数据分析 第五篇:异常值分析
异常值在统计学上的全称是疑似异常值,也称作离群点(outlier),异常值的分析也称作离群点分析。异常值是指样本中出现的“极端值”,数据值看起来异常大或异常小,其分布明显偏离其余的观测值。异常值分析是检验数据中是否存在不合常理的数据,在数据分析中,既不能忽视异常值的存在,也不能简单地把异常值从数据分析中剔除。重视异常值的出现,分析其产生的原因,常常成为发现新问题进而改进决策的契机。
从散点图上,可以直观地看到离群点,离群点是孤立的一个数据点;从分布上来看,离群点远离数据集中的其他数据点。
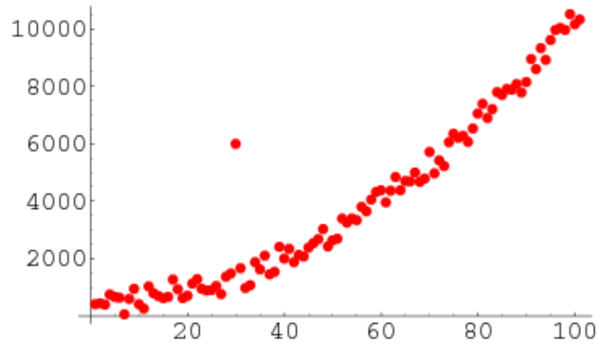
在上图中,离群点(outlier)跟其他观测点的偏离非常大,注意,离群点是异常的数据点,但是不一定是错误的数据点。
一,离群点检测
在数据处理过程中,可以对数据做一个描述性分析,进而查看哪些数据是不合理的。常用的统计量是最大值和最小值,用来判断变量的取值是否超出了合理的范围,例如,客户年龄的最大值是199,该值存在异常。
除此之外,检测离断点的方法,通常有Z-score 和 IQR。
1,Z-score方法
在介绍Z-score方法之前,先了解一下 3∂原则,
3σ原则
如果数据服从正态分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布下,距离平均值3σ之外的值出现的概率为 P(|x-μ|>3σ)<=0.003,属于极个别的小概率事件。
如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
这个原则有个前提条件:数据需要服从正态分布。
在3∂原则下,如果观测值与平均值的差值超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。
如果数据不服从正态分布,那么可以用远离平均值的多少倍标准差来描述,倍数就是Z-score。Z-score以标准差为单位去度量某一原始分数偏离平均数的距离,它回答了一个问题:"一个给定分数距离平均数多少个标准差?",Z-score的公式是:
Z-score = (Observation — Mean)/Standard Deviation
z = (X — μ) / σ
Z-score需要根据经验和实际情况来决定,通常把远离标准差3倍距离以上的数据点视为离群点,也就是说,把Z-score大于3的数据点视作离群点,Python代码的实现如下:
import numpy as np import pandas as pd def detect_outliers(data,threshold=3): mean_d = np.mean(data) std_d = np.std(data) outliers = [] for y in data_d: z_score= (y - mean_d)/std_d if np.abs(z_score) > threshold: outliers.append(y) return outliers
2,IQR方法
四分位点内距(Inter-Quartile Range,IQR),是指在第75个百分点与第25个百分点的差值,或者说,上、下四分位数之间的差,计算IQR的公式是:
IQR = Q3 − Q1
IQR是统计分散程度的一个度量,分散程度通过需要借助箱线图来观察,通常把小于 Q1 - 1.5 * IQR 或者大于 Q3 + 1.5 * IQR的数据点视作离群点,探测离群点的公式是:
outliers = value < ( Q1 - 1.5 * IQR ) or value > ( Q3 + 1.5 * IQR )
这种探测离群点的方法,是箱线图默认的方法,箱线图提供了识别异常值/离群点的一个标准:
异常值通常被定义为小于 QL - l.5 IQR 或者 大于 Qu + 1.5 IQR的值,QL称为下四分位数, Qu称为上四分位数,IQR称为四分位数间距,是Qu上四分位数和QL下四分位数之差,其间包括了全部观察值的一半。
箱线图的各个组成部分的名称及其位置如下图所示:
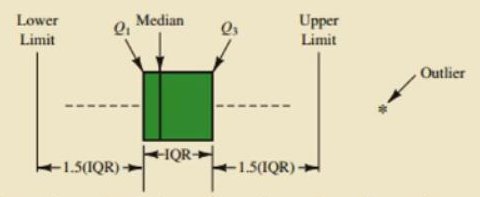
箱线图可以直观地看出数据集的以下重要特性:
- 中心位置:中位数所在的位置就是数据集的中心,从中心位置向上或向下看,可以看出数据的倾斜程度。
- 散布程度:箱线图分为多个区间,区间较短时,表示落在该区间的点较集中;
- 对称性:如果中位数位于箱子的中间位置,那么数据分布较为对称;如果极值离中位数的距离较大,那么表示数据分布倾斜。
- 离群点:离群点分布在箱线图的上下边缘之外。
使用Python实现,参数sr是Series类型的变量:
def detect_outliers(sr): q1 = sr.quantile(0.25) q3 = sr.quantile(0.75) iqr = q3-q1 #Interquartile range fence_low = q1-1.5*iqr fence_high = q3+1.5*iqr outliers = sr.loc[(sr < fence_low) | (sr > fence_high)] return outliers
二,异常值的处理
在数据处理时,异常值的处理方法,需视具体情况而定。有时,异常值也可能是正常的值,只不过异常的大或小,所以,很多情况下,要先分析异常值出现的可能原因,再判断如何处理异常值。
处理的异常值的常用方法有:
- 删除含有异常值的记录;
- 插补,把异常值视为缺失值,使用缺失值的处理方法进行处理,好处是利用现有数据对异常值进行替换,或插补;
- 不处理,直接在含有异常值的数据集上进行数据分析;
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号