统计4:显著性检验
在统计学中,显著性检验是“假设检验”中最常用的一种,显著性检验是用于检测科学实验中实验组与对照组之间是否有差异以及差异是否显著的办法。
一,假设检验
显著性检验是假设检验的一种,那什么是假设检验?假设检验就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设是否合理。
在验证假设的过程中,总是提出两个相互对立的假设,把要检验的假设称作原假设,记作H0,把与H0对立的假设称作备择假设,记作H1。假设检验需要解决的问题是:指定一个合理的检验法则,利用已知样本的数据作出决策,是接受假设H0,还是拒绝假设H0。
1,假设检验的基本思想
- 如果原假设为真,而检验的结论却劝你拒绝原假设,把这种错误称之为第一类错误(弃真),通常把第一类错误出现的概率记为α;就是说,拒绝真假设的概率是α。
- 如果原假设不真,而检验的结论却劝你接受原假设,把这种错误称之为第二类错误(取伪),通常把第二类错误出现的概率记为β;就是说,接受假假设的概率是β。
二,显著性检验
什么是显著性检验?在给定样本容量的情况下,我们总是控制犯第一类错误的概率α,这种只对犯第一类错误的概率加以控制,而不考虑犯第二类错误的概率β的检验,称作显著性检验。概率α称为显著性水平,显著性水平是数学界约定俗成的,通常取值有α =5%,2.5%,1% ,代表着显著性检验的结论错误率必须低于5%、2.5%和1%。在统计学中,通常把在现实世界中发生几率小于5%的事件称之为“不可能事件”。
一般情况下,根据研究的问题,如果拒绝真假设的损失大,为减少这类错误,α取值小些,把拒绝真假设的概率降到最低;反之,α取值大些。
在显著性检验中,需要用到检验统计量,根据检验法则来确定统计量,常用的统计量是Z统计量和t统计量。当检验统计量取某个区域C中的值时,拒绝原假设H0,则称区域C为拒绝域,拒绝域的边界点称为临界点。
显著性检验通常分为两大类:临界值法和p值法。
三,检验统计量
在统计学中,检验统计量是用于检验假设的参数是否正确的统计量,检验统计量服从一个给定的概率分布。常用的检验统计量有t统计量、Z统计量和卡方统计量等。
根据显著性水平,确认检验统计量的拒绝域的临界点,统计决策所依据的规则如下:
1,Z检验统计量
设统计量 Z,n为样本容量,μ0为样本均值,σ为标准差,那么Z服从标准正态分布,即Z~N(0,1),这就是在假设检验中用到的Z检验统计量。
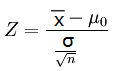
常用于方差σ2已知,而均值μ未知的问题。
2,t检验统计量
设统计量t,那么该统计量服从t分布,即t~t(n-1),这就是假设检验中经常用到得t检验统计量。
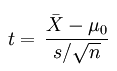
常用于方差σ2未知,而均值μ已知的问题。
3,卡方检验统计量
设卡方统计量χ2,那么该统计量服从卡方分布,即χ2~χ2(n-1),这就是假设检验中经常用到得卡方检验统计量。
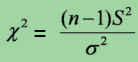
4,F检验统计量


四,临界法
使用临界法处理参数的假设检验问题的步骤如下:
- 根据实际问题的要求,提出原假设H0和备择假设H1;
- 给定显著性水平 α 以及样本容量n;
- 确定检验统计量的形式:构造检验统计量,收集样本数据,计算检验统计量的样本观察值。
- 确定拒绝域的形式:按P{当H0为真拒绝H0}<=α 求出拒绝域;
- 根据样本观测值做出决策,是接受H0还是拒绝H0。
五,显著性检验的实例分析(使用临界点法来检验假设)
某车间用一台包装机装糖,袋装糖的净重是一个随机变量,它服从正态分布。当机器正常时,其均值为0.5(kg),标准差为 0.015(kg)。某日开工后,为检验包装机是否工作正常,随机地抽取它所包装的9袋糖,称得净重为(kg)
0.497 0.506 0.518 0.524 0.498 0.511 0.520 0.515 0.512
问机器是否正常?
1,分析思路
以μ,σ分别表示这一天袋装糖的净重总体X的均值和标准差。由于长期实践表明标准差比较稳定,设σ=0.015,于是X~N(μ, 0.0152),而总体的均值μ未知。
关键点:总体服从正态分布,方差已知,而期望未知。
我们假设总体的均值μ0=0.5,根据样本来检验假设是否成立,即设 原假设 H0:μ=0.5 和 备择假设 H1:μ!=0.5
由于要检验的假设涉及到总体均值,那么使用哪个统计量来检验总体均值呢?答案是使用样本均值![]() ,原因主要是有以下两个:
,原因主要是有以下两个:
- 样本均值
 是总体均值μ的无偏估计,的观察值
是总体均值μ的无偏估计,的观察值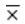 的大小在一定程度上反映了μ的大小,
的大小在一定程度上反映了μ的大小, - 如果原假设H0为真,则观察值与的 μ0的偏差|
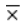 - μ0 | 一般不会太大;如果 |- μ0 | 过分大,就有理由怀疑假设H0的正确性而拒绝H0。
- μ0 | 一般不会太大;如果 |- μ0 | 过分大,就有理由怀疑假设H0的正确性而拒绝H0。
所以,考虑使用样本均值来检验总体均值。
根据实际问题,选择合适的统计量,选择的标准是:无偏性、可计算差值
样本的观察值共有9个,用R很容易计算出样本的均值![]() =0.512,这个样本均值是统计量。
=0.512,这个样本均值是统计量。
> x <- c(0.497, 0.518, 0.524, 0.498, 0.511, 0.520, 0.515, 0.512) > mean(x) [1] 0.511875
由于样本的均值大于0.5,是否可以判断出今天的机器不正常?不能,这是因为计算的均值是通过抽样获取的,既然是样本,就可能存在误差,不能直接使用样本的均值来作判断。
也就是说:由于做出决策的依据是一个样本,当实际上H0为真时,仍可能做出拒绝H0的决策,这种错误是无法消除的。
教材是这样说的:样本是进行统计推断的依据,在引用时,往往不是直接使用样本本身,而是针对不同的问题构造样本的适当函数,利用这些样本的函数进行统计推断。
你能看懂吗,每个字都认识,就是看不懂。
说人话:通过样本计算的统计量是有误差的,对本例而言,样本的均值
敲黑板,划重点:假定有一个总体数据,如果从总体中多次抽样,那么理论上,每次抽样所得到的统计量(如期望)与总体参数(如期望)应该差别不大,大致围绕在总体参数中心,呈正态分布。就是说,样本统计量和总体参数的差值呈正态分布。
由于无法排除犯这类错误的可能性,因此,需要把犯这类错误的概率控制在一定限度之内,即给出一个较小的数 α (通常的取值有5%,2.5%,和1%),使犯这类错误的概率不超过α,即使得: P{ 当H0为真时拒绝H0 } <= α,设 α=5%。
说人话:根据样本计算出来的统计量服从一定的分布,即抽样分布,根据抽样分布来计算概率。如果统计量的概率小于α,那么接受H0,认为原假设H0是正确的。
当计算样本统计的概率时,需要用到检验统计量,检验统计量最好是差值,即样本统计量和总体的相应统计量的差值,根据差值的分布来检验假设。
本例使用Z统计量,Z统计量是样本统计量![]() 的函数,服从N(0, 1),S是样本标准差,n是样本容量,μ0是总体均值
的函数,服从N(0, 1),S是样本标准差,n是样本容量,μ0是总体均值

接下来就是根据显著性水平α来确定分位点,正态分布是左右对称的,所以分位点应该取概率的 α/2 处。
对于正态分布,根据中心极限定理,假设总体均值为0,如果多次抽样,每次抽样得到的均值都应该在0附近,如果偏离0太远,那很有可能并非来自这个总体。
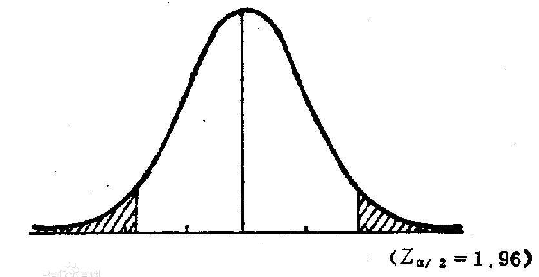
也就是说,Z统计量的概率低于α=5%,接受原假设H0,从图中可以得出最小的检验统计量的值 Zα/2=1.96,由于可得检验统计量拒绝域是大于1.96或小于 -1.96
根据样本的均值![]() 计算检验统计量的值是:2.4=(0.512-0.5)/(0.015/3),样本的检验统计量位于拒绝域中,因此,拒绝原假设,认为今天的机器有问题。
计算检验统计量的值是:2.4=(0.512-0.5)/(0.015/3),样本的检验统计量位于拒绝域中,因此,拒绝原假设,认为今天的机器有问题。
2,具体的步骤
step1,根据实际问题提出原假设H0和备择假设H1
设常量:μ0=0.5,为此,提出两个对立的假设:
原假设 H0:μ=μ0
备择假设 H1:μ!=μ0
step2,确定检验统计量
因为要检验的假设涉及到总体均值 μ,所以,考虑借助样本均值 ![]() 这一统计量来判断总体的均值。
这一统计量来判断总体的均值。
由于 ![]() 是μ的无偏估计,
是μ的无偏估计,![]() 的观察值的大小在一定程度上反映了μ的大小,因此,如果原假设H0为真,则观察值与的 μ0的偏差|- μ0 | 一般不会太大;如果 |- μ0 | 过分大,就有理由怀疑假设H0的正确性而拒绝H0。
的观察值的大小在一定程度上反映了μ的大小,因此,如果原假设H0为真,则观察值与的 μ0的偏差|- μ0 | 一般不会太大;如果 |- μ0 | 过分大,就有理由怀疑假设H0的正确性而拒绝H0。
考虑当H0为真时,Z统计量服从N(0,1),即 Z ~N(0,1)
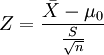
S是样本的标准差,本例中S=σ=0.015。把Z作为检验统计量,衡量|- μ0 | 的大小归结为衡量统计量Z的大小。
step2,确定显著性水平和样本容量
设显著性水平α=0.05,样本容量n=9
step4:确定拒绝域的形式
适当选定一正数k,使得当观察值
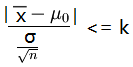
就接受原假设H0,否则就拒绝原假设H0。
然而,由于做出决策的依据是一个样本,当实际上H0为真时,仍可能做出拒绝H0得决策(这种可能性是无法消除的),这是第一类错误,犯这类错误得概率记作:P{ 当H0为真时拒绝H0 }
由于无法排除犯这类错误的可能性,因此,需要把犯这类错误的概率控制在一定限度之内,即给出一个较小的数 α (通常的取值有5%,2.5%,和1%),使犯这类错误的概率不超过α,即使得:
P{ 当H0为真时拒绝H0 } <= α
为了确定常数k,考虑使用统计量Z,由于只允许犯这类错误的概率最大为 α ,得到如下等式:
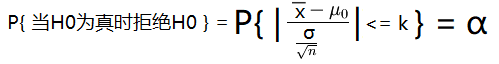
由于当H0为真时,统计量Z~N(0,1),由标准正态分布分位点的定义得 k=zα/2
如果Z的观察值满足 |z|>=k=zα/2,则拒绝H0;如果|z|<k=zα/2,则接受H0。
step5,根据样本观测值做出决策
在本例中,α=0.05,则有k=zα/2 =k=z0.025=1.96,又已知n=9,σ=0.015,再由样本值计算得=0.511,
那么统计量Z的观测值是:
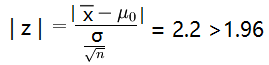
于是拒绝H0,认为这天包装机工作不正常。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号