pandas 索引和选择数据
数据框和序列结构中都有轴标签,轴标签的信息存储在Index对象中,轴标签的最重要的作用是:
- 唯一标识数据,用于定位数据
- 用于数据对齐
- 获取和设置数据集的子集。
本文重点关注如何对序列(Series)和数据框(DataFrame)进行切片(slice),切块(dice)、如何获取和设置子集。
下表列出数据框最基本的操作及其语法:

一,最基本的选择操作
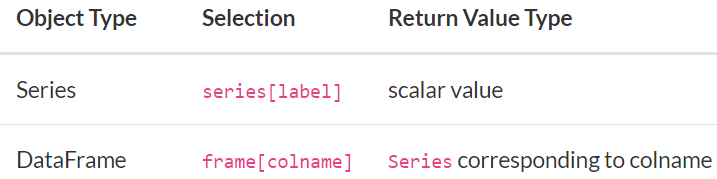
最基本的选择都是使用中括号[]来实现,但是只能实现单个维度的选择。序列(Series)最基本的选择是使用行标签来选择一个标量值,数据框(DataFrame)最基本的选择是使用列名获得一个序列。对于序列来说,如果行索引是整数,那么轴标签就是整数;对于数据框而言,列的标签通常都是文本类型。
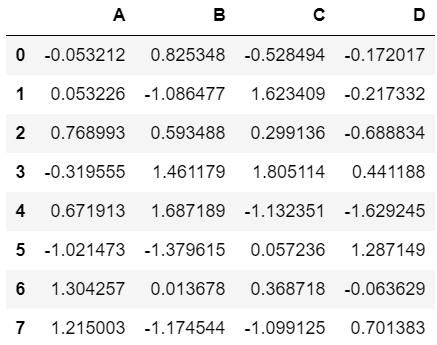
创建一个数据框,用于数据演示:
df = pd.DataFrame(np.random.randn(8, 4), columns=['A', 'B', 'C', 'D'])
从数据框中获取A列的数据:
>>> df["A"] 0 -0.053212 1 0.053226 2 0.768993 3 -0.319555 4 0.671913 5 -1.021473 6 1.304257 7 1.215003 Name: A, dtype: float64
从数据框中选择多个列的数据:
df[["A","B"]]
数据框的一列是一个序列,从序列中获得一个标量值:
>>> s=df["A"] >>> s[0] -0.05321219353405595
从序列中选择多行的数据:
s[[0,1]]
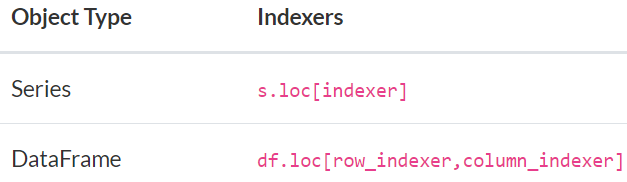
二,使用loc 和 iloc来选择数据
索引的选择主要是基于标签的选择和基于位置的选择,对于索引来说,位置序号默认从0开始,到length(index)-1 结束。
对于数据框而言,如果没有填写row_indexer 或 column_indexer,那么表示所有的row或column。在row_indexer和column_indexer中,可以使用连续的标签,比方说,0:4,表示从0到4的一个range,即0、1、2、3,注意不包含4。
1,基于标签的选择
.loc 属性用于基于轴标签选择特定的轴,df是数据框结构:
- 单个标签:df.loc["row"], df.loc["row","col"]
- 多个离散的标签:df.loc[["row1","row2","row3"]],df.loc[["row1","row2","row3"],["col1","col2"]]
- 连续的标签:df.loc["row0":"row3"],df.loc["row0":"row3","col0":"col3"]
- 布尔掩码数组,对于数据框,所有的行构成一个序列,每行都对应一个掩码,如果掩码为True,表示选择该行;如果为False,表示忽略该行。同理,数据框中的所有列也构成一个序列,每列都对应一个掩码,如果掩码为True,表示选择该列;如果为False,表示忽略该列。
使用连续的标签,获得数据框的一个切片:
df.loc[0:1]
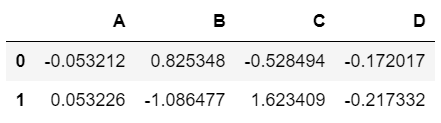
使用多个离散的标签获得特定的行和列:
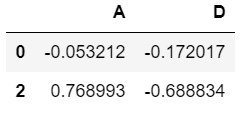
df.loc[[0,2],["A","D"]]
2,基于位置的选择
.iloc属性用于基于位置的选择,位置序号从0开始,到轴长(axis length-1)截止:
- 单个位置
- 多个离散的位置
- 连续的位置
- 布尔掩码数组
跟基于标签的选项相比,只不过把标签换成了位置。
三,布尔掩码索引
布尔操作符是: &, | , ~,分别表示 与、或、非。通过操作符,可以把多个布尔值组合成一个逻辑表达式。
当使用布尔掩码向量来作为索引时,布尔向量的长度必须和索引的长度相同。这就意味着,如果一个序列有5行,那么布尔向量必须有5行;如果一个数据框有6列,那么用于选择列的布尔向量必须有5个元素。
例如,获得列A的数据,获得一个序列,对序列进行逻辑运算,得到一个布尔向量:
df["A"]>0

用布尔向量来过滤数据行,得到基于数据掩码的选择:
df.loc[df["A"]>0,["A","B"]]

使用布尔掩码向量作为行索引,由于行索引有8个,即Range(8),因此,布尔掩码向量必须有8行。df["A"]>0 返回一个布尔向量,是由8个布尔值构成的向量。当元素值是Ture时,表示选择该行;当元素值是False时,表示忽略该行。
也可以对布尔向量进行逻辑运算,比如:
s[(s < -1) | (s > 0.5)]
四,通过可调用的函数来选择数据
数据框和序列的 .loc, .iloc 和 [] 都可以接收一个可调用的函数( callable function)作为索引, 可调用的函数必须只有一个参数,并且参数是序列或数据框,返回的是布尔掩码向量。
举个例子,使用lambda定义函数,下面两个脚本是等价的。
df.loc[lambda df: df['A'] > 0, ["A","B"]] df.loc[df["A"]>0,["A","B"]]
五,isin函数
判断单个值或多个值是否存在于序列或数据框中,返回的是布尔值掩码,并可以通过掩码来会返回值:
In [157]: s.isin([v1,v2,...])
In [158]: s[s.isin([v1,v2,...])]
六,where函数和mask函数
where()函数接收的参数是布尔掩码,返回的shape跟原始的序列和数据框相同,只不过布尔值为False的元素被设置为NaN,布尔值为True的元素显示为原始值,即,把布尔掩码为False的元素掩蔽。
例如,序列s是df["A"],s>0是一个布尔掩码,下面的代码返回的是一个序列,只不过掩码为False的元素全部为NaN,where()函数的作用是布尔掩码为True的返回,为False的设置为NaN。
s.where(s>0)

mask()函数接收的参数也是布尔掩码,返回的shape跟原始序列或数据框也相同,只不过布尔值为False的元素显示为原始值,而布尔值为True的元素显示为NaN,即,把不二掩码为True的元素掩蔽。
七,query()函数
query()函数可以使用表达式来选择数据框,以简化数据框的查询,比如,以下两段代码返回的结果是相同的,而使用query()函数的代码更简洁:
# 布尔组合 df[(df['a'] < df['b']) & (df['b'] < df['c'])] df.query('(a < b) & (b < c)') # isin df[df['a'].isin(df['b'])] df.query('a in b') # not in df.query('a not in b') df[~df['a'].isin(df['b'])] #布尔组合 df.query('a in b and c < d') df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
在query()函数中,可以使用关键字 index来代替数据框的index属性:
df.query('index < b < c')
在query()函数中,使用 == [] 等价于 in;使用 != [] 等价于 not in
# in df.query('b == ["a", "b", "c"]') df[df['b'].isin(["a", "b", "c"])] # not in df.query('c != [1, 2]') df.query('[1, 2] not in c')
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号