DAX:表值函数 SUMMARIZECOLUMNS的语法介绍
SUMMARIZECOLUMNS是一个专门用于查询和计算表的函数,主要包含分组列和扩展列。
- 分组列是用于分组的列,只能来源于基础表中已有的列,分组列可以来源于同一个表,也可以来源于相关的列。
- 扩展列是由name和expression对构成的,name是字符串,expression是包含聚合函数的表达式。
1,SUMMARIZECOLUMNS的语法
SUMMARIZECOLUMNS 函数不是一个迭代函数,分组列之间不要求必须有关系,对于不同表,分组列之间是交叉连接(cross-join);对于相同表,分组列之间使用的是自动存在(auto-existed)。
SUMMARIZECOLUMNS( <groupBy_columnName> [, < groupBy_columnName >]…, [<filterTable>]…[, <name>, <expression>]…)
参数注释:
groupBy_columnName:分组列,分组列必须使用列的完全限定名,格式是table[column],该列必须是基础表中的列,分组列可以有0个或多个。多个分组列之间的表不要求必须有关系,对于不同表,分组列之间是交叉连接(cross-join);对于相同表,分组列之间使用的是自动存在(auto-existed)。
filterTable:可选参数,该参数是一个表值表达式,只能使用表形式的过滤器参数。filterTable会被添加到分组列的筛选上下文中,对分组列所在的基础表进行过滤。要设置常量来过滤分组列,需要使用TREATS函数设置数据沿袭。在分组列执行cross-join/auto-exist之前,SUMMARIZECOLUMNS 函数使用filterTable中的值对分组列进行过滤,这是为了降低分组列的行数,提高cross-join/auto-exist的性能。如果把该表达式嵌入到 NONVISUAL 函数中,那么filterTable参数中的值被标记为不影响度量值,而仅适用于分组列。
name、expression:可选参数,该参数总是成对存在,表示添加列,该参数对总是成对出现的,name是列的名称,expression用于计算列的值。
2,SUMMARIZECOLUMNS不能用于上下文转换
SUMMARIZECOLUMNS函数没有行上下文,只包含筛选上下文,并且不能用在上下文转换中。
如果外部上下文已经完成了转换,那么SUMMARIZECOLUMNS 不能被调用,这使得它没法用在大多数度量中,这是因为度量通常都被隐式封装在CALCULATE函数中,而CALCULATE通常需要进行上下文转换。如果度量中包含SUMMARIZECOLUMNS 函数,那么在任何上下文转换的情况下都不能调用SUMMARIZECOLUMNS 函数。由于Power BI几乎总是会生成上下文转换来计算度量,所以SUMMARIZECOLUMNS 几乎不能用在Power BI报表的度量中。
如果筛选上下文包含行上下文,或者由上下文转换生成的筛选上下文,那么不能使用 SUMMARIZECOLUMNS,它是一个专门用于查询和计算表的函数,以下查询产生错误:
SUMX ( SUMMARIZECOLUMNS ( 'Product'[Brand], "Qty", SUM ( Sales[Quantity] ) ), [Qty] )
3,SUMMARIZECOLUMNS的过滤器
SUMMARIZECOLUMNS函数总是把同一张表上的过滤器组合成一个过滤器,这是auto-exist的机制,此过滤器生成的组合表仅包含在SUMMARIZECOLUMNS 中作为分组列的列,或者filterTable参数显式列出的列,这种自动存在(auto-exists)的行为会对FILTERS 等函数有副作用。
SUMMARIZECOLUMNS函数的过滤器的作用:仅用于过滤度量和位于同一表中的分组列。这些过滤器不能直接过滤来自不同表的分组列,但是能够通过度量中隐含的非空过滤器间接过滤不同表的分组列。
为了无条件地把过滤器应用于分组列,请通过CALCULATETABLE 函数应用过滤器来计算 SUMMARIZECOLUMNS。
4,SUMMARIZECOLUMNS 函数执行的过程
对于以下代码,SUMMARIZECOLUMNS函数执行的过程是:
Sales by Year and Color new style = SUMMARIZECOLUMNS ( 'Date'[Calendar Year], 'Product'[Color], TREATAS ( { 2018 },'Date'[Calendar Year] ), "Sales Amount", SUMX ( Sales, Sales[Quantity] * Sales[Unit Price] ) )
第一步:使用TREATS来创建数据沿袭,并设置Calendar Year的值是2018。如果SUMMARIZECOLUMNS函数没有fiterTable参数,所以分组列的所有的值都将成为过滤器。
第二步:由于分组列来自不同的表,分组列的值先进行交叉连接(cross join),并把结果集作为SUMMARIZECOLUMNS函数的筛选上下文。
第三步:在SUMMARIZECOLUMNS函数的筛选上下文中计算度量。
注意:返回的表包含分组列和扩展列,返回的数据行中,至少包含一个非空值,如果一个数据行中所有expression的结果都是BLANK/NULL,那么该行不包含在汇总表中。
另外一个汇总函数是被弃用的SUMMARIZE,这个函数存在很大的性能问题,请停止使用。
5,IGNORE选项
IGNORE只能用于SUMMARIZECOLUMNS函数中,用于修改 SUMMARIZECOLUMNS 函数的默认行为。只是这个函数名非常具有迷惑性,命名给差评。
那什么是SUMMARIZECOLUMNS 函数的默认行为:对于不使用IGNORE()的表达式,如果所有行都返回 BLANK/NULL,那么这些行将被排除。
IGNORE()函数的作用是:在调用SUMMARIZECOLUMNS函数时,IGNORE() 标记一个度量表达式,如果所有行都返回 BLANK/NULL,那么这些行会返回BLANK,而不是被排除。
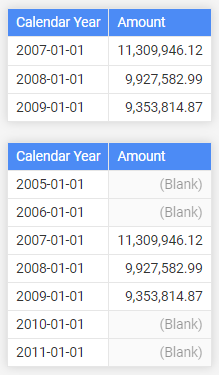
举个例子,使用IGNORE()标记一个Measure,在特定的[Calendar Year]中,如果所有行都返回BLANK,那么在结果中显示该[Calendar Year],并设置Measure的值是BLANK。
EVALUATE SUMMARIZECOLUMNS ( 'Date'[Calendar Year], "Amount", [Sales Amount] ) EVALUATE SUMMARIZECOLUMNS ( 'Date'[Calendar Year], "Amount", IGNORE ( [Sales Amount] ) )
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号