20183413 2019-2020-2 《Python程序设计》实验4报告
20183413 2019-2020-2 《Python程序设计》实验4报告
课程:《Python程序设计》
班级:1834
姓名: 李杰
学号:20183413
实验教师:王志强
实验日期:2020年6月10日
必修/选修: 公选课
1.实验内容
使用爬虫获取某网站的信息。
2.实验过程及结果
我本次实验打算利用爬虫爬上某个网站,在我试图使用requests库设计程序时,却发现我的电脑无法安装requests库,我用的是python3.8,这一版本自带了pip,但是我的电脑依然无法通过pip来下载安装外部网络库,我在网上找了几种解决方法,甚至是重新安装python都无济于事。所以我只能寄希望于python自带的urllib来完成实验,但是因为该库功能不及requests,以及没有安装bs4等网络库,具体实验效果会大打折扣,只能实现简单的功能。
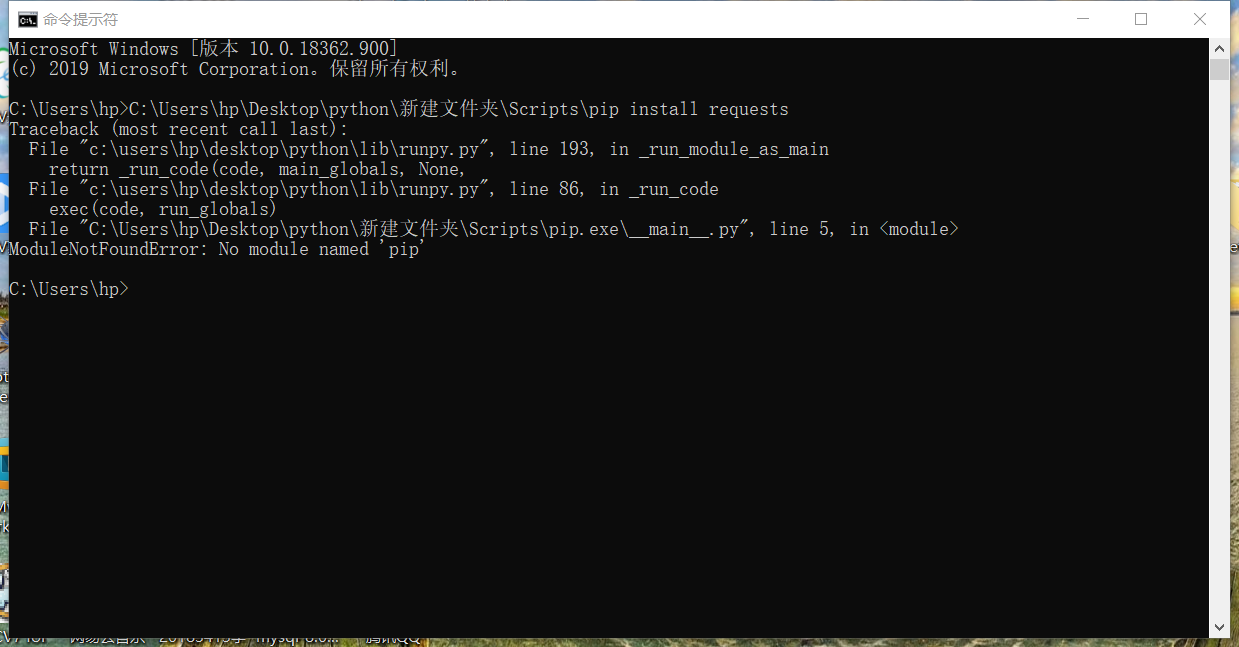
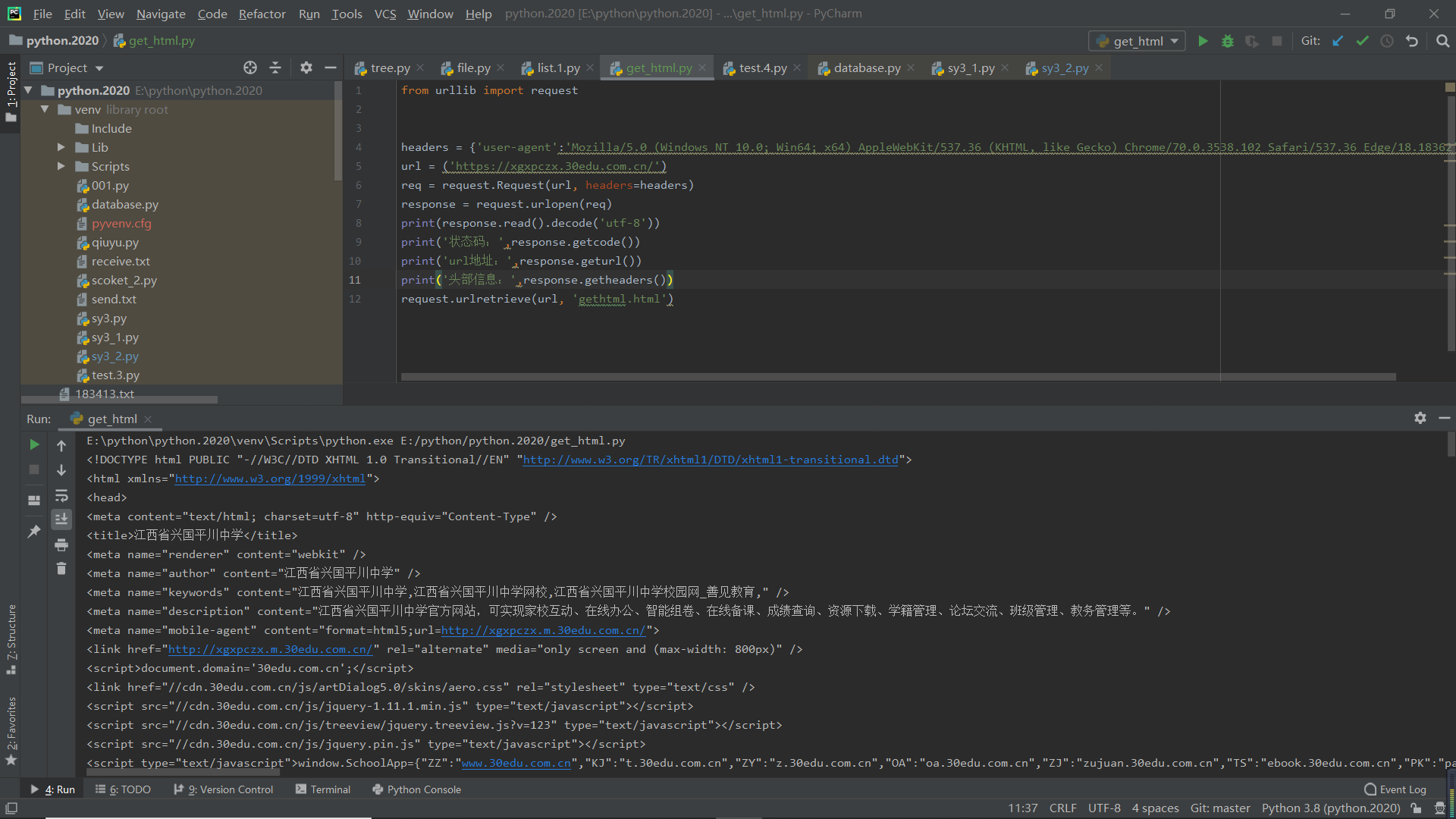
首先调用urllib库的request模块,找一个网站的url,使用Request函数发送请求,随后使用urlopen函数打开网站,最后读取网站内容并输出。打开时遇到403错误,从该网站处获取头部信息,请求headers处理,即可成功爬取该网站信息。还可以调用urllib库中的其他函数获取状态码、头部信息等,还可以将获取的网站内容下载至电脑。
from urllib import request
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
url = ('https://xgxpczx.30edu.com.cn/')
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
print('状态码:',response.getcode())
print('url地址:',response.geturl())
print('头部信息:',response.getheaders())
request.urlretrieve(url, 'gethtml.html')
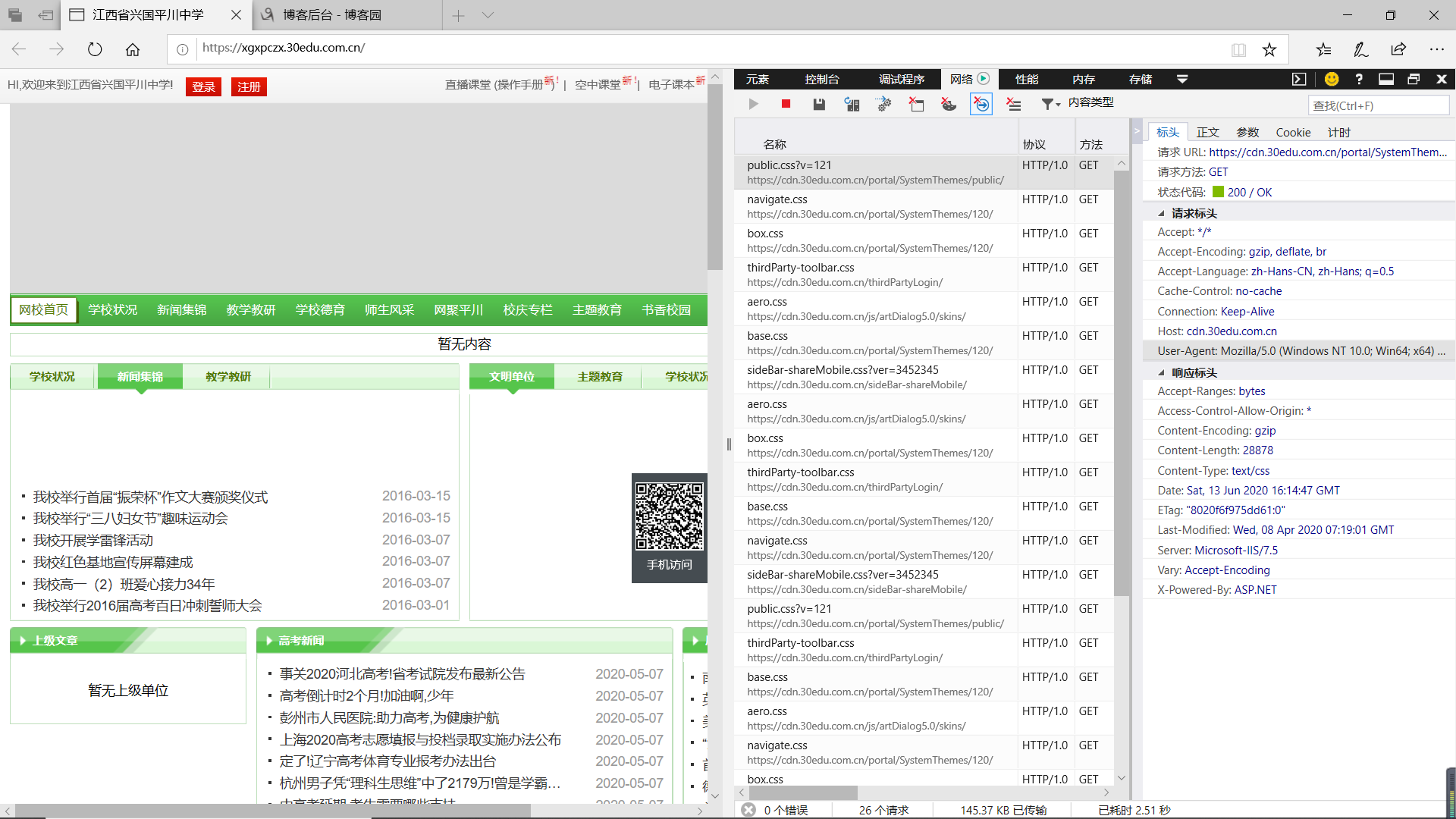

3.实验过程中遇到的问题及解决过程
问题:始终无法安装外部网络库
解决方案:使用自带的urllib进行实验
总结
时间过得很快,刚刚接触python的我们已经结束了一个学期的课程学习。对我来说,python即熟悉又陌生,熟悉是因为大一下学期学习了C语言,那个时候我花了很多时间去学习这门课程,通过计算机实习,我对C语言和程序设计有了更浓厚的兴趣和更深的理解,对程序设计的好奇也是我选择这门课的主要原因;陌生是因为python和C语言又有很多不同的地方,比如一个是面向对象,一个是面向过程。通过一个学期的学习,python给我的印象是简便、功能强大,python语言中有许多函数我们可以直接调用,利用这些函数,我们可以仅用一两行代码就实现C语言中几十行代码才能完成的功能,另外,就我目前学到的知识来说,同样是一个学期的学习,我们学到的C语言的知识还是十分基础的,实际应用起来还是比较费劲;但是我们学到的python的知识就更加丰富了,我们已经可以使用它来爬网站、写游戏了。python的应用范围也更加广,在以后的实际应用中也用的更多,比如这段时间的大创,里面项目中的程序大部分都是使用python编写的,所以说学号python十分受用。这一学期的课王老师讲的很好,我们学的也不错,但是我们不能满足于此,要在以后的时间里不断学习、不断练习,这样才能真正的掌握好这一门语言。对于这门课的建议,我觉得老师可以举行一些有意思的比赛,比如让同学们设计一款游戏,老师限定游戏的类型,给出要求,看看谁能把游戏做的更好,或者是让同学们同时爬某个网站的信息,看看谁爬的最快,最全。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号