设计数据仓库
数据仓库是数据的仓库,数据是从操作型数据库系统中获取,经过集成处理、按照合适的粒度进行聚合而成的数据的集合。 构建数据仓库,要从数据模型、数据集成、粒度设计和分区设计这四个方面着手,迭代式开发。
一,数据模型
在设计数据仓库之前,首先要了解操作型数据库的数据模型,数据模型分为三个层次:
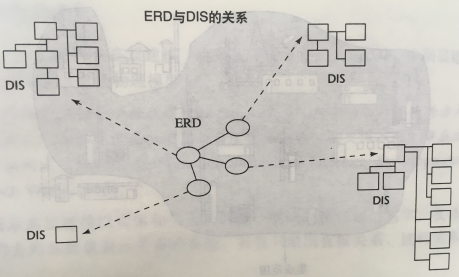
- ERD(实体关系图)是最顶层的概念模型,是实体关系的高度抽象,主要用于确定各个实体(或主题)及其之间的关系;
- 中间层是数据集成(DIS),用于对主要数据分组,设置数据的链接,确定主键、属性和关系;
- 底层是物理模型,用于设计SQL Server的关系表,在这一层上,确定数据的粒度、对数据进行分区、定义引用、创建索引等
1,实体关系图(ERD)
实体关系图是数据之间关系的高度抽象,直接定义了数据模型中的实体(主题)和实体之间的关系,用于理解数据模型中涵盖的主题

2,数据集成(DIS)
对实体-关系模型中标识出的每一个主题或实体,都要建立一个DIS模型,
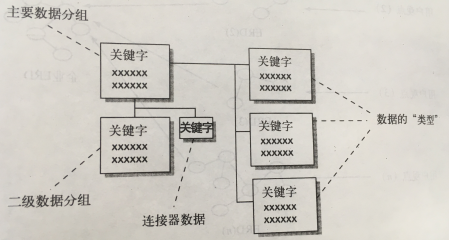
数据集成模型基本上由三部分构成:
- 主要数据分组:每个主题或实体有且只有一个主要数据分组,例如,客户是一个主要数据分组,有客户ID这个唯一标识。
- 二级数据分组:实体的额外属性,例如,客户的居住地址
- 连接器:数据之间的关系,用于把一个数据分组和其他数据分组联系起来
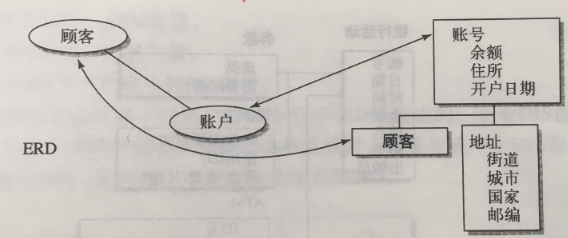
当在ERD层标识一个实体-关系之后,在DIS层就用连接器和数据分组来表现:
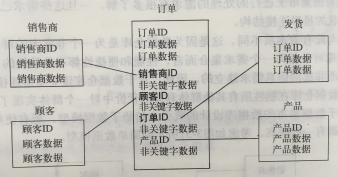
数据分组包含关键字和其他属性,用于对数据分组进行详细的描述。
3,物理模型(关系表)
物理模型是从DIS模型创建而来的, 一般来说,数据集成模型中定义的数据分组,都对应一个关系表,数据分组中的关键字和属性,用于定义关系表的主键和属性列。但是,这些表不能直接用于设计数据库中的关系表,但是,物理模型是设计关系的依据,还要考虑对关系表进行性能优化。
二,数据仓库的性能优化设计
设计关系表的关键是集成数据,设计数据的粒度和分区,另外,为了优化性能,还需要设计缓存,设计冗余字段,去外键,增加层次结构。
1,数据集成
把原始数据集成到数据仓库中,为了性能优化,通常会对数据列做如下处理:
- 增加代理主键:保留业务主键,但是,增加自增的正整数列(代理主键)作为关系表的主键,用于唯一标识实体。
- 增加时间列:记录数据插入的时间(Inserted Time)和数据最新更新的时间(Last Updated Time),便于对数据做增量更新。
- 数据集成时,还需要对数据进行一致性处理,比如,对属性列统一命名,统一编码,统一度量单位等
另外,一般数据仓库中,不会保留长文本数据,如果必须保留长文本数据,建议把该文本列分离出去。对于无效的数据,需要清理出去;对于空值得数据,需要设置默认值等。
2,粒度
在数据仓库中,数据存在着不同的细节级:原始数据(最细节的数据)、当前细节数据、轻度聚合数据和高度聚合数据,数据的粒度升级,是在数据由操作层传输到导出层进行的,一旦数据过期,就由原始数据导出当前细节数据,进而导出聚合数据。我们把聚合之后的数据称作缓存数据,这是为了定向提高某个主题或分析的查询性能。
不同的细节级,实际是由数据粒度的不同导致的,而粒度的升级通常是由时间、类别等属性聚合之后得到的。粒度会深刻地影响存储到数据仓库中的数据量的大小和数据仓库支持的查询类型。数据仓库中数据量的大小和粒度成反比,粒度越低,支持的查询范围越广泛,数据量越大。换句话说,低粒度可以回答任何问题,而高粒度会限制数据所能回答的问题。
由于高粒度会降低数据量,使得查询速度更快;而低粒度能够回答更多的问题,因此,在数据仓库中,一般根据数据被查询的频次,设计多重粒度,这样啊,既能使用高粒度快速响应高频问题,也能使用低粒度回答低频的问题。
3,分区
数据分区是把数据分散到可独立进行IO处理的分离的硬盘中,从根本上来说,分区的好处有两点:
- 利用分区,可以把IO分散到不同的物理硬盘上去,以并发方式访问数据,提高数据查询和更新的速度;
- 利用分区,可以把不常用的数据切换到廉价的大容量硬盘上去,而把常用的数据切换到性能优越的硬盘上去;
对数据分区,需要依据特定的数据列,通常以时间列作为分区列,把不同的时间区间的数据存放到不同的分区中去。
注意:把分区分布于不同的物理硬盘,才能充分利用硬件的IO能力,通常情况下,一块物理硬盘会划分为多个逻辑硬盘,如果把不同的分区放到不同的逻辑硬盘上,而这些逻辑硬盘属于同一个物理硬盘,那么IO实际上不会并发执行。
4,反向规范化
数据模型的输出是一系列的关系表,每个表都包含关键字和属性,典型的OLTP数据库设计的规范是避免冗余,所有的属性都必须依赖于主键,不允许传递依赖(即不允许间接依赖主键),这样设计的结果使更新操作的cost最小化,但是,对于一个查询请求,可能会join多张表,而SQL Server对于多表的Join操作的性能优化能力有限,这会导致查询性能急剧降低。
由于数据仓库很少对数据进行更新,通常是保存历史数据不变;在设计数据仓库时,可以违反第三范式(不允许间接依赖主键),把实体的相关字段合并到一个表中,使相关的数据在物理上是顺序存储的。这样的表结构设计,既能减少了查询语句中使用Join的次数,充分利用SQL Server引擎的优化能力,也能利用物理硬盘的IO特性(顺序读取一块数据),提高数据查询的性能。
另外一个提高查询性能的表设计是根据访问频率来分裂表,当一个列是长文本字段,且访问频次相当低时,可以把该列分离出去,存放到另一个附表中,这样设计表的结果是高频访问的列和窄列放到主表中,低频的长文本列放到副表中,主表和附表通过代理主键关联在一起。
5,缓存设计
由于数据仓库中的数据更新的次数少,对于常用的数据聚合,可以预先把数据计算好,存储到缓存表,也就是说,在数据仓库中,创建不同粒度的关系表。而缓存表中的数据,可以把计算的时间安排在夜晚等非工作时间段,这样,用户在工作时不需要重复计算,只需要查询就可以快速获得结果,提高了工作效率。
6,外键关系
对于参照完整性,在数据仓库中,一般不会创建外键关系,参照完整性是通过“人工”识别的。这样,即使删除了参考表中的数据,也不会影响引用表,只不过join不出结果而已。
把外键关系转换为数据冗余,这也就是数据的反规范化设计,这样做会增大数据仓库使用的存储容量,降低数据更新的性能,但是会加快数据查询的速度,当数据是稳定的,补偿更新时,采用数据冗余是性能优化的设计方案。
7,增加层次结构
层次结构是聚合数据的角度,例如,数据是以天为单位,那么可以设计时间维度,该维度表的层次结构分别是天、周、月、季和年,分析人员可以按照周、月、季和年来聚合数据,以不同的视角来分析数据。常用的层次结构是日期、行政区划,类别等。数据仓库中,肯定是存储在时间维度的,也必定存在日期维度。
8,数据压缩
对于数据仓库而言,IO资源比CPU资源更加稀缺,我们可以使用计算资源换IO资源。虽然压缩和解压缩会浪费CPU资源,但是数据压缩使得数据可以存储到较小的硬盘空间中,也就是说,同样的硬盘空间存储更多的数据,这使得一次IO能够读取更多的数据。
9,索引设计
尽量使用窄列创建索引时,索引不是越多越好,但也不能一个索引都不创建。
对于只插入数据,而极少查询的数据表,可以创建一个自增列作为主键,并创建聚集索引从物理上顺序存储数据;
对于复合主键的情况下,可以创建非聚集索引,而使用自增列作为主键,并创建聚集索引从物理上顺序存储数据;
对于变长数据类型,如果数据经常更新或改变,可能会带来非常严重的性能问题,在创建索引时,尽量不要把变化频繁的变长列作为索引列,考虑作为包含列来处理。
三,多维结构
数据仓库中经常提到的设计方法是多维结构,基于星型连接、事实表和维度表来设计关系表架构,多维方法只适用于数据集市,而不适合数据仓库。数据集市中的表结构是根据部门的特殊需求而建立的,其结构一般是星型连接,包含事实表和维度表,通常由OLAP技术支持。
通常来说,多维结构的特征是:
- 星型连接是指维度表中数据允许冗余,
- 维度表主要存储类别属性和层次结构,
- 事实表存储实体数据,实体的属性通过外键和维度表关联。
使用多维结构的结果是:事实表中基本不存储文本数据,维度表中记录的是实体的类别,时间等属性,大多数是文本数据和层次结构数据。多维结构灵活性不足,通用性不足。
四,设计模型
数据仓库的数据库设计有两种基本模型:关系模型和多维模型,关系模型更加灵活,所以更适合数据仓库的设计,而多维模型更适合数据集市。
1,关系模型
关系模型是OLTP数据库系统的设计模型,表设计符合数据库设计的第一范式、第二范式和第三范式,关系模型提高了数据更新的性能,而牺牲了数据查询的性能。由于OLTP是高更新的数据库系统,因此,关系模型非常适合操作型数据库系统。然而,数据仓库中存储的数据不常更新,更多的是对数据的查询。
关系模型的最大优点是灵活,支持适度变化的需求,适合数据仓库的设计。
2,多维模型
通常认为,多维模型是建立数据仓库的设计方法,多维模型牺牲数据更新的性能,以提高数据查询的性能。多维模型的两种结构是星形连接和雪花形连接,雪花形连接是星形连接的扩展。多维模型存在数据冗余,这会使得,通过一次访问就可以得到一个实体的所有数据,Join操作较少,数据查询较快,可以直接用于OLAP技术。缺点是不够灵活,一旦设计完成,要想改动就很难了。
(1)星形连接
从设计模型上来看,星形连接是以一颗事实表为中心,周围围绕着维度表。
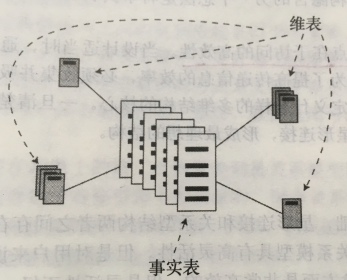
星形连接的中心是一个事实表,事实表是包含大量数据值的一个表;事实表的周围是维度表,用于描述事实表的类别,时间等属性。事实表和维度表通过公共属性(外键)相关联。
(2)雪花形连接
通常,星形连接只包含一张事实表,当需要多张事实表相结合时,这就是雪花形结构:
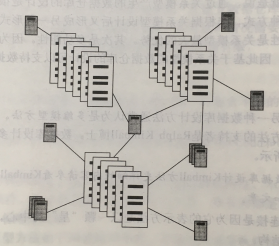
在雪花形结构中,不同的事实表通过共享一个或多个公共维度表连接起来。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号