


爬虫
一、python 连接测试URL
① 导入库
from requests import get
② 设定url, 并使用get方法请求页面得到响应
url = "https://hao.360.cn/"
r = get(url, timeout=3)
print("获得响应的状态码:", r.status_code)
print("响应内容的编码方式:", r.encoding)
运行结果:
获得响应的状态码: 200
响应内容的编码方式: ISO-8859-1
③ 获取网页内容
r.encoding = "utf-8"
url_text = r.text
print("网页内容:", r.text)
print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html> <!--STATUS OK--><html> <head> ... 意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
网页内容长度: 2287
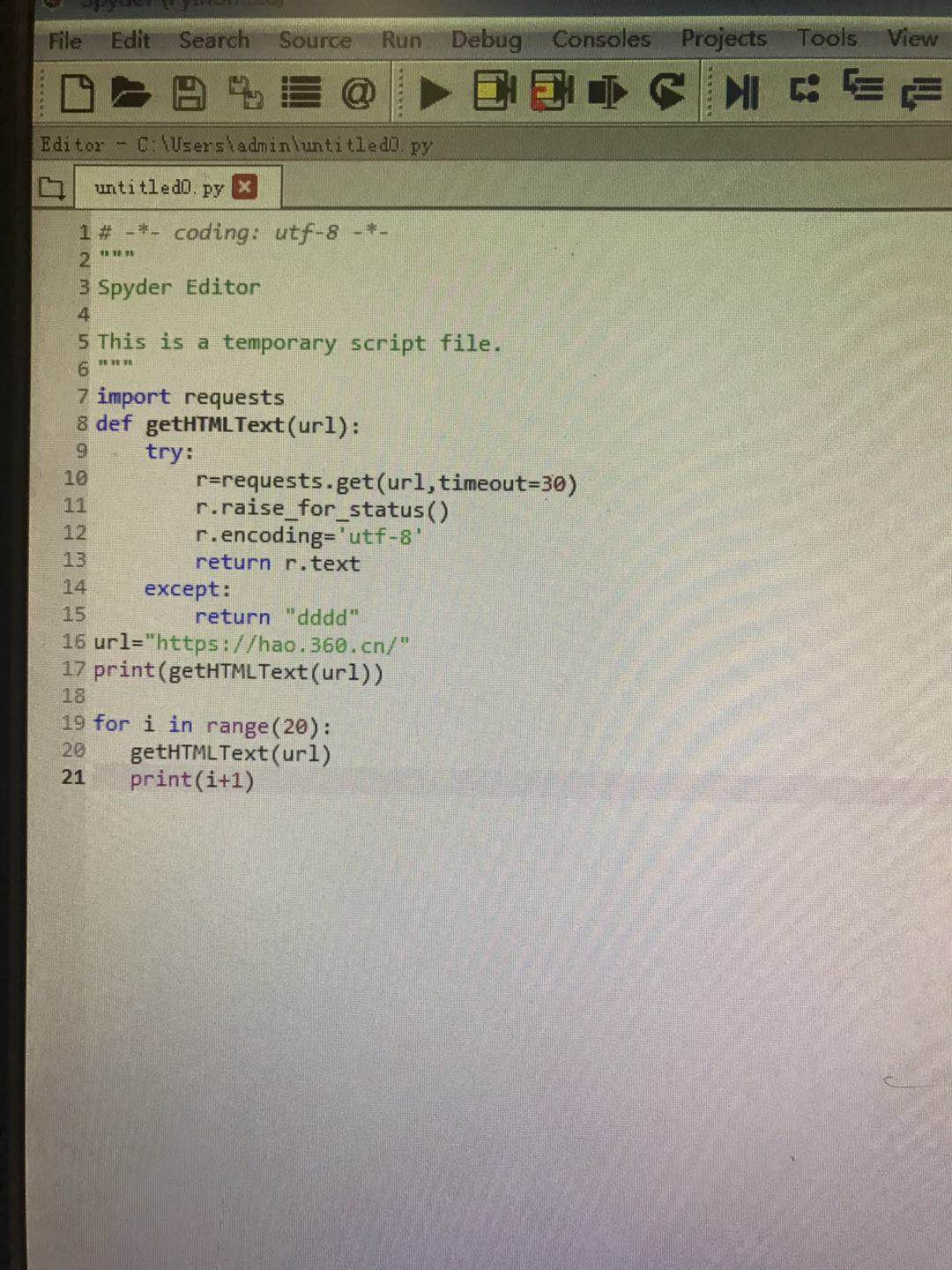
二、python 连接360浏览器20次
①输入代码
"""
Spyder Editor
This is a temporary script file.
"""
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding='utf-8'
return r.text
except:
return "dddd"
url="https://hao.360.cn/"
print(getHTMLText(url))
for i in range(20):
getHTMLText(url)
print(i+1)
②效果如图
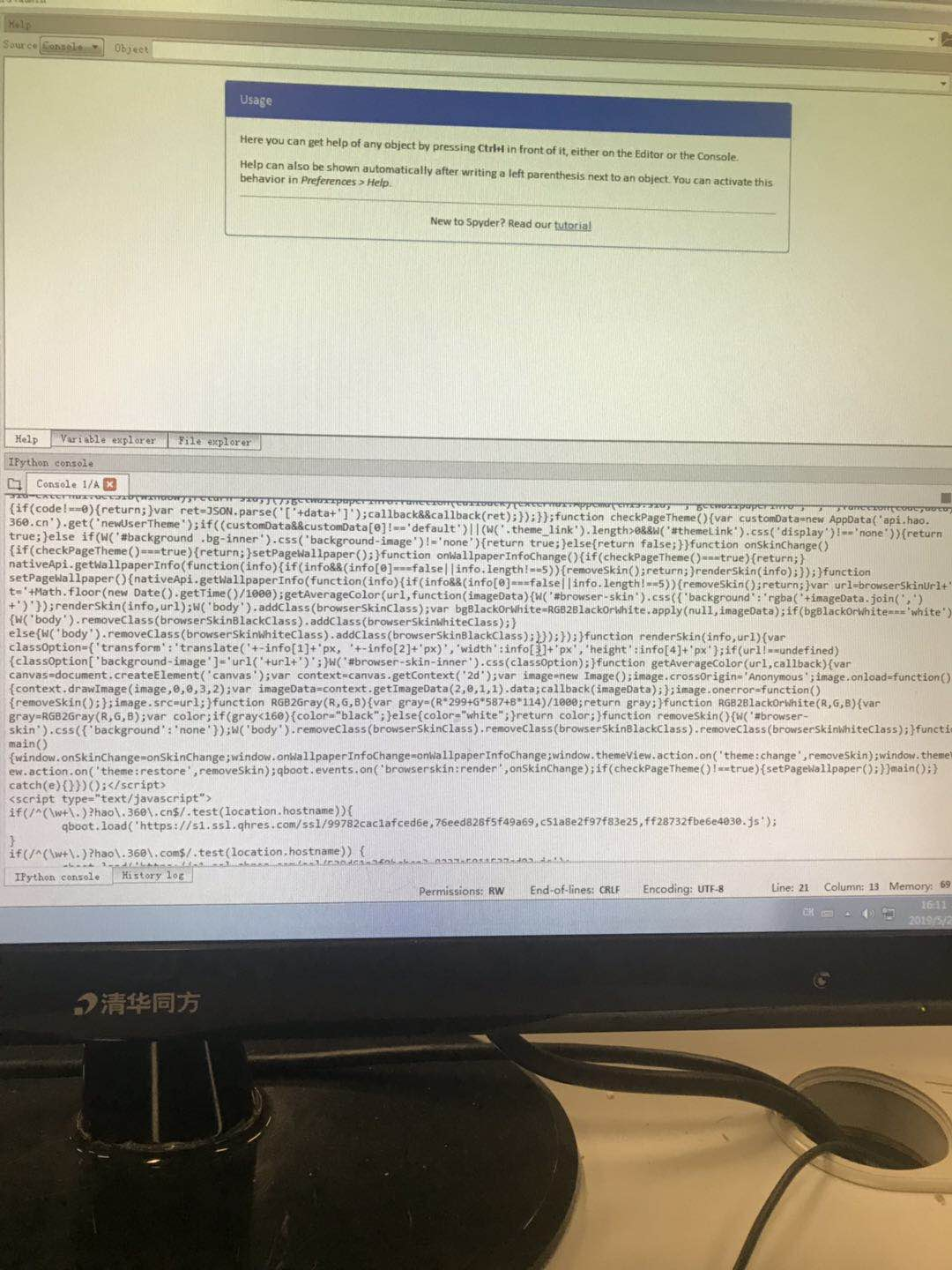
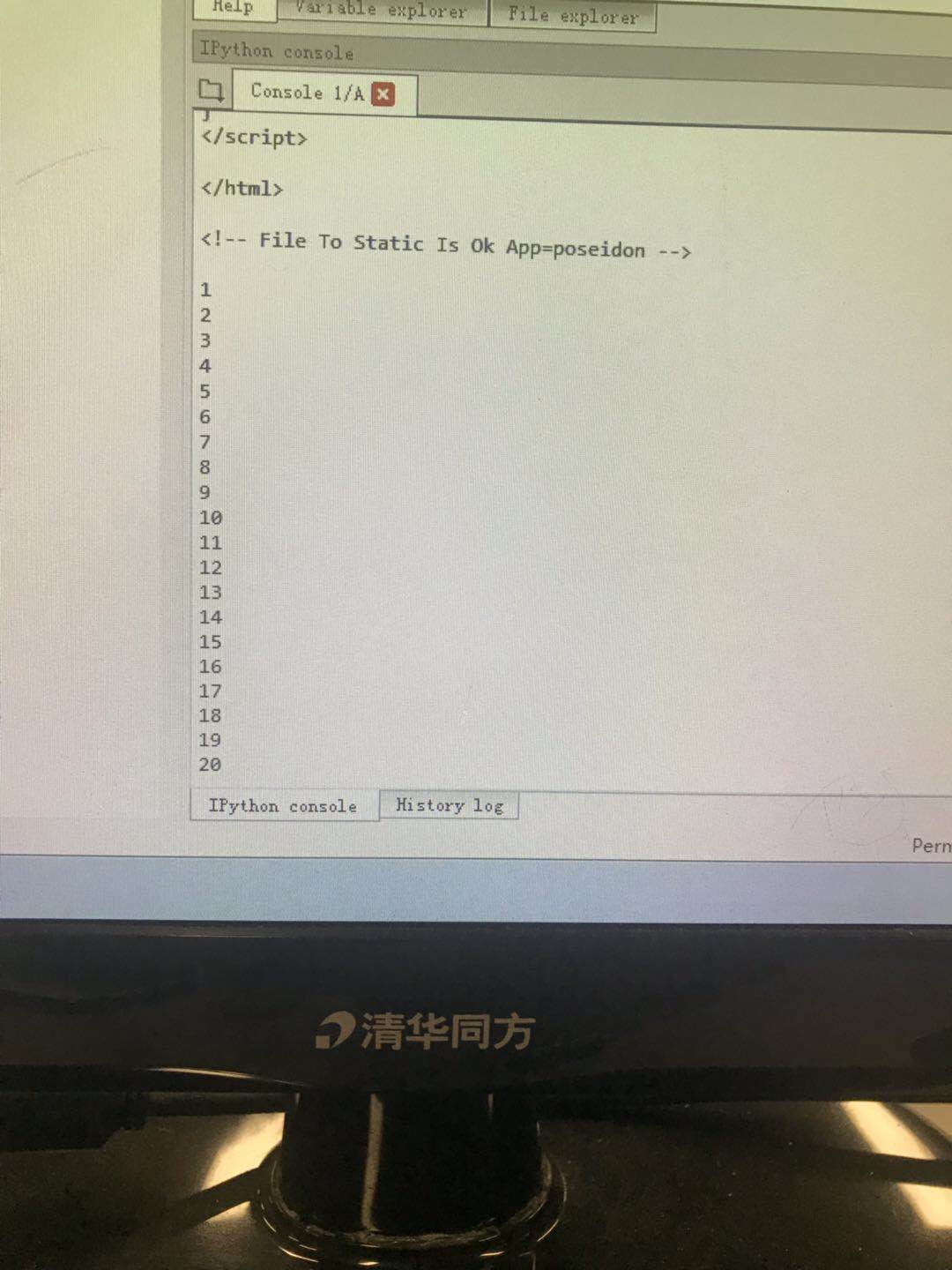
下图显示次数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号