Python 学习 第17篇:sqlalchemy 读写SQL Server数据库
在Python语言中,从SQL Server数据库读写数据,通常情况下,都是使用sqlalchemy 包和 pymssql 包的组合,这是因为大多数数据处理程序都需要用到DataFrame对象,它内置了从数据库中读和写数据的函数:read_sql()和to_sql(),这两个函数支持的连接类型是由sqlalchemy和pymssql构成的,因此,掌握这两个包对于查询SQL Server数据库十分必要。
一,SQLAlchemy的架构
在Python语言环境中,当需要和关系型数据进行交互时,SQLAlchemy是事实上的标准包。SQLAlchemy由两个截然不同的组件组成,称为Core和ORM(Object Relational Mapper,对象关系映射器),Core是功能齐全的数据库工具包,使用SQL 脚本来查询数据库;ORM是基于Core的可选包,把数据库对象抽象成表、列、关系等实体。但是SQLAlchemy本身无法操作数据库,需要pymssql等第三方数据库API(Database API ),简写为 DBAPI,根据数据库类型而调用不同的数据库API。
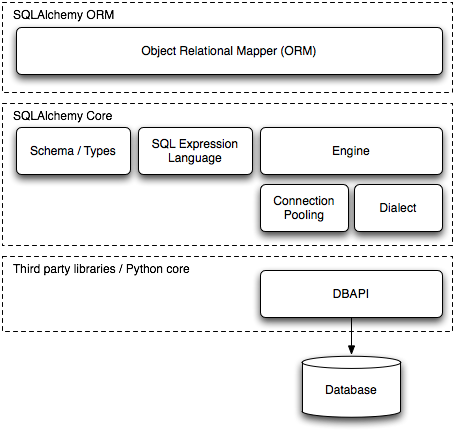
从上图可以看出,SQLAlchemy的基础是使用DB API跟数据库进行交互,而DB API不是一个package,而是一个规范,是一个抽象的接口,pymssql是实现该规范的一个工具包。
SQLAlchemy的Core组件使用DBAPI来和数据库进行交互,当使用SQL脚本对数据库执行查询和修改操作时,必须用到SQLAlchemy的Engine 对象和Dialect对象。Engine 对象用于创建连接,连接到SQL Server,而Dialect对象(通常是Cursor对象)代表执行上下文,表示向SQL Server发送的请求和返回的结果。
本文主要分享使用Core组件来和数据库进行交互。
二,SQLAlchemy的Engine实例
使用SQLAlchemy从数据库中读写数据的基本用法:通过SQL 语句更新数据,通过DataFrame的read_sql()函数从数据库中读取数据,通过to_sql()函数把数据写入到数据表中。
在对数据库执行读写操作之前,必须连接到数据库。SQLAlchemy通过 create_engine () 函数创建Engine,使用Engine管理DBAPI的连接,DBAPI的连接仅仅表示一种连接资源。应用Engine最有效率的方式是在模块级别创建一次,而不是按照对象或函数来调用。
import pymssql import sqlalchemy from sqlalchemy import create_engine connection_format = 'mssql+pymssql://{0}:{1}@{2}/{3}?charset=utf8' connection_str = connection_format.format(db_user,db_password,db_host,db_name) engine = create_engine(connection_str,echo=False)
对于SQL Server数据库来说,连接字符串的格式是:
dialect[+driver]://user:password@host/dbname?charset=utf8
其中,dialect 代表数据库类型,比如 mssql、mysql等,driver 代表DBAPI的类型,比如 psycopg2、pymysql等。
当echo参数为True时,会显示执行的SQL语句,推荐把echo设置False,关闭日记功能。
Engine对象可以直接用于向数据库发送SQL 脚本,调用Engine.execute()函数执行SQL脚本。
三,连接数据库
最通用的方法是通过Engine.connect()方法获得连接资源,connection 是Connection类的一个实例,是DBAPI连接的一个代理对象。
connection = engine.connect() result = connection.execute("select username from users") for row in result: print("username:", row['username']) connection.close()
result是ResultProxy的一个实例,该实例引用DBAPI的cursor。如果执行SELECT命令,当把所有的数据行都返回时,ResultProxy将自动关闭DBAPI的游标。如果执行UPDATE命令,不返回任何数据行,在命令执行之后,游标立即释放资源。
四,查询的结果
使用Engine 或 Connection的execute()函数执行select查询,返回游标变量。游标标量是一个迭代器,每次迭代返回的结果都是一个数据行,数据行是由字段构成的元组:
cursor = connection.execute(' select * from dbo.vic_test') for row in cursor: do_something
也可以使用DataFrame对象的read_sql()函数,把数据读取到DataFrame对象中,或者调用DataFrame对象的to_sql()函数,把DataFrame对象中的数据写入到关系表中。
五,显式使用事务
Connection对象提供begin()函数显式开始一个事务(Transaction)对象,该对象通常用于try/except代码块中,以保证调用Transaction.rollback() 或 Transaction.commit()。
connection = engine.connect() tran = connection.begin() try: connection.execute('sql statement') tran.commit() except: tran.rollback() raise
sqlalchemy实现了自动提交(autocommit),使用Connection.execution_options()方法来设置autocommit选项,实现事务的自动提交:
conn.execute(sql_text("SELECT my_mutating_procedure()").execution_options(autocommit=True))
如果设置选项autocommit=True(默认为True),那么检测会自动进行。如果执行的纯文本的SQL语句,并且语句中包含数据修改和数据定义命令,那么自动提交事务。
六,附上代码库
import pymssql from sqlalchemy import create_engine import pandas as pd from sqlalchemy.sql import text as sql_text class DBHelper(): def __init__(self): self.db_host = r'' self.db_name = r'' self.db_user = r'' self.db_password = r'' ###################################################### ## data connection ## ###################################################### def get_engine(self): str_format = 'mssql+pymssql://{0}:{1}@{2}/{3}?charset=utf8' connection_str = str_format.format(self.db_user,self.db_password,self.db_host,self.db_name) engine = create_engine(connection_str,echo=False) return engine ###################################################### ## common SQL APIs ## ###################################################### def write_data(self,df,destination,if_exists='append',schema='dbo'): engine = self.get_engine() df.to_sql(destination, con=engine, if_exists=if_exists,index = False, schema=schema, method='multi', chunksize=100) def read_data(self,sql): engine = self.get_engine() df = pd.read_sql(sql, con=engine) return df def exec_sql(self,sql): engine = self.get_engine() with engine.connect() as con: with con.begin(): con.execute(sql_text(sql).execution_options(autocommit=True))
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号