utf-8')
aa=list(df['评分'])
word_counts = collections.Counter(aa)
word_counts_top10 = word_counts.most_common(10)
print(word_counts_top10)
bb=dict(word_counts)
mm=list(bb.keys())
nn=list(bb.values())
plt.rcParams['font.sans-serif']=['SimHei']
label = mm
fractions = nn
plt.pie(fractions,labels=label,autopct='%1.2f%%')
plt.title("豆瓣电影评分分布")
plt.show()
(2)效果
四、结论:
1、通过主题数据的分析与可视化可以让数据更加清楚直观。
2、经过这次的课程设计,将之前学的内容进行了一个整合,复习,应用到了课程设计中,但是还有很多地方不够熟练,需要多加练习。

