
网络爬虫作业
题目如下:
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
爬取页面如下:
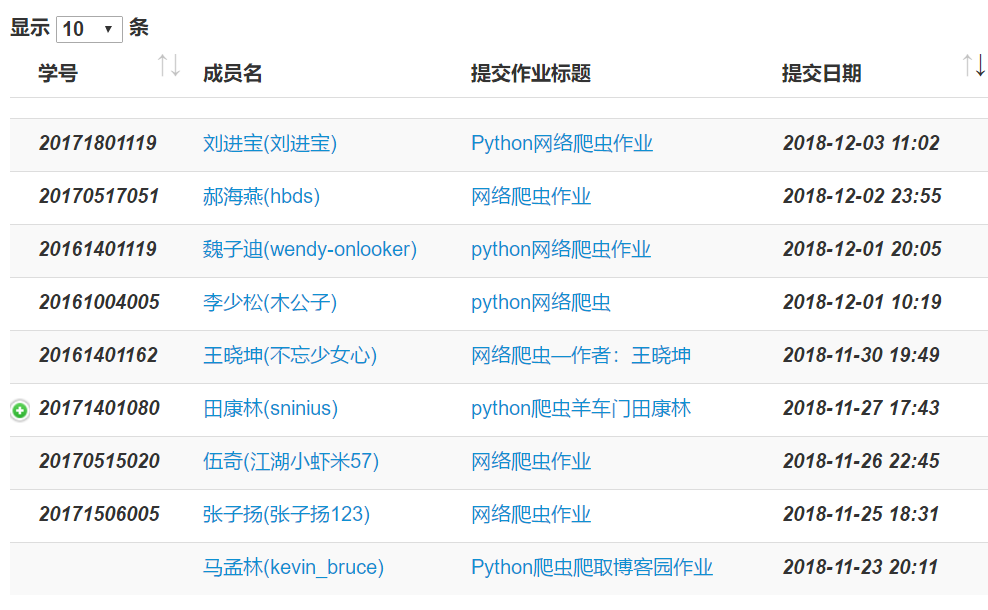
在对应位置鼠标右键——审查元素,可以找到对应代码如图:

紧接着我们需要拿到这部分的url 按F12——network中找到对应的name——answer啥的。。。
紧接着也能发现这是一个json文件。

代码如下:
import requests as r import json import time try: a = r.get('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543758681318') except: print('Error') def cd(): b = json.loads(a.text)['data'] e = '' for i in b: c = (str(i['StudentNo']) + ',' + str(i['RealName']) + ',' + str(i['Title']) + ',' + str(i['DateAdded'].replace('T',' ')) + ',' + str(i['BlogUrl'])).replace('None','助教') e = e + c + '\n' print(e) with open('E:\\hwlist.csv','w') as f: f.write(e) while True: cd() time.sleep(2500)
结果:
学生序号有问题不知道为啥。。。‘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号