Azure 存储简介
Azure Storage Account(存储账户)包含所有Azure Storage的数据对象,包括Blob、Data Lake Gen2,File、Queue、Disk和Table等服务,该Storage Account为用户的Azure Storage数据提供了唯一的命名空间,可以通过HTTP或HTTPS来访问它。Azure Storage Account中的数据是持久的、高度可用的、安全的和可扩展的。
一,存储账户的类型
Azure Storage提供了4种类型的存储账户,每种类型都支持不同的功能,并具有自己的定价模型。
- General-purpose v2 accounts:基础的存储账户,用于Blob、Data Lake Gen2,File、Queue和Table等服务,最常用和最基础的存储账户。
- BlockBlobStorage accounts:具有高级性能特征的bock blob和 append blob。推荐用于高事务处理率、数据较小且低存储延迟的场景种。
- FileStorage accounts:纯文件的存储账户
- BlobStorage accounts:旧版的Blob-Only的存储账户,推荐使用General-purpose v2 accounts。
存储账户的作用是为用户在Azure中提供唯一的命名空间,存储在Azure Storage中的任何对象都有唯一的地址,且都在唯一账户名下。账户名和Azure Storage Blog endpoint的组合构成了存储账户中对象的基地址。
举个例子,如果存储账户的名称是:mystorageaccount,默认的Blog storage的endpoint是:
http://mystorageaccount.blob.core.windows.net
1,存储账户的端点
存储账户为Azure中的数据提供了唯一的命名空间,使得存储在Azure Storage中的每个对象都有一个唯一的地址,该地址包含在存储账户名,也就是说,存储账户和Azure 存储服务的端点的组合构成在存储账户中对象的基地址:
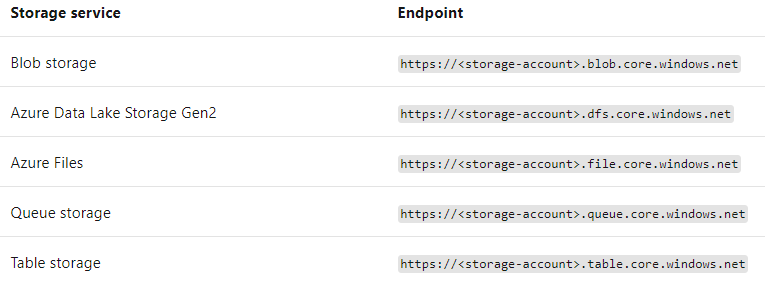
2, Access tier(访问层)
Azure Storage根据使用模式的不同,提供了用于访问block blob数据的不同选项。Azure Storage中的访问层(Access Tier)都针对特定的数据使用模式进行了优化,通过选择合适的访问层,可以以最具成本效益的方式存储Block Blob数据。
可用的访问层:
- Hot:用于频繁访问存储账户中的对象,在hot tier中,访问数据最具有成本效益,而存储数据的成本则较高。默认情况下,在hot tier中创建新的存储账户。
- Cool:用于存储不经常访问,且存储时间超过30天的大量数据。在Cool tier中存储数据更具成本效益,而访问数据的成本则较高。
- Archive:仅用于单个Block Blob,归档层可以忍受数小时的检索延迟,并且数据在归档层中至少保留180天。归档层最适合存储长时间访问的数据,但是访问数据是最慢的。
目前,只有 General-purpose V2 和 BlobStorage支持访问层。
二,Blob存储
Blob(Binary Large Object,二进制类型的大对象)存储是Microsoft的云对象存储解决方案,Blob存储经过优化,可存储大量非结构化数据。 非结构化数据是不遵循特定数据模型或定义的数据,例如文本或二进制数据。
Blob存储用于:
- 把图像或文档直接提供给浏览器
- 存储文件以进行分布式访问
- 流式传输视频和音频
- 写入日志文件
- 存储数据以进行备份和欢迎
- 存储数据以on-premises方式进行分析,或Azure 托管服务。
1,Blob存储的资源
Blob存储提供三种资源:
- 存储账户
- 存储账户中的Container(容器)
- 容器中的Blob

2,容器(Container)
一个容器组织了一组Blob,类似于文件系统中的目录(Directory),一个Storage Account可以包含无限数量的容器,一个容器可以存储无线数量的Blob。
3,Blob
Azure Storage支持三种的Blob:
- Block blobs :用于存储文本和二进制数据,块Blob由可以单独管理的数据块构成。
- Append Blob:对追加操作进行优化的的Blob,特别适合用于记录日志。
- Page blobs:存储随机访问的文件,Page Blob存储虚拟硬盘(Virtual Hard Drive,VHD)文件,并用作Azure VM的硬盘。
三,Azure Data Lake Storage Gen2存储
Azure Data Lake Storage Gen2(简称二代Data Lake)是基于Azure Blob Storage构建的,具有Blob存储的优点,例如,低成本的分层存储(tiered storage),高可用性,强一致性和灾难恢复能力等。它也提供了有层次结构的文件系统(hierarchical file system)。二代Data Lake的核心功能是数据存储和数据查询两个部分,它已经集成于存储账号(Storage Account)的功能体系之中。
Azure Data Lake Storage Gen2:有层次结构的文件系统
“层次结构”和“文件系统”是反复被强调的Data Lake Storage Gen2的最大特点,也是它有别于传统Blob对象存储的最大不同。传统对象存储虽然从路径上看起来也具有“目录”的虚拟概念,但其实目录通常并不实际存在,可认为仅是Blob对象路径字符串中的一部分,因为对象存储本质上是key-value形式的存储。而ADLS这样的“文件系统”级别的存储能力上,目录则是一等公民,可以设置访问权限等元数据(并且能够被子节点继承),也可以使目录重命名等操作变得十分便捷迅速。这样的特性无疑使ADLS更适合作为企业数据湖这样应用的存储介质。
Data Lake Storage Gen2可以向Blob存储中添加讽刺的名称空间(hierarchical namespace),分层名称空间把对象/文件组织到目录的分层结构中,以实现高效的数据访问,并使得文件的管理更加容易,通过目录和子目录来组织和操作文件。
在通常情况下,对象存储的命名约定是使用名称中的斜杠来模仿分层目录结构,比如C:/dir/file.txt,这种结构在Data Lake Storage Gen2中变为现实。重命名或删除目录之类的操作将成为目录上的单个原子元数据操作。无需枚举和处理共享目录名称前缀的所有对象。
在Data Lake Storage Gen2服务中,创建一个容器victest,在容器中创建Folder,或者在容器中存储file:

四,一个服务,多个概念
由于Data Lake Storage Gen2建立在Azure Blob存储之上,因此多个概念可以描述相同的共享事物。
以下是等效实体,却使用不同的概念来描述, 除非另有说明,否则这些实体直接是同义词:

参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号