



从YOLOv1到YOLOv13,再到YOLO26 - 实践
YOLO(You Only Look Once)系列目标检测算法自2015年首次发布以来,经历了快速的发展和迭代。从最初的YOLOv1到即将问世的YOLO26,该系列算法在实时性、准确性和效率上不断取得突破。YOLOv1奠定了基础,通过单阶段处理图像,实现了良好的准确性和速度。
随后的版本如YOLOv2、YOLOv3等不断引入新架构和数据增强技术,提升检测性能。YOLOv5由Ultralytics改进,提供了更好的性能和速度权衡。YOLOv10由清华大学创建,采用无NMS训练和效率驱动的架构,达到先进性能。YOLOv13引入超图增强等新机制,进一步提升性能。YOLO26则专为边缘和低功耗设备设计,展现了对不同应用场景的适应性。
YOLO的发展轨迹
YOLOv1:由 Joseph Redmon 等人于 2015 年首次提出,通过单阶段处理图像来提供良好的准确性和速度。第一个YOLO版本为实时应用奠定了基础,为后续开发树立了新标准。
YOLOv2:或 YOLO9000在 v1 基础上进行扩展,提高环境运行的分辨率,并能够检测超过 9000 个物体类别,从而增强了其多功能性和准确性。
YOLOv3通过:YOLO 模型系列的第三次迭代,以其高效的实时目标检测能力而闻名。通过多尺度预测和更深的网络架构进一步提升了这些功能,从而能够更好地检测较小物体。
YOLOv4:由 Alexey Bochkovskiy 于 2020 年发布的 YOLOv3 的 darknet 原生更新版本。融合了CSP 连接和 Mosaic 数据增强等功能。
YOLOv5:Ultralytics 改进的 YOLO 架构版本,与以前的版本相比,提供了更好的性能和速度权衡。
YOLOv6:由美团于 2022 年发布,并应用于该公司的许多自动送货机器人中。
YOLOv7:YOLOv4 的作者于 2022 年发布的更新的 YOLO 模型。仅支持推理。
YOLOv8:一种多功能模型,具有增强的功能,例如实例分割、姿势/关键点估计和分类。
YOLOv9:在 Ultralytics YOLOv5 代码库上训练的实验模型,实现了可编程梯度信息 (PGI)。
YOLOv10:由清华大学开发,具有无 NMS 训练和效率驱动的架构,可提供最先进的性能和延迟。
YOLOv11:Ultralytics 的 YOLO 系列模型,可在包括检测、分割、姿势估计、跟踪和分类在内的多个任务中提供最先进 (SOTA) 的性能。
YOLOv12 YOLO 系列首个完全基于注意力机制的目标检测模型。通过引入区域注意力(A²)、残差高效聚合网络(R-ELAN)等创新,在COCO信息集实现58.9% mAP精度和208FPS实时性能。就是:由纽约州立大学布法罗分校和中国科学院大学联合发布,
YOLOv13:由清华大学等国内各大高校联合发布,在继承 YOLO 系列实时检测优点的基础上,引入了超图增强、高阶语义建模、轻量化结构重构等一系列新机制。
YOLO26:Ultralytics 公司发布的 YOLO 系列实时物体检测器的最新产品,专为边缘和低功耗设备而设计。
YOLOv1 和 YOLOv2
论文标题:《You Only Look Once: Unified, Real-Time Object Detection》和《YOLO9000: Better, Faster, Stronger》
论文地址:https://arxiv.org/pdf/1506.02640 和 https://arxiv.org/pdf/1612.08242
Github:http://pjreddie.com/darknet/yolov1和 https://github.com/pjreddie/darknet
YOLOv1 由 Joseph Redmon 于 2015 年首次发布,它的单次机制彻底改变了目标检测,该机制利用更简单的 Darknet19 架构在一次网络传递中预测边界框和类概率。此种初始方法显著加速检测过程,建立了基础技能,并将在 YOLO 系列的后续版本中进行完善。
YOLOv2 于 2016 年发布,引入了一种新的 30 层架构,带有来自 Faster R-CNN 的锚框和批量归一化,以加速收敛并增强模型性能。
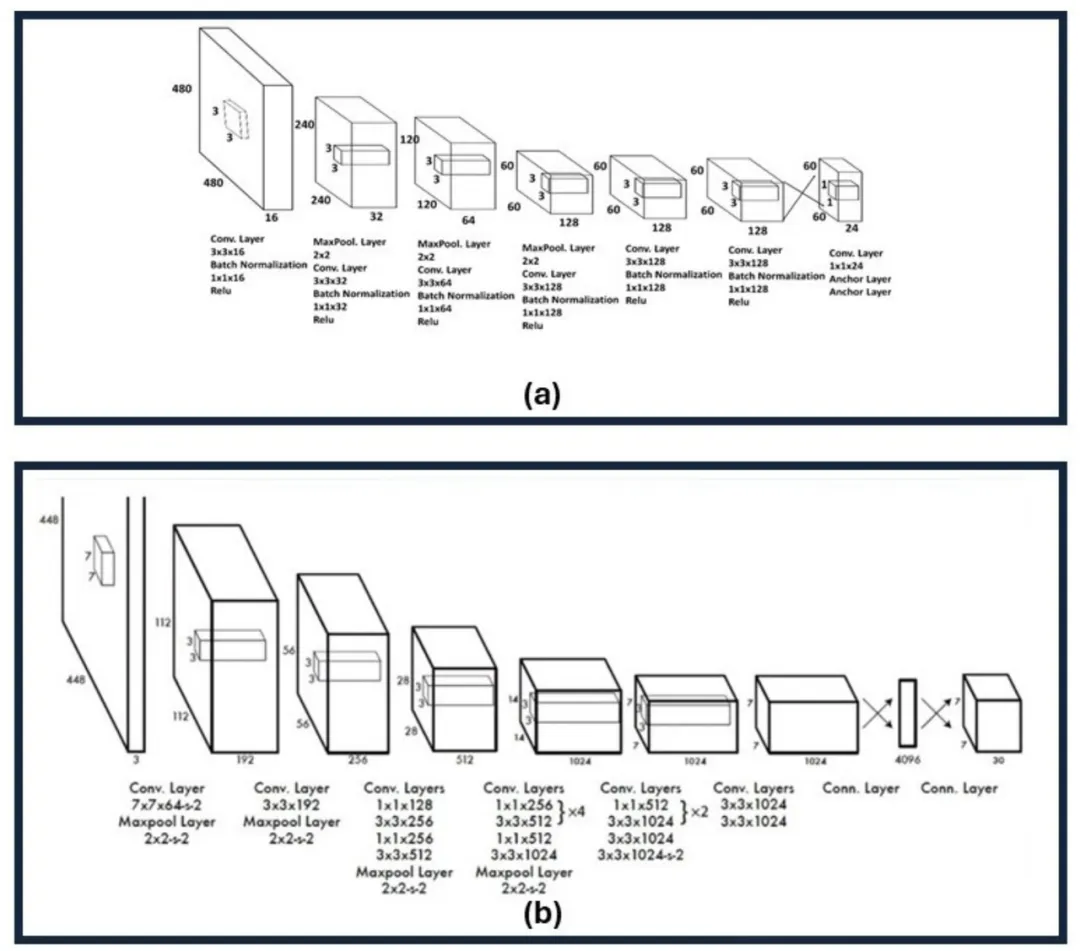
YOLOv1 和 YOLOv2 架构的比较。
(a) YOLOv1 架构,显示了用于目标检测的卷积层、最大池层和全连接层的序列。该模型在一个统一的步骤中执行特征提取和预测,旨在完成实时性能。
(b) YOLOv2 架构,展示了诸如使用批量归一化、更高分辨率的输入和锚框等改进
YOLOv3 和 YOLOv4
论文标题:《YOLOv3: An Incremental Improvement》和《YOLOv4: Optimal Speed and Accuracy of Object Detection》
论文地址:https://arxiv.org/pdf/1804.02767 和 https://arxiv.org/pdf/2004.10934
Github:https://github.com/pjreddie/darknet和 https://github.com/AlexeyAB/darknet
YOLOv3:这是 You Only Look Once (YOLO) 目标检测算法的第三个版本,引入了利用三种不同尺度进行检测的方法,利用了三种不同大小的检测核:13x13、26x26 和 52x52。这显著提高了对不同大小物体的检测精度。此外,YOLOv3 还增加了诸如每个边界框的多标签预测和一个更好的特征提取网络等作用。
YOLOv4:代表 You Only Look Once version 4(第 4 版)。它是一种实时目标检测模型,旨在消除之前 YOLO 版本(如 YOLOv3)和其他目标检测模型的局限性。利用多种创新功能协同工作以优化其性能。这些能力包括加权残差连接 (WRC)、跨阶段局部连接 (CSP)、跨 mini-批归一化 (CmBN)、自对抗训练 (SAT)、Mish 激活、Mosaic 内容增强、DropBlock 正则化和 CIoU 损失。这些功能相结合,实现了当时最先进的结果。
YOLOv4 中引入的架构创新影响了这些后续模型的发展。
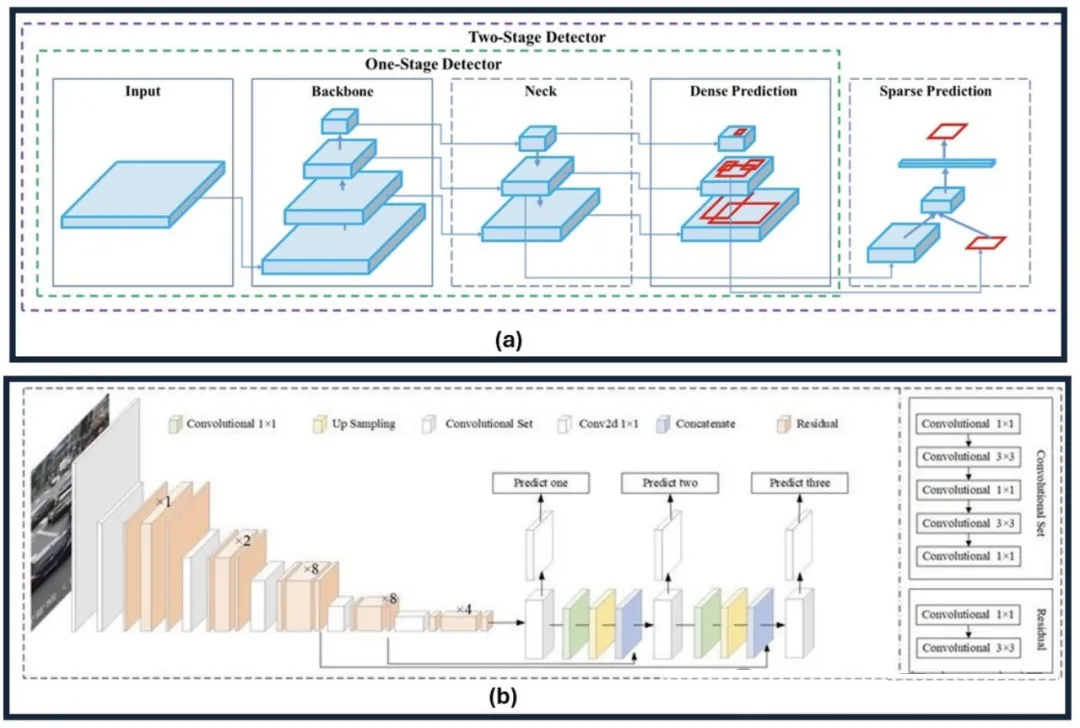
YOLOv4 和 YOLOv3 架构比较。
(a) YOLOv4 架构表明了具有骨干、颈部、密集预测和稀疏预测模块的两级检测器。
(b) YOLOv3 架构具有卷积层和上采样层,可实现多尺度预测。这凸显了两个版本之间在目标检测方面的结构进步
YOLOv5
GitHub:https://github.com/ultralytics/yolov5.git
标志着YOLO系列的重大演变,专注于为实际应用程序提供简化架构的生产部署。该版本强调通过细化模型的层和组件来降低模型的复杂性,在不牺牲检测精度的情况下提高推理速度。
YOLOv5 的架构融合了一系列优化,包括改进的骨干、颈部和头部设计,共同增强了其检测能力。其核心是,引入了 CSP 网络,提高网络的效率并减少计算需求。通过多个空间金字塔池化(SPP)块进一步优化了CSPNet,允许在不同尺度上进行特征提取。
Neck 特征采用路径聚合网络(PAN)模块,并增加了上采样层以改善特征图的分辨率。Head 是一系列卷积层,用于生成边界框和类别标签的预测。使用基于 Anchor 的预测,将每个边界框与一组特定形状和大小的预定义 Anchor 框相连接。
损失函数计算涉及两个核心部分:二进制交叉熵用于计算类别和目标性损失,而完整交并比(CIoU)用于衡量定位准确性。
YOLOv6
论文标题:《YOLOv6 v3.0: A Full-Scale Reloading》
论文地址:https://arxiv.org/pdf/2301.05586
GitHub:https://github.com/meituan/YOLOv6
该模型在其架构和训练方案中引入了多项显着增强功能,包括双向连接 (BiC) 模块的实现、锚点辅助训练 (AAT) 策略以及改进的 backbone 和 neck 设计,从而在 COCO dataset 上实现了最先进的精度。

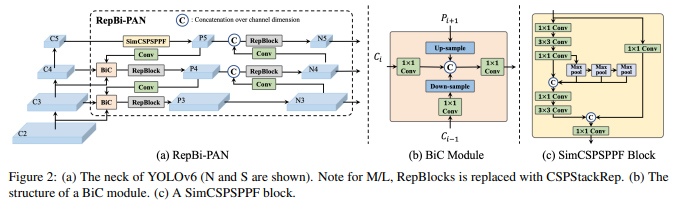
YOLOv6 概述。模型架构图,展示了经过重新设计的网络组件和训练策略,这些改进显著提升了性能。
(a) YOLOv6 的 neck(显示了 N 和 S)。请注意,对于 M/L,RepBlocks 被替换为 CSPStackRep。
(b) BiC 模块的结构。(c) SimCSPSPPF 块
双向连接 (BiC) 模块:YOLOv6 在检测器的 neck 中引入了 BiC 模块,增强了定位信号,并在速度几乎没有降低的情况下给予了性能提升。
Anchor-Aided Training (AAT) Strategy:该模型提出了 AAT,以享受基于 anchor 和 无 anchor 范例的优势,而不会影响推理效率。
增强的骨干网络和 Neck 设计:借助加深 YOLOv6 以在骨干网络和 Neck 中囊括另一个阶段,该模型在高分辨率输入下构建了 COCO 数据集上的最先进性能。
自蒸馏策略:采用一种新的自蒸馏策略来提升 YOLOv6 较小模型的性能,在训练期间增强辅助回归分支,并在推理时移除它,以避免显著的速度下降。
YOLOv7
论文标题:《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
论文地址:https://arxiv.org/pdf/2207.02696
GitHub:https://github.com/WongKinYiu/yolov7
在 5 FPS 到 160 FPS 的范围内,其速度和准确性均超过当时所有已知的对象检测器。在 GPU V100 上,它是所有当时已知实时对象检测器中准确性最高的(56.8% AP),帧率达到 30 FPS 或更高。此外,YOLOv7 在速度和准确性方面均优于其他对象检测器,如 YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5 等。该模型从头开始在 MS COCO 数据集上进行训练,未使用任何其他素材集或预训练权重。
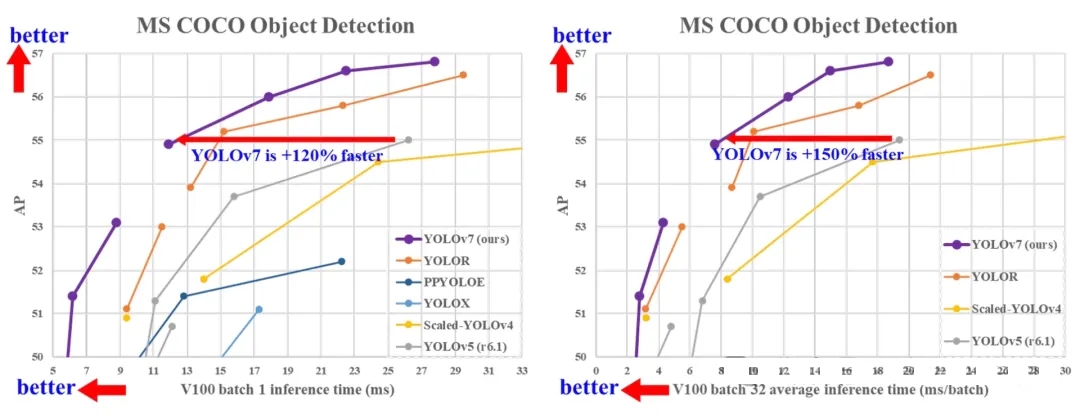
模型重参数化: YOLOv7 提出了一种计划的重参数化模型,这是一种适用于具有梯度传播路径概念的不同网络中的层的策略。
动态标签分配: 使用多个输出层训练模型会带来一个新难题:“如何为不同分支的输出分配动态目标?”为了解决这个问题,YOLOv7 引入了一种新的标签分配方法,称为由粗到细的引导式标签分配。
扩展和复合缩放通过: YOLOv7 针对实时目标检测器提出了“扩展”和“复合缩放”方法,能够有效地利用参数和计算。
效率: YOLOv7 提出的办法可以有效地减少约 40% 的参数和 50% 的最先进的实时目标检测器的计算量,并且具有更快的推理速度和更高的检测精度。
YOLOv8
GitHub:https://github.com/ultralytics/ultralytics
由 Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面提供了前沿的性能。YOLOv8 在之前 YOLO 版本的基础上进行了改进,引入了新的特性和优化,使其成为各种应用中各种目标检测任务的理想选择。
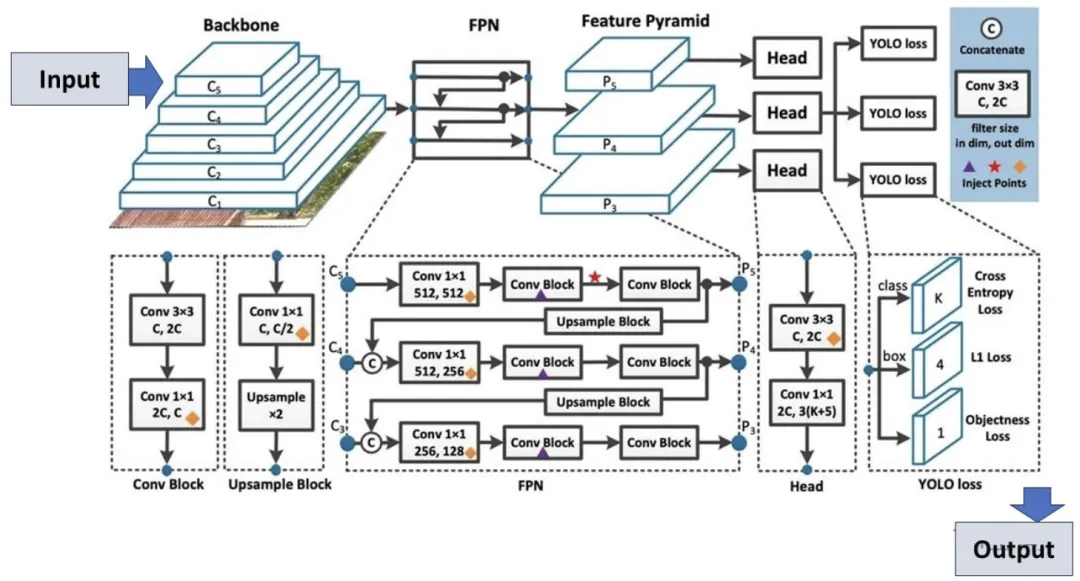
YOLOv8 架构:展示关键组件及其连接。 主干网络通过多个卷积层(C1至C5)处理输入图像,提取层次特征。然后这些特征经过特征金字塔网络(FPN)创建特征金字塔(P3、P4、P5),从而增强不同尺度的检测。网络头执行最终预测,结合卷积块和上采样块来细化特征
高级骨干和颈部架构:YOLOv8 采用最先进的骨干和颈部架构,从而改进了特征提取和目标检测性能。
无锚点分离式 Ultralytics Head:YOLOv8 采用无锚点分离式 Ultralytics head,与基于锚点的方法相比,这有助于提高准确性并提高检测效率。
优化的准确性-速度权衡:YOLOv8 专注于在准确性和速度之间保持最佳平衡,适用于各种应用领域中的实时对象检测任务。
多种预训练模型:通过YOLOv8 提供了一系列预训练模型,以满足各种任务和性能需求,从而能够更轻松地找到适合您特定用例的正确模型。
YOLOv9
论文标题:《YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information》
论文地址:https://arxiv.org/pdf/2402.13616
GitHub:https://github.com/WongKinYiu/yolov9
标志着实时对象检测的重大进步,引入了突破性技术,如可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN)。该模型在效率、准确性和适应性方面表现出显著的改进,在 MS COCO 数据集上设置了新的基准。
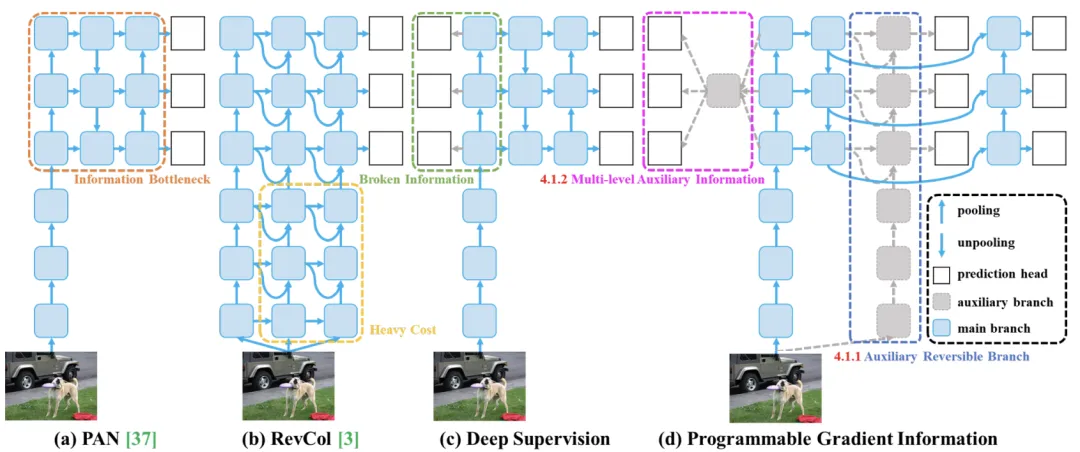
PGI和相关的网络架构及途径。(a)路径聚合网络(PAN),(b)可逆列(RevCol),(c)常规深度监控,以及(d)我们提出的可编程梯度信息(PGI)。PGI主要由三个部分组成:(1)主分支:用于推理的架构,(2)辅助可逆分支:生成可靠的梯度,为主分支提供反向传输,(3)多级辅助信息:控制主分支学习可规划的多级语义信息
YOLOv9 的进步深刻地植根于解决深度神经网络中信息丢失带来的挑战。信息瓶颈原理和可逆函数其设计的核心,确保 YOLOv9 保持高效率和准确性。就是的创新应用
可编程梯度信息 (PGI)
YOLOv9 中引入的一个新概念,旨在解决信息瓶颈问题,确保在深层网络层中保留基本数据。这允许生成可靠的梯度,从而促进准确的模型更新并提高整体检测性能。就是PGI
广义高效层聚合网络 (GELAN)
GELAN 代表了一种战略性的架构进步,使 YOLOv9 能够实现卓越的参数利用率和计算效率。它的设计允许灵活地集成各种计算块,使 YOLOv9 能够适应广泛的应用,而不会牺牲速度或准确性。

不同网络架构的随机初始权重输出特征图的可视化结果:(a)输入图像(b)PlainNet(c)ResNet(d)CSPNet,以及(e)GELAN。从图中行看出,在不同的架构中,提供给目标函数以计算损失的信息会不同程度地丢失,我们的架构许可保留最完整的信息,并为计算目标函数提供最可靠的梯度信息
YOLOv10
论文标题:《YOLOv10: Real-Time End-to-End Object Detection》
论文地址:https://arxiv.org/pdf/2405.14458
GitHub:https://github.com/THU-MIG/yolov10
由清华大学的研究人员基于 Ultralytics Python 包构建,它引入了一种新的实时对象检测方法,解决了之前 YOLO 版本中存在的后处理和模型架构缺陷。
通过消除非极大值抑制 (NMS) 并优化各种模型组件,YOLOv10 以显著降低的计算开销实现了最先进的性能。大量实验表明,它在多个模型规模上都具有卓越的精度-延迟权衡。
该模型架构包括以下组件:
- Backbone:YOLOv10 中的 Backbone 负责特征提取,它运用了 CSPNet(Cross Stage Partial Network)的增强版本,以改善梯度流并减少计算冗余。
- Neck:Neck 的设计目的是聚合来自不同尺度的特征,并将它们传递到 Head。它包括 PAN(路径聚合网络)层,用于有效的多尺度特征融合。
- One-to-Many Head:在训练期间为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- One-to-One Head:在推理期间为每个对象生成单个最佳预测,从而无需 NMS,从而减少延迟并提高效率。
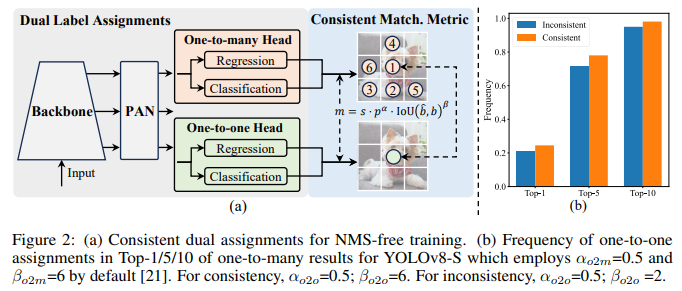
无NMS训练: 采用一致的对偶分配来消除对NMS的需求,从而减少推理延迟。
整体模型设计:从效率和准确性的角度对各种组件进行全面优化,包括轻量级分类 Head、空间通道解耦下采样和秩引导块设计。
增强的模型特性: 结合了大内核卷积和部分自注意力模块,以提高性能,而无需显著的计算成本。
YOLOv11
GitHub:https://github.com/ultralytics/ultralytics
YOLO11 是UltralyticsYOLO系列实时目标检测器的迭代版本,它以前沿的精度、速度和效率重新定义了可能性。YOLO11 在之前 YOLO 版本的显著进步基础上,在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务的多功能选择。
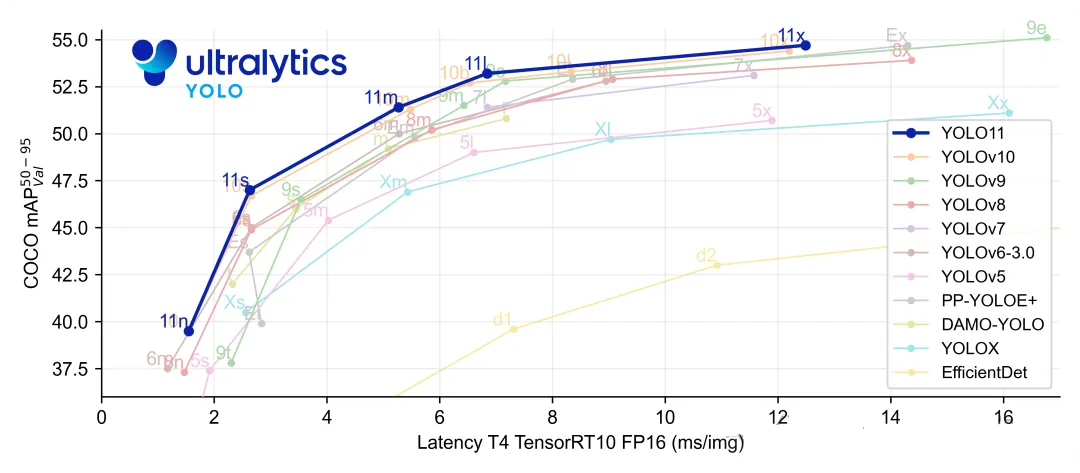
增强的特征提取:YOLO11 采用改进的 backbone 和 neck 架构,从而增强了特征提取能力,以构建更精确的目标检测和复杂的任务性能。
优化效率和速度:YOLO11 引入了改进的架构设计和优化的训练流程,从而提供更快的处理速度,并在精度和性能之间保持最佳平衡。
以更少的参数构建更高的精度:凭借模型设计的进步,YOLO11m 在 COCO 材料集上实现了更高的 平均精度均值 (mAP),同时比 YOLOv8m 使用的参数减少了 22%,从而在不影响精度的情况下提高了计算效率。
跨环境的适应性:YOLO11 可以无缝部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统,从而确保最大的灵活性。
广泛支持的任务范围:无论是目标检测、实例分割、图像分类、姿势估计还是旋转框检测 (OBB),YOLO11 都旨在满足各种计算机视觉挑战。
YOLOv12
论文标题:《YOLOv12: Attention-Centric Real-Time Object Detectors》
论文地址:https://arxiv.org/pdf/2502.12524
GitHub:https://github.com/sunsmarterjie/yolov12.git
YOLO12 引入了一种以注意力为中心的架构,它脱离了之前 YOLO 模型中利用的传统 CNN 方法,但保留了许多应用所必需的实时推理速度。该模型通过在注意力机制和整体网络架构方面的创新方法,实现了先进的目标检测精度,同时保持了实时性能。
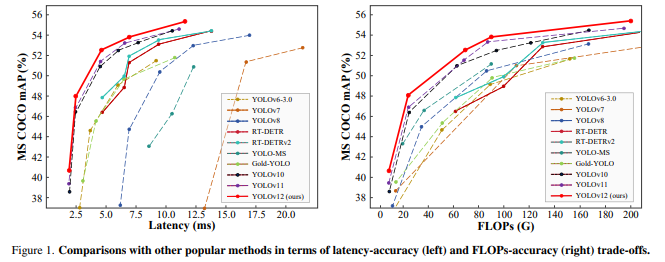
区域注意力机制通过: 一种新的自注意力方法,能够奏效地处理大型感受野。它将特征图分成l个大小相等的区域(默认为 4 个),水平或垂直,避免复杂的运算并保持较大的实用感受野。与标准自注意力相比,这大大降低了计算成本。
残差高效层聚合网络(R-ELAN)在更大规模的以注意力为中心的模型中。R-ELAN 引入:就是:一种基于 ELAN 的改进的特征聚合模块,旨在解决优化挑战,尤其
- 具有缩放的块级残差连接(类似于层缩放)。
一种重新设计的特征聚合方法,创建了一个类似瓶颈的结构。
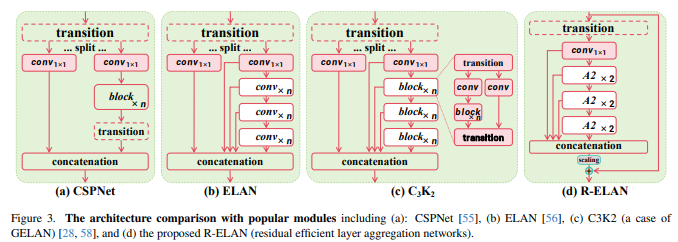
与流行模块的架构比较,包括(a):CSPNet(b)ELAN(c)C3K2(GELAN的一个例子)(d)R-ELAN(残差高效层聚合网络)
优化的注意力机制架构:YOLO12 精简了标准注意力机制,以提高效率并与 YOLO 框架兼容。这包括:
- 使用 FlashAttention来最大限度地减少内存访问开销。
- 移除位置编码,以获得更简洁、更高效的模型。
- 调整 MLP 比率(从典型的 4 调整到 1.2 或 2),以更好地平衡注意力和前馈层之间的计算。
- 减少堆叠块的深度以改进优化。
- 利用卷积运算(在适当的情况下)以提高其计算效率。
- 在注意力机制中添加一个7x7可分离卷积(“位置感知器”),以隐式地编码位置信息。
- 全面的任务支持: YOLO12 支持一系列核心计算机视觉任务:目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
- 增强的效率: 与许多先前的模型相比,以更少的参数建立了更高的准确率,从而证明了速度和准确率之间更好的平衡。
灵活部署: 专为跨各种平台部署而设计,从边缘设备到云基础设施。

运用X尺度模型获得的就是YOLOv10、YOLOv11和拟议的YOLOv12之间的热图比较。与先进的YOLOv10和YOLOv11相比,YOLOv12对图像中的物体有更清晰的感知。所有结果都
YOLOv13
论文标题:《YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception》
论文地址:https://arxiv.org/pdf/2506.17733
GitHub:https://github.com/iMoonLab/yolov13
YOLOv13是 YOLO 系列的最新版本,于 2025 年 6 月正式推出。该模型由清华大学和 iMoonLab 研究人员开发,旨在提升目标检测的精度和效率。YOLOv13 在 COCO 数据集上完成了更高的 mAP(平均精度),同时保持了较低的 FLOPs(计算量)和推理速度。该模型提供了多种尺寸版本,包括 Nano、Small、Large 和 X-Large,以适应不同应用场景的需求。
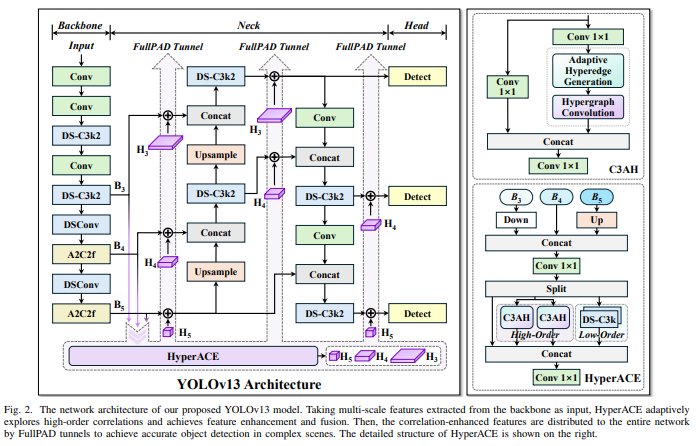
YOLOv13模型网络架构。HyperACE以骨干网提取的多尺度特征为输入,自适应地探索高阶相关性,达成特征增强和融合。继而,通过FullPAD隧道将相关增强特征分布到整个网络中,以实现复杂场景中的精确目标检测。HyperACE的详细结构如右图所示。
YOLOv13 的核心技术创新包括 HyperACE(基于超图的自适应关联增强)和 FullPAD 机制,这些技术提升了多尺度特征融合与感知能力,提升了繁琐场景下的检测性能。
HyperACE:基于超图的自适应相关增强
- 将多尺度特征图中的像素视为超图顶点。
- 采用可学习的超边构建模块,以自适应地探索顶点之间的高阶相关性。
- 利用具有线性复杂度的消息传递模块,在高级相关性的指导下有效聚合多尺度特征,以建立对复杂场景的管用视觉感知。
FullPAD:全流程聚合与分配范式
- 使用 HyperACE 聚合骨干网络的多尺度特征,并在超图空间中提取高阶相关性。
- 利用三个独立的隧道,将这些相关性增强的特征分别传递到骨干网络与颈部连接处、颈部内部层以及颈部与头部连接处。通过这种方式,YOLOv13 在整个流程中实现了细粒度信息流和表征协同。
- FullPAD 显著提高了梯度传播,并增强了检测性能。
基于DS模块的模型轻量化
- 基于深度可分离卷积(DSConv、DS-Bottleneck、DS-C3k、DS-C3k2)构建的模块替换大核卷积,在保留感受野的同时大幅减少参数和计算量。
- 实现更快的推理速度而不牺牲精度。
尽管 YOLOv13 在研究和性能上表现出色,但其在实际部署中仍面临一些挑战,例如代码稳定性、社区支持不足以及与 Ultralytics 官方版本的集成疑问。此外,YOLOv5 和 YOLOv8 由于其稳定性和成熟的工具链,仍然是工业落地的首选版本。
YOLO26:魔改终结者
YOLO26型号仍在构建中,尚未发布。此处呈现的性能数据仅为预览。 最终下载和发布将在不久之后进行,请随时依据YOLO Vision 2025 进行更新。
UltralyticsYOLO26 是YOLO 系列实时物体检测器的最新产品,专为边缘和低功耗设备而设计。它采用精简设计,消除了不必要的复杂性,同时集成了有针对性的创新技术,以提供更快、更轻和更方便的部署。

YOLO26 的架构遵循三个核心原则:
简单:一个就是YOLO26 原生的端到端模型,无需非最大抑制(NMS)即可直接生成预测结果。由于省去了这一后处理步骤,推理变得更快、更轻便,也更容易部署到现实世界的系统中。这一突破性方法由清华大学的王敖在YOLOv10中首创,并在 YOLO26 中得到进一步发展。
部署效率:端到端设计省去了管道的整个阶段,大大简化了集成、减少了延迟,并使不同环境下的部署更加稳健。
训练创新:YOLO26 引入了MuSGD 优化器,它是SGD和Muon的混合体,灵感来自 Moonshot AI 在 LLM 训练中取得的Kimi K2突破。该优化器具有更高的稳定性和更快的收敛速度,将语言模型中的优化技术应用到了计算机视觉领域。
这些创新结合在一起,使模型系列在小型物体上实现了更高的精度,提供了无缝部署,在 CPU 上的运行速度提高43%,从而使 YOLO26 成为迄今为止在资源有限的环境中最实用、最易部署的YOLO 模型之一。
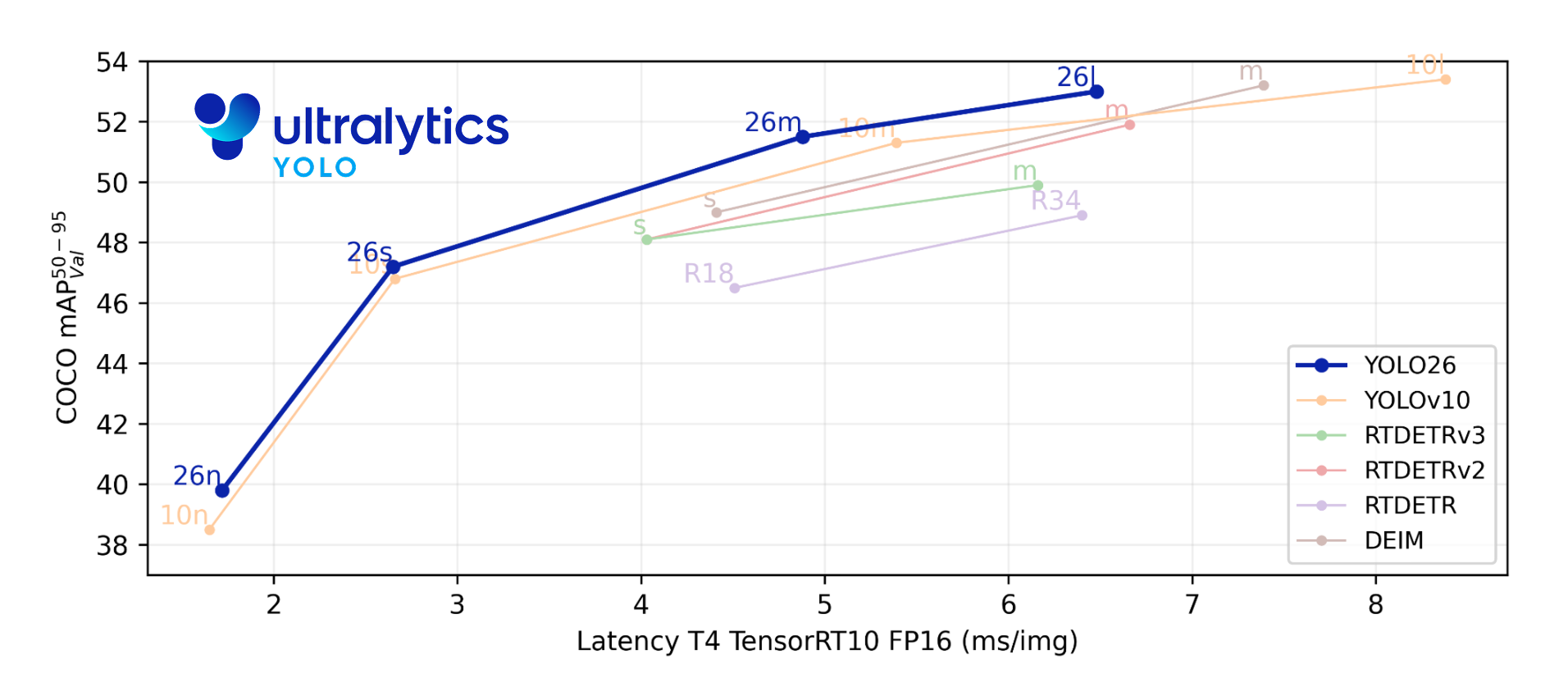
主要功能
- DFL 移除分布焦距损耗 (DFL) 模块哪怕高效,但往往使导出复杂化,并限制了硬件兼容性。YOLO26 完全取消了 DFL,简化了推理,扩大了对边缘和低功耗设备的支持。
- 端到端无 NMS 推理与依赖 NMS 作为单独后处理步骤的传统检测器不同,YOLO26本身就是端到端的。预测结果直接生成,减少了延迟,使集成到生产框架的速度更快、更轻便、更可靠。
- ProgLoss + STAL改进的损失函数提高了检测精度,在小目标识别物联网、机器人、航空图像和其他边缘应用的关键要求。就是方面有显著改进,这
- MuSGD 优化器一种结合了SGD和Muon的新型混合优化器。受到 Moonshot AI 的Kimi K2的启发,MuSGD 将 LLM 训练中的先进优化技巧引入计算机视觉,使训练更加稳定,收敛速度更快。
- CPU 推理速度提高 43YOLO26 专门针对边缘计算进行了优化,大大加快了CPU 推理速度,确保在没有 GPU 的设备上实现实时性能。
支持的任务和模式
YOLO26 被设计为多任务模型系列,将YOLO 的多功能性扩展到各种计算机视觉挑战中:
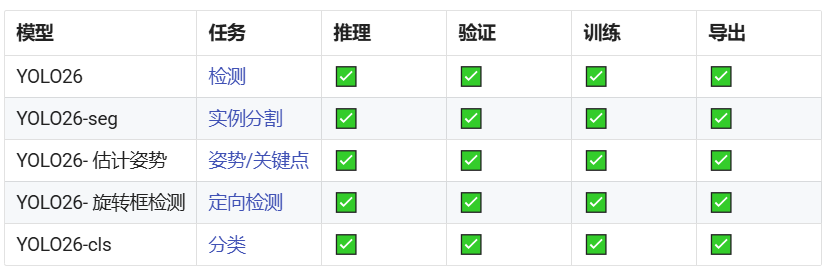
这一统一的框架确保 YOLO26 适用于实时检测、分割、分类、姿势估计 和面向对象检测,所有这些都支持训练、验证、推理和输出。
写在最后
YOLO系列的持续发展表明其在 CV 领域的强大生命力和广泛的应用前景。从 YOLOv1 把检测一夜拉进“端到端实时”时代,到 YOLOv2 借 Anchor 打通尺度、YOLOv3 用多尺度特征确立速度与精度的黄金交点,再到 YOLOv4 狂堆 Bag-of-Freebies、YOLOv5 把工程化做到极致,随后 v6-v8 在量化、部署、多任务上持续“做减法”,v9-v11 用 GELAN、ELAN、AuxLoss 把精度再推新高,v10 率先砍掉 NMS 迈向真正端到端,v12-v13 深耕小目标与稀疏激活,直至今日 YOLO26 以 MuSGD+ProgLoss 彻底拿掉冗余、CPU 也能跑实时——十三年十五代,YOLO 始终沿着“更快、更准、更轻、更易落地”的单一主线不断自我颠覆:每一次版本跳跃,都是“精简即速度”与“尺度即性能”的再平衡,也把实时目标检测的天花板一次次抬向新的时代。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号