pandas 透视和逆透视——melt、pivot、pivot_table
在实际的数据处理中,通常需要按照特定的需求对数据的格式进行处理,透视操作和逆透视操作有时是不可逆的。
一,透视和逆透视操作示例
数据透视的过程如下图所示,以Year为索引,按照Course列来透视Earning,把数据从长格式转换为宽格式:

数据逆透视的过程如下图所示,把数据从宽格式转换为长格式:
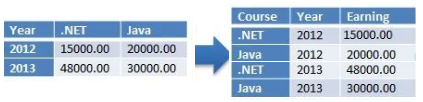
二,长宽格式的转换
宽格式是指:一列或多列作为标识变量(id_vars),其他变量作为度量变量(value_vars),直观上看,这种格式的数据比较宽,举个列子,列名是:id1、id2、var1、var2、var3,一行可以表示多个度量变量的值。
而长格式是指在一行中,除了标识变量(id_vars),其他列是variable和name,从宽格式转换为长格式,会使得数据行数增加,直观上看,这种格式的数据比较长,举个例子,列名是:id1、id2、variable、value,一行只表示一个度量变量的值。
在宽格式转换为长格式的过程中,宽格式中的多个度量变量进行了分裂,使得长格式中的每一行,实际上,只表示一个度量变量的值。
有如下宽数据:
>>> df = pd.DataFrame({'idA': {0: 'a', 1: 'b', 2: 'c'},
... 'varB': {0: 1, 1: 3, 2: 5},
... 'varC': {0: 2, 1: 4, 2: 6}})
>>> df
idA varB varC
0 a 1 2
1 b 3 4
2 c 5 6
三,数据的逆透视
融合数据,也叫做逆透视表(unpivot),把数据从宽格式转换为长格式
DataFrame.melt(self, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
参数注释:
- id_vars:作为标识变量的列
- value_vars:作为值的列
- var_name:默认值是variable,对长格式中度量变量的列名所在的列进行命名
- value_name:默认值是value,对长格式中度量变量的列值所在的列进行命名
- col_level:如果列是MultiIndex,使用这个level的索引进行melt
举个例子,把示例中的宽数据转换为长数据,id列是idA,度量变量是varB,得到如下长数据:
>>> df.melt(id_vars='idA',value_vars='varB') idA variable value 0 a varB 1 1 b varB 3 2 c varB 5
id列是idA,度量变量是varB和varC,得到如下长数据:
>>> df.melt(id_vars='idA',value_vars=['varB','varC']) idA variable value 0 a varB 1 1 b varB 3 2 c varB 5 3 a varC 2 4 b varC 4 5 c varC 6
四,数据透视(pivot)
把数据从长格式转换为宽格式,返回按照特定的index或column重塑的DataFrame,不带聚合函数,可以处理文本数据:
DataFrame.pivot(self, index=None, columns=None, values=None)
参数注释:
- index:用于创建新DataFrame的索引,相当于分组列,相同索引的行称为一个小分组。
- columns:根据columns指定的列值来创建新DataFame的列名,使用该参数指定的列来创建结果的列名。
- values:和columns对应,表示相应列的列值,用于填充结果列的列值
重塑数据的流程:
- 根据index的唯一值进行分组,
- 把columns指定的列的唯一值作为结果的列名,即,列的值作为结果的列名
- 把values对应的列值作为新列名的值,即,把列的值作为结果中对应列的值
举个例子,有如下长格式的数据:
>>> df=df.melt(id_vars='idA',value_vars=['varB','varC']) >>> df idA variable value 0 a varB 1 1 b varB 3 2 c varB 5 3 a varC 2 4 b varC 4 5 c varC 6
使用pivot把长格式转换为宽格式,按照idA列进行分组,把variable的列值作为结果的列名,把values的列值作为结果列的值:
>>> df.pivot(values='value',columns='variable',index='idA') variable varB varC idA a 1 2 b 3 4 c 5 6
重塑的数据包含行索引idA,列标签varB和varC,其中variable是列标签的name。
使用reset_index()函数把行索引转换为列,其中variable是列索引的名称:
>>> df.pivot(values='value',columns='variable',index='idA').reset_index() variable idA varB varC 0 a 1 2 1 b 3 4 2 c 5 6
五,透视表(pivot_table)
透视表是指按照特定的index和columns进行聚合操作之后的表,该函数和pivot函数的行为相似,只不过会对值进行聚合操作,只能处理数值属性:
DataFrame.pivot_table(self, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
参数注释:
- values:聚合的列
- index:分组器,作为结果的索引
- columns:分组器,作为结果的列
- aggfunc:聚合的函数
- fill_value:用于填充缺失值的值
- margins:bool,默认值是True,把所有行或列的值加和,计算subtotal(小组和)或grand total(总合)
- margins_name:str,默认值是All,当margins为Ture时,为每个汇总设置名称。
- observed:boolean, default False,仅适用于分组器是分类索引的。
例如,对长数据进行重塑,获得透视表:
>>> df.pivot_table(values='value',index='idA',columns='variable',aggfunc='mean') variable varB varC idA a 1 2 b 3 4 c 5 6
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号