



深入解析:时序数据库选型指南:为什么工业物联网场景首选 Apache IoTDB?
引言
面对物联网设备产生的海量时间序列数据,传统数据库正面临前所未有的性能与架构挑战。
在工业物联网、智慧城市、车联网等场景中,每秒产生数百万数据点已成为常态。据实测数据,传统关系型数据库在处理此类数据时,写入性能通常不超过1万点/秒,且存储成本居高不下。而专门设计的时序数据库如Apache IoTDB,单节点写入吞吐可达1000万点/秒以上,存储空间仅为传统方案的1/10。
本文将深入解析时序数据库选型要点,并揭示IoTDB如何在工业物联场景中脱颖而出。
文章目录
一、物联网时代的数据挑战
现代工业环境中的传感器网络每秒产生海量时间序列数据,这些数据具有显著特征:
- 高频写入:单个设备可能以毫秒级频率持续产生数据点
- 高基数维度:数万甚至百万级设备节点形成复杂层级关系
- 长期存储:工业数据常需保存数十年用于趋势分析与安全审计
- 实时分析:设备监控与预警要求毫秒级响应延迟
传统数据库采用的行式存储和二维表结构在处理此类数据时面临写入瓶颈、存储膨胀、查询效率低下三大痛点,这正是时序数据库(TSDB)登上历史舞台的核心驱动力。
二、IoTDB的架构创新
作为源自清华大学的Apache顶级项目,IoTDB专为工业物联网场景设计,其架构创新体现在三个层面: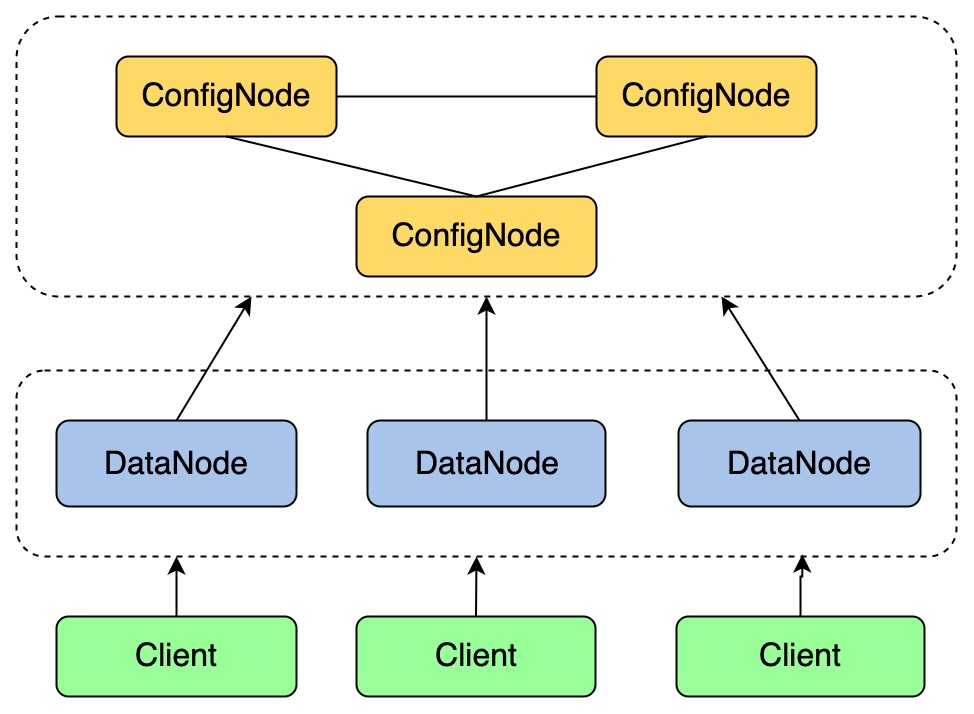
1. 树表双模型:贴合工业数据结构
IoTDB独创的树形数据模型天然适配设备层级关系,例如:
工厂A(根节点)
├── 车间1
│ ├── 生产线A
│ │ ├── 温度传感器
│ │ └── 振动传感器
│ └── 生产线B
└── 车间2通过root.factory.workshop1.lineA.temperature路径即可精确定位传感器,避免传统数据库的多表关联查询,使复杂设备关系的查询效率提升10倍以上。
同时V2.0版本引入的表模型支持标准SQL查询,实现:
- 时间序列与关系数据的统一处理
- ASOF INNER JOIN等高级时序关联操作
- 用户自定义函数(UDTF)扩展分析能力
2. 端边云协同:全域数据流水线
IoTDB提供业界最完整的端-边-云一体化架构:
| 层级 | 组件 | 资源占用 | 典型场景 |
|---|---|---|---|
| 设备端 | IoTDB-Edge | <10MB | 数据本地存储与预处理 |
| 边缘层 | IoTDB-Edge集群版 | 1-2GB | 区域数据汇聚与实时计算 |
| 云端 | IoTDB-Cluster | 弹性扩展 | 全局分析与企业级应用 |
这种分层架构通过TsFile(专有时序文件格式)实现数据无缝同步,边缘端采集的数据可直接被云端加载分析,避免ETL过程中的数据损失和延迟。
3. 高效存储引擎:十倍的压缩奇迹
IoTDB通过列式存储+时序编码+多级压缩实现存储效率的跃升:
原始数据 → Gorilla编码(处理浮点) → RLE(处理整型) → Snappy压缩 → TsFile实测数据显示,工业设备数据经过该流程后:
- 压缩比达到8-10倍,远超传统数据库的2-3倍
- 存储空间相比InfluxDB节省30%-50%
- 查询响应时间缩短至传统方案的1/20
三、与国外产品的性能对决
1. 对阵传统数据库:百倍性能碾压

下表展示IoTDB与关系型数据库的性能对比:
| 指标 | IoTDB | 传统数据库 | 优势倍数 |
|---|---|---|---|
| 写入吞吐 | ≥1000万点/秒 | ≤1万点/秒 | 100x |
| 存储成本 | 1TB原始数据 | 10TB | 10x |
| 时间窗口查询 | 毫秒级 | 分钟级 | 60x+ |
| 复杂分析延迟 | 亚秒级 | 小时级 | 100x+ |
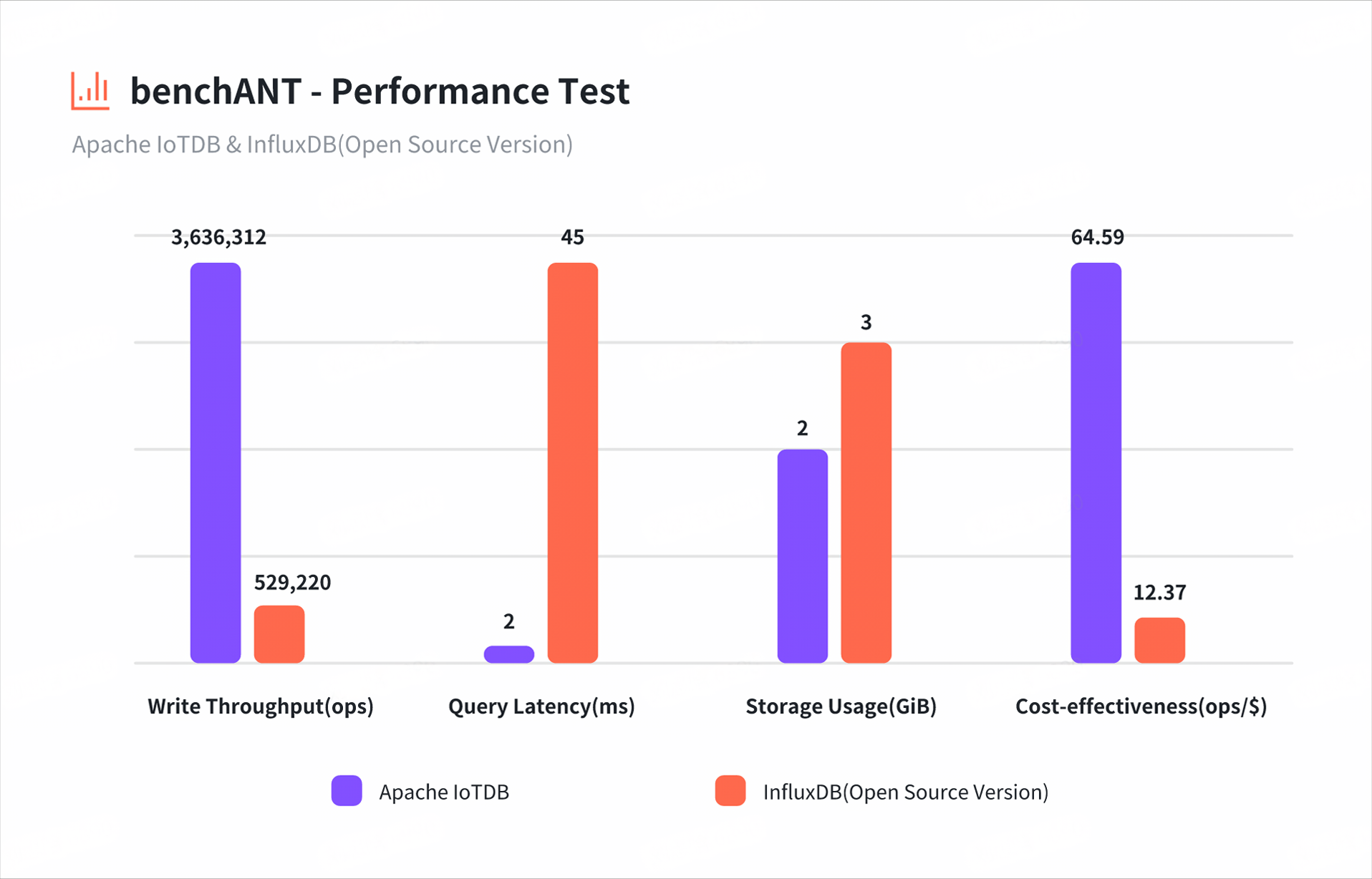
2. 对阵InfluxDB:工业场景的完胜
在工业设备监控场景的对比测试中:
- 写入吞吐:IoTDB单节点达30万点/秒 vs InfluxDB OSS版20万点/秒
- 高基数支持:IoTDB处理10万设备元数据时内存占用仅为InfluxDB的1/3
- 查询灵活性:InfluxDB的Flux语言功能强大但学习曲线陡峭,而IoTDB的类SQL语法更符合工程师习惯
- 协议适配:IoTDB原生支持Modbus、OPC UA等工业协议,减少数据接入成本
3. 对阵OpenTSDB:架构轻量化的典范
OpenTSDB作为早期时序数据库代表,其基于HBase的架构导致:
- 部署需ZooKeeper+HDFS+HBase三件套
- 原始数据以字符串存储导致5倍以上存储膨胀
- 边缘设备部署基本不可行
而IoTDB单机版可运行在树莓派级别设备,启动内存仅需百MB级,运维成本降低70%。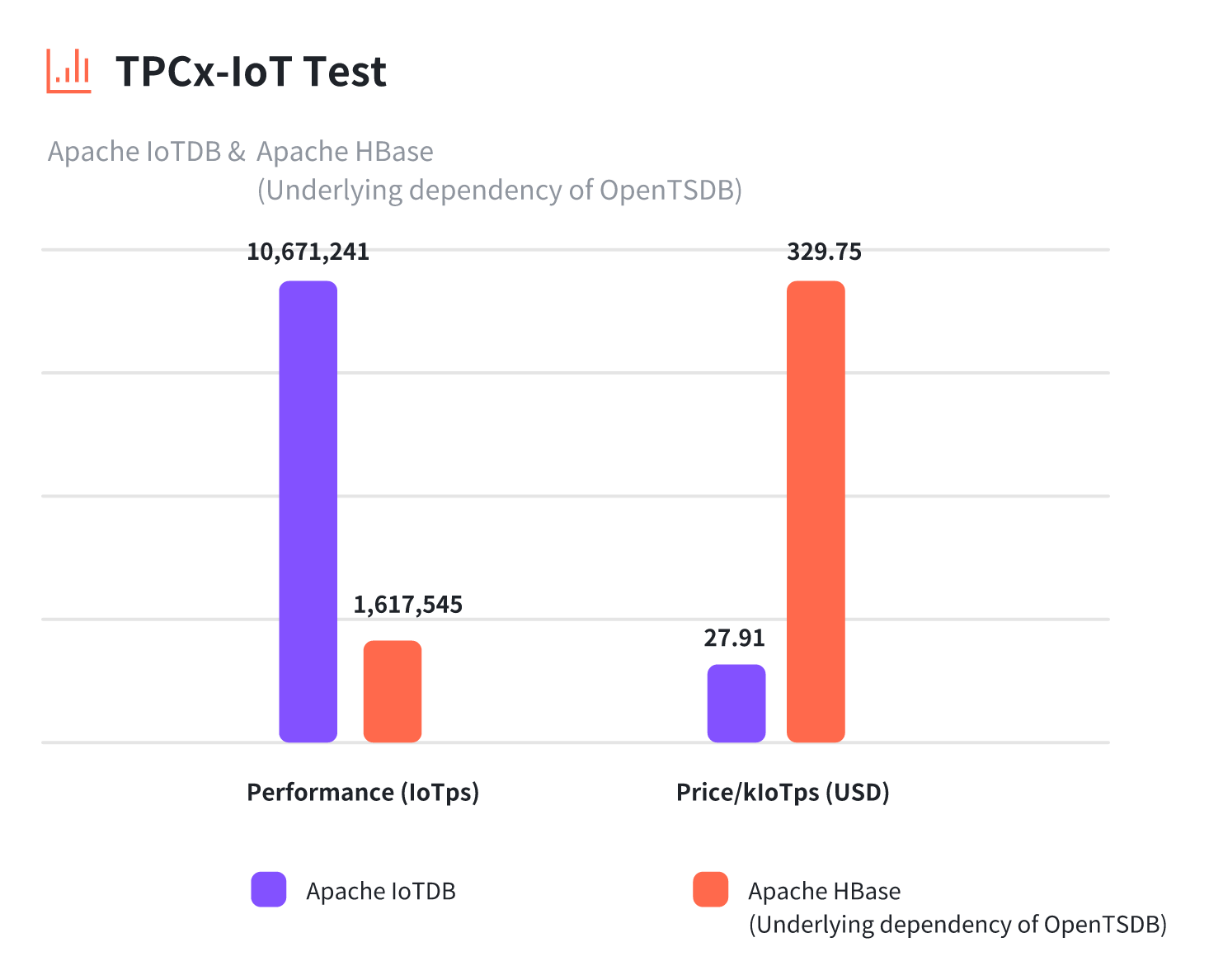
四、企业版的核心价值
天谋科技(Timecho)推出的IoTDB企业版在开源版基础上增强五大能力:

1. 可视化运维控制台
- 实时集群状态监控
- 数据模型可视化编辑
- 查询性能分析看板
避免“命令行恐惧症”,降低DBA使用门槛
2. 生产级增强功能
| 功能 | 开源版 | 企业版 |
|---|---|---|
| 数据备份 | 全量导出 | 增量实时同步 |
| 访问控制 | IP白名单 | 角色权限+审计日志 |
| 安全审计 | 无 | 全操作追踪 |
| 高可用 | 主从切换 | 跨地域容灾 |
3. AI内生支持
企业版集成端到端机器学习流水线:
- 通过SQL直接调用预测算法:
SELECT forecast(temperature) FROM sensors - 内置异常检测模型自动识别设备异常
- 支持协变量分析(引入温度、湿度等外部因子)
在风电故障预测场景中,提前30分钟识别故障的准确率达92%。

五、选型决策指南
1. 首选IoTDB的场景
- 工业物联网:设备层级复杂、协议多样的工厂环境
- 边缘计算:资源受限的嵌入式或移动场景
- 成本敏感型:PB级数据长期存储的预算控制
- 国产化要求:需适配麒麟OS、鲲鹏芯片等信创生态
2. 推荐搭配方案
3. 避坑建议
- 避免高基数操作:单设备测点不宜超过1万
- 冷热分离策略:对历史数据启用TTL自动转存对象存储
- 写入缓冲配置:网络不稳定时启用本地缓存防数据丢失
- 集群分片规划:按物理区域划分数据分片,减少跨网查询
随着2025年V2.0.4版本的发布,IoTDB在用户自定义函数、时间序列JOIN、脚本工具完善化等方面持续进化。测试数据表明,在典型工业设备监控场景中,IoTDB相比传统方案可降低50%存储成本,提升10倍以上查询效率,写入性能可达传统数据库的100倍。对于真正需要处理海量时间序列数据的企业,IoTDB不仅是技术选项,更是战略选择。
立即体验:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号