

Redis!——亿级流量专业的系统架构设计系列就是应用缓存不止
在当今互联网架构中,缓存技术犹如系统的"加速器",通过将热点数据存储在高速介质中,显著降低数据库负载并提升响应速度。无论是CPU的L1/L2/L3缓存,还是分布式系统中的Redis集群,缓存无处不在。本文将深入探讨应用级缓存的设计原理、实现方案及最佳实践,为构建高并发系统提供实用指南。
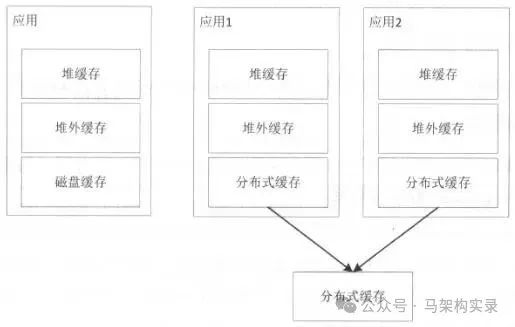
缓存架构层级示意图
图:典型的多级缓存架构示意图,数据从CPU缓存到磁盘形成完整的存储层次
一、缓存基础:从命中率到回收策略
1.1 缓存的本质与价值
缓存的核心思想是**"让数据更接近使用者"**,通过空间换时间的策略,将频繁访问的数据存储在高速存储介质中。一个设计良好的缓存系统应满足:
- • 高命中率:缓存命中率=缓存命中次数/(缓存命中次数+回源次数)
- • 低延迟:数据访问响应时间短
- • 高一致性:缓存与数据源保持最终一致
- • 可扩展性:支持容量动态扩展
1.2 关键指标:缓存命中率
命中率是衡量缓存有效性的核心指标。以下场景适合缓存:
- • 频繁访问的热点数据
- • 计算昂贵的复杂结果
- • I/O密集型操作的结果集
- • 符合局部性原理的数据
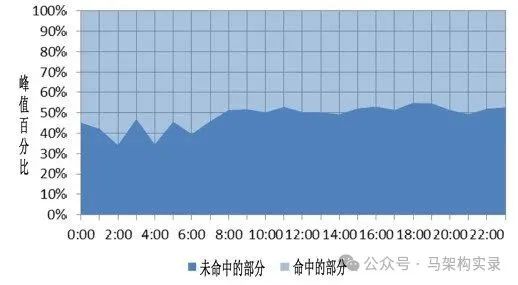
缓存命中率曲线图
图:缓存命中率随时间变化曲线,展示了不同时段缓存命中与未命中的比例关系
1.3 缓存回收策略全解析
当缓存空间满时,需要根据特定策略淘汰旧数据,常见策略包括:
策略类型 | 核心原理 | 适用场景 |
FIFO | 先进先出,最早进入的先淘汰 | 数据访问顺序固定的场景 |
LRU | 最近最少使用,淘汰最久未访问数据 | 大多数通用场景 |
LFU | 最不常用,淘汰访问频率最低数据 | 访问频率分布不均的场景 |
TTL | 存活期,固定时间后淘汰 | 时效性强的数据 |
TTI | 空闲期,多久未访问后淘汰 | 间歇性访问的数据 |
在Java缓存实现中,LRU是最常用的策略,Guava Cache、Ehcache等主流框架均默认支持。
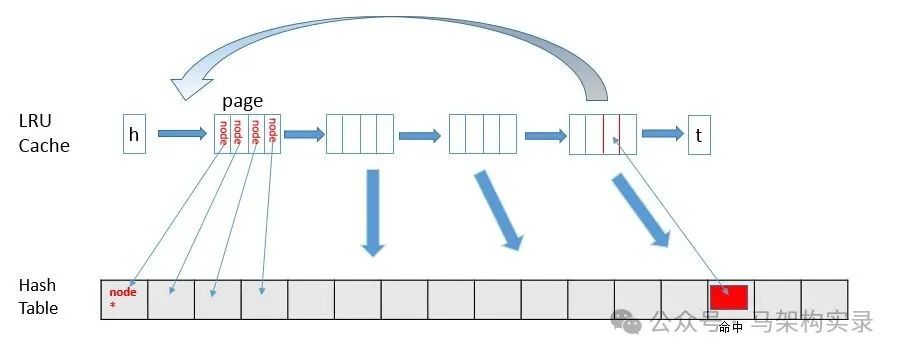
LRU算法工作原理示意图
图:LRU算法工作原理示意图,当新数据访问时,最近使用的元素被移到头部,满员时尾部元素被淘汰
二、缓存类型:从本地到分布式
2.1 缓存金字塔模型
现代系统通常采用多级缓存架构,形成"金字塔"式存储层次:
- 1. 堆缓存:存储在JVM堆内存,速度最快但容量有限
- 2. 堆外缓存:不受GC影响,支持更大容量
- 3. 磁盘缓存:持久化存储,重启不丢失
- 4. 分布式缓存:跨节点共享,支持集群扩展
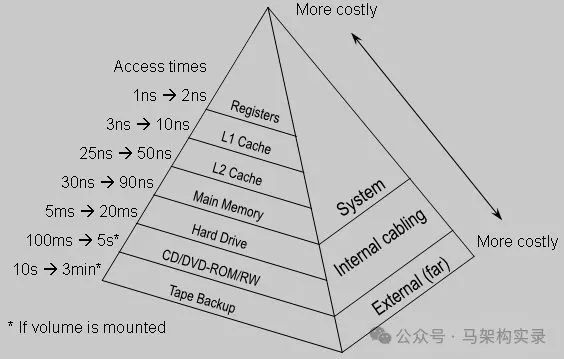
缓存金字塔模型架构图
图:缓存金字塔模型架构图,展示了从堆缓存到分布式缓存的层级结构及访问速度对比
2.2 主流缓存框架对比
特性 | Guava Cache | Ehcache 3.x | MapDB | Redis |
堆缓存 | ✅ | ✅ | ✅ | ❌ |
堆外缓存 | ❌ | ✅ | ✅ | ❌ |
磁盘缓存 | ❌ | ✅ | ✅ | ✅ |
分布式 | ❌ | ✅ | ❌ | ✅ |
回收策略 | LRU | LRU | LRU/LFU | 多种 |
易用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
2.3 堆缓存实战:Guava Cache实现
Guava Cache是Java堆缓存的首选方案,小巧高效,以下是典型配置:
Cache myCache = CacheBuilder.newBuilder()
.concurrencyLevel(4) // 并发级别,控制segment数量
.expireAfterWrite(10, TimeUnit.SECONDS) // TTL策略
.maximumSize(10000) // 最大容量,超出按LRU淘汰
.recordStats() // 开启统计,记录命中率
.softValues() // 软引用,内存不足时回收
.build();核心配置参数说明:
- •
concurrencyLevel:并发写支持,建议设为CPU核心数 - •
expireAfterWrite:写入后过期,适合变化不频繁数据 - •
expireAfterAccess:访问后过期,适合热点波动数据 - •
weakKeys/weakValues:弱引用,允许GC回收
2.4 分布式缓存:Ehcache + Terracotta
对于分布式场景,可采用Ehcache+Terracotta Server组合:
PersistentCacheManager cacheManager = CacheManagerBuilder
.newCacheManagerBuilder()
.with(ClusteringServiceConfigurationBuilder
.cluster(URI.create("terracotta://192.168.147.50:9510"))
.autoCreate())
.build(true);
Cache myCache = cacheManager.createCache("myCache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(
String.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.with(ClusteredResourcePoolBuilder.clusteredDedicated("cache", 32, MemoryUnit.MB))
)
);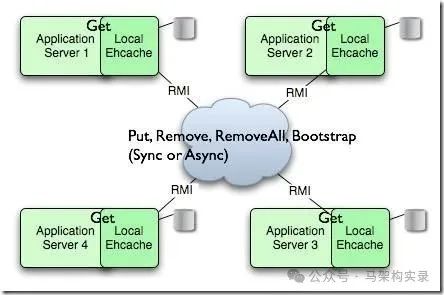
分布式缓存集群架构图
图:分布式缓存集群架构图,展示了多应用服务器通过RMI协议与中心缓存节点交互的结构
三、缓存使用模式:从理论到实践
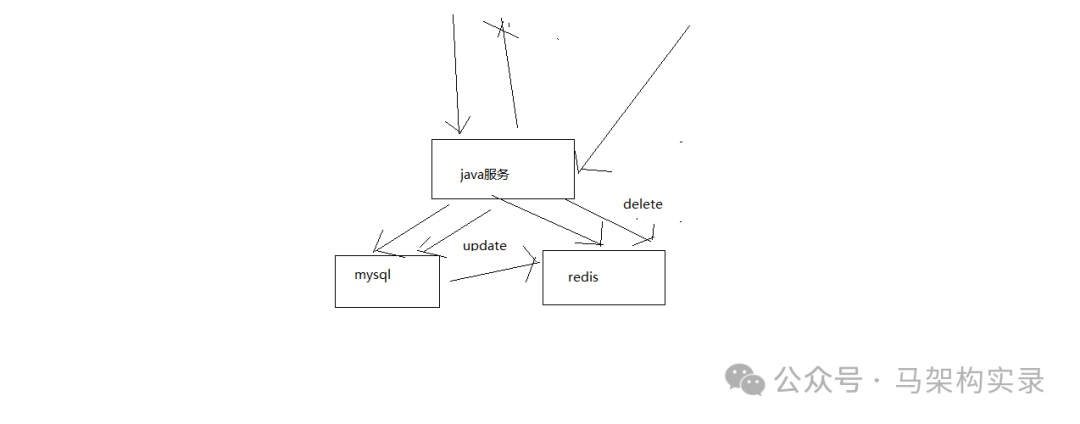
3.1 Cache-Aside模式(旁路缓存)
最常用的缓存模式,业务代码直接操作缓存和数据源:
// 读操作
String value = cache.getIfPresent(key);
if (value == null) {
value = loadFromDB(key); // 回源数据库
cache.put(key, value); // 更新缓存
}
// 写操作
updateDB(key, value); // 先更新数据库
cache.invalidate(key); // 再失效缓存优点:实现简单,灵活性高
缺点:代码侵入性强,一致性需业务保证
Cache-Aside模式流程图
图:Cache-Aside模式流程图,展示了读操作的缓存命中与回源流程及写操作的更新策略
3.2 Read-Through/Write-Through模式
将数据源访问逻辑封装在缓存层,业务代码只与缓存交互:
// Read-Through模式实现
LoadingCache userCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build(newCacheLoader() {
@Override
public User load(Integer userId)throws Exception {
return userDAO.findById(userId); // 自动回源
}
});
// 业务代码直接调用缓存
Useruser= userCache.get(userId);核心优势:
- • 消除重复代码,业务逻辑更清晰
- • 内置防缓存击穿机制
- • 统一管理缓存策略
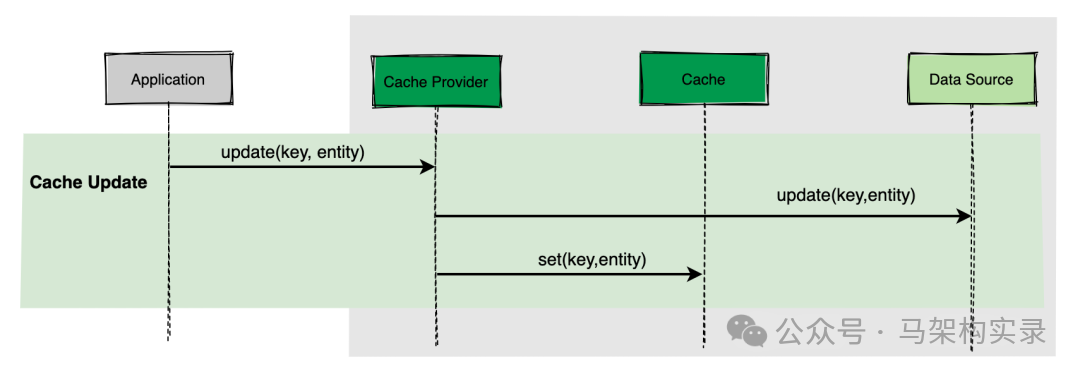
Write-Through缓存模式示意图
图:Write-Through缓存模式示意图,缓存层作为中间件自动同步更新数据源
3.3 Write-Behind模式(异步回写)
写缓存时异步更新数据源,适合写频繁场景:
CacheConfiguration config = CacheConfigurationBuilder
.newCacheConfigurationBuilder(String.class, String.class,
ResourcePoolsBuilder.heap(100))
.withLoaderWriter(newDefaultCacheLoaderWriter() {
@Override
publicvoidwrite(String key, String value) {
// 异步写入数据库
asyncExecutor.submit(() -> db.update(key, value));
}
})
.add(WriteBehindConfigurationBuilder
.newBatchedWriteBehindConfiguration(3, TimeUnit.SECONDS, 100)
.queueSize(1000)
.concurrencyLevel(2)
.build())
.build();适用场景:
- • 写操作远多于读操作
- • 允许短暂的数据不一致
- • 需要合并多次写操作
四、高级实战:缓存架构最佳实践
4.1 多级缓存设计
大型系统通常采用多级缓存架构:
// 多级缓存实现示例
public Object getValue(String key) {
// 1. 先查本地堆缓存
Objectvalue= localCache.get(key);
if (value != null) return value;
// 2. 再查分布式缓存
value = redisCache.get(key);
if (value != null) {
localCache.put(key, value); // 回填本地缓存
return value;
}
// 3. 最后查数据库
value = db.load(key);
redisCache.put(key, value); // 更新分布式缓存
localCache.put(key, value); // 更新本地缓存
return value;
}4.2 缓存穿透防护:NULL缓存
防止查询不存在数据导致缓存失效:
// NULL缓存实现
Stringvalue= loadFromDB(key);
if (value == null) {
// 存储NULL对象而非null值
cache.put(key, SPECIAL_NULL_OBJECT);
}
// 读取时处理
Objectresult= cache.get(key);
if (result == SPECIAL_NULL_OBJECT) {
returnnull; // 返回null但不回源
}4.3 缓存一致性保障策略
缓存与数据库一致性方案:
- 1. Cache-Aside + TTL:最简单方案,依赖TTL最终一致
- 2. 更新数据库后立即更新缓存:适用于读多写少场景
- 3. Canal订阅binlog更新缓存:高一致性,适合核心业务
- 4. 分布式锁+双删策略:解决并发更新冲突
// 双删策略示例
public void updateData(String key, Object value) {
// 1. 删除缓存
cache.delete(key);
// 2. 更新数据库
db.update(key, value);
// 3. 延迟再次删除(解决更新期间的脏读)
scheduler.schedule(() -> cache.delete(key), 100, TimeUnit.MILLISECONDS);
}4.4 缓存性能监控
关键监控指标:
- • 命中率:目标>90%
- • 平均响应时间:目标<1ms
- • 缓存穿透率:目标<0.1%
- • 缓存更新成功率:目标>99.9%
五、常见问题与解决方案
5.1 缓存三大问题及对策
问题类型 | 产生原因 | 解决方案 |
缓存穿透 | 查询不存在的数据,缓存失效 | NULL缓存、布隆过滤器 |
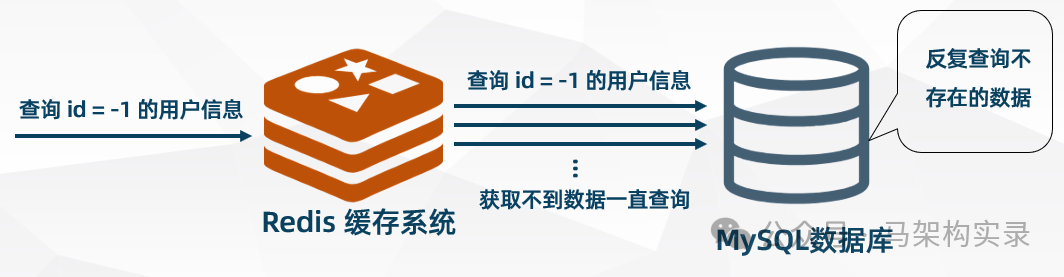
缓存穿透解决方案图示
图:缓存穿透防护方案,通过布隆过滤器拦截无效请求,NULL缓存避免空值穿透
| 缓存击穿 | 热点key失效,大量并发请求直达DB | 互斥锁、热点永不过期 |
| 缓存雪崩 | 大面积缓存同时失效,DB压力骤增 | 过期时间随机化、多级缓存 |
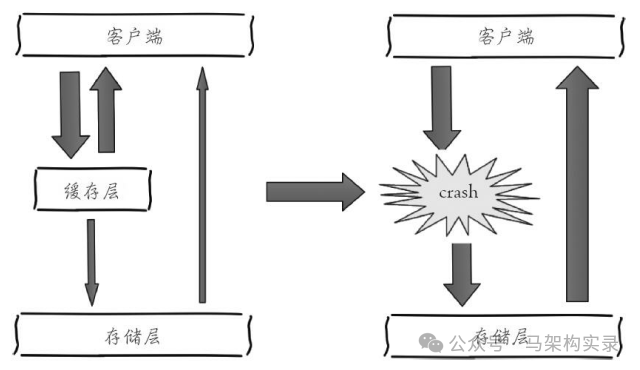
缓存雪崩防护措施图解
图:缓存雪崩防护措施图解,左侧为正常缓存流程,右侧展示缓存层崩溃后的流量直达存储层的危险情况
5.2 缓存与GC优化
堆缓存可能导致GC压力增大,优化方案:
- • 合理设置缓存大小,避免过大
- • 使用软引用/弱引用
- • 考虑堆外缓存(如MapDB)
- • 定期清理过期数据
// 堆外缓存实现(MapDB)
HTreeMap offHeapCache = DBMaker
.memoryDirectDB() // 堆外内存
.concurrencyScale(16) // 并发级别
.make()
.hashMap("offHeapCache")
.expireMaxSize(100000) // 最大条目
.expireAfterCreate(30, TimeUnit.SECONDS)
.create();总结与展望
缓存是构建高性能系统的关键组件,设计时需综合考虑业务场景、数据特性和性能需求。本文介绍的缓存策略和实现方案已在大规模生产环境得到验证,包括:
- 1. 多级缓存架构:本地缓存+分布式缓存结合
- 2. 灵活的缓存策略:根据数据特性选择LRU/LFU/TTL等
- 3. 高可用设计:防穿透、击穿、雪崩的完整方案
- 4. 性能优化:命中率提升与GC优化实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号