pandas 数据结构和数据类型
pandas是基于NumPy构建的模块,是数据分析必不可少的包之一,通常情况下,引入pandas的约定,只要在代码中看到pd,就要联想到pandas:
import pandas as pd
pandas包含两种最主要数据结构:序列(Series)和数据框(DataFrame)。对于这两个数据结构,有两个最基本的概念:轴(Axis)和标签(Label),对于二维数据结构,轴是指行和列,轴标签是指行的索引和列的名称,存储轴标签的数据结构是Index结构。
对于这两个数据结构,还有一个特性:数据对齐是天生存在的,轴和标签之间的连接是内在的,不会被破坏,除非有意为之。这意味着,每行都有一个索引,通过索引可以定位到该行;每列都有一个列名,通过列名可以定位到该列;通过行索引和列名称,可以唯一定位到一个唯一的数据点(cell)的数据值。
一,数据框的数据结构
数据框(DataFrame)存储的是二维数据,数据框的结构由row和column构成,每一行都有一个row label,每一列都有一个column label,把row和column称作axis,把row label和column label称作axis label。通常情况下,column label 是文本类型,是列名称(column name),而row label是数值类型,也称作行索引(row index)。
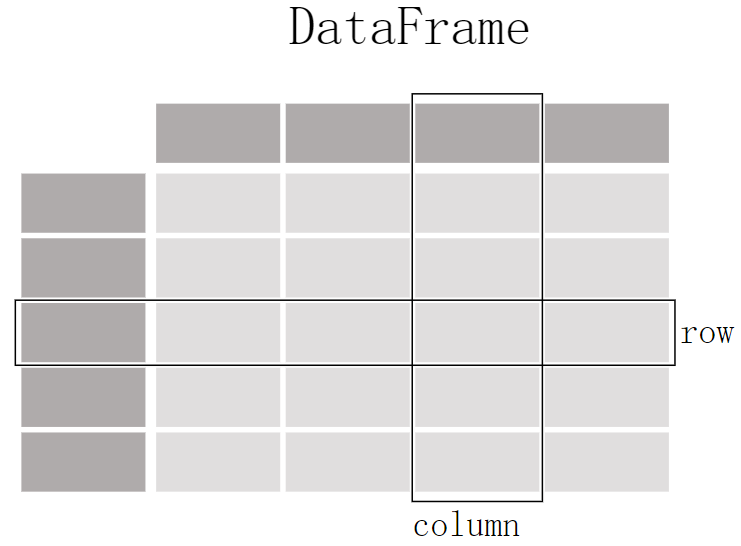
从DataFrame的结构图中可以看出,DataFrame结构由二部分构成:深色的区域叫做Axis Label(轴标签),浅灰色的区域是data,对于Axis,左侧的轴称作index、上方的轴称作columns,而轴的结构实际上是一个Index类型。
import pandas as pd In [2]: df = pd.DataFrame({ ...: "Name": ["Braund", ...: "Allen", ...: "Bonnell"], ...: "Age": [22, 35, 58], ...: "Sex": ["male", "male", "female"]} ...: ) ...: In [3]: df Out[3]: Name Age Sex 0 Braund 22 male 1 Allen 35 male 2 Bonnell 58 female
该数据框(DataFrame) 有三行三列,行索引分别是0、1、2,列名称分别是Name、Age和Sex。每一列的数据类型是相同的,对于Name和Sex列,它们的数据类型是文本,而Age列的数据类型是整数型。
二,序列的数据结构
序列(Series)是一维结构,DataFrame的每一列都是一个序列(Series),序列结构只有行索引(row index),没有列名称(column name),但是序列有Name、dtype和index属性,其中Name属性是指序列的名称,dtype属性是指序列值的类型,index属性是序列的索引。序列存储的数据的数据类型是相同的。

从序列的结构图中,可以看出,实际上,序列包含数据(data)和索引(index)。左侧是索引,右侧是数据。
从DataFrame中选择Age列,这是一个Series结构,
In [4]: df["Age"] Out[4]: 0 22 1 35 2 58 Name: Age, dtype: int64
序列是由一组数据(各种NumPy数据类型),以及一组与之相关的行标签(索引)组成,序列要求数据类型是相同的。
当然也可以创建一个新的序列,通过以下函数来创建一个新的序列:序列可以看作是一维数组:由于没有显式为Series指定索引,pandas会自动创建一个从0到length(Series)-1的整数型索引。
>>> cat=pd.Series(data=['a','b'],name='Category') >>> cat 0 a 1 b Name: Category, dtype: object
可以使用函数pandas.Series.rename() 来修改序列的name。
三,序列和数据框之间的关系
序列和数据框之间的关系是:数据框的每一列都是一个序列,数据框的每一行都是一个序列。
数据框(DataFrame)是二维的数据结构,由一组有序的列构成,每列的数据类型是相同的,列与列之间的数据类型可以不相同。数据框的结构是行和列,每一列都有列名(或叫做列索引、列标签),每一行都有行索引,行索引通常是正整数,也可以是文本类型。
序列和数据框之间是密切关联的,当访问DataFrame的一行时,pandas自动把该行转换为序列;当访问DataFrame的一列时,Pandas也自动把该列转换为序列。
四,轴标签,也称作索引
存储轴标签的数据结构是Index,对于数据框,行标签(即行索引)和列名称(即列索引)是由Index对象存储的;对于序列,行索引是由Index对象存储的。索引对象是不可修改的,类似一个固定大小的数组。
对于索引,还可以通过序号来访问,序号是自动生成的,从0开始。
轴标签的最重要的作用是:
- 唯一标识数据,用于定位数据
- 用于数据对齐
- 获取和设置数据集的子集。
数据框和序列对象都有一个属性index,用于获取行标签,对于数据框,还有一个columns属性,用于获取列标签:
>>> df.index RangeIndex(start=0, stop=3, step=1) >>>df.columns Index(['Name', 'Age', 'Sex'], dtype='object')
Series和DataFrame可以看作一个字典结构:索引是Key,数据值是Value,通过索引结构来唯一标识数据值。
五,数据类型
在大多数情况下,pandas使用NumPy的数组和dtypes作为序列和数据框中列的数据类型,NumPy支持的数据类型是float、int、bool、timedelta64[ns]。pandas扩展了NumPy的类型系统,用dtype属性来显示元素的数据类型,pandas主要有以下几种dtype:
- 字符串类型:object
- 整数类型:Int64,Int32,Int16, Int8
- 无符号整数:UInt64,UInt32,UInt16, UInt8
- 浮点数类型:float64,float32
- 日期和时间类型:datetime64[ns]、datetime64[ns, tz]、timedelta[ns]
- 布尔类型:bool
1,查看变量的类型
查看变量的数据类型,使用type(var)函数
type(obj)
2,特殊的objct类型
通常情况下,使用object表示字符类型;
>>> pd.Series(['a', 'b', 'c'], dtype="object") 0 a 1 b 2 c dtype: object
对于object类型,如果一个pandas对象在单列中包括多个dtype,那么使用object来容纳所有的dtype。
# string data forces an ``object`` dtype In [333]: pd.Series([1, 2, 3, 6., 'foo']) Out[333]: 0 1 1 2 2 3 3 6 4 foo dtype: object
3,数值类型
pandas中的整数类型和浮点数类型可以为空(NULL),在定义数据组或序列时,使用dtype参数来定义整数类型:
arr = pd.array([1, 2, np.nan], dtype=pd.Int64Dtype()) pd.array([1, 2, np.nan], dtype="Int64") pd.Series([1, 2, np.nan], dtype="Int32")
使用float32、float64定义浮点数类型:
>>> pd.Series([1, 2, np.nan], dtype="float32") 0 1.0 1 2.0 2 NaN dtype: float32
4,日期和时间类型类型
datetime64[ns] 表示的是日期和时间类型
>>> pd.Series(['2018-07-01', '2019-07-01', '2019-10-01'], dtype="datetime64[ns]") 0 2018-07-01 1 2019-07-01 2 2019-10-01 dtype: datetime64[ns]
六,类型转换
可以使用astype()函数,显式把对象的类型从一个类型强制转换为指定的数据类型:
>>> pd.Series(['2018-07-01', '2019-07-01', '2019-10-01']).astype('datetime64[ns]') 0 2018-07-01 1 2019-07-01 2 2019-10-01 dtype: datetime64[ns]
pandas还有类型转换的特殊函数,用于转换为特定的数据类型:
- to_numeric()
- to_datetime()
- to_timedelta()
比如,把序列转换为日期类型:
>>> pd.to_datetime(pd.Series(['2018-07-01', '2019-07-01', '2019-10-01'])) 0 2018-07-01 1 2019-07-01 2 2019-10-01 dtype: datetime64[ns]
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号