Kaggle TMDB 票房预测
数据分析 - Kaggle TMDB 票房预测
-
- 环境准备
- 数据集
- 正文
- 数据预处理
- 数据探索性分析
- 建模
环境准备
使用了的环境:
- Windows 10
- python 3.7.2
- Jupyter Notebook (代码均在此测试成功)
数据集
https://www.kaggle.com/c/tmdb-box-office-prediction/data
正文
开工前准备,导入第三方库:
import pandas as pd
pd.set_option('max_columns',None)
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.graph_objs as go
import plotly.offline as py
from wordcloud import WordCloud
plt.style.use('ggplot')
import ast
from collections import Counter
import numpy as np
from sklearn.preprocessing import LabelEncoder
# 文本挖掘
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
from sklearn.linear_model import LinearRegression
# 模型
from sklearn.model_selection import train_test_split
import lightgbm as lgb
加载数据:
train=pd.read_csv('dataset/train.csv')
test=pd.read_csv('dataset/test.csv')
简单了解数据:
train.head()
| id | belongs_to_collection | budget | genres | homepage | imdb_id
| original_language | original_title | overview | popularity |
poster_path | production_companies | production_countries | release_date
| runtime | spoken_languages | status | tagline | title | Keywords
| cast | crew | revenue
---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---
0 | 1 | [{‘id’: 313576, ‘name’: 'Hot Tub Time Machine … | 14000000 |
[{‘id’: 35, ‘name’: ‘Comedy’}] | NaN | tt2637294 | en | Hot Tub Time
Machine 2 | When Lou, who has become the "father of the In… | 6.575393 |
/tQtWuwvMf0hCc2QR2tkolwl7c3c.jpg | [{‘name’: ‘Paramount Pictures’, ‘id’: 4},
{'na… | [{‘iso_3166_1’: ‘US’, ‘name’: 'United States o… | 2/20/15 | 93.0
| [{‘iso_639_1’: ‘en’, ‘name’: ‘English’}] | Released | The Laws of Space
and Time are About to be Vio… | Hot Tub Time Machine 2 | [{‘id’: 4379,
‘name’: ‘time travel’}, {‘id’: 9… | [{‘cast_id’: 4, ‘character’: ‘Lou’,
'credit_id… | [{‘credit_id’: ‘59ac067c92514107af02c8c8’, 'de… | 12314651
1 | 2 | [{‘id’: 107674, ‘name’: 'The Princess Diaries … | 40000000 |
[{‘id’: 35, ‘name’: ‘Comedy’}, {‘id’: 18, 'nam… | NaN | tt0368933 | en
| The Princess Diaries 2: Royal Engagement | Mia Thermopolis is now a
college graduate and … | 8.248895 | /w9Z7A0GHEhIp7etpj0vyKOeU1Wx.jpg |
[{‘name’: ‘Walt Disney Pictures’, ‘id’: 2}] | [{‘iso_3166_1’: ‘US’, ‘name’:
'United States o… | 8/6/04 | 113.0 | [{‘iso_639_1’: ‘en’, ‘name’:
‘English’}] | Released | It can take a lifetime to find true love; she’…
| The Princess Diaries 2: Royal Engagement | [{‘id’: 2505, ‘name’:
‘coronation’}, {‘id’: 42… | [{‘cast_id’: 1, ‘character’: ‘Mia Thermopolis’…
| [{‘credit_id’: ‘52fe43fe9251416c7502563d’, 'de… | 95149435
2 | 3 | NaN | 3300000 | [{‘id’: 18, ‘name’: ‘Drama’}] |
http://sonyclassics.com/whiplash/ | tt2582802 | en | Whiplash | Under
the direction of a ruthless instructor, … | 64.299990 |
/lIv1QinFqz4dlp5U4lQ6HaiskOZ.jpg | [{‘name’: ‘Bold Films’, ‘id’: 2266},
{‘name’: … | [{‘iso_3166_1’: ‘US’, ‘name’: 'United States o… | 10/10/14 |
105.0 | [{‘iso_639_1’: ‘en’, ‘name’: ‘English’}] | Released | The road
to greatness can take you to the edge. | Whiplash | [{‘id’: 1416, ‘name’:
‘jazz’}, {‘id’: 1523, 'n… | [{‘cast_id’: 5, ‘character’: ‘Andrew Neimann’,…
| [{‘credit_id’: ‘54d5356ec3a3683ba0000039’, 'de… | 13092000
3 | 4 | NaN | 1200000 | [{‘id’: 53, ‘name’: ‘Thriller’}, {‘id’: 18,
'n… | http://kahaanithefilm.com/ | tt1821480 | hi | Kahaani | Vidya
Bagchi (Vidya Balan) arrives in Kolkata … | 3.174936 |
/aTXRaPrWSinhcmCrcfJK17urp3F.jpg | NaN | [{‘iso_3166_1’: ‘IN’, ‘name’:
‘India’}] | 3/9/12 | 122.0 | [{‘iso_639_1’: ‘en’, ‘name’: ‘English’},
{'iso… | Released | NaN | Kahaani | [{‘id’: 10092, ‘name’: ‘mystery’},
{‘id’: 1054… | [{‘cast_id’: 1, ‘character’: ‘Vidya Bagchi’, '… |
[{‘credit_id’: ‘52fe48779251416c9108d6eb’, 'de… | 16000000
4 | 5 | NaN | 0 | [{‘id’: 28, ‘name’: ‘Action’}, {‘id’: 53, 'nam… |
NaN | tt1380152 | ko | 마린보이 | Marine Boy is the story of a former
national s… | 1.148070 | /m22s7zvkVFDU9ir56PiiqIEWFdT.jpg | NaN |
[{‘iso_3166_1’: ‘KR’, ‘name’: ‘South Korea’}] | 2/5/09 | 118.0 |
[{‘iso_639_1’: ‘ko’, ‘name’: ‘한국어/조선말’}] | Released | NaN | Marine Boy
| NaN | [{‘cast_id’: 3, ‘character’: ‘Chun-soo’, 'cred… | [{‘credit_id’:
‘52fe464b9251416c75073b43’, 'de… | 3923970
数据集大小:数据量挺小的
print(train.shape)
print(test.shape)
(3000, 23)
(4398, 22)
数据预处理
从上面的数据预览,发现有几列是json形式的数据,必须转化成可处理的格式。json数据在python中可以pyquery处理,pyquery的语法类似于jquery,也可以用ast.literal_eval将字符串型的json数据转化成字典列表,这里我用第二种方法:
dict_columns = ['belongs_to_collection', 'genres', 'production_companies',
'production_countries', 'spoken_languages', 'Keywords', 'cast', 'crew']
def json_to_dict(df):
for column in dict_columns:
df[column] = df[column].apply(lambda x: {} if pd.isna(x) else ast.literal_eval(x) )
return df
train = json_to_dict(train)
test = json_to_dict(test)
再将这些不规则数据转化成特征,分为标签提取与编码,如关键演员、题材、分类、系列、发行方等,以及标签数量统计,如分类数量、演员数量、主题长度等。这里需要注意,因为数据集不多,为避免模型过拟合,应仅对TOP的标签进行编码:
# collections
train['collection_name'] = train['belongs_to_collection'].apply(lambda x: x[0]['name'] if x != {} else 0)
train['has_collection'] = train['belongs_to_collection'].apply(lambda x: len(x) if x != {} else 0)
test['collection_name'] = test['belongs_to_collection'].apply(lambda x: x[0]['name'] if x != {} else 0)
test['has_collection'] = test['belongs_to_collection'].apply(lambda x: len(x) if x != {} else 0)
train = train.drop(['belongs_to_collection'], axis=1)
test = test.drop(['belongs_to_collection'], axis=1)
# genres
list_of_genres = list(train['genres'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
train['num_genres'] = train['genres'].apply(lambda x: len(x) if x != {} else 0)
train['all_genres'] = train['genres'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
top_genres = [m[0] for m in Counter([i for j in list_of_genres for i in j]).most_common(15)]
for g in top_genres:
train['genre_' + g] = train['all_genres'].apply(lambda x: 1 if g in x else 0)
test['num_genres'] = test['genres'].apply(lambda x: len(x) if x != {} else 0)
test['all_genres'] = test['genres'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
for g in top_genres:
test['genre_' + g] = test['all_genres'].apply(lambda x: 1 if g in x else 0)
train = train.drop(['genres'], axis=1)
test = test.drop(['genres'], axis=1)
# production companies
list_of_companies = list(train['production_companies'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
train['num_companies'] = train['production_companies'].apply(lambda x: len(x) if x != {} else 0)
train['all_production_companies'] = train['production_companies'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
top_companies = [m[0] for m in Counter([i for j in list_of_companies for i in j]).most_common(30)]
for g in top_companies:
train['production_company_' + g] = train['all_production_companies'].apply(lambda x: 1 if g in x else 0)
test['num_companies'] = test['production_companies'].apply(lambda x: len(x) if x != {} else 0)
test['all_production_companies'] = test['production_companies'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
for g in top_companies:
test['production_company_' + g] = test['all_production_companies'].apply(lambda x: 1 if g in x else 0)
train = train.drop(['production_companies', 'all_production_companies'], axis=1)
test = test.drop(['production_companies', 'all_production_companies'], axis=1)
# production countries
list_of_countries = list(train['production_countries'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
train['num_countries'] = train['production_countries'].apply(lambda x: len(x) if x != {} else 0)
train['all_countries'] = train['production_countries'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
top_countries = [m[0] for m in Counter([i for j in list_of_countries for i in j]).most_common(25)]
for g in top_countries:
train['production_country_' + g] = train['all_countries'].apply(lambda x: 1 if g in x else 0)
test['num_countries'] = test['production_countries'].apply(lambda x: len(x) if x != {} else 0)
test['all_countries'] = test['production_countries'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
for g in top_countries:
test['production_country_' + g] = test['all_countries'].apply(lambda x: 1 if g in x else 0)
train = train.drop(['production_countries', 'all_countries'], axis=1)
test = test.drop(['production_countries', 'all_countries'], axis=1)
# spoken languages
list_of_languages = list(train['spoken_languages'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
train['num_languages'] = train['spoken_languages'].apply(lambda x: len(x) if x != {} else 0)
train['all_languages'] = train['spoken_languages'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
top_languages = [m[0] for m in Counter([i for j in list_of_languages for i in j]).most_common(30)]
for g in top_languages:
train['language_' + g] = train['all_languages'].apply(lambda x: 1 if g in x else 0)
test['num_languages'] = test['spoken_languages'].apply(lambda x: len(x) if x != {} else 0)
test['all_languages'] = test['spoken_languages'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
for g in top_languages:
test['language_' + g] = test['all_languages'].apply(lambda x: 1 if g in x else 0)
train = train.drop(['spoken_languages', 'all_languages'], axis=1)
test = test.drop(['spoken_languages', 'all_languages'], axis=1)
# keywords
list_of_keywords = list(train['Keywords'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
train['num_Keywords'] = train['Keywords'].apply(lambda x: len(x) if x != {} else 0)
train['all_Keywords'] = train['Keywords'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
top_keywords = [m[0] for m in Counter([i for j in list_of_keywords for i in j]).most_common(30)]
for g in top_keywords:
train['keyword_' + g] = train['all_Keywords'].apply(lambda x: 1 if g in x else 0)
test['num_Keywords'] = test['Keywords'].apply(lambda x: len(x) if x != {} else 0)
test['all_Keywords'] = test['Keywords'].apply(lambda x: ' '.join(sorted([i['name'] for i in x])) if x != {} else '')
for g in top_keywords:
test['keyword_' + g] = test['all_Keywords'].apply(lambda x: 1 if g in x else 0)
train = train.drop(['Keywords', 'all_Keywords'], axis=1)
test = test.drop(['Keywords', 'all_Keywords'], axis=1)
# cast
list_of_cast_names = list(train['cast'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
list_of_cast_genders = list(train['cast'].apply(lambda x: [i['gender'] for i in x] if x != {} else []).values)
list_of_cast_characters = list(train['cast'].apply(lambda x: [i['character'] for i in x] if x != {} else []).values)
train['num_cast'] = train['cast'].apply(lambda x: len(x) if x != {} else 0)
top_cast_names = [m[0] for m in Counter([i for j in list_of_cast_names for i in j]).most_common(15)]
for g in top_cast_names:
train['cast_name_' + g] = train['cast'].apply(lambda x: 1 if g in str(x) else 0)
train['genders_0_cast'] = train['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
train['genders_1_cast'] = train['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
train['genders_2_cast'] = train['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
top_cast_characters = [m[0] for m in Counter([i for j in list_of_cast_characters for i in j]).most_common(15)]
for g in top_cast_characters:
train['cast_character_' + g] = train['cast'].apply(lambda x: 1 if g in str(x) else 0)
test['num_cast'] = test['cast'].apply(lambda x: len(x) if x != {} else 0)
for g in top_cast_names:
test['cast_name_' + g] = test['cast'].apply(lambda x: 1 if g in str(x) else 0)
test['genders_0_cast'] = test['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
test['genders_1_cast'] = test['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
test['genders_2_cast'] = test['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
for g in top_cast_characters:
test['cast_character_' + g] = test['cast'].apply(lambda x: 1 if g in str(x) else 0)
train = train.drop(['cast'], axis=1)
test = test.drop(['cast'], axis=1)
# crew
list_of_crew_names = list(train['crew'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values)
list_of_crew_jobs = list(train['crew'].apply(lambda x: [i['job'] for i in x] if x != {} else []).values)
list_of_crew_genders = list(train['crew'].apply(lambda x: [i['gender'] for i in x] if x != {} else []).values)
list_of_crew_departments = list(train['crew'].apply(lambda x: [i['department'] for i in x] if x != {} else []).values)
list_of_crew_names = train['crew'].apply(lambda x: [i['name'] for i in x] if x != {} else []).values
train['num_crew'] = train['crew'].apply(lambda x: len(x) if x != {} else 0)
top_crew_names = [m[0] for m in Counter([i for j in list_of_crew_names for i in j]).most_common(15)]
for g in top_crew_names:
train['crew_name_' + g] = train['crew'].apply(lambda x: 1 if g in str(x) else 0)
train['genders_0_crew'] = train['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
train['genders_1_crew'] = train['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
train['genders_2_crew'] = train['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
top_crew_jobs = [m[0] for m in Counter([i for j in list_of_crew_jobs for i in j]).most_common(15)]
for j in top_crew_jobs:
train['jobs_' + j] = train['crew'].apply(lambda x: sum([1 for i in x if i['job'] == j]))
top_crew_departments = [m[0] for m in Counter([i for j in list_of_crew_departments for i in j]).most_common(15)]
for j in top_crew_departments:
train['departments_' + j] = train['crew'].apply(lambda x: sum([1 for i in x if i['department'] == j]))
test['num_crew'] = test['crew'].apply(lambda x: len(x) if x != {} else 0)
for g in top_crew_names:
test['crew_name_' + g] = test['crew'].apply(lambda x: 1 if g in str(x) else 0)
test['genders_0_crew'] = test['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
test['genders_1_crew'] = test['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
test['genders_2_crew'] = test['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
for j in top_crew_jobs:
test['jobs_' + j] = test['crew'].apply(lambda x: sum([1 for i in x if i['job'] == j]))
for j in top_crew_departments:
test['departments_' + j] = test['crew'].apply(lambda x: sum([1 for i in x if i['department'] == j]))
train = train.drop(['crew'], axis=1)
test = test.drop(['crew'], axis=1)
预览一下数据处理完成后的效果:
train.head()
| id | budget | homepage | imdb_id | original_language |
original_title | overview | popularity | poster_path | release_date |
runtime | status | tagline | title | revenue | collection_name |
has_collection | num_genres | all_genres | genre_Drama | genre_Comedy
| genre_Thriller | genre_Action | genre_Romance | genre_Crime |
genre_Adventure | genre_Horror | genre_Science Fiction | genre_Family |
genre_Fantasy | genre_Mystery | genre_Animation | genre_History |
genre_Music | num_companies | production_company_Warner Bros. |
production_company_Universal Pictures | production_company_Paramount
Pictures | production_company_Twentieth Century Fox Film Corporation |
production_company_Columbia Pictures | production_company_Metro-Goldwyn-
Mayer (MGM) | production_company_New Line Cinema |
production_company_Touchstone Pictures | production_company_Walt Disney
Pictures | production_company_Columbia Pictures Corporation |
production_company_TriStar Pictures | production_company_Relativity Media |
production_company_Canal+ | production_company_United Artists |
production_company_Miramax Films | production_company_Village Roadshow
Pictures | production_company_Regency Enterprises | production_company_BBC
Films | production_company_Dune Entertainment | production_company_Working
Title Films | production_company_Fox Searchlight Pictures |
production_company_StudioCanal | production_company_Lionsgate |
production_company_DreamWorks SKG | production_company_Fox 2000 Pictures |
production_company_Summit Entertainment | production_company_Hollywood
Pictures | production_company_Orion Pictures | production_company_Amblin
Entertainment | production_company_Dimension Films | num_countries |
production_country_United States of America | production_country_United
Kingdom | production_country_France | production_country_Germany |
production_country_Canada | production_country_India |
production_country_Italy | production_country_Japan |
production_country_Australia | production_country_Russia |
production_country_Spain | production_country_China |
production_country_Hong Kong | production_country_Ireland |
production_country_Belgium | production_country_South Korea |
production_country_Mexico | production_country_Sweden |
production_country_New Zealand | production_country_Netherlands |
production_country_Czech Republic | production_country_Denmark |
production_country_Brazil | production_country_Luxembourg |
production_country_South Africa | num_languages | language_English |
language_Français | language_Español | language_Deutsch |
language_Pусский | language_Italiano | language_日本語 | language_普通话 |
language_हिन्दी | language_ | language_Português | language_العربية |
language_한국어/조선말 | language_广州话 / 廣州話 | language_தமிழ் | language_Polski
| language_Magyar | language_Latin | language_svenska |
language_ภาษาไทย | language_Český | language_עִבְרִית |
language_ελληνικά | language_Türkçe | language_Dansk |
language_Nederlands | language_فارسی | language_Tiếng Việt |
language_اردو | language_Română | num_Keywords | keyword_woman director
| keyword_independent film | keyword_duringcreditsstinger |
keyword_murder | keyword_based on novel | keyword_violence |
keyword_sport | keyword_biography | keyword_aftercreditsstinger |
keyword_dystopia | keyword_revenge | keyword_friendship | keyword_sex |
keyword_suspense | keyword_sequel | keyword_love | keyword_police |
keyword_teenager | keyword_nudity | keyword_female nudity | keyword_drug
| keyword_prison | keyword_musical | keyword_high school | keyword_los
angeles | keyword_new york | keyword_family | keyword_father son
relationship | keyword_kidnapping | keyword_investigation | num_cast |
cast_name_Samuel L. Jackson | cast_name_Robert De Niro | cast_name_Morgan
Freeman | cast_name_J.K. Simmons | cast_name_Bruce Willis |
cast_name_Liam Neeson | cast_name_Susan Sarandon | cast_name_Bruce McGill
| cast_name_John Turturro | cast_name_Forest Whitaker | cast_name_Willem
Dafoe | cast_name_Bill Murray | cast_name_Owen Wilson |
cast_name_Nicolas Cage | cast_name_Sylvester Stallone | genders_0_cast |
genders_1_cast | genders_2_cast | cast_character_ |
cast_character_Himself | cast_character_Herself | cast_character_Dancer |
cast_character_Additional Voices (voice) | cast_character_Doctor |
cast_character_Reporter | cast_character_Waitress | cast_character_Nurse
| cast_character_Bartender | cast_character_Jack |
cast_character_Debutante | cast_character_Security Guard |
cast_character_Paul | cast_character_Frank | num_crew | crew_name_Avy
Kaufman | crew_name_Robert Rodriguez | crew_name_Deborah Aquila |
crew_name_James Newton Howard | crew_name_Mary Vernieu | crew_name_Steven
Spielberg | crew_name_Luc Besson | crew_name_Jerry Goldsmith |
crew_name_Francine Maisler | crew_name_Tricia Wood | crew_name_James
Horner | crew_name_Kerry Barden | crew_name_Bob Weinstein |
crew_name_Harvey Weinstein | crew_name_Janet Hirshenson | genders_0_crew
| genders_1_crew | genders_2_crew | jobs_Producer | jobs_Executive
Producer | jobs_Director | jobs_Screenplay | jobs_Editor |
jobs_Casting | jobs_Director of Photography | jobs_Original Music Composer
| jobs_Art Direction | jobs_Production Design | jobs_Costume Design |
jobs_Writer | jobs_Set Decoration | jobs_Makeup Artist | jobs_Sound Re-
Recording Mixer | departments_Production | departments_Sound |
departments_Art | departments_Crew | departments_Writing |
departments_Costume & Make-Up | departments_Camera | departments_Directing
| departments_Editing | departments_Visual Effects | departments_Lighting
| departments_Actors
---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---
0 | 1 | 14000000 | NaN | tt2637294 | en | Hot Tub Time Machine 2
| When Lou, who has become the "father of the In… | 6.575393 |
/tQtWuwvMf0hCc2QR2tkolwl7c3c.jpg | 2/20/15 | 93.0 | Released | The
Laws of Space and Time are About to be Vio… | Hot Tub Time Machine 2 |
12314651 | Hot Tub Time Machine Collection | 1 | 1 | Comedy | 0 |
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 |
0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 24 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 6 | 8 | 10 | 1 | 1 | 1 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 72 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 59 | 0 | 13 | 1 | 3 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
1 | 1 | 1 | 1 | 4 | 2 | 9 | 10 | 12 | 4 | 2 | 13 | 8
| 4 | 2 | 4 | 4 | 0
1 | 2 | 40000000 | NaN | tt0368933 | en | The Princess Diaries 2:
Royal Engagement | Mia Thermopolis is now a college graduate and … |
8.248895 | /w9Z7A0GHEhIp7etpj0vyKOeU1Wx.jpg | 8/6/04 | 113.0 |
Released | It can take a lifetime to find true love; she’… | The Princess
Diaries 2: Royal Engagement | 95149435 | The Princess Diaries Collection
| 1 | 4 | Comedy Drama Family Romance | 1 | 1 | 0 | 0 | 1 | 0
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 10 | 10 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 1 | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 4 | 4 | 3
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 4 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0
2 | 3 | 3300000 | http://sonyclassics.com/whiplash/ | tt2582802 | en
| Whiplash | Under the direction of a ruthless instructor, … | 64.299990
| /lIv1QinFqz4dlp5U4lQ6HaiskOZ.jpg | 10/10/14 | 105.0 | Released |
The road to greatness can take you to the edge. | Whiplash | 13092000 |
0 | 0 | 1 | Drama | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 51 | 0 | 0 | 0 | 1
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 31 | 7
| 13 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0
| 0 | 1 | 1 | 64 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 49 | 4 | 11 | 4 | 4 | 1 | 1
| 1 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 2 | 18 | 9
| 5 | 9 | 1 | 5 | 4 | 3 | 6 | 3 | 1 | 0
3 | 4 | 1200000 | http://kahaanithefilm.com/ | tt1821480 | hi |
Kahaani | Vidya Bagchi (Vidya Balan) arrives in Kolkata … | 3.174936 |
/aTXRaPrWSinhcmCrcfJK17urp3F.jpg | 3/9/12 | 122.0 | Released | NaN |
Kahaani | 16000000 | 0 | 0 | 2 | Drama Thriller | 1 | 0 | 1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 4 | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
0 | 0 | 0
4 | 5 | 0 | NaN | tt1380152 | ko | 마린보이 | Marine Boy is the
story of a former national s… | 1.148070 |
/m22s7zvkVFDU9ir56PiiqIEWFdT.jpg | 2/5/09 | 118.0 | Released | NaN |
Marine Boy | 3923970 | 0 | 0 | 2 | Action Thriller | 0 | 0 | 1
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0
| 0 | 0 | 0
达到预期的效果,但是日期还是字符串格式,再转化一下日期为标准格式:
def fix_date(x):
"""
Fixes dates which are in 20xx
"""
year = x.split('/')[2]
if int(year) <= 19:
return x[:-2] + '20' + year
else:
return x[:-2] + '19' + year
test.loc[test['release_date'].isnull() == True, 'release_date'] = '01/01/98'
train['release_date'] = train['release_date'].apply(lambda x: fix_date(x))
test['release_date'] = test['release_date'].apply(lambda x: fix_date(x))
train['release_date'] = pd.to_datetime(train['release_date'])
test['release_date'] = pd.to_datetime(test['release_date'])
数据探索性分析
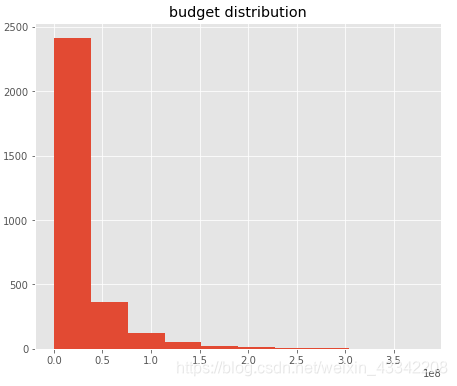
首先看一下预算的分布情况,发现大部分值比较小,数据不平衡,应做log处理,增加数值较小时的区分度:
plt.hist(train['budget'])
plt.title('budget distribution')
plt.hist(np.log1p(train['budget']))
plt.title('log1p budget distribution')
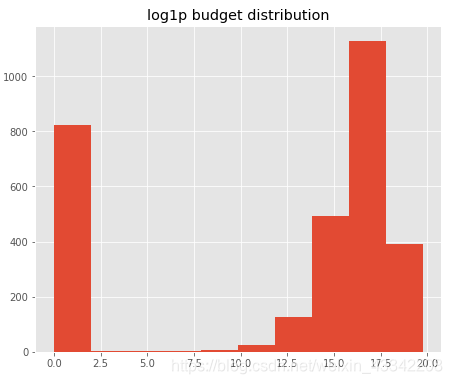
显然收入revenue也一样处理:
# log_budget, Normalization
train['log_budget'] = np.log1p(train['budget'])
test['log_budget'] = np.log1p(test['budget'])
# log_revenue, Normalization
train['log_revenue'] = np.log1p(train['revenue'])
再看下homepage,这里把homepage转换成布尔值,有homepage的也是有实力的象征:
train['has_homepage'] = 0
train.loc[train['homepage'].isnull() == False, 'has_homepage'] = 1
test['has_homepage'] = 0
test.loc[test['homepage'].isnull() == False, 'has_homepage'] = 1
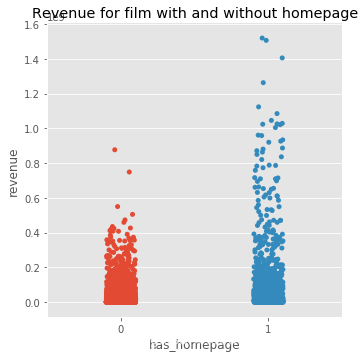
是否有主页的分布情况,有主页的票房更高:
sns.catplot(x='has_homepage', y='revenue', data=train);
plt.title('Revenue for film with and without homepage');
各个语言的票房收入情况:
sns.boxplot(x='original_language',y='log_revenue',
data=train.loc[train['original_language'].isin(train['original_language'].value_counts().head(10).index)])
plt.title("Log_Revenue VS Original_language")
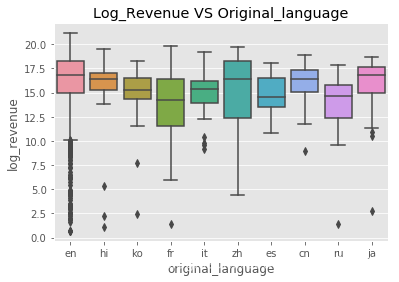
英语好片很多,烂片也很多,其他语言也有好的电影,总体差别不大。
overview列,涉及到文本信息挖掘,这里简单结合常用的Tfidf和线性回归进行建模,如下:()
vectorizer=TfidfVectorizer(sublinear_tf=True,analyzer='word',token_pattern=r'\w{1,}',ngram_range=(1,2),min_df=5)
overview_text=vectorizer.fit_transform(train['overview'].fillna(''))
linreg=LinearRegression()
linreg.fit(overview_text,train['log_revenue'])
使用eli5可视化各关键字对log_revenue的影响:
import eli5
print('Target value:', train['log_revenue'][5])
eli5.show_prediction(linreg,doc=train['overview'][5],vec=vectorizer)

日期特征比较粗糙,增加星期几、月份、季度、年份等特征:
def process_date(df):
date_parts=['year','weekday','month','weekofyear','day','quarter']
for part in date_parts:
df["release_date_"+part]=getattr(df["release_date"].dt,part).astype(int)
return df
train=process_date(train)
test=process_date(test)
先看下每年电影的发行量:这里用可交互式的可视化工具plotly
d1=train['release_date_year'].value_counts().sort_index()
d2=test['release_date_year'].value_counts().sort_index()
py.init_notebook_mode(connected=True)
data=[go.Scatter(x=d1.index,y=d1.values,name='train'),go.Scatter(x=d2.index,y=d2.values,name='test')]
layout=go.Layout(dict(title='Number of films per year',xaxis=dict(title='year'),yaxis=dict(title='Count')),legend=dict(orientation='v'))
py.iplot(dict(data=data,layout=layout))

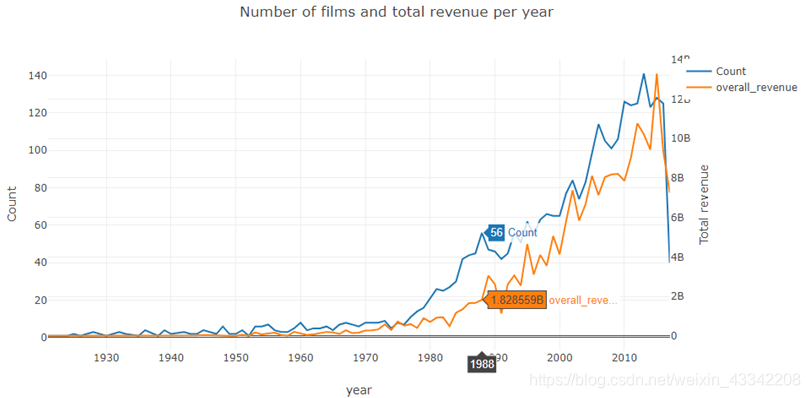
总发行量与总票房的趋势:
d1=train['release_date_year'].value_counts().sort_index()
d2=train.groupby(['release_date_year'])['revenue'].sum()
data=[go.Scatter(x=d1.index,y=d1.values,name='Count'),go.Scatter(x=d2.index,y=d2.values,name='overall_revenue',yaxis='y2')]
layout=go.Layout(dict(title= "Number of films and total revenue per year",xaxis=dict(title='year'),yaxis=dict(title='Count'),yaxis2=dict(title='Total revenue', overlaying='y', side='right')),
legend=dict(orientation='v'))
py.iplot(dict(data=data,layout=layout))
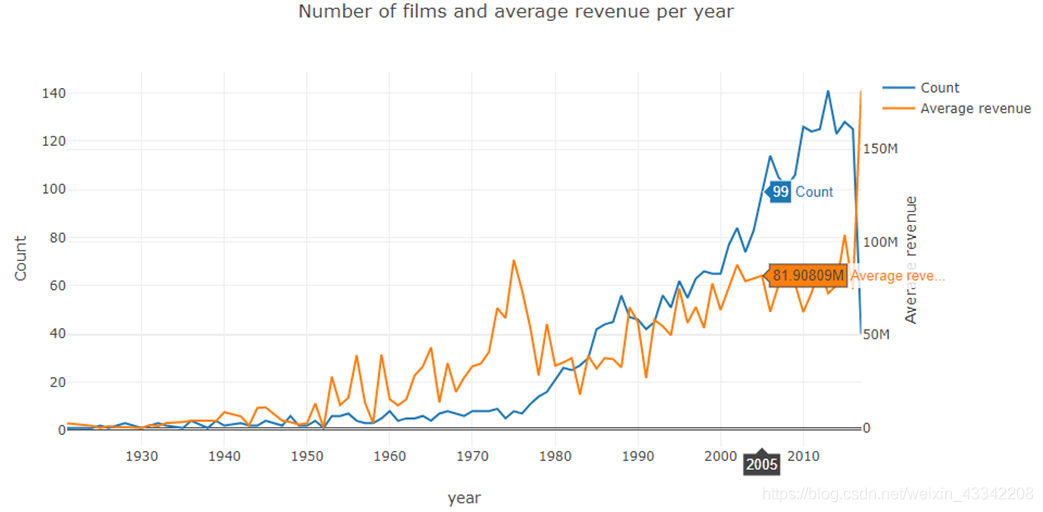
总发行量与平均票房的趋势:(似乎平均票房在2000之后趋于稳定)
d1=train['release_date_year'].value_counts().sort_index()
d2=train.groupby(['release_date_year'])['revenue'].mean()
data=[go.Scatter(x=d1.index,y=d1.values,name='Count'),go.Scatter(x=d2.index,y=d2.values,name='Average revenue',yaxis='y2')]
layout=go.Layout(dict(title="Number of films and average revenue per year",xaxis=dict(title='year'),yaxis=dict(title='Count'),
yaxis2=dict(title='Average revenue',overlaying='y',side='right')),legend=dict(orientation='v'))
py.iplot(dict(data=data,layout=layout))
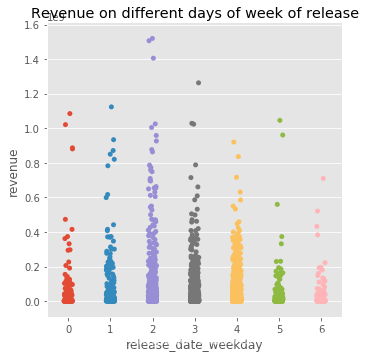
周几发行是否与票房有关:
sns.catplot(x='release_date_weekday',y='revenue',data=train)
plt.title('Revenue on different days of week of release')
再看下箱线图:
sns.boxplot(x='release_date_weekday',y='log_revenue',data=train)
plt.title('Revenue on different days of week of release')
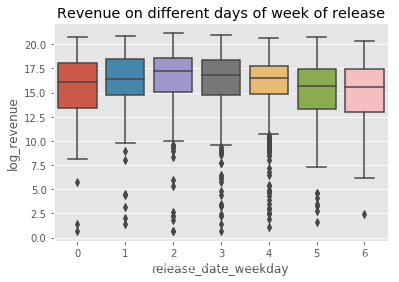
发现:周一到周三发布的电影很多是高票房的,周六发行的电影票房就很低了。
电影介绍tagline分析,分析出现频率最高的词汇:
plt.figure(figsize = (12, 12))
text_tagline=' '.join(train['tagline'].fillna(''))
wordcloud_tagline=WordCloud(max_font_size=None,background_color='white',width=1200,height=1000).generate_from_text(text_tagline)
plt.imshow(wordcloud_tagline)
plt.title('Top words in tagline')
plt.axis("off")
plt.show()

是否有系列has_collection对票房的影响:
sns.boxplot(x='has_collection',y='log_revenue',data=train)
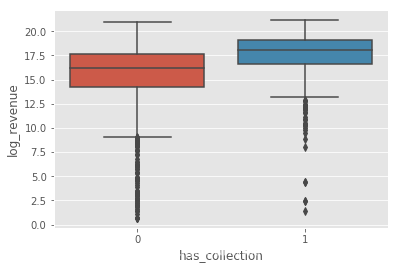
发现系列电影的平均票房更高。
分析电影题材数量与票房的关系:
train['num_genres'].value_counts()
sns.catplot(x='num_genres',y='revenue',data=train)
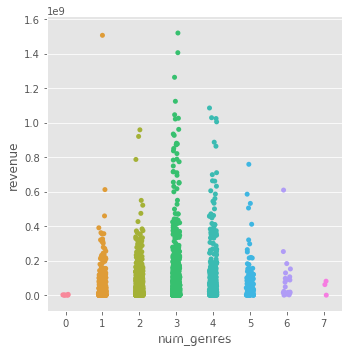
题材数量3个往往有更高的票房,数量多了反而不好。
最后看下电影发行方与票房的关系,分别绘制分布图:
f,axes=plt.subplots(6,5,figsize=(24,32))
plt.suptitle('Violin of revenue vs production company')
for i,e in enumerate([i for i in train.columns if 'production_company_' in i]):
sns.violinplot(x=e,y='revenue',data=train,ax=axes[i//5][i%5])

建模
先删除一些无关的特征:
train = train.drop(['homepage', 'imdb_id', 'poster_path', 'release_date', 'status', 'log_revenue'], axis=1)
test = test.drop(['homepage', 'imdb_id', 'poster_path', 'release_date', 'status'], axis=1)
再删除特征值唯一的特征:
for col in train.columns:
if train[col].nunique()==1:
print(col)
train.drop([col],axis=1)
train.drop([col],axis=1)
对分类标签进行编码:
for col in ['original_language','collection_name','all_genres']:
le=LabelEncoder()
le.fit(list(train[col].fillna(''))+list(test[col].fillna('')))
train[col]=le.transform(train[col].fillna('').astype(str))
test[col]=le.transform(test[col].fillna('').astype(str))
将文本转化成特征:
train_texts = train[['title', 'tagline', 'overview', 'original_title']]
test_texts = test[['title', 'tagline', 'overview', 'original_title']]
for col in ['title','tagline','overview','original_title']:
train['len_'+col]=train[col].fillna('').apply(lambda x: len(str(x)))
train['words_'+col]=train[col].fillna('').apply(lambda x: len(str(x).split(' ')))
test['len_'+col]=test[col].fillna('').apply(lambda x: len(str(x)))
test['words_'+col]=test[col].fillna('').apply(lambda x: len(str(x).split(' ')))
train=train.drop(col,axis=1)
test=test.drop(col,axis=1)
训练数据和测试数据:
X=train.drop(['id','revenue'],axis=1)
y=np.log1p(train['revenue'])
X_test=test.drop(['id'],axis=1)
模型训练:
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.1)
# rmse: root mean square error, (sum(d^2)/N)^0.5
params = {'num_leaves': 30,
'min_data_in_leaf': 20,
'objective': 'regression',
'max_depth': 5,
'learning_rate': 0.01,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9,
"bagging_seed": 11,
"metric": 'rmse',
"lambda_l1": 0.2,
"verbosity": -1}
model1=lgb.LGBMRegressor(**params,n_estimators=20000,nthread=4,jobs=-1)
model1.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)], eval_metric='rmse',verbose=1000, early_stopping_rounds=200)
Training until validation scores don’t improve for 200 rounds.
[1000] training’s rmse: 1.42756 valid_1’s rmse: 2.07259
Early stopping, best iteration is:
[1118] training’s rmse: 1.38621 valid_1’s rmse: 2.06726
训练后,各特征权重:
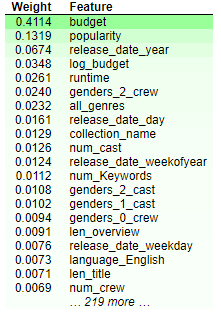


 浙公网安备 33010602011771号
浙公网安备 33010602011771号