正则表达式 第一篇:元字符
规则表达式(Regular Expression),常用的名称是正则表达式,用于检索、替换符合特定规则的文本或字符串。正则表达式定义的规则,也被称作模式(Pattern)。正则表达式常用于从文本中查找到符合模式的文本,说某个字符串匹配某个正则表达式,是指这个文本里有一部分,或几个部分分别满足表达式表示的规则(或模式)。
一,什么是正则表达式?
正则表达式也是由字符构成的字符串,确切来说,是由普通字符或特殊字符构成的字符串,这些特殊字符是有特殊含义和作用的,称作元字符。普通字符通常是指要查找的文本,有些元字符是由转义字符\+普通字符构成的。注意,空格和换行都是普通字符。
举个例子,假设你在一篇英文小说里查找 hi,你可以使用正则表达式 hi。这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个连续的字符组成,前一个字符是 h, 后 一个是 i,中间没有任何字符,也不能有换行。
通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配 hi,HI,Hi,hI 这四种情况中的任意一种。不幸的是,很多单词里包含 hi 这两个连续的字符,比如 him,history,high 等等。用 hi 作为正则表达式来查找的话,这些单词里边的 hi 也会被找出来。如果要精确地查找 hi 这个单词的话,应该使用 \bhi\b。
\b 是正则表达式中的一个特殊字符,即元字符,代表着字符的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是 \b 并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是 (一个是,一个不是或不存在)\w。
对\bhi\b的理解是:
- 前一个\b:由于\b的后面是h,那么h的前一个字符只能是空格、标点符号、换行、或没有字符。
- 后一个\b:由于\b的前面是i,那么i的后一个字符只能是空格、标点符号、换行、或没有字符。
假如你要找的是 hi 后面不远处跟着一个 Lucy,你应该用 \bhi\b.*\bLucy\b。
这里,. 是另一个元字符,匹配除了换行符以外的任意字符。* 同样是元字符,不过它代表的不是字符,也不是位置,而是数量 —— 它指定 * 前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,.* 连在一起就意味着任意数量的不包含换行的字符。现在 \bhi\b.*\bLucy\b 的意思就很明显了:先是一个单词 hi, 然后是任意数量的任意字符 (但不能是换行),最后是 Lucy 这个单词。
加入你要找的是包含hi开始的单词,那么可以使用\bhi\w*\b,解释:
- 首先是:单词开始位置 \b和字母hi,表示以hi开始的单词,
- 其次是:任意数量的字母或数字 (\w*),
- 最后是:单词结束处 (\b)。
二,正则表达式的元字符
正则表达式定义的模式,是由"\"+普通字符构成的,把“\”字符称作转义字符,是因为它把普通的字符转义为有特殊含义的元字符。注意,正则表达式是区分大小写的,可以通过表达式选择来忽略大小写限制。
1,常用元字符
用以匹配特定的字符(字母,数字,符号),注意字母是区分大小写的:
- . 匹配任意字符(不包括换行符)
- ^ 匹配开始位置,多行模式下匹配每一行的开始
- $ 匹配结束位置,多行模式下匹配每一行的结束
- \A 匹配字符串的开始位置
- \Z 匹配字符串的结束位置
- \b 匹配位于每个单词的开始或结束位置
- \B 匹配不是单词开头和结束的位置,即每个单词的中间位置
- \d 匹配一个数字, 相当于 [0-9]
- \D 匹配非数字,相当于 [^0-9]
- \s 匹配任意空白字符, 相当于 [ \t\n\r\f\v]
- \S 匹配非空白字符,相当于 [^ \t\n\r\f\v]
- \w 匹配数字、字母、下划线中任意一个字符, 相当于 [a-zA-Z0-9_]
- \W 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_]
- \ 转义字符,把元字符转义为普通字符
2,重复字符或分组
指定前面一个字符或分组重复的次数,重复次数的渴望上有两种匹配模式:贪婪和懒惰。
贪婪匹配模式,在能使整个匹配成功的前提下使用最多的重复:
- * :重复零次或更多次,尽可能多的重复
- + :重复一次或更多次,尽可能多的重复
- ? :重复零次或一次,尽可能多的重复
- {n} :重复n次,尽可能多的重复
- {n,} :重复n次或更多次,尽可能多的重复
- {n,m} :重复n到m次,尽可能多的重复
懒惰匹配模式,在能使整个匹配成功的前提下使用最少的重复:
- *?:重复零次或更多次,尽可能少的重复
- +?:重复一次或更多次,尽可能少的重复
- ?? :重复零次或一次,尽可能少的重复
- {n}? :重复n次,尽可能少的重复
- {n,}? :重复n次或更多次,尽可能少的重复
- {n,m}? :重复n到m次,尽可能少的重复
3,分组,转义,分支
这些字符有特定的含义和用途:
- () : 用小括号表示一个分组
- \ : 转义字符,将特殊字符转移为普通字符,例如:"\(" 表示小括号“(”,小括号不再作为特殊字符
- | : 分支,子表达式之间是“或”的关系
- [...] : 指定限定字符列表,一个字符必须匹配列表中任意一个字符,在中括号中指定匹配的字符列表,例如:[aeiou] 一个字符必须aeiou中的任意一个;
- [-]:连字符,在字符组中,连字符出现在字符中间,表示连续的字符序列,例如,[0-9]表示从0到9的数字;
- [^... ] : 指定排除字符列表,一个字符不能是排除列表中的任意一个字符,中括号中指定排除的字符列表,例如:[^aeiou] 一个字符不能是aeiou中的任意一个;
4,正则表达式中需要转义的字符
* . ? + $ ^ [ ] ( ) { } | \ ,在这些字符前面加上转义字符\,才表示字面意义上的字符。
三,字符类,匹配字符
匹配字符是指在元字符所在的位置处,匹配一个字符:
- . 匹配任意字符,不包括换行符
- \d 匹配一个数字, 相当于 [0-9]
- \D 匹配非数字,相当于 [^0-9]
- \s 匹配任意空白字符, 相当于 [ \t\n\r\f\v]
- \S 匹配非空白字符,相当于 [^ \t\n\r\f\v]
- \w 匹配数字、字母、下划线中任意一个字符, 相当于 [a-zA-Z0-9_]
- \W 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_]
- \char 转义字符,跟在其后的字符将失去作为特殊元字符的含义,例如\.只能匹配.,不能再匹配任意字符
- 普通字符 普通字符直接匹配,注意大小写
注意:正则表达式是区分大小写的,元字符的大写和小写形式表示的含义是不同的;文本字符的大小写也是不同的。
元字符实际上是由字符“\”和普通字符构成的,“\”称作转义字符,也就是说,“\”的作用是把普通字符转换为特殊的字符。由于元字符也是文本中的普通字符,当需要匹配这些特殊字符时,例如,文本中包含"\","."等特殊字符时,必须使用转义字符,把特殊字符转义为普通字符。对于转义字符本身,\\表示一个“\”。
使用\s匹配所有空白字符,包括:空格符,制表符,换行符和回车符。
1,匹配任意空白字符

2,匹配任意非空白字符
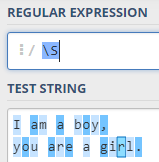
3,匹配数字、字母、下划线中任意一个字符
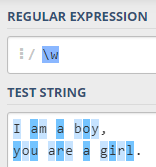
4,匹配非数字、字母、下划线中任意一个字符
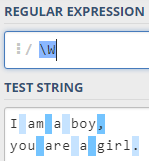
5,匹配一个单词
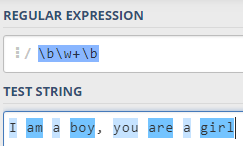
单词的开始和结束,使用\b,单词是由多个字符构成的,至少由一个,因此是\w+,把元字符组合成一个匹配单词的正则表达式是:\b\w+\b
四,定位符,匹配位置
元字符中匹配位置的元字符主要是:
- ^ 匹配开始位置,多行模式下匹配每一行的开始
- $ 匹配结束位置,多行模式下匹配每一行的结束
- \b 匹配位于每个单词的开始或结束的位置
- \B 匹配每个每个单词的不是开始或结束的位置,即单词中间的位置
- \A 匹配字符串的开始位置
- \Z 匹配字符串的结束位置
匹配位置的元字符不占用字符,只是匹配一个位置,例如,\b 表示匹配一个位置,并不占用任何字符,这个位置的一侧是单词字符,一侧为非单词字符。
1,匹配每行的开始位置
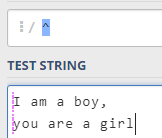
2,匹配结束位置
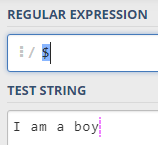
3,匹配每个单词的开始和结束位置
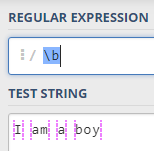
4,匹配每个单词的中间位置

5,匹配字符串开始的位置
在多行模式下,只匹配字符串的起始位置

6,匹配字符串的结束位置
在多行模式下,只匹配字符串的结束位置
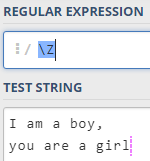
五,字符组
字符组是若干字符的组合,表示只匹配其中一个字符:
- [...] 字符组,一个字符的集合,可匹配其中任意一个字符
- [ - ] 连字符,表示一个范围
- [^...] 排除字符
1,字符组
如果要匹配字符grey和gray,可以使用字符组: gr[ae]y,该正则表达式的意思是:先找到字符gr,然后跟着一个a或e,最后是一个字符y。
注意:在字符组以外,普通字符(如gr[ae]y中的g和r)都有接下来是(and then)的意思,这与字符组内部的情况是完全相反的。字符组的内容是在同一个位置能够匹配的若干字符,所以他的意思是“或”。如“[0123456789]”就是匹配1到9之间的任意一个数字。如果“<H[1234]>”就是用来匹配<H1>,<H2>,<H3>,<H4>。
2,连字符
在字符组内部“-”(连字符)出现在两个字符中间,表示一个范围,例如:
- “<H[1234]>”与“<H[1-4]>”是完全一样的;
- [0-9]和[a-z]是常用的匹配数字和小写字母的简便方式
- 多重范围也是允许的,如“[0123456789abcdeABCDE]“可以写作”[0-9a-eA-E]“
注意:只有在字符组内部,连字符才是元字符,否则他就是只能匹配普通的连字符号。连字符还有一个例外,即使在字符组内部,如果连字符出现在字符组的开头(或排除型字符组的开头,下面会讲,如[^-]),那也不是元字符而只是一个普通字符。同样的道理,问号和点号(后面会讲到这两个元字符)通常被当做元字符处理,但在字符组里则不是如此。只有连字符和^(下面马上讲到,是排除字符)才可能是字符组里的元字符(但是转义符,字符组简记法仍然有效,即[\da-zA-Z]或[^\da-zA-Z]或[\\"]中的\仍然有转义的含义,\d仍然代表数字,\\"仍然代表字符串中的“\"”单独的\不会匹配任何字符,\\会匹配字符'\')。相当于字符组内部有一个自己独立的小世界,有自己的规则。
3,字符组内的排除字符
用“[^…]”取代“[…]”,这个字符组就会匹配任何未列出的字符。例如”[^1-8]”匹配除了1到8以外的任何字符。注意:这句话有两层含义,一个是排除1-8字符,另一个是一定要匹配一个字符。
例子:匹配q后面不是u的字符,正则是”q[^u]”。那么qi会被匹配。那Qantas呢?Iraq呢?答案是这两个都不会被匹配,一个是因为Q是大写,一个是因为q在最后,后面没有除了u以外的任何字符。再次注意,排除型字符组也是要匹配一个字符的。
六,量词
量词用于设置匹配前面一个字符的次数:
- * 匹配前一个元字符0到多次
- + 匹配前一个元字符1到多次
- ? 匹配前一个元字符0到1次
- {m,n} 匹配前一个元字符m到n次
问号,加号和星号统称为量词,表示前面一个字符的重复次数。
1,可选字符 ?
这些元字符,只用于匹配相邻的前一个字符;如果要匹配多个字符,需要使用(),那么用于表示()内的字符重复,例如:
- 对于正则 colou?r,表示color或colour, “u?”表示:u要么出现一次,要么不出现,元字符?只作用于前面紧邻的元素;
- 对于正则 4(th)?,用于表示4或4th,(th)?表示:th要么出现一次,要么不出现,当元字符?前面紧邻的元素是()时,把()作为一个元素来对待。
把()作为一个整体来看待,是一个元素,括号内的元素可以很多。
2,“+(加号)”和”*(星号)”
+和*的作用与?类似,元字符”+”表示“前面紧邻的元素出现一次或多次”;而元字符”*”表示“前面紧邻的元素不出现或出现任意多次”,换种说法就是”*”表示匹配尽可能多的次数,但如果一次都不匹配也没关系。”+”表示匹配尽可能多的次数,但如果一次都不匹配就报告失败。
3,区间量词
区间量词“{min, max}” 表示重复次数的范围,其中min为下限,如果min为空,表示没有下限;max为上线,如果max为空,表示没有上限。例如,对于正则 ”a{3,12}”表示能够容许a出现3到12次,用区间量词来表示其他量词:问号对应“{0,1}”,加号对应”{1,}”, 星号对应”{0,}”
七,选择分支
元字符“|”,表示“或(or)”关系,表示从多个候选的子表达式中,只需要匹配一个。子表达式的范围是由()来限制的,如果没有(),那么以元字符“|”,把表达式分割为两个子表达式,例如:
- “Bob”和“Robert”是两个表达式,通过元字符"|"把这两个表达式组合成一个表达式:“Bob|Robert”,表示只需要匹配其中任意一个子表达式即可。
- 对于上面的“gr[ea]y”例子,还可以写作“grey|gray”或者“gr(a|e)y”,后者用括号来划定多选结构的范围
- 请注意,“gr[a|e]y”不符合我们的需求,在这里,“|”只是一个和“a”与“e”一样的普通字符,在字符组内部|不是元字符。
“gr[ea]y”与“gr(a|e)y”的例子可能会让人觉得多选结构与字符组没太大的区别,但是不要混淆这两个概念。一个字符组只能匹配目标文本中的单个字符,而每个多选结构自身可能是完整的正则表达式,都可以匹配任意长度的文本。
比较”^From|Subject|Date:*”和”^(From|Subject|Date):*”会发现匹配结果大不相同,第一个表达式由3个多选分支构成,能匹配”^From”或”Subject”或”Date:*”,实用性不大。我们希望在每一个多选分支前都有脱字符,之后都有”:*”,所以应该使用括号来限制这些多选分支: ”^(From|Subject|Date):*”,含义是匹配以“From:*”或“Subject:*”或“Date:*”开头的文本行。
八,分组
()是分组元字符,最常见的用途是:
- 限制多选项的范围,如“gr(a|e)y”;
- 将若干字符组合为一个单元,受问号或星号之类量词的作用,如:”(cat|dog)+”
还有一个作用是环视,下文分享。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号