



实用指南:(论文速读)TDAD:基于两阶段扩散模型的工业异常检测
题目:TDAD: Self-supervised industrial anomaly detection with a two-stage diffusion model(基于两阶段扩散模型的自监督工业异常检测)
期刊:Computers in Industry
摘要:视觉异常检测由于其显著的有效性和高效性,已成为一种非常适用于实际工业制造的解决方案。然而,它也带来了一些挑战和不确定性。为了解决异常类型的复杂性和与素材注释相关的高成本疑问,本文引入了一种基于两阶段扩散模型的自监督学习框架TDAD。TDAD包括三个关键部分:异常合成、图像重建和缺陷分割。它是端到端的训练,目的是提高异常的像素级分割精度,降低误检率。通过从正常样本中合成异常,设计基于扩散模型的重构网络,并结合多尺度语义特征融合模块进行缺陷分割,TDAD在具有挑战性和广泛使用的数据集(如MVTec和VisA基准)上实现了图像级检测和异常定位的最先进性能。

引言
制造业质量控制的核心挑战。传统技巧往往受限于异常样本稀缺和标注成本高昂的问题。就是工业视觉检查中的异常检测一直
核心创新与工艺亮点
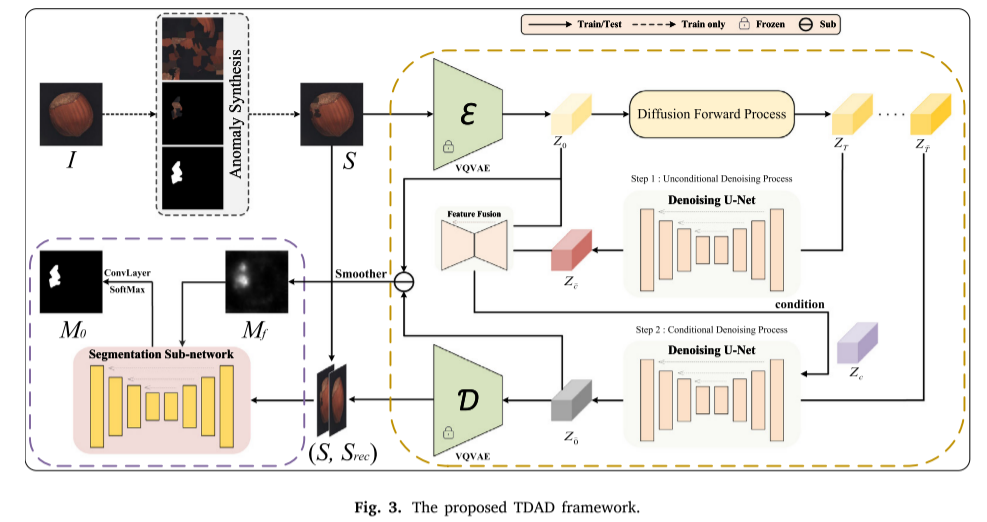
1. 整体架构设计
TDAD采用端到端的训练策略,包含三个核心模块:
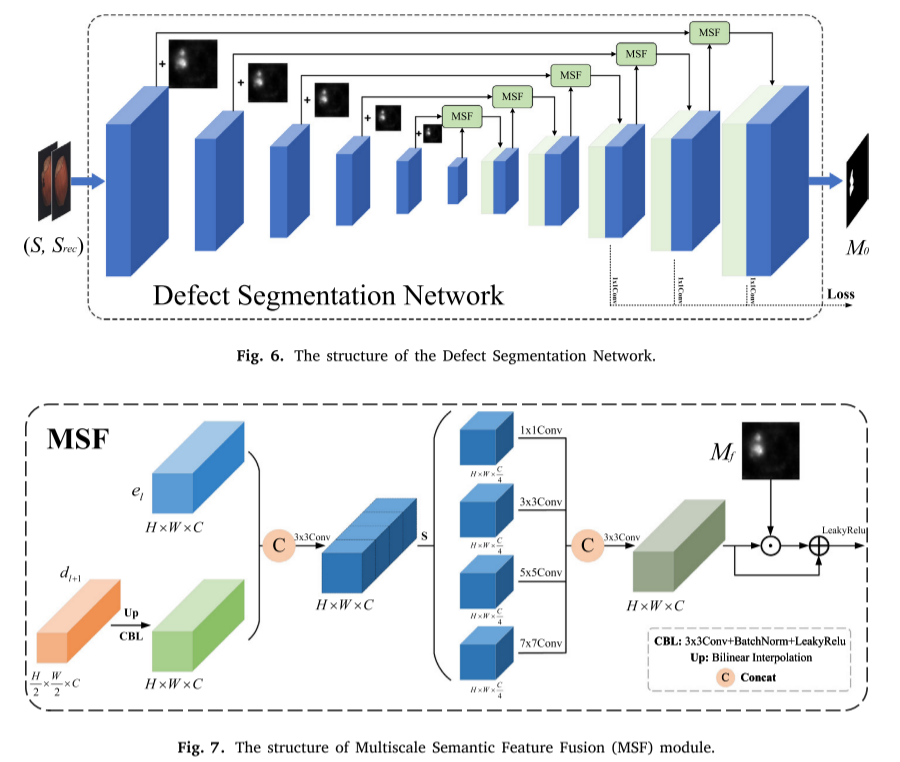
异常合成模块:通过多尺度缺陷掩码和纹理变换从正常样本生成合成异常样本两阶段扩散重建模块:创新性地设计了两阶段重建过程,奏效抑制异常区域的高保真重建缺陷分割模块:集成多尺度语义特征融合的U-Net网络,实现精确的像素级异常定位。
2. 两阶段扩散重建的核心洞察
这是论文最具创新性的贡献。传统的扩散模型在异常检测中存在两个问题:
- 过度泛化:可能重建出异常区域,导致误检
- 语义信息丢失:重建过程中关键语义特征可能丢失
TDAD的两阶段设计巧妙地解决了这些问题:
第一阶段:低噪声、高采样步数的无条件扩散
- 将异常区域视为噪声进行处理
- 保留核心语义特征的同时抑制异常重建
第二阶段:高噪声、高采样步数的条件引导扩散
- 使用特征融合网络整合原始和重建特征
- 依据条件引导实现精细重建
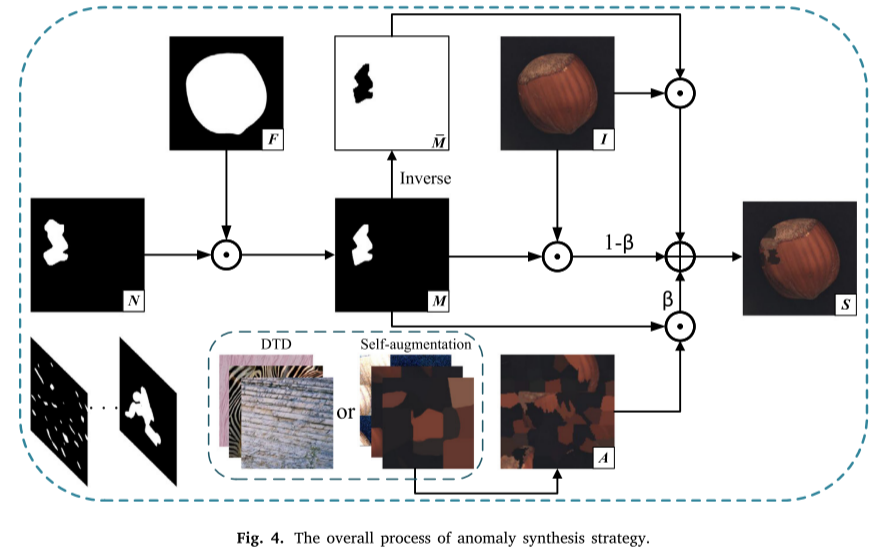
3. 多尺度异常合成策略
为了提高合成异常的多样性和真实性,TDAD引入了增强的异常合成策略:
- 多尺度掩码生成:结合Perlin噪声和不规则大面积区域
- 多样化纹理源:整合DTD纹理数据集和目标图像自身特征
- 自适应前景提取:应用Otsu等自适应阈值算法自动生成前景掩码
PyTorch实现框架
可能的TDAD的核心PyTorch实现:就是以下
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import numpy as np
import cv2
from typing import Optional, Tuple, List
import math
class NoiseScheduler:
"""扩散模型噪声调度器"""
def __init__(self, num_timesteps: int = 1000, beta_start: float = 0.0001, beta_end: float = 0.02):
self.num_timesteps = num_timesteps
# 线性噪声调度
self.betas = torch.linspace(beta_start, beta_end, num_timesteps)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.alphas_cumprod_prev = F.pad(self.alphas_cumprod[:-1], (1, 0), value=1.0)
# 计算采样所需的系数
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - self.alphas_cumprod)
def add_noise(self, original_samples, noise, timesteps):
"""向原始样本添加噪声"""
sqrt_alpha_prod = self.sqrt_alphas_cumprod[timesteps].flatten()
sqrt_one_minus_alpha_prod = self.sqrt_one_minus_alphas_cumprod[timesteps].flatten()
while len(sqrt_alpha_prod.shape) 0.7).astype(np.float32)
# 应用形态学操作使形状更自然
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
return torch.from_numpy(mask)
def generate_multiscale_mask(self, shape: Tuple[int, int]):
"""生成多尺度异常掩码"""
h, w = shape
masks = []
# 生成不同尺度的掩码
for scale in [8, 16, 32]:
small_h, small_w = h // scale, w // scale
small_mask = self.generate_perlin_mask((small_h, small_w))
large_mask = F.interpolate(
small_mask.unsqueeze(0).unsqueeze(0),
size=(h, w),
mode='bilinear',
align_corners=False
).squeeze()
masks.append(large_mask)
# 组合不同尺度的掩码
final_mask = torch.stack(masks).max(dim=0)[0]
return (final_mask > 0.5).float()
def generate_foreground_mask(self, image: torch.Tensor):
"""生成前景掩码"""
# 转换为numpy进行处理
img_np = image.cpu().numpy().transpose(1, 2, 0)
if img_np.max() 0:
noise_loss = F.mse_loss(
outputs['z_recon'][is_normal == 0],
outputs['z0'][is_normal == 0]
)
losses['diffusion_loss'] = noise_loss
# 特征融合损失
if 'recon_images' in outputs:
feature_loss = self.smooth_l1_loss(outputs['recon_images'], outputs.get('synthetic_images', outputs['recon_images']))
losses['feature_loss'] = feature_loss
# 分割损失
if 'seg_outputs' in outputs and 'gt_masks' in outputs:
seg_loss = 0
weights = [1.0, 0.5, 0.25] # 多尺度权重
for i, (pred, weight) in enumerate(zip(outputs['seg_outputs'], weights)):
target = F.interpolate(outputs['gt_masks'].unsqueeze(1), size=pred.shape[-2:], mode='bilinear', align_corners=False)
smooth_l1 = self.smooth_l1_loss(pred, target)
focal = self.focal_loss(pred, target)
seg_loss += weight * (smooth_l1 + self.lambda_focal * focal)
losses['segmentation_loss'] = seg_loss
# 总损失
total_loss = sum(losses.values())
losses['total_loss'] = total_loss
return losses
# 训练函数示例
def train_epoch(model: TDAD, dataloader: DataLoader, optimizer: torch.optim.Optimizer,
criterion: TDADLoss, device: torch.device):
"""训练一个epoch"""
model.train()
total_loss = 0
for batch_idx, (normal_images, texture_images) in enumerate(dataloader):
normal_images = normal_images.to(device)
texture_images = texture_images.to(device)
# 随机决定是否生成异常样本
is_normal = torch.bernoulli(torch.ones(normal_images.shape[0]) * 0.5).to(device)
optimizer.zero_grad()
# 前向传播
outputs = model(normal_images, texture_images, is_training=True)
# 计算损失
losses = criterion(outputs, is_normal)
loss = losses['total_loss']
# 反向传播
loss.backward()
optimizer.step()
total_loss += loss.item()
if batch_idx % 10 == 0:
print(f'Batch {batch_idx}, Loss: {loss.item():.4f}')
return total_loss / len(dataloader)
# 使用示例
if __name__ == "__main__":
# 模型初始化
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TDAD().to(device)
criterion = TDADLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-4)
print("TDAD model initialized successfully!")
print(f"Model parameters: {sum(p.numel() for p in model.parameters() if p.requires_grad):,}")
# 测试前向传播
with torch.no_grad():
test_normal = torch.randn(2, 3, 256, 256).to(device)
test_texture = torch.randn(2, 3, 256, 256).to(device)
outputs = model(test_normal, test_texture, is_training=True)
print("Forward pass successful!")
print(f"Synthetic images shape: {outputs['synthetic_images'].shape}")
print(f"Feature score shape: {outputs['feature_score'].shape}")
print(f"Segmentation outputs: {len(outputs['seg_outputs'])} scales")定量结果
MVTec内容集上的表现:
- 图像级AUROC: 99.4%(与最新的RD++方法持平)
- 像素级AUROC: 98.6%(比第二名CFlow高0.2%)
- PRO指标: 95.5%(比第二名RD++高0.9%)
VisA数据集上的表现:
- 图像级AUROC: 98.6%(比第二名高2.6%)
- 像素级AUROC: 99.1%
- PRO指标: 94.8%
关键优势
- 重建质量显著提升:两阶段设计有效抑制了异常区域的高保真重建
- 定位精度优异:多尺度语义特征融合模块供应了精确的边界定位
- 计算效率平衡:纵然比非扩散方法慢约0.1秒,但重建质量的提升值得这个代价
- 泛化能力强:在不同类型的工业缺陷上都表现出色
技术洞察与未来方向
核心技术洞察
分阶段处理的智慧:第一阶段关注语义保持,第二阶段关注细节重建,这种分工明确的设计非常有效
特征空间操作:在潜在空间进行扩散既降低了计算成本,又保持了语义完整性
多尺度设计理念:从异常合成到特征融合,多尺度处理贯穿整个框架
局限性与改进方向
- 计算效率:虽然运用了潜在扩散模型,但仍需要进一步优化速度
- 多类别扩展:当前主要针对单类别异常检测,多类别场景需要进一步研究
- 3D扩展潜力:在更复杂的工业场景中,3D异常检测有重要应用价值
实践建议
部署考虑
- 硬件要求:建议采用GPU加速,内存需求相对较高
- 数据准备:必须足够的正常样本和多样化的纹理素材
- 参数调优:两阶段的噪声水平和采样步数需根据具体应用场景调整
应用场景
TDAD特殊适合以下工业应用:
- 表面缺陷检测(钢材、纺织品等)
- 电路板异常检测
- 产品质量控制
- 设备故障诊断
总结
TDAD代表了工业异常检测领域的一个重要进展。依据巧妙的两阶段扩散设计,它克服了传统方法的核心痛点,在保持高精度的同时提供了实用的计算效率。这种自监督学习框架为工业4.0时代的智能制造提供了强有力的技术支撑。
论文的成功不仅在于技术创新,更在于对实际工业需求的深入理解。随着扩散模型技术的不断发展,我们有理由期待更多类似的创新应用出现,推动工业异常检测技术向更高的水平发展。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号