分析一套源代码的代码规范和风格并讨论如何改进优化代码
我的工程实践是关于金融文本数据挖掘的,恰好github上有同样题目的项目,且该项目使用了python语言。接下来将分析该项目的源代码的代码规范及风格。
1.目录结构及文件命名
由上图可以看出,目录结构清晰明了,大多数文件命名还是简洁易懂,且在README文件中有对文件实现功能的说明。整体来讲,目录结构清晰,文件命名简洁易懂。
2.代码规范
2.1 类名、函数名
python中类名采用每个单词首字母大写的方式,函数名采用部小写字母,并且以下划线分隔单词的形式命名。观察整个代码,发现只有少数函数名的命名符合规范,这一部分如下图所示。
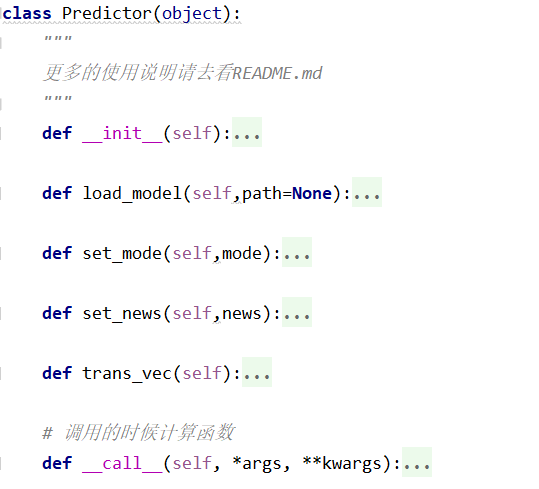
函数除命名不规范之外,有的函数命名并不能让人一眼看出该函数的作用,并且整个代码中20%左右的函数没有注释说明其作用。这一方面有待改进。
2.2 变量名
在python中,函数里的变量名需要小写。看下面一段代码:


#爬取数据 def spider(stockCode,year,season): #字符化处理 stockCodeStr = str(stockCode) yearStr = str(year) seasonStr = str(season) url = 'http://quotes.money.163.com/trade/lsjysj_' + stockCodeStr + '.html?year=' + yearStr + '&season=' + seasonStr #print(url) data = requests.get(url, headers=headers) soup = BeautifulSoup(data.text, 'lxml') table = soup.findAll('table', {'class': 'table_bg001'})[0] rows = table.findAll('tr') # print(rows[:0:-1]) #返回一个季度的交易数据 return rows[:0:-1]
整个代码中,变量名的命名如同上面部分代码所示,大多数变量名的命名是符合规范的,但也有部分是不符合规范的,例如上面代码中的seasonStr、stockCodeStr。
2.3 接口
除导入之外,整个代码中,使用接口之处很少,只在连接数据库时使用了接口。具体看下面一段代码:
def toMysql(rows): # 数据库的链接 conn = pymysql.connect(host='localhost', port=3306, user='root', password='', db='testdata', charset='utf8mb4') try: # 获取会话指针 with conn.cursor() as cursor: # 创建sql语句 sql = "insert into `sz50data`(`date`,`close`) values(%s,%s)" # 执行sql语句 cursor.execute(sql, (rows[0], rows[4])) # 提交 conn.commit() # print('sql commit ok') finally: conn.close()
通过这段代码可以看出,接口使用是符合规范的。
2.4 单元测试
源代码中在清洗网页数据标签时,进行了一段测试,具体如下所示:
ef test(): # 下面是一段html的测试代码 test_html = """ <div id="sidebar"> <div id="tools"> <h5 id="tools_example"><a href="/example/xmle_examples.asp"> XML 实例,特殊字符:15(处理之后应该没有了)</a></h5> <h5 id="tools_quiz"><a href="/xml/xml_quiz.asp"><XML 测验></a></h5> <h3>'vevev'</h3> </div> <div id="ad"> <script type="text/javascript"><!-- google_ad_client = "ca-pub-3381531532877742"; /* sidebar-160x600 */ google_ad_slot = "3772569310"; google_ad_width = 160; google_ad_height = 600; //--> </script> <script type="text/javascript" src="http://pagead2.googlesyndication.com/pagead/show_ads.js"> </script> </div> </div> """ print(cleanHtml(test_html,'】15'))
3.符合规范的代码片段
if __name__ == '__main__': modes = 5 # 一共5种word2vec方法 loadStopwords() loadEmotionwords() loadWords(stopList) loadDocument(stopList) resultX = [] resultY = [] logfile = [] # 留作bug for doc in os.listdir(documentPath): if doc[:3] in ('pos', 'neg', 'neu'): logfile.append(doc) # logfile存储每个文件id和对应tag # 以后会用它计算结果3*3的矩阵 with open(os.path.join('result', 'log', 'logfile.plk'), 'wb') as f: pickle.dump(logfile, f) # 存取 for mode in range(modes): x = [] y = [] for doc in os.listdir(documentPath): news = None news_file_path = os.path.join(documentPath, doc) if doc[:3] in ('neg', 'neu', 'pos'): with open(news_file_path, 'r', encoding='utf-8') as f: news = f.read() x.append(words2Vec(news, emotionList, stopList, posList, negList, mode=mode)) if doc.startswith('neg'): y.append(-1) elif doc.startswith('neu'): y.append(0) else: y.append(1) print('In', mode, news_file_path) resultX.append(np.array(x)) resultY.append(np.array(y)) np.savez(os.path.join('result', 'vector', 'resultX.npz'), onehot=resultX[0], wordfreq=resultX[1], twovec=resultX[2], tfidf=resultX[3], outofdict=resultX[4]) np.savez(os.path.join('result', 'vector', 'resultY.npz'), onehot=resultY[0], wordfreq=resultY[1], twovec=resultY[2], tfidf=resultY[3], outofdict=resultY[4]) print('Over')
4.代码进一步改进优化
整个代码中,有许多地方命名不规范,空格使用不规范,但大体上代码还是很清晰的,因此代码的进一步优化工作是命名、空格使用的规范及添加必要的注释。
5.python 代码编写规范
5.1 代码编排
1)缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
2)每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
3)类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
5.2 文档编排
1)模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
2)不要在一句import中多个库,比如import os, sys不推荐。
3)如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
5.3 空格的使用
总体原则,避免不必要的空格。
1)各种右括号前不要加空格。
2)逗号、冒号、分号前不要加空格。
3)函数的左括号前不要加空格。如Func(1)。
4)序列的左括号前不要加空格。如list[2]。
5)操作符左右各加一个空格,不要为了对齐增加空格。
6)函数默认参数使用的赋值符左右省略空格。
7)不要将多句语句写在同一行,尽管使用‘;’允许。
8)if/for/while语句中,即使执行语句只有一句,也必须另起一行。
5.4 注释
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!
注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
1)块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如:
# Description : Module config.
#
# Input : None
#
# Output : None
2)行注释,在一句代码后加注释。比如:x = x + 1 # Increment x
但是这种方式尽量少使用。
3)避免无谓的注释。
5.5 文档描述
1)为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
2)如果docstring要换行,参考如下例子,详见PEP 257
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
5.6 命名规范
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
1)尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。
2)模块命名尽量短小,使用全部小写的方式,可以使用下划线。
3)包命名尽量短小,使用全部小写的方式,不可以使用下划线。
4)类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。
5)异常命名使用CapWords+Error后缀的方式。
6)全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。
7)函数命名使用全部小写的方式,可以使用下划线。
8)常量命名使用全部大写的方式,可以使用下划线。
9)类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
10)类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。
11)类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
12)为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
13)类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号