spaCy 第二篇:语言模型
spaCy处理文本的过程是模块化的,当调用nlp处理文本时,spaCy首先将文本标记化以生成Doc对象,然后,依次在几个不同的组件中处理Doc,这也称为处理管道。语言模型默认的处理管道依次是:tagger、parser、ner等,每个管道组件返回已处理的Doc,然后将其传递给下一个组件。

一,加载语言模型
spaCy使用的语言模型是预先训练的统计模型,能够预测语言特征,对于英语,共有en_core_web_sm、en_core_web_md和en_core_web_lg三种语言模型,还有一种语言模型:en,需要以管理员权限运行以下命令来安装en模型:
python -m spacy download en
使用spacy.load()函数来加载语言模型
spacy.load(name,disable)
其中,name参数是语言模型的名词,disable参数是禁用的处理管道列表,例如,创建en_core_web_sm语言模型,并禁用ner:
nlp = spacy.load("en_core_web_sm", disable=['ner'])
语言模型中不仅预先定义了Language管道,还定义了处理文本数据的处理管道(pipeline),其中分词器是一个特殊的管道,它是由Language管道确定的,不属于pipeline。
{ "lang": "en", "name": "core_web_sm", "description": "Example model for spaCy", "pipeline": ["tagger", "parser", "ner"] }
在加载语言模型nlp之后,可以查看该语言模型预先定义的处理管道,也就是说,处理管道依赖于统计模型。
1,查看nlp对象的管道
>>> nlp.pipe_names ['tagger', 'parser', 'ner']
2,移除nlp的管道
nlp.remove_pipe(name)
3,向nlp的处理管道中增加管道
nlp.add_pipe(component, name=None, before=None, after=None, first=None, last=None)
二,语言管道和分词器管道
Language管道是一个特殊的管道,当调用spacy.load()加载语言模型时,spaCy自动创建Lanuage管道,用于存储共享的词汇表、分词规则(Tokenization Rule)和文本注释。
分词器管道是跟Language管道息息相关的一个管道,当创建Language管道之后,spaCy根据Language管道提供的词汇表来创建分词器。分词器用于把文本分为单词,标点符号,空格等标记,除了使用默认的分词器之外,spaCy允许用户根据需要对分词器进行调整:
from spacy.tokenizer import Tokenizer tokenizer = Tokenizer(vocab=nlp.vocab,rules,prefix_search, suffix_search, infix_search, token_match)
参数注释:
- vocab:词汇表
- rules:dict类型,分词器的特殊规则,把匹配到特殊规则的单词作为一个token,主要是用于设置token的注释(annotation);
- prefix_search、suffix_search:类型是re.compile(string).search
- infix_finditer:类型是re.compile(string).finditer,把匹配到这前缀、后缀或中缀的字符串作为一个token;
- token_match:返回boolean值的函数类型,把匹配到的字符串识别为一个token;
在文本处理的过程中,spaCy首先对文本分词,原始文本在空格处分割,类似于text.split(' '),然后分词器(Tokenizer)从左向右依次处理token,在处理token时,spaCy做了两个check:
- 是否匹配特殊规则(execption rule)
- 是否前缀、中缀或后缀可以分割
一个可选的布尔函数token_match,它匹配的字符串不会被拆分,覆盖以前的规则,对URL或数字之类的东西很有用。
三,扩展语言
每一种语言都是不同的,通常充满异常和特殊情况,尤其是最常见的单词。 其中一些例外是跨语言共享的,而其他例外则完全具体,通常非常具体,需要进行硬编码。 spaCy.lang模块包含所有特定于语言的数据,以简单的Python文件组织,这使得数据易于更新和扩展。
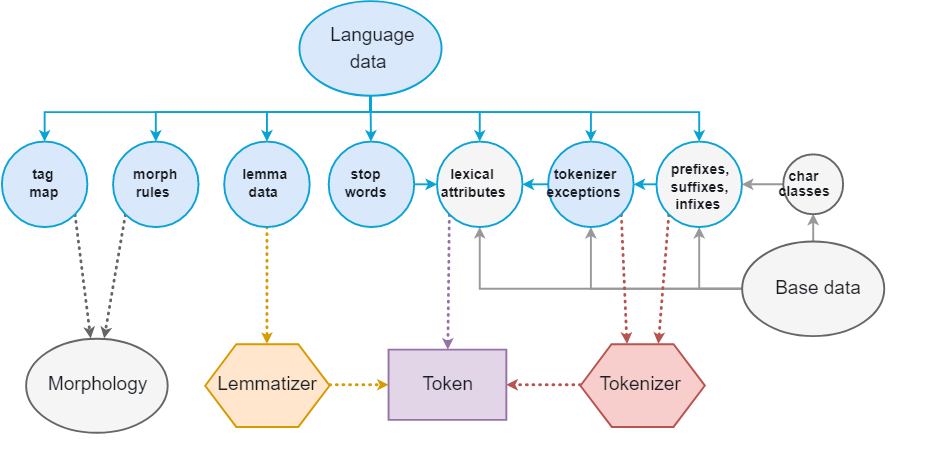
每一个单独的组件可以在语言模块种导入遍历,并添加到语言的Defaults对象种,某些组件(如标点符号规则)通常不需要自定义,可以从全局规则中导入。 其他组件,比如tokenizer和norm例外,则非常具体,会对spaCy在特定语言上的表现和训练语言模型产生重大影响。
例如,导入English模块,查看该模块的帮助:
from spacy.lang.en import English help(English)
通过这些模块来扩展语言,处理特殊的语法,通常在分词器(Tokenizer)中添加特殊规则和Token_Match函数来实现。
1,向分词器中添加特殊的规则
import spacy from spacy.symbols import ORTH, LEMMA, POS, TAG nlp = spacy.load("en_core_web_sm") # add special case rule special_case = [{ORTH: u"gim", LEMMA: u"give", POS: u"VERB"}, {ORTH: u"me"}] nlp.tokenizer.add_special_case(u"gimme", special_case)
2,设置特殊的规则来匹配token
创建一个自定义的分词器,使分词把https作为一个token:
import re import spacy from spacy.lang.en import English def my_en_tokenizer(nlp): prefix_re = spacy.util.compile_prefix_regex(English.Defaults.prefixes) suffix_re = spacy.util.compile_suffix_regex(English.Defaults.suffixes) infix_re = spacy.util.compile_infix_regex(English.Defaults.infixes) pattern_re = re.compile(r'^https?://') return spacy.tokenizer.Tokenizer(nlp.vocab, English.Defaults.tokenizer_exceptions, prefix_re.search, suffix_re.search, infix_re.finditer, token_match=pattern_re.match)
在处理文本时调用该分词器,把匹配到正则的文本作为一个token来处理:
nlp = spacy.load("en_core_web_sm") nlp.tokenizer = my_en_tokenizer(nlp) doc = nlp(u"Spacy is breaking when combining custom tokenizer's token_match, access https://github.com/explosion/spaCy to get details") print([t.text for t in doc])
3,自定义分词器
预先定义的分词器是按照空格来分词的,用于可以自定义分词器
### customer tokenizer class myTokenizer(object): def __init__(self, vocab): self.vocab = vocab def __call__(self, text): words=[] re_search=my_token_match(text) if re_search: for start,end in re_search.regs: if start >=0 and end>=0: words.append(text[start:end]) text=my_token_replace(text) split_words=my_token_split(text) print(split_words) words.extend([w for w in split_words if w!='']) # All tokens 'own' a subsequent space character in this tokenizer spaces = [True] * len(words) return Doc(self.vocab, words=words, spaces=spaces) ### parse the synonyms RE_SYNONYMS=parse_synonyms() def my_token_match(text): global RE_SYNONYMS return re.compile(RE_SYNONYMS).search(text) def my_token_replace(text): global RE_SYNONYMS return re.compile(RE_SYNONYMS).sub('',text) def my_token_split(text): #return re.compile('\s+|\W+|_+').split(text) return re.compile('\s+|\\+|_+').split(text)
引用自定义的分词器
nlp=spacy.load("en_core_web_sm") nlp.tokenizer = myTokenizer(nlp.vocab)
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号