评估分类模型的指标:召回率、精确率、F1值
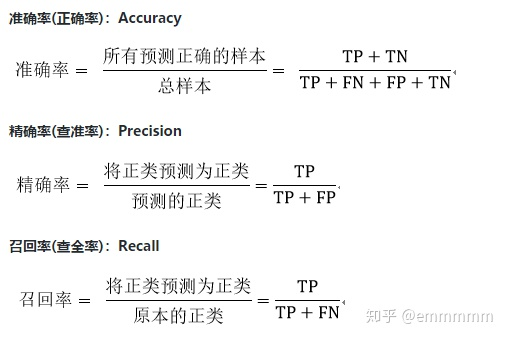
评估分类模型性能的方法是:混淆矩阵,其总体思路是统计A类别实例被预测(分类)为B类别的次数。召回率(Recall)和精度(Precise)是广泛用于统计学分类领域的两个度量值,用来评估分类结果的质量。
召回率(Recall Rate,也叫查全率)是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;
精度(Precision Rate,也叫查准率)是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
一,混淆矩阵
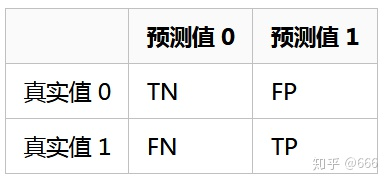
要解释清楚精确率和召回率,得先解释混淆矩阵,二分类问题的混淆矩阵由 4 个数构成。
- 真阴性(True Negatives,TN):算法预测为负例(N),实际上也是负例(N)的个数,即算法预测对了(True);
- 真阳性(True Positives,TP):算法预测为正例(P),实际上是负例(N)的个数,即算法预测错了(False);
- 假阴性(False Negatives,FN): 算法预测为负例(N),实际上是正例(P)的个数,即算法预测错了(False);
- 假阳性(False Positives,FP):算法预测为正例(P),实际上也是正例(P)的个数,即算法预测对了(True)。
混淆矩阵定义如下:
二,召回率和精确率
对于精确率和召回率:一句话,精确率就是“查的准”,召回率就是“查的全”:
1, 精确率
准确率的含义是:预测为正例的那些数据里预测正确的数据个数”
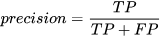
2,召回率
召回率的含义是:真实为正例的那些数据里预测正确的数据个数
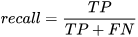
3,准确率和召回率的相互关系
准确率和召回率互相影响,理想状态下肯定追求两个都高,但是实际情况是两者相互“制约”:追求准确率高,则召回率就低;追求召回率高,则通常会影响准确率。若两者都低,则一般是出了某种问题。
在一组不同阈值下,准确率和召回率的关系如下图:
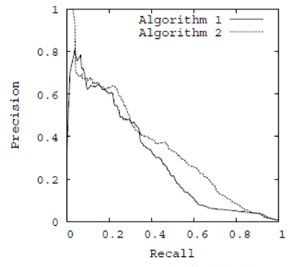
4,调和均值
精准率和召回率是此消彼长的,即精准率高了,召回率就下降,在一些场景下要兼顾精准率和召回率,就有 F1 score。
F1值是来综合评估精确率和召回率,当精确率和召回率都高时,F1也会高
F1的公式为:

有时候我们对精确率和召回率并不是一视同仁,我们用一个参数 来度量两者之间的关系。
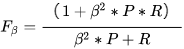
如果 >1,召回率有更大的影响;
如果 <1,精确率有更大的影响;
如果 =1,精确率和召回率影响力相同,和
形式一样;
参考文档:
作者:悦光阴
本文版权归作者和博客园所有,欢迎转载,但未经作者同意,必须保留此段声明,且在文章页面醒目位置显示原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号