统计2:随机变量及其分布
在一些随机试验中,结果可以用数值来表示,此时样本空间S的元素是数字;但是,有些试验,当样本空间S的元素不是数字时,就需要引入随机变量的概念了。
设S是样本空间,把随机试验的每一个结果,即把S的每个元素e与实数对应起来,从而便于对S进行描述和研究。
一,随机变量
定义 设随机试验的样本空间为S={e},X=X(e)是定义在样本空间S上的单值函数,称X=X(e)为随机变量。
(1),有许多随机试验,结果本身是一个数,即样本点e本身是一个数,令X=X(e)=e,那么X就是一个随机变量。
(2),把一枚硬币抛掷三次,把出现正面记作A,把出现反面记作B,那么样本空间S={e}={AAA,AAB,ABA,ABB,BAA,BAB,BBA,BBB},
设随机变量X是出现正面的次数,那么随机变量X=X(e)={0,1,2,3},
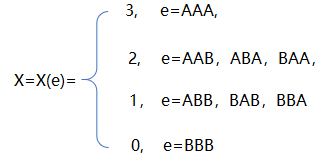
由此,可以计算出:随机变量X=2发生的的概率是 P{X=2}=P{AAB, ABA, BAA}=3/8。
因为随机变量是元素的单值函数,所以随机变量对应样本空间的一个或多个元素。
如何计算随机变量的概率,下文给出了三种方式:
- 分布律:适用于离散型随机变量
- 分布函数:适用于离散型随机变量和连续型随机变量
- 概率密度函数:适用于连续型随机变量
注意:连续型随机变量取任意指定的实数值的概率都等于0,即P{X=a} =0,但是,概率为0并不意味着,{X=a}是不可能事件,只是事件{X=a}发生的概率非常小,小到几乎不可能发生。
二,离散型随机变量
有些随机变量,它全部可能取到的值是有限多个或可列无线多个,这种随机变量称为离散型随机变量。
要掌握一个离散型随机变量X的统计规律,只需要直到X的所有可能取值,以及取每一个可能值得概率。
设离散型随机变量X所有可能取值为xk(k=1,2,...),X取各个可能值得概率,即事件{X=xk}的概率为:
P{X=xk}=pk,k=1,2,...
离散型随机变量常用的分布规律是:0-1分布律,二项分布率,泊松分布律,读者需要知道分布律的特性。
1,0-1分布律
对于一个随机变量,如果样本空间只包含两个元素,即S={e1,e2},可以定义随机变量X来描述随机试验的结果:
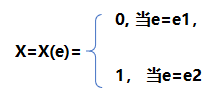
随机变量X只可能取值0和1两个值,分布律是:
P{X=k}=pk(1-p)1-k, k=0,1 (0<p<1)
2,二项分布律
设试验E只有两个可能结果A和B,设P(A)=p( 0<p<1),此时P(B)=1-p,把试验E独立重复地进行n次,则称这一串重复的独立试验服从二项分布律:
随机变量X只可能取值0和1两个值,把分布律是:
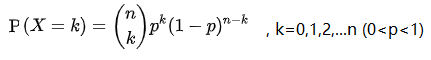
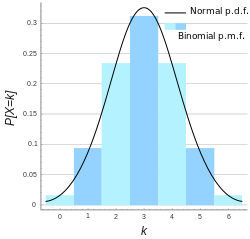
对于固定的n和p,二项分布b(n,p)的概率分布是:当k增加时,概率P{X=k}先是随之增加,直至达到最大值,随后单调减少。
3,泊松分布律
设随机变量X所有可能取得值是0,1,2,...,而取各个值得概率是:
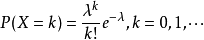
其中参数λ>0,是常数,泊松分布的参数λ是单位时间内随机事件平均发生的次数。泊松分布的图形大概是
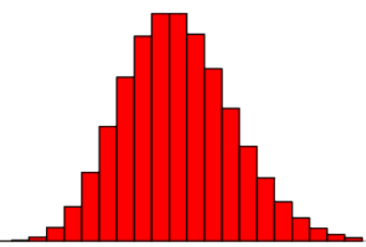
可以看到,泊松分布的特点是概率先随着k值的增加而增加,再达到顶点后,随着k值的增加而减少。
泊松分布和二项分布得图形很相似,实际上,可以使用泊松分布来逼近二项分布:
设λ>0 是常数,n是任意正整数,设np=λ,以n,p为参数得二项分布得概率值,可以有参数为λ=np得泊松分布概率值近似,可以用作二项分布概率的近似计算。
三,随机变量的分布函数
为了研究随机变量取值落在一个区间(x1, x2]的概率: P{x1<X<=x2}
引入随机变量的分布函数:
定义 设X是一个随机变量,x是任意实数,函数
F(x)=P{X<=x}
称作X的分布函数,对于任意实数x1,x2 (x1<x2),如何计算随机变量X落在区间(x1, x2]的概率?
P{x1<X<=x2}=P{X<=x2}-P{x<=x1}=F(x2)-F(x1)
因此,如果已知X的分布函数,就知道X落在任一区间(x1, x2]的概率,从这个意义上说,分布函数完整地描述了随机变量的统计规律性。
分布函数是一个普通的函数,如果把X看成数轴上的随机点的坐标,那么分布函数F(x)在x处的函数值就表示X落在区间(-∞, x]上的概率。
四,连续型随机变量的概率密度函数
定义 如果对于随机变量X的分布函数F(x),存在非负可积函数f(x),使对于任意实数x有分布函数:
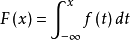
则X为连续型随机变量,称f(x)为X的概率密度函数,简称为概率密度。
如何通过概率密度函数计算随机变量的概率?对于任意实数a,b(a<=b),随机变量的取值落在区间(a,b]的概率是:
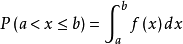
连续性随机变量使用概率密度来研究,服从概率密度函数, 概率密度是什么意思?简单来说,就是连续随机变量落在某个区间的面积就是其概率。
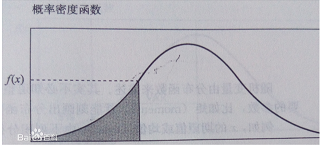
读者需要知道常用的概率密度是:均匀分布,指数分布和正态分布。
1,均匀分布
均匀分布的概率密度函数为:
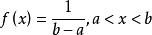
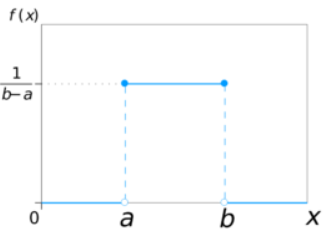
均分分布的概率密度函数是,落在区间(a,b)内任意等长度的子区间内的可能性是相同的,或者说,落在(a,b)的子区间内的概率只依赖于子区间的长度,而与子区间的位置无关。
2,指数分布
指数分布概率分布函数是:
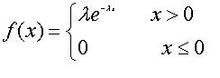
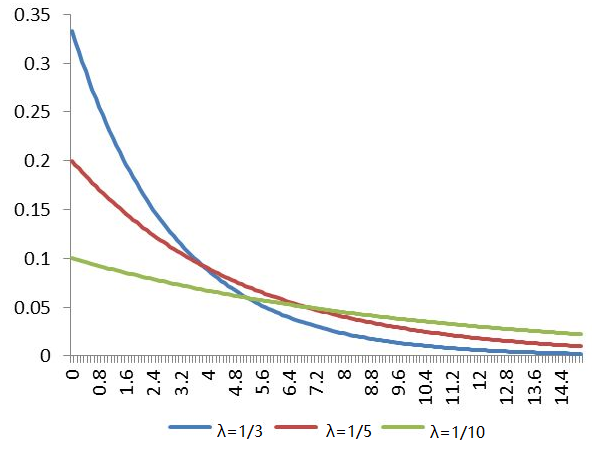
其中λ > 0为常数,指数分布的概率密度函数如下图所示:
3,正态分布
正态分布的的概率密度函数是,其中μ,σ( σ>0)为常数,μ是数学期望,σ是标准差。
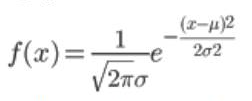
若随机变量X服从一个数学期望为μ、方差为σ2的正态分布,记为X~N(μ,σ2),其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
正态分布的概率密度图形如下所示,其图形是关于x=μ对称的,当x=μ时取得最大值。x离μ越远,f(x)的取值越小,这表明,对于同样长度的区间,当区间远离μ时,X落在这个区间上的概率越小。
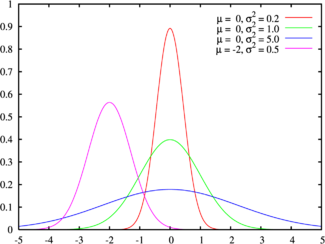
结论:
- x离μ越远,f(x)的取值越小,这表明,对于同样长度的区间,当区间远离μ时,X落在这个区间上的概率越小。
- 若 X~N(μ,σ2),那么随机变量X的期望和方差是:E(X)=μ,D(X)=σ2。
我们把μ = 0,σ = 1的正态分布是标准正态分布。
在自然和社会现象中,大量随机变量都服从或近似服从正态分布。
五,一维随机变量的函数的分布
定义 设X是随机变量,那么Y=g(X)是随机变量的函数;当X取值x时,Y取值g(x)。
如何计算Y的概率分布?可以通过随机变量X来计算Y的概率:
- 当已知X的分布律时,可以通过X的分布律来计算Y的分布律;
- 当已知X的分布函数时,可以通过X的分布函数来计算Y的分布函数;
- 当已知X的概率密度函数时,可以通过X的概率密度函数来计算Y的概率密度函数。
因此,Y是另一个随机变量,其概率可以由随机变量X来计算。
六,二维随机变量
在实际问题中,对于某些随机试验的结果,需要同时用两个或两个以上的随机变量来描述,例如,为了研究某一个地区学龄前儿童的发育情况,对这一地区的儿童进行抽样,对于每个儿童都能观察到身高(H)和体重(W),因此,设样本空间S={e}={某地区的全部学龄前儿童},而H(e)和W(e)是定义在S上的两个随机变量。
设E是一个随机试验,样本空间是S={e},设X=X(e),Y=Y(e)是定义在S上的随机变量,把(X,Y)叫做二维随机变量。
二维随机变量(X,Y)的性质不仅跟X和Y有关,而且还依赖于这俩那哥哥随机变量的相互关系。因此,逐个地研究X和Y的性质是不够的,还需要将(X,Y)看作一个整体来进行。
定义 设(X,Y)是二维随机变量,对于任意实数x,y,二元函数:
F(x)=P{X<=x 且 Y<=y}=P{X<=x, Y<=y}
称作二维随机变量(X,Y)的分布函数,或称为随机变量X和Y的联合分布函数。
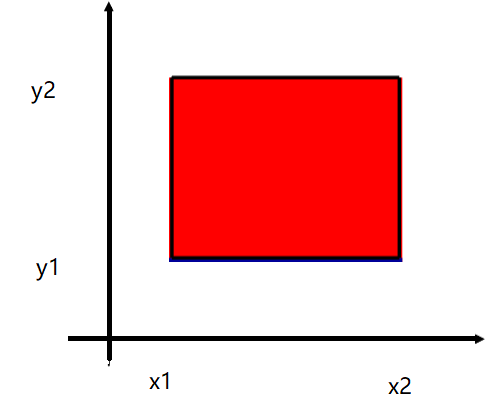
如果把二维随机变量(X,Y)看作是平面上随机点的坐标,那么容易计算出随机点(X,Y)落在举行区域{(x,y) | x1<x<=x2, y1<y<=y2}的概率为:
P{x1 < X <=x2, y1<Y<=y2}=F(x2,y2) + F(x1+y1) - F(x2,y1) - F(x1,y2)
七,相互独立的多维随机变量
定义 设F(x,y)和Fx(x,y),Fy(x,y)分别是二维随机变量(X,Y)的分布函数以及边缘分布函数,若对于所有x,y,有
P{X<=x, Y<=y}=P{X<=x} P{Y<=x}, 即F(x,y)=Fx(x,y) Fy(x,y) ,
则称随机变量X和Y是相互独立的。把二维随机变量推广到n维随机变量(X1,X2,...,Xn),得到n维随机变量的分布函数定义为:
F(x1,x2,...,xn)=P{X1<=x1,X2<=x2,...,Xn<=xn},其中 x1,x2,...,xn为任意实数。
如果X1,X2,...Xn是相互独立的,那么
F(x1,x2,...,xn)=Fx1(x1) Fx2(x2) ... Fxn(xn)
定理:设(X1,X2,...,Xm)和(Y1,Y2,...,Yn)相互独立,则Xi(i=1,2,...,m)和Yj(j=1,2,...,n)相互独立,如果h,g是连续函数,则h(X1,X2,...,Xm)和g(Y1,Y2,...,Yn)相互独立。
八,随机变量的函数的分布
设X,Y相互独立,且X和Y都服从正态分布,那么随机变量Z=X+Y也服从正态分布。
这个结论还能推广到n个独立的服从正态分布的随机变量之和的情况,
即,若Xi(i=1,2,...,n)相互独立,且服从正态分布,那么Z=X1+X2+...+Xn 仍然服从正态分布。
一般,有限个相互独立的,且服从正态分布的随机变量的线性组合仍然服从正态分布。
九,大数定律
大数定律(law of large numbers),是一种描述当试验次数很大时所呈现的概率性质的定律。
1,弱大数定律(辛钦大数定理)
设随机变量X1,X2,...,Xnx相互独立,服从同一个分布,且具有相同的数学期望μ,则序列的期望:
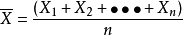
以概率收敛于μ,也就是说,随着n的增大, ![]() 与μ之间的误差会越来越小。
与μ之间的误差会越来越小。
白话:一个团的军人的平均身高是a,n个团的军人的平均身高近似等于a。
2,伯努利大数定理
当n足够大时,事件A出现的频率将几乎接近于其发生的概率,即频率的稳定性。
白话:如果一个团的军人数量足够多,那么这个团的军人的平均身高是稳定的。
3,切比雪夫大数定理
随着样本容量n的增加,样本平均数将接近于总体平均数。从而为统计推断中依据样本平均数估计总体平均数提供了理论依据。
白话:如果一个团的军人数量足够多,那这个团的军人平均身高可以代表整个军队的军人的平均身高。
十,中心极限定理
中心极限定理表明,在相当一般的条件下,当独立随机变量的个数不断增加时,其和的分布趋于正态分布。通俗地说,如果一个事件受到N(N趋近于无穷)个独立因素的共同影响,且每个因素产生的影响都是独立的,那么这个事件发生的概率就服从中心极限定理,收敛于正态分布。因此,在实际应用中,正态分布是非常重要的,只要影响因素足够多,每个因素的作用都很微小,不必考虑每个因素服从什么分布,都可以用正态分布来预测事件发生的概率。
1,独立同分布的中心极限定理
设随机变量X1,X2,...,Xn相互独立,服从同一分布,并且具有有限的数学期望和方差:E(Xi)=μ,D(Xi)=σ2 >0 (k=1,2....),
当n很大时,随机变量之和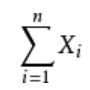 的标准化变量:
的标准化变量: ![]() 近似地服从标准正态分布N(0,1)。
近似地服从标准正态分布N(0,1)。
因此,当n很大时, ![]() 近似地服从正态分布N(nμ,nσ2)。该定理是中心极限定理最简单又最常用的一种形式,在实际工作中,只要n足够大,便可以把独立同分布的随机变量之和当作正态变量。
近似地服从正态分布N(nμ,nσ2)。该定理是中心极限定理最简单又最常用的一种形式,在实际工作中,只要n足够大,便可以把独立同分布的随机变量之和当作正态变量。
白话:标准化变量Yn近似地服从标准正态分布。
2,棣莫佛-拉普拉斯定理
设随机变量Yn(n=1,2,...,)服从参数为n,p(0<p<1)的二项分布,则对于任意x,都有
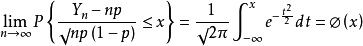
白话:这个定理表明,正态分布是二项分布的极限分布,当n充分大时,可以由该定理近似地求二项分布的概率。
3,不同分布的中心极限定理
设随机变量X1,X2,......Xn,......独立同分布,具有数学期望E(Xk)=μk 和方差 ![]() ,(k=1,2,...), 记:
,(k=1,2,...), 记:![]()
的标准化变量:白话:标准化变量Yn近似地服从标准正态分布。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号