




OmniParse 项目技术分析报告 - 教程
项目概述
OmniParse 是一个强大的数据摄取和解析平台,专门设计用于将各种非结构化数据转换为结构化、可操作的数据,并针对 GenAI(大语言模型)应用进行了优化。
技术栈分析
核心技术框架
- 编程语言: Python 3.10+
- Web框架: FastAPI (用于API服务)
- 依赖管理: Poetry
- 前端界面: Gradio (交互式UI)
- 部署: Docker, Skypilot
- GPU支持: CUDA (需要8-10GB VRAM)
主要AI模型和库
- 文档处理:
- Surya OCR系列模型 (OCR、检测、布局、排序)
- Marker (PDF解析核心)
- Texify (数学公式转换)
- 图像处理: Florence-2 base模型
- 音频处理: Whisper Small模型
- 网页爬取: Selenium + Crawl4AI
支持的文件格式
- 文档: .doc, .docx, .pdf, .ppt, .pptx
- 图像: .png, .jpg, .jpeg, .tiff, .bmp, .heic
- 视频: .mp4, .mkv, .avi, .mov
- 音频: .mp3, .wav, .aac
- 网页: 动态网页内容
项目优势
1. 多格式支持
- 支持20+种文件类型
- 统一的API接口处理不同数据格式
- 从文档到多媒体的全面覆盖
2. 本地化部署
- 完全本地运行,无需外部API
- 数据隐私和安全性高
- 适合企业级应用
3. GenAI优化
- 输出结构化的Markdown格式
- 专门为RAG和微调应用优化
- 与主流AI框架兼容
4. 部署友好
- Docker容器化部署
- GPU和CPU模式支持
- Colab友好的环境配置
5. 用户友好
- Gradio交互式界面
- 丰富的API端点
- 详细的文档说明
项目劣势
1. 硬件要求高
- 需要8-10GB VRAM的GPU
- 仅支持Linux系统
- 对硬件资源要求较高
2. 模型性能限制
- 使用最小变体模型以适应GPU内存
- 可能不是最佳性能表现
- 对非英语语言支持有限
3. 解析准确性
- PDF表格格式化可能不够完美
- 数学公式转换不是100%准确
- 空白和缩进处理存在问题
4. 商业使用限制
- 基于GPL-3.0许可证
- 商业使用有收入限制(500万美元)
- 需要考虑许可证合规性
使用场景
1. 知识管理系统
- 企业文档数字化
- 知识库构建
- 历史资料整理
2. RAG系统构建
- 文档向量化预处理
- 多模态检索增强
- 智能问答系统
3. 内容分析平台
- 媒体内容转录
- 图像内容识别
- 网页内容抓取
4. 教育科研
- 学术论文处理
- 研究资料整理
- 多媒体内容分析
5. 合规和审计
- 文档标准化处理
- 数据格式统一
- 内容结构化存储
代码结构分析
核心模块架构
omniparse/
├── server.py # 主服务器入口
├── download.py # 模型下载脚本
├── core/ # 核心处理模块
│ ├── parsers/ # 各类解析器
│ │ ├── document_parser.py
│ │ ├── image_parser.py
│ │ ├── audio_parser.py
│ │ ├── video_parser.py
│ │ └── web_parser.py
│ ├── models/ # AI模型管理
│ └── utils/ # 工具函数
├── api/ # API端点定义
├── ui/ # Gradio界面
└── docker/ # 容器配置主要执行步骤
- 服务初始化
- 加载配置参数
- 初始化AI模型
- 启动Web服务器
- 文件接收与验证
- 文件类型检测
- 格式验证
- 安全检查
- 智能路由
- 根据文件类型选择解析器
- 模型加载和配置
- 处理参数设置
- 内容解析
- OCR文本识别
- 图像内容分析
- 音频视频转录
- 结构化输出
- Markdown格式转换
- 元数据提取
- 质量验证
- 结果返回
- 格式化响应
- 错误处理
- 性能监控
时序图
文档处理流程
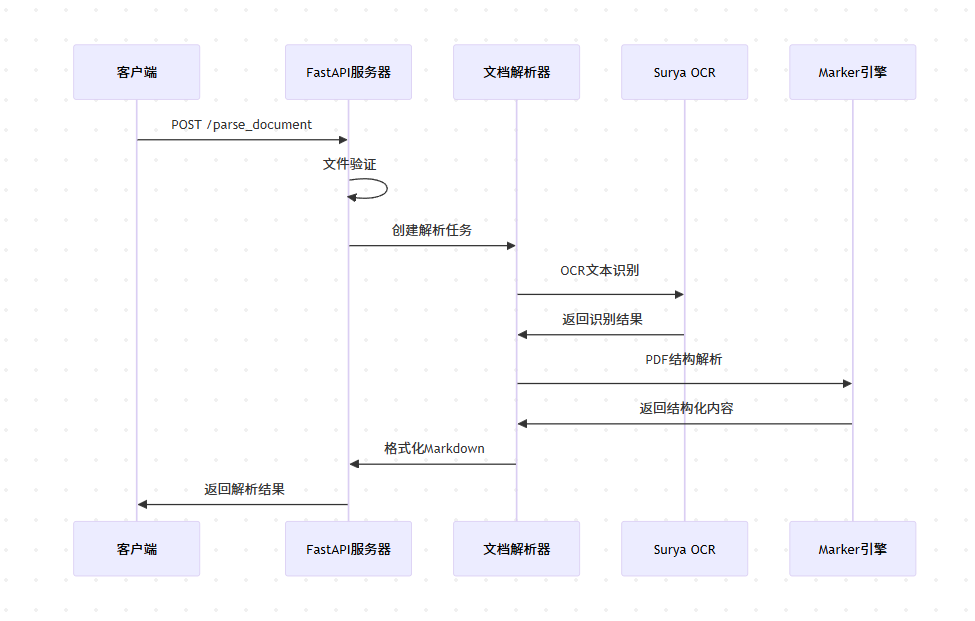
Marker引擎Surya OCR文档解析器FastAPI服务器客户端Marker引擎Surya OCR文档解析器FastAPI服务器客户端POST /parse_document文件验证创建解析任务OCR文本识别返回识别结果PDF结构解析返回结构化内容格式化Markdown返回解析结果
图像处理流程
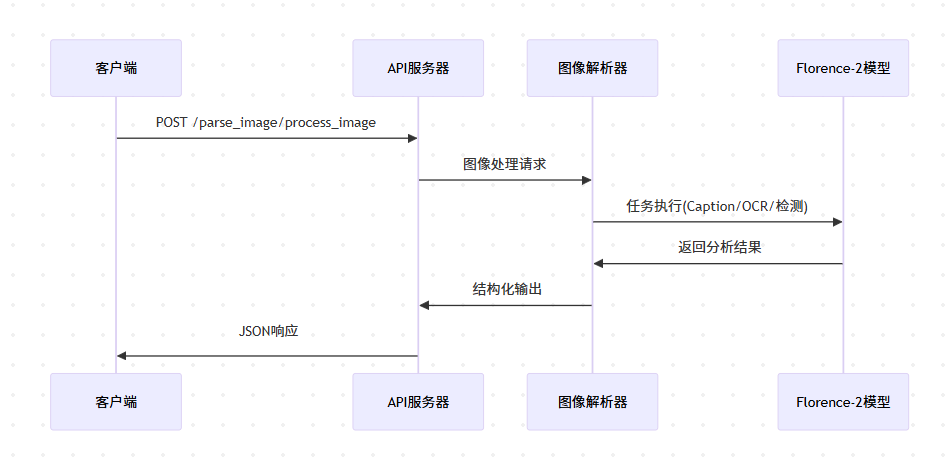
Florence-2模型图像解析器API服务器客户端Florence-2模型图像解析器API服务器客户端POST /parse_image/process_image图像处理请求任务执行(Caption/OCR/检测)返回分析结果结构化输出JSON响应
开发示例
1. 基础API调用示例
Python客户端
python
import requests
import json
class OmniParseClient:
def __init__(self, base_url="http://localhost:8000"):
self.base_url = base_url
def parse_document(self, file_path):
"""解析文档文件"""
with open(file_path, 'rb') as file:
files = {'file': file}
response = requests.post(
f"{self.base_url}/parse_document",
files=files
)
return response.json()
def parse_image(self, image_path, task="Caption", prompt=""):
"""解析图像内容"""
with open(image_path, 'rb') as image:
files = {'image': image}
data = {
'task': task,
'prompt': prompt
}
response = requests.post(
f"{self.base_url}/parse_media/process_image",
files=files,
data=data
)
return response.json()
def parse_website(self, url):
"""解析网页内容"""
data = {'url': url}
response = requests.post(
f"{self.base_url}/parse_website",
json=data
)
return response.json()
# 使用示例
client = OmniParseClient()
# 解析PDF文档
result = client.parse_document("/path/to/document.pdf")
print("文档内容:", result['content'])
# 解析图像
image_result = client.parse_image(
"/path/to/image.jpg",
task="Detailed Caption"
)
print("图像描述:", image_result['result'])
# 解析网页
web_result = client.parse_website("https://example.com")
print("网页内容:", web_result['content'])2. 批量处理示例
python
import asyncio
import aiohttp
import os
from pathlib import Path
class BatchProcessor:
def __init__(self, base_url="http://localhost:8000"):
self.base_url = base_url
async def process_file(self, session, file_path):
"""异步处理单个文件"""
file_ext = Path(file_path).suffix.lower()
with open(file_path, 'rb') as file:
if file_ext in ['.pdf', '.docx', '.pptx']:
endpoint = "/parse_document"
data = aiohttp.FormData()
data.add_field('file', file)
elif file_ext in ['.jpg', '.jpeg', '.png']:
endpoint = "/parse_media/process_image"
data = aiohttp.FormData()
data.add_field('image', file)
data.add_field('task', 'OCR with Region')
else:
return {"error": f"Unsupported file type: {file_ext}"}
async with session.post(
f"{self.base_url}{endpoint}",
data=data
) as response:
return await response.json()
async def batch_process(self, file_paths):
"""批量处理文件"""
async with aiohttp.ClientSession() as session:
tasks = [
self.process_file(session, file_path)
for file_path in file_paths
]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
# 使用示例
async def main():
processor = BatchProcessor()
# 获取要处理的文件列表
file_paths = [
"/path/to/document1.pdf",
"/path/to/document2.docx",
"/path/to/image1.jpg",
"/path/to/image2.png"
]
results = await processor.batch_process(file_paths)
for i, result in enumerate(results):
print(f"文件 {file_paths[i]} 处理结果:")
if isinstance(result, dict) and 'content' in result:
print(result['content'][:200] + "...")
print("-" * 50)
# 运行批量处理
if __name__ == "__main__":
asyncio.run(main())3. RAG系统集成示例
python
from typing import List, Dict
import chromadb
from sentence_transformers import SentenceTransformer
class OmniParseRAG:
def __init__(self, omniparse_client, collection_name="documents"):
self.client = omniparse_client
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.chroma_client = chromadb.Client()
self.collection = self.chroma_client.create_collection(
name=collection_name
)
def ingest_document(self, file_path: str, metadata: Dict = None):
"""摄取文档到RAG系统"""
# 使用OmniParse解析文档
parsed_result = self.client.parse_document(file_path)
content = parsed_result.get('content', '')
# 文本分块
chunks = self._chunk_text(content)
# 生成嵌入向量并存储
embeddings = self.encoder.encode(chunks).tolist()
ids = [f"{file_path}_{i}" for i in range(len(chunks))]
metadatas = [
{**(metadata or {}), "chunk_id": i, "file_path": file_path}
for i in range(len(chunks))
]
self.collection.add(
embeddings=embeddings,
documents=chunks,
metadatas=metadatas,
ids=ids
)
return len(chunks)
def _chunk_text(self, text: str, chunk_size: int = 1000) -> List[str]:
"""简单的文本分块"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
def search(self, query: str, top_k: int = 5):
"""检索相关文档片段"""
query_embedding = self.encoder.encode([query]).tolist()
results = self.collection.query(
query_embeddings=query_embedding,
n_results=top_k
)
return {
'documents': results['documents'][0],
'metadatas': results['metadatas'][0],
'distances': results['distances'][0]
}
# 使用示例
rag_system = OmniParseRAG(client)
# 摄取文档
rag_system.ingest_document(
"/path/to/report.pdf",
metadata={"type": "report", "year": 2024}
)
# 搜索相关内容
search_results = rag_system.search("什么是人工智能?")
for doc, meta in zip(search_results['documents'], search_results['metadatas']):
print(f"来源: {meta['file_path']}")
print(f"内容: {doc[:200]}...")
print("-" * 50)4. 自定义处理器示例
python
from abc import ABC, abstractmethod
class CustomProcessor(ABC):
"""自定义处理器基类"""
@abstractmethod
def process(self, content: str, metadata: dict) -> dict:
pass
class DocumentSummarizer(CustomProcessor):
"""文档摘要处理器"""
def __init__(self, omniparse_client):
self.client = omniparse_client
def process(self, file_path: str, metadata: dict = None) -> dict:
# 解析文档
result = self.client.parse_document(file_path)
content = result.get('content', '')
# 简单的摘要生成(实际应用中可以使用更复杂的NLP模型)
summary = self._generate_summary(content)
return {
'original_content': content,
'summary': summary,
'word_count': len(content.split()),
'metadata': metadata or {}
}
def _generate_summary(self, text: str, max_sentences: int = 3) -> str:
"""简单的提取式摘要"""
sentences = text.split('. ')
if len(sentences) dict:
file_ext = Path(file_path).suffix.lower()
if file_ext in ['.pdf', '.docx']:
return self._process_document(file_path, metadata)
elif file_ext in ['.jpg', '.jpeg', '.png']:
return self._process_image(file_path, metadata)
elif file_ext in ['.mp4', '.avi']:
return self._process_video(file_path, metadata)
else:
raise ValueError(f"Unsupported file type: {file_ext}")
def _process_document(self, file_path: str, metadata: dict) -> dict:
result = self.client.parse_document(file_path)
return {
'type': 'document',
'content': result.get('content', ''),
'metadata': metadata
}
def _process_image(self, file_path: str, metadata: dict) -> dict:
# 多种图像分析任务
tasks = ['Caption', 'Object Detection', 'OCR']
results = {}
for task in tasks:
result = self.client.parse_image(file_path, task=task)
results[task.lower().replace(' ', '_')] = result
return {
'type': 'image',
'analyses': results,
'metadata': metadata
}
def _process_video(self, file_path: str, metadata: dict) -> dict:
result = self.client.parse_video(file_path)
return {
'type': 'video',
'transcript': result.get('transcript', ''),
'metadata': metadata
}
# 使用示例
summarizer = DocumentSummarizer(client)
analyzer = MultimodalAnalyzer(client)
# 文档摘要
summary_result = summarizer.process("/path/to/document.pdf")
print("文档摘要:", summary_result['summary'])
# 多模态分析
analysis_result = analyzer.process("/path/to/image.jpg")
print("图像分析:", analysis_result['analyses']['caption'])总结
OmniParse 是一个功能强大的多模态数据解析平台,特别适合需要处理各种非结构化数据并将其转换为GenAI友好格式的应用场景。其本地化部署、多格式支持和GenAI优化的特性使其成为企业级AI应用的理想选择。
然而,需要注意其硬件要求较高,对非英语内容的处理能力有限,以及商业使用的许可证限制。在实际部署时,建议根据具体需求和资源情况进行评估


 浙公网安备 33010602011771号
浙公网安备 33010602011771号