



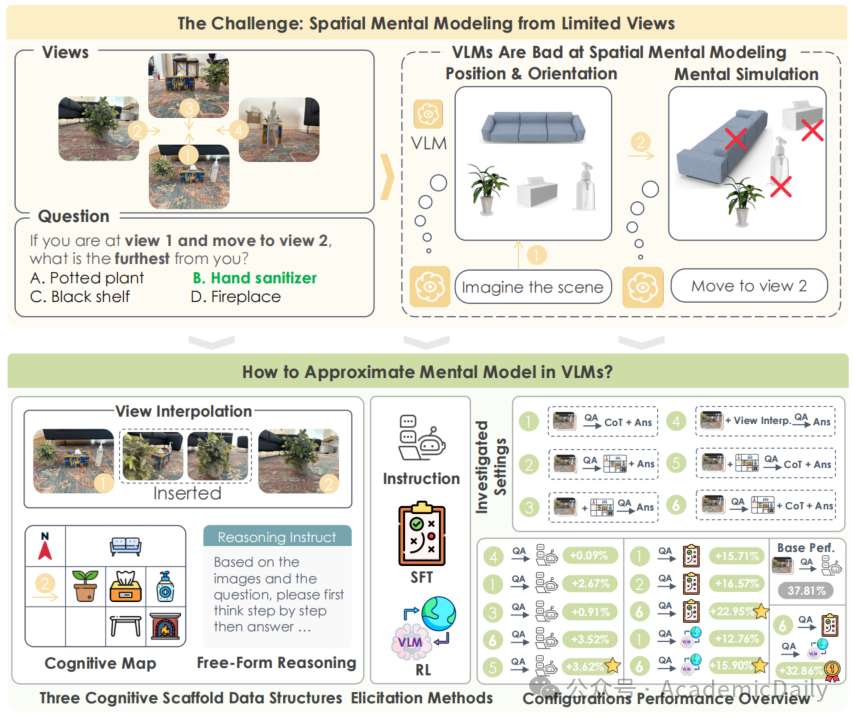
VLMs能否像人类一样从少数视图中想象出完整场景?人类会形成空间心理模型,即对不可见空间的内部表征,以推理布局、视角和运动。新 MINDCUBE 基准包含 3268 张图像和 21154 个问题,揭示了这一关键差距,现有 VLMs 在该基准上表现接近随机。利用 MINDCUBE,我们系统评估了 VLMs 通过表征位置(认知映射)、方向(视角获取)和动态(“假设” 运动的心理模拟) - 实践
转:斯坦福李飞飞 | 认知地图技术让 VLMs 实现人类级空间推理,WorldScore基准开启3D生成新时代
原创 AcademicDaily AcademicDaily2025年06月27日 14:28北京
在AI领域,李飞飞教授的每一次发声都牵动着行业的神经。
近日,她领衔的World Labs团队在空间智能研究中取得里程碑式突 —— 经过构建认知地图,视觉语言模型(VLMs)首次达成了接近人类水平的空间推理能力。
这一成果不仅填补了 AI 在三维空间理解上的空白,更被业界视为通向AGI的关键一步。
与此同时,团队发布的WorldScore基准为3D生成模型供应了统一评估标准,标志着 AI 空间智能进入量化发展新阶段。

【论文链接】https://arxiv.org/pdf/2506.21458v1
1摘要
VLMs能否像人类一样从少数视图中想象出完整场景?人类会形成空间心理模型,即对不可见空间的内部表征,以推理布局、视角和运动。
新 MINDCUBE 基准包含 3268 张图像和 21154 个挑战,揭示了这一关键差距,现有 VLMs 在该基准上表现接近随机。
利用 MINDCUBE,我们框架评估了 VLMs 通过表征位置(认知映射)、方向(视角获取)和动态(“假设” 运动的心理模拟)来构建稳健空间心理模型的能力。
随后探索了三种辅助 VLMs 近似空间心理模型的途径,包括不可见的中间视图、自然语言推理链和认知地图。
显著的改进来自 “先建图后推理” 的协同方法,该方法联合训练模型先生成认知地图,再基于地图进行推理。
借助训练模型在这些内部地图上推理,将准确率从 37.8% 提升至 60.8%(+23.0%)。加入强化学习后性能进一步提升至 70.7%(+32.9%)。
核心见解是,这种空间心理模型的支架,即主动构建和利用具有灵活推理过程的内部结构化空间表征,可显著改善对不可观测空间的理解。
AcademicDailyAcademicDaily是一个跟踪、推荐和解读大模型等AI成果的技术交流平台,致力于传播和分享前沿技术。
2背景
对于VLMs而言,要从被动感知迈向与部分可观测环境交互,从有限视图中推理不可见的空间关系至关重要。
人类能轻松通过几次自我中心观察整合信息,推断房间布局或家具后隐藏的物体。
然而,尽管 VLMs 取得了显著进展,却难以从有限视图合成空间信息、保持跨视图一致性,以及对未直接可见的物体进行推理。
这一差距亟需专门的评估设置,需包括:
(a)对物体被遮挡或不在视野中的部分观察进行推理;
(b)在变化的视角间保持跨视图一致性;
(c)心理模拟以推断隐藏的空间关系。因此,本文引入 MINDCUBE 基准来填补这一空白。
3贡献
提出 MINDCUBE 基准,包含 21154 个问题和 3268 张图像,用于评估 VLMs 在部分观察和动态视角下的空间推理能力。
探索了三种帮助 VLMs 近似空间心理模型的途径,并发现 “先建图后推理” 的协同方法效果最佳,显著提升了模型性能。
依据SFT和RL相结合的方式,将 VLMs 在空间推理任务上的准确率从 37.8% 提升至 70.7%,证明了主动构建和利用内部结构化空间表征的有效性。
4MIND CUBE基准和评估
4.1MINDCUBE基准概述
MINDCUBE是用于评估VLMs在部分观察和动态视角下空间推理能力的基准,其核心设计旨在解决以下挑战:
跨视图对象一致性:维持不同视角下的对象关系;
遮挡/不可见元素推理:对被遮挡或未直接可见的对象进行推断。
数据构成:
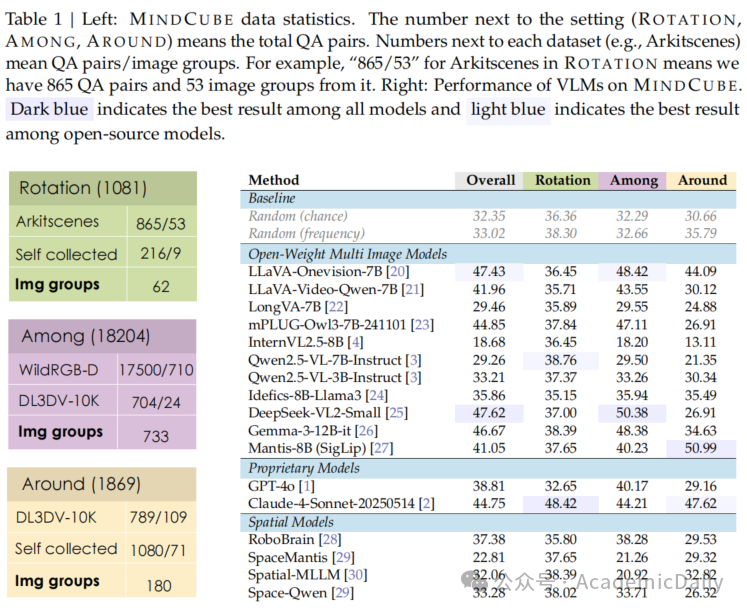
包含3268张图像,分为976个多视图组,对应21154个空间推理问题;
数据来源包括公开资料集和自收集图像,覆盖室内/室外场景。
4.2基准分类法
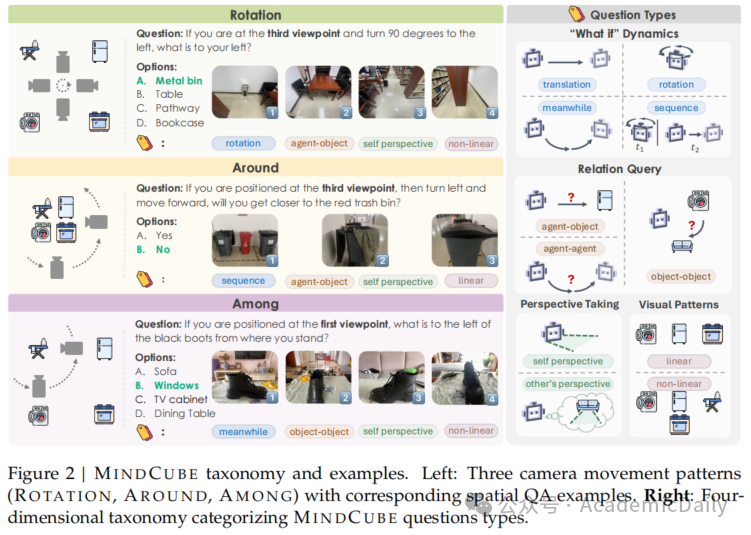
借助五个维度对疑问类型进行系统分类(图2):
相机移动模式:
旋转:原地旋转观察(如90°转向);
环绕:围绕对象做圆周运动;
穿梭:在多个对象间移动。
视觉模式:对象的空间排列(线性/非线性)。
“假设”动态:
纯平移、纯旋转、同时平移+旋转、顺序平移+旋转。
关系查询:
智能体-对象、智能体-智能体、对象-对象。
视角获取:
自我视角、他人视角(如从沙发视角推理)。
4.3信息集构建流程
图像筛选:根据相机移动模式从数据集中提取多视图组,确保视图符合空间推理需求(如无运动模糊、对象可见性)。
标注与问题生成:
标注对象空间关系、遮挡程度等;
基于分类法自动生成问题,含有干扰选项(如错误的对象位置)。
4.4评估结果与分析
模型表现:
17个主流VLMs(如LLaVA、GPT-4o、DeepSeek-VL2)在MINDCUBE上表现普遍不佳,最高准确率为47.62%(DeepSeek-VL2-Small),远低于人类水平(94.55%)。
专有模型(如Claude-4-Sonnet)在特定类别(如Rotation)中表现较好,但无模型在所有类别中领先。
关键发现:
多图像输入和空间微调未显著提升性能,表明现有方法难以奏效处理空间推理。
5哪种脚手架最能引导未改变的 VLMs 的空间思维?

5.1认知支架的数据结构设计
为帮助冻结的VLMs从有限视图构建空间心理模型,研究提出三种结构化数据作为认知支架(图3):
视图插值:
在稀疏视图间生成中间帧(如1帧或2帧),模拟心理动画过程,试图增强视角转换的连续性。
认知地图:
普通版:仅包含物体位置的2D俯视图,类似“认知拼贴”;
增强版:额外标注相机视角的位置和朝向,强化视图与物体的空间关系。
自由形式推理:
自然语言CoT,外化空间推断步骤,如通过多视图对比确定物体相对位置。
5.2实验设置与关键结果
模型与数据:启用Qwen2.5-VL-3B-Instruct模型,在MINDCUBE-TINY子集(1050题)上测试。
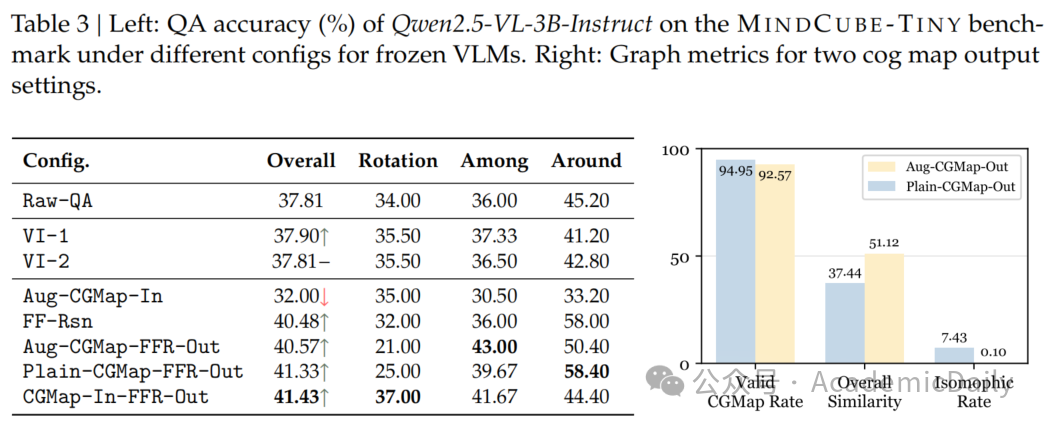
核心发现(表3):
视图插值无效:添加1-2帧中间视图后,准确率仅提升0.09%,表明视觉连续性无法改善推理。
认知地图输入适得其反:直接提供增强地图导致准确率下降至32.00%,因模型无法有效利用外部结构。
自由形式推理奏效:单独启用推理链将准确率提升至40.48%,结合地图生成可进一步提升至41.33%。
地图生成质量(见表3右):
模型生成的地图格式有效性高(ValidRate>92%),但与真实地图的同构率极低(增强版0.10%,普通版7.43%),说明缺乏几何推理能力。
6能否教会视觉语言模型构建并利用空间表征?
6.1 SFT框架设计
为处理冻结模型的空间推理缺陷,研究借助SFT训练VLMs自主构建和利用空间表征,核心设计如下:
数据构建:
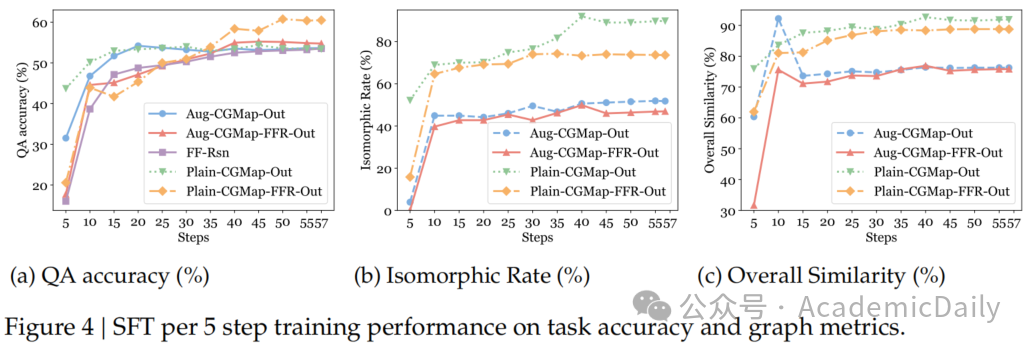
认知地图:依据模板法生成10,000个真实地图,以鸟瞰视角标注物体位置和相机朝向(见图4)。
推理链:手动构建10,000条自然语言推理链,遵循“视图分析→跨视图整合→挑战推断”三步逻辑。
实验配置:
基础模型:Qwen2.5-VL-3B-Instruct;
评估数据集:MINDCUBE-TINY;
任务组合:单独地图生成、单独推理、联合地图+推理。
6.2 SFT关键结果
单组件微调效果(见表4):
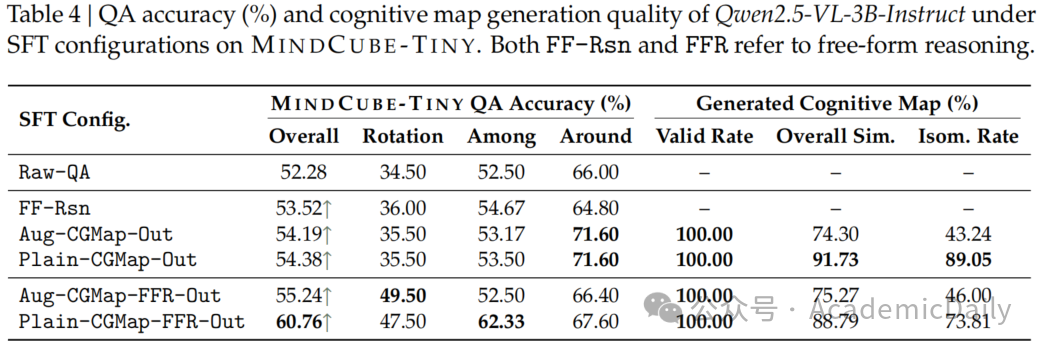
单独微调地图生成将准确率提升至56.38%,地图同构率从7.4%提升至89.05%。
单独微调推理链仅提升1.2%,表明纯语言推理缺乏空间表征支撑。
联合训练的协同效应:
联合生成普通地图+推理实现最高准确率60.76%,地图同构率达73.81%,证明结构与推理的互补性。
训练动态分析(见图4):
单独地图生成模型快速收敛但准确率停滞,而联合训练模型虽收敛慢,但持续提升至更高水平。
7强化学习能否进一步优化空间思维过程?
7.1 RL实验设置
基于SFT模型,研究通过RL进一步优化空间推理,核心设计如下:
框架与算法:利用VAGEN框架,采用GRPO算法。
奖励函数:
结构有效性(+1):生成合规的认知地图或推理链;
答案正确性(+5):正确回答空间问题。
实验配置:
从scratch训练:RL-FF-Rsn(推理链)、RL-Aug-CGMap-FFR-Out(联合地图+推理);
从SFT初始化:以最佳SFT模型(Plain-CGMap-FFR-Out)为起点,训练RL-Plain-CGMap-FFR-Out。
7.2 RL关键结果
性能提升(见表5):
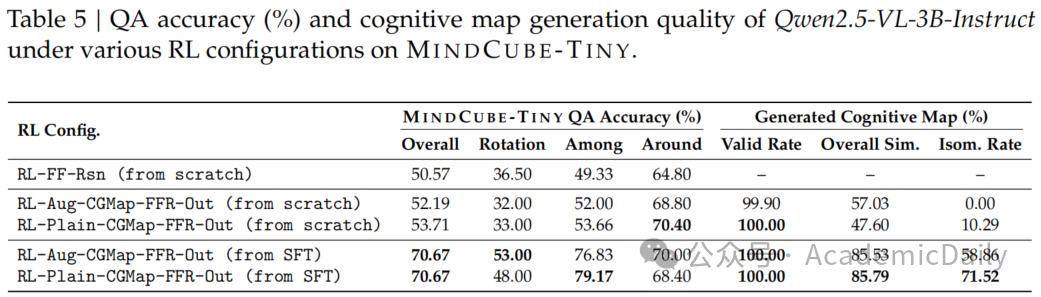
从SFT初始化的RL模型将准确率提升至70.67%,较SFT基线(60.76%)提高9.91%。
普通地图+推理(RL-Plain-CGMap-FFR-Out)的地图同构率达71.52%,优于增强版(58.86%),表明简洁表征更易优化。
训练效率:
RL有效的前提。就是从scratch训练的RL模型性能提升有限(最高53.71%),证明SFT预训练
8结论
本文提出了MINDCUBE基准以研究VLMs如何从有限视图近似空间心理模型,这是在部分可观测环境中进行推理的核心认知能力。
不同于仅进行基准测试,本文探索了如何通过结构化数据和推理来支撑内部表征。
关键发现是,在所有启发方法(输入输出配置、监督微调、强化学习)中,构建并基于自生成的认知地图进行推理,是对空间心理模型最有效的近似。
从经过良好训练的监督微调检查点初始化强化学习,进一步优化了这一过程,将空间推理性能推向了新的高度。
在未来影响方面,本文的工作确立了将认知地图生成与推理相结合来建模空间信息是最有效的技巧。
通过相信一旦建立了用于认知地图生成和推理的高质量监督微调数据集,就能够利用强化学习进一步突破性能界限。
原文连接:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号