
为何HPA在滚动时扩容出了多余的Pod?
1.背景
在给线上环境的Pod增加HPA时,HPA通过云效的YAML模板自动部署,因此每次更新时,Pod会自动获得HPA能力。
线上如以下配置:
- 最小副本设置为1,最大副本为10;
- 扩容阈值设置为CPU和内存的75%;
- request CPU为1C、内存为1G;
但在发布过程中,Pod 副本从 1 突然增加到 2,尽管此时 CPU 使用率不到 0.1%,内存使用率稳定在 35% 左右。我们对以下可能的原因进行了排查,均未发现异常:
1.内存指标基准值:已确认未混淆请求(Request)与限制(Limit)。
2.指标类型配置:未误用 AverageUtilization 与 AverageValue,配置正确。
3.发布时资源波动:发布过程中未出现瞬时资源峰值,未触发扩容阈值。
4.历史资源使用情况:历史监控数据显示使用率始终未超过 40%。
综上,目前尚未发现引起异常扩容的直接原因。
2.问题解决
该问题此前未被重点关注,经阿里云排查后确认,属 HPA 在缺乏监控数据时采用保守补零策略,在滚动发布过程中误判负载,从而过度扩容(多弹)。
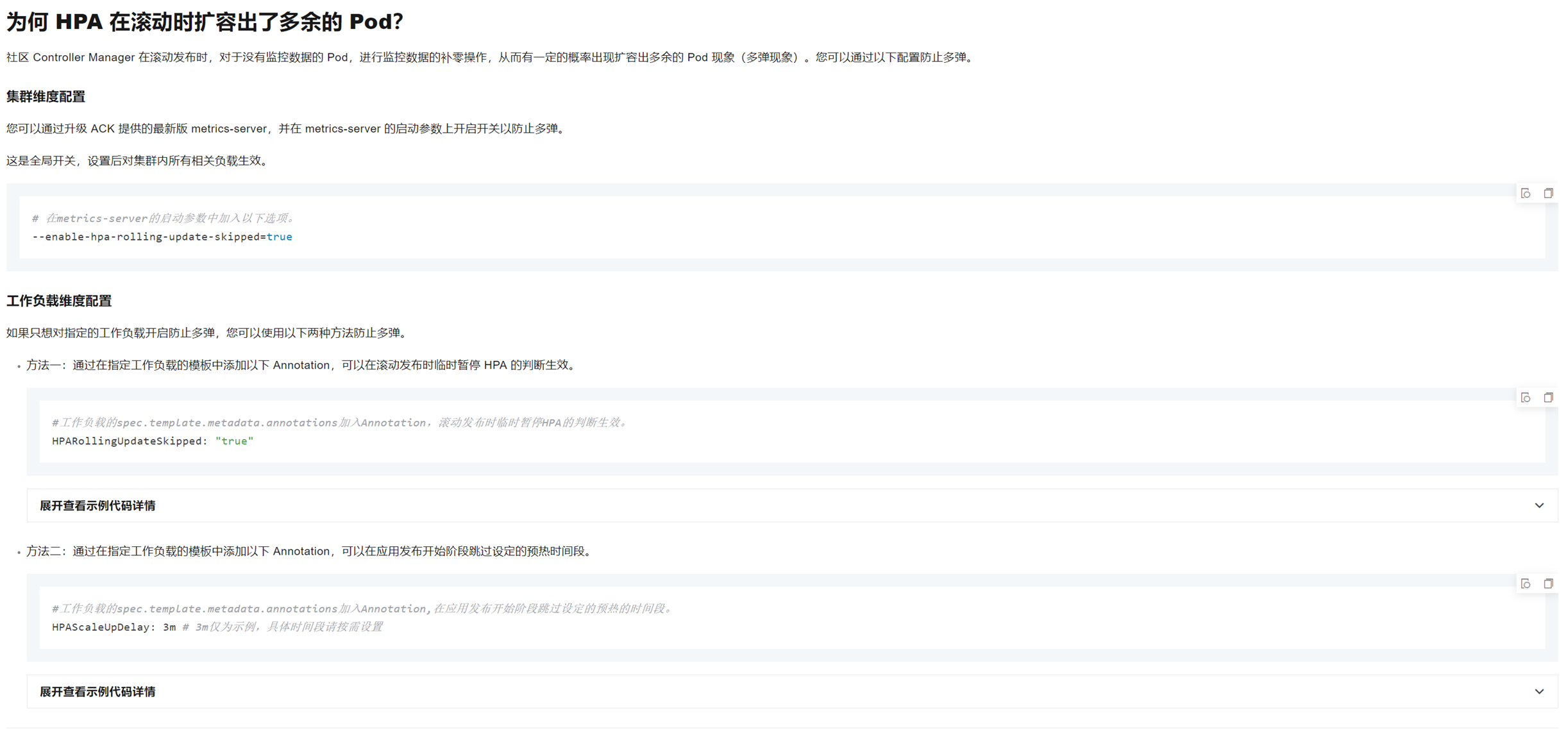
解决方案说明:
我们选择**“工作负载维度配置”**的方式来规避问题,而非调整全局参数(便于通过云效模版控制,避免影响其他服务)。
方法一:HPARollingUpdateSkipped: "true"
- 作用:在滚动更新期间临时暂停 HPA 判断逻辑
- 行为:HPA 不进行任何扩缩容操作
- 效果:等待发布完成后,HPA 再恢复正常工作,避免“多弹”现象
方法二:HPAScaleUpDelay: "3m"
- 作用:为新 Pod 设置预热时间
- 行为:在前 3 分钟内,不将新 Pod 的指标纳入 HPA 判断
- 背景问题:
- 新 Pod 启动初期尚无可用指标
- 控制器将其指标视为“0%”,导致平均值被拉低
- HPA 误判负载高,从而提前扩容(多弹)
可以两种方法可配合使用 —— 在滚动过程中暂停判断(HPARollingUpdateSkipped),并为新 Pod 设置合理的预热窗口(HPAScaleUpDelay),以避免因指标缺失导致的错误扩容。
3.具体原理
3.1 什么是“没有监控数据”?
在滚动发布(rolling update) 的过程中,新版本的 Pod 会逐个替换旧版本的 Pod。而新启动的 Pod 由于刚启动不久,还没有进入就绪状态或者 Metrics Server 还未采集到它的资源使用数据(比如 CPU、内存)。这时候,这个 Pod 被认为是“没有监控数据”。
3.2 为什么要“补零”?
这是 HPA 的一种保守策略。在无法获取监控数据的情况下,HPA 面临两种选择:
1.跳过这个 Pod,不参与平均值计算:这样做可能会导致误判,比如系统实际负载升高了,但因为新 Pod 没数据而被忽略。
2.假设这个 Pod 使用为 0(补零):即将这个 Pod 视为“资源完全空闲”,也就是认为它的 CPU 或内存使用率是 0%。
Kubernetes 社区的 HPA 控制器采用的是第 2 种方式(补零),原因如下:
- 避免错过扩容:如果真实负载很高,新 Pod 没有数据被跳过了,HPA 可能会低估整体使用率,不扩容,从而服务性能可能受到影响。
- 安全优先:宁可多扩几个 Pod,也不要资源不够导致服务崩溃。
3.3 补零的副作用:为什么会“多弹”?
这种“补零”机制虽然出于安全考虑,但也带来副作用:
- 新 Pod 没数据 → 被当成 0% 使用率 → 拉低整个 Deployment 的平均使用率。
- HPA 认为整体平均值 < 目标值(例如低于 75%) → 判定为“该扩容” → 扩容新 Pod。
- 然后这些新 Pod 也因为刚启动没数据,又被补零 → 再次触发扩容……
于是形成了“连锁反应”,导致短时间内扩容了多个 Pod,这就叫“多弹现象”。
举个例子更清楚:
假设你有一个 Deployment,当前有 4 个 Pod,CPU 利用率都在 75% 附近。现在触发滚动更新,系统逐个替换 Pod。
滚动更新时,一些新 Pod 还没准备好,这些 Pod 会:
- 没有 metrics;
- 被算作 0% 使用率。
于是:
- 当前 Pod 数 = 4;
- 有两个还没准备好的新 Pod;
- 实际参与平均计算的就变成了:
(75 + 75 + 0 + 0) / 4 = 37.5%
这比目标 75% 要低太多了,HPA 认为负载不够,就触发扩容,于是就“多弹”出了几个 Pod。
3.4 如何解决这个问题?
有些平台或云厂商(比如阿里云)提供了解决方案,比如:
- 设置 Annotation 临时暂停 HPA 判断;(本文档解决方案使用的就是这种)
- 延迟 HPA 对新 Pod 的评估(通过设置预热时间);
- 关闭补零机制(如果平台支持)。
但是其他云们目前还未调研,但是搜索资料得到以下信息:
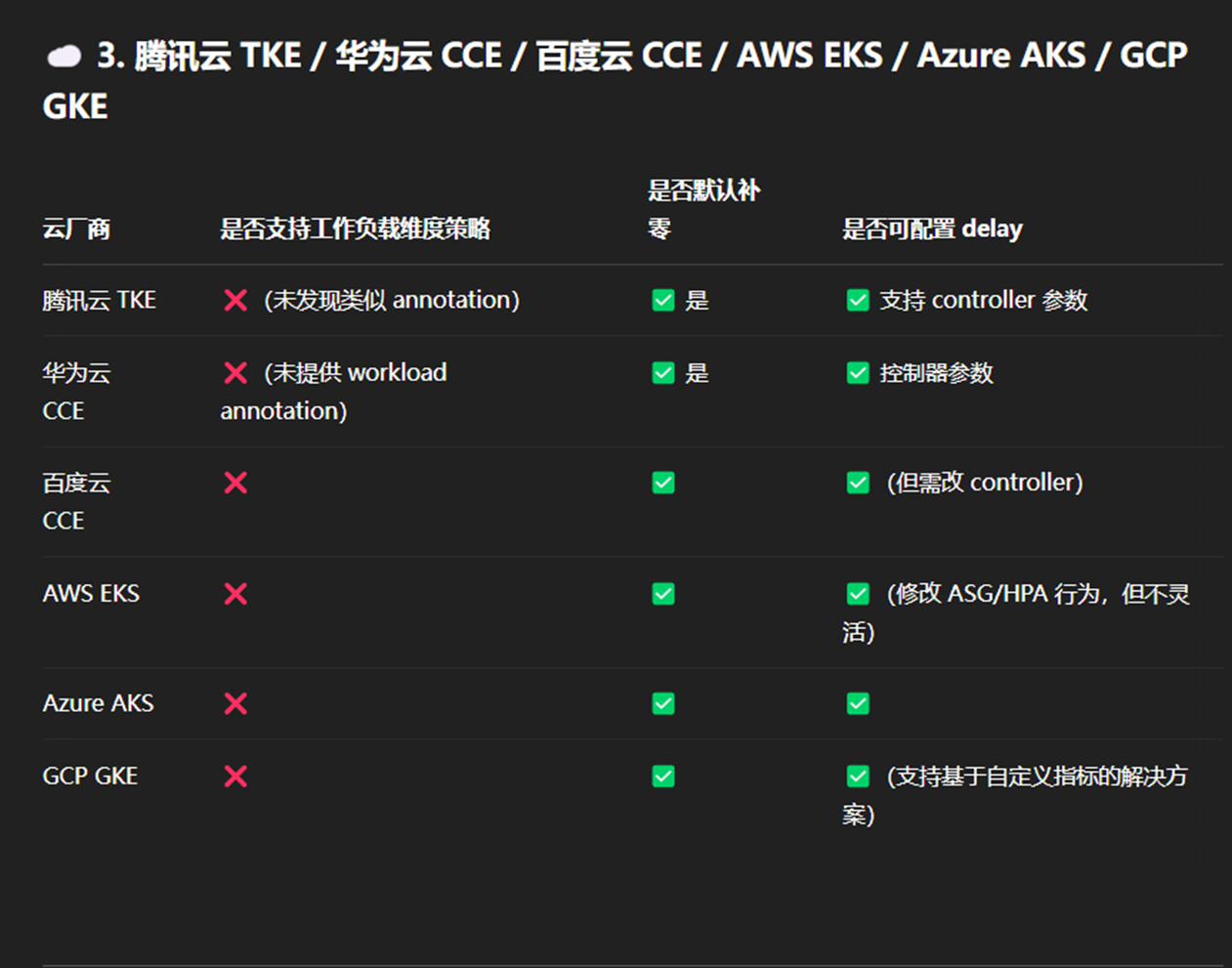
3.4.1 其他云(Amazon EKS / GKE / AKS)
这些平台基本使用 Kubernetes 原生 HPA 控制器,也存在“补零”导致的多弹问题。
解决手段一般为:
- 使用 KEDA 替代原生 HPA,支持更细粒度的触发逻辑;
- 搭配使用 --horizontal-pod-autoscaler-initial-readiness-delay 和 --horizontal-pod-autoscaler-cpu-initialization-period;
- 限制 HPA 行为的频率:配置 behavior.scaleUp.stabilizationWindowSeconds 和 behavior.scaleDown.stabilizationWindowSeconds。
但没有像阿里云那样的滚动发布期间的 Annotation 暂停能力。
总结
目前仅阿里云 ACK 提供了工作负载级别的 annotation 方式,解决滚动更新导致的“多弹”问题。
其他云厂商基本只能通过全局 controller 参数调整,修改成本高,风险较大。
若你在使用阿里云 ACK,优先推荐使用 annotation 控制策略,既灵活又安全。
3.4.2 KEDA(可选替代方案)
- 事件驱动自动扩缩容框架
- 支持更多维度的扩缩容:如 Kafka、消息队列、数据库队列长度等;
- 更灵活,可自定义触发条件、冷却时间、缩放行为;
- 避免了 HPA 传统 CPU/内存模型下的补零问题。
3.5 总结一句话
“补零”是为了在没有监控数据时保守估算资源使用情况,确保服务不因负载过高而不可用,但这种机制也可能引起不必要的扩容(多弹),尤其是在滚动发布过程中。
3.6 补充参数(可无视)

4.参考链接
k8s工作负载伸缩FAQ及对应的解决方案_容器服务 Kubernetes 版 ACK(ACK)-阿里云帮助中心 (aliyun.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号