

机器学习概述
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
Python环境

pip list截图
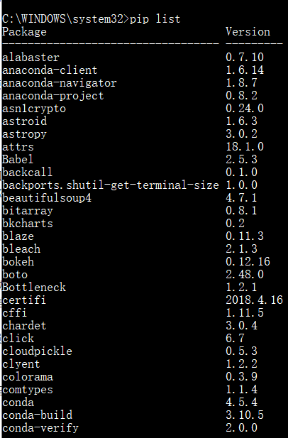
基本库,如numpy、pandas、scipy、matplot

2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
机器学习可以解决给定数据的预测问题,如数据清洗或特征选择,确定算法模型或参数优化,以及结果预测。
机器学习不能解决大数据存储或并行计算,不能做一个机器人。
举例:
机器学习:“盯住2号位, 她很容易起快球”。
传统算法:排球规则。


导数:简单的说,导数就是曲线的斜率,是曲线变化快慢的反应。二阶导数是斜率变化快慢的反应,表征曲线凸凹性。二阶导数连续的曲线,往往称之为“ 光顺”的。还记得高中物理老师时常念叨的:加速度的方向总是指向轨迹曲线凹的一侧。
根据 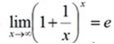 可以得到函数f(x)=lnx的导数,进一步根据换底公式、反函数求导等,得到其他初等函数的导数。
可以得到函数f(x)=lnx的导数,进一步根据换底公式、反函数求导等,得到其他初等函数的导数。
积分应用2: N→∞→InN!→N(InN-1)
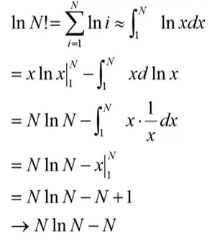
Taylor公式- Maclaurin公式:
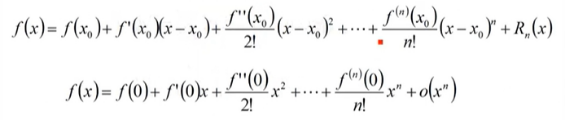
Taylor公式的应用1:
数值计算:初等函数值的计算(在原点展开)
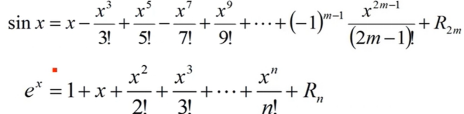
在实践中,往往需要做一定程度的变换。
Taylor公式的应用2
考察Gini系数的图像、熵、分类误差率三者之间的关系
将f(x)=-Inx在x=l处一阶展开,忽略高阶无穷小,得到f(x)≈1-x

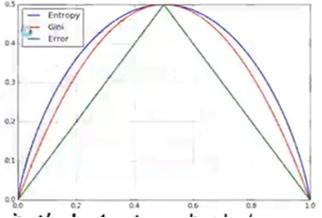
方向导数:
如果函数z= =f(x,y)在点P(x,y)是可微分的,那么,函数在该点沿任一方向L的方向导数都存在,且有:
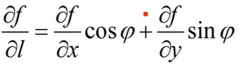
其中,ψ为x辅到方向L的转角。
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
1.什么是机器学习?
对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
这里最重要的是机器学习的对象:
①任务Task,T,一个或者多个
②经验Experience,E
③性能Performance,P
即:随着任务的不断执行,经验的累积会带来计算机性能的提升。
Tom Michael Mitchell, 1997
换个表述
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
2.机器学习有哪些分类?
目前机器学习主流分为监督学习、无监督学习、增强学习。
监督学习:
监督学习可分为“回归”和“分类”问题。
在回归问题中,我们会预测一个连续值。也就是说我们试图将输入变量和输出用一个连续函数对应起来;而在分类问题中,我们会预测一个离散值,我们试图将输入变量与离散的类别对应起来。
每个数据点都会获得标注,如类别标签或与数值相关的标签。一个类别标签的例子:将图片分类为「苹果」或「橘子」;数值标签的例子如:预测一套二手房的售价。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。例如,准确识别新照片上的水果(分类)或者预测二手房的售价(回归)。
无监督学习:
在无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构。
在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。数据点没有相关的标签。相反,无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构。这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。
例如,对于收集到的论文,根据每个论文的特征量如词频,句子长,页数等进行分组。
强化学习:
Alphago用的就是强化学习,强化学习是一种学习模型,它并不会直接给你解决方案——你要通过试错去找到解决方案。
强化学习不需要标签,你选择的行动(move)越好,得到的反馈越多,所以你能通过执行这些行动看是输是赢来学习下围棋,不需要有人告诉你什么是好的行动什么是坏的行动。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号