
day50-正则表达式01
正则表达式01
5.1正则表达式的作用
正则表达式的便利
在一篇文章中,想要提取相应的字符,比如提取文章中的所有英文单词,提取文章中的所有数字等。
- 传统方法是:使用遍历的方式,对文本中的每一个字符进行ASCII码的对比,如果ASCII码处于英文字符的范围,就将其截取下来,再看后面是否有连续的字符,将连续的字符拼接成一个单词。这种方式代码量大,且效率不高。
- 使用正则表达式
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//体验正则表达式的便利
public class Regexp_ {
public static void main(String[] args) {
//假设有如下文本
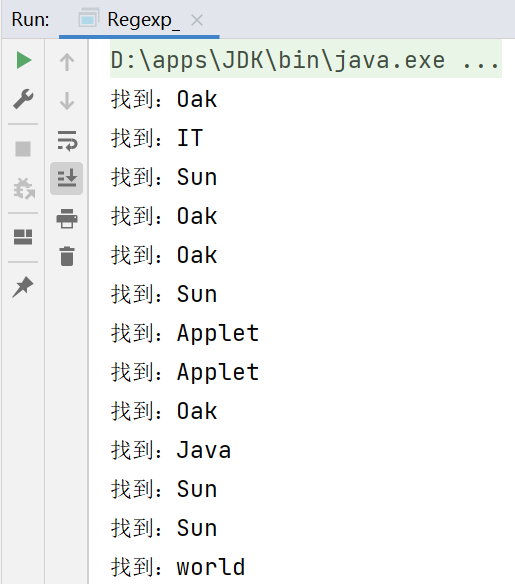
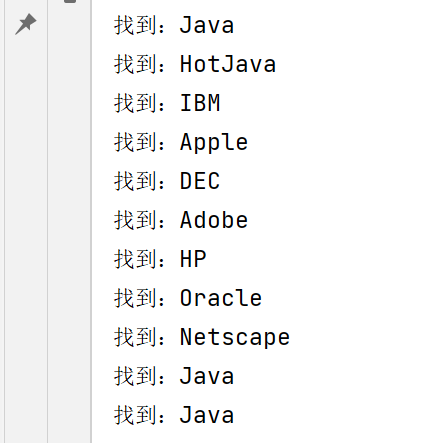
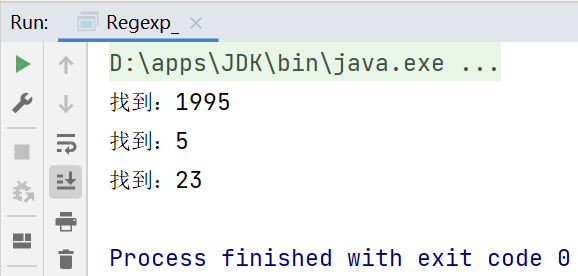
String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来," +
"急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企" +
"业为此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且" +
"重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常" +
"小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公" +
"司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网" +
"页中进行执行的技术),并将Oak更名为Java。5月23日,Sun公司在Sun world会议上正式发布Java和" +
"HotJava浏览器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微软等各大公司都纷纷停止" +
"了自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产品开发了相应的Java平台。";
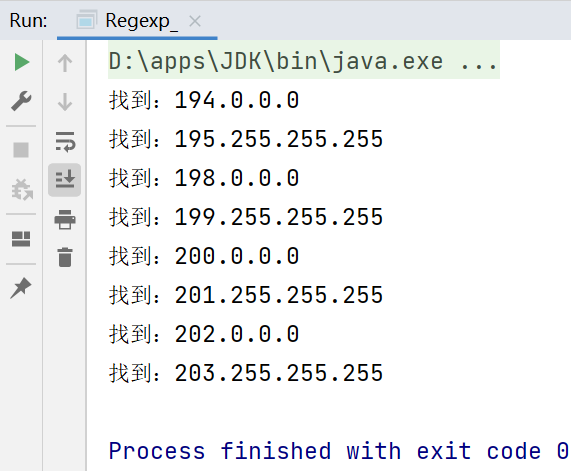
String content2 = "无类域间路由(CIDR,Classless Inter-Domain Routing)地址根据网络拓扑来分配,可以" +
"将连续的一组网络地址分配给一家公司,并使整组地址作为一个网络地址(比如使用超网技术),在外部路由表上" +
"只有一个路由表项。这样既解决了地址匮乏问题,又解决了路由表膨胀的问题。另外,CIDR还将整个世界分为四" +
"个地区,给每个地区分配了一段连续的C类地址,分别是:欧洲(194.0.0.0~195.255.255.255)、北美(19" +
"8.0.0.0~199.255.255.255)、中南美(200.0.0.0~201.255.255.255)和亚太(202.0.0.0~203.2" +
"55.255.255)。这样,当一个亚太地区以外的路由器收到前8位为202或203的数据报时,它只需要将其放到通向亚" +
"太地区的路由即可,而对后24位的路由则可以在数据报到达亚太地区后再进行处理,这样就大大缓解了路由表膨胀的问题";
//正则表达式来完成
// (1)先创建一个Pattern对象,模式对象,可以理解成就是一个正则表达式对象
//Pattern pattern = Pattern.compile("[a-zA-Z]+");//提取文章中的所有英文单词
//Pattern pattern = Pattern.compile("[0-9]+");//提取文章中的所有数字
//Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");//提取文章中的所有的英文单词和数字
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");//提取文章中的ip地址
// (2)创建一个匹配器对象
// 理解:就是 matcher 匹配器按照pattern(模式/样式),到content文本中去匹配
// 找到就返回true,否则就返回false(如果返回false就不再匹配了)
Matcher matcher = pattern.matcher(content2);
// (3)可以开始循环匹配
while (matcher.find()) {
//匹配到的内容和文本,放到 m.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
提取所有英文单词:
提取所有数字:
提取ip地址:
正则表达式是处理文本的利器
- 再提出几个问题
- 在程序中如何验证用户输入的邮件信息是否符合电子邮件的格式?
- 如何验证输入的电话号码是符合手机号格式?
为了解决上述问题,java提供了正则表达式技术(regular expression / regexp),专门用于处理类似的文本问题。简单地说,正则表达式是对字符串执行 模式匹配 的技术。
5.2基本介绍
- 介绍
-
一个正则表达式,就是用某种模式去匹配字符串的一个公式。
它们看上去奇怪而复杂,但经过练习后,你就会发现这些复杂的表达式写起来还是相当简单的。而且,一旦弄懂它们,就能将数小时辛苦而且容易出错的文本处理工作缩短在几分钟甚至几秒内完成。
-
正则表达式不是java独有的,实际上很多编程语言都支持正则表达式进行字符串操作,且它们的匹配规则大同小异。
5.3底层实现
实例分析:
给出一段字符串文本,请找出所有四个数字连在一起的子串===>分析底层实现
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//分析java的正则表达式的底层实现**
public class RegTheory {
public static void main(String[] args) {
String content="1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月,Sun公司发布了" +
"第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平台的微型" +
"版),应用于移动、无线9889+及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的" +
"标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应" +
"用于基于Java的应用服务器。Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着J" +
"ava的应用开始普及。3443";
//请找出所有四个数字连在一起的子串
//说明:
// 1.\\d表示一个任意的数字
String regStr="\\d\\d\\d\\d";
//2.创建一个模式对象
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:创建匹配器matcher,按照前面写的 正则表达式的规则 去匹配 content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()){
System.out.println("匹配:"+matcher.group(0));
}
}
}
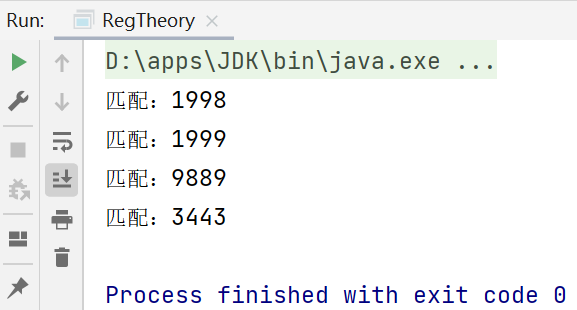
5.3.1match.find()
- match.find()完成的任务:
-
根据指定的规则,定位满足规则的子字符串(比如1998)
-
找到后,将"1998"子字符串开始的索引记录到 matcher对象的属性 int[] groups数组中的groups[0];把该子串的结束索引再+1的值记录到 groups[1]
此时groups[0]=0,groups[1]=4
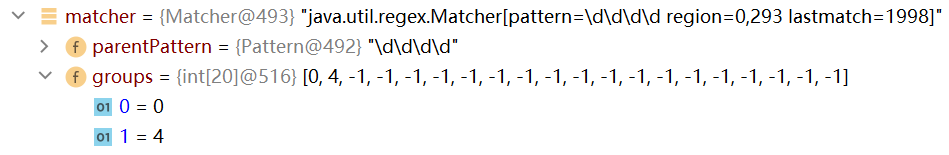
-
同时记录oldLast的值为 子串的结束索引+1 即4,这样做的原因是:下次执行find方法时,就从该下标4开始匹配

5.3.2matcher.group(0)
//源码:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
根据传入的参数group=0,计算groups[0 * 2] 和 groups[0 * 2 + 1] 的记录的位置,从content截取子字符串返回
此时groups[0]=0,groups[1]=4,注意:截取的位置为[0,4) ,包含 0 但是不包含索引为 4 的位置
-
如果再次指向find方法,仍然按照上面的分析去执行:
比如下一个匹配的子字符串是“1999”,首先,将该字符串的开始索引的值,以及结束索引加1的值记录到matcher属性的groups数组中(会先将上次存储在groups数组中的数值清空)
然后记录oldLast的值为 子串的结束索引+1,下次执行find方法时,就从该下标35开始匹配
groups[0]=31,groups[1]=35,oldLsat=35
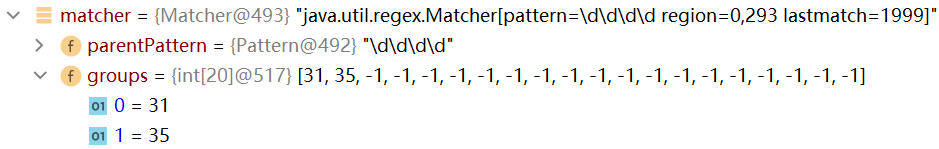
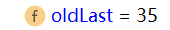
然后执行matcher.group(0)方法,根据传入的参数group=0,计算groups[0 * 2] 和 groups[0 * 2 + 1] 的记录的位置,即[31,35),从content截取子字符串返回
5.3.3分组
什么是分组?
在正则表达式中有括号(),表示分组,第一个括号()表示第一组,第二个括号()表示第二组....
实例代码:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//分析java的正则表达式的底层实现**
public class RegTheory {
public static void main(String[] args) {
String content="1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月,Sun公司发布了" +
"第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平台的微型" +
"版),应用于移动、无线及9889有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的" +
"标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应" +
"用于基于Java的应用服务器。Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着J" +
"ava的应用开始普及。3443";
//请找出所有四个数字连在一起的子串
//说明:
// 1.\\d表示一个任意的数字
String regStr="(\\d\\d)(\\d\\d)";
//2.创建一个模式对象
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:创建匹配器matcher,按照前面写的 正则表达式的规则 去匹配 content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
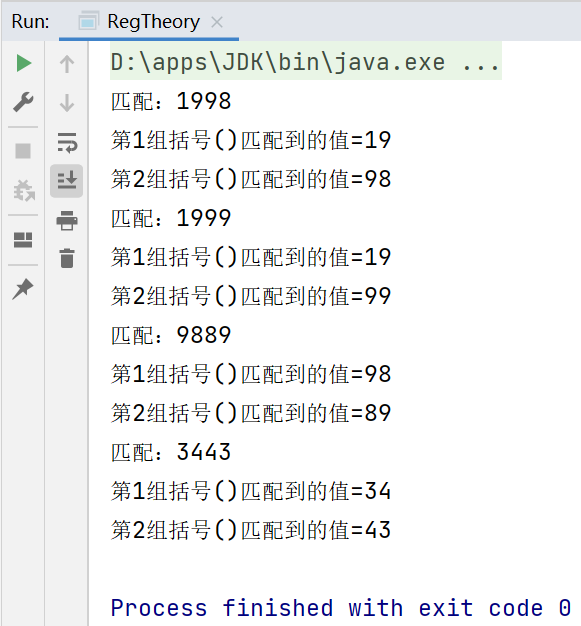
while (matcher.find()){
System.out.println("匹配:"+matcher.group(0));
System.out.println("第1组括号()匹配到的值="+matcher.group(1));
System.out.println("第2组括号()匹配到的值="+matcher.group(2));
}
}
}
以上面的代码为例:
- match.find():
1.根据指定的规则,定位满足规则的子字符串(比如"1998")
2.1找到后,将"1998"子字符串开始的索引位置记录到 matcher对象的属性 int[] groups数组中,把该子串的结束索引+1的值记录到 groups[1] 中
此时 groups[0]=0 ;groups[1] = 4
2.2 记录第一组括号()匹配到的字符串("19")的位置 : groups[2]=0 , groups[3]=2
2.3 记录第二组括号()匹配到的字符串("98")的位置 : groups[4]=2 , groups[5]=4
如果有更多的分组就以此类推
索引下标是指:匹配的字符串在整文本或字符串中的位置,索引下标从0开始
验证:
在程序中打上断点,点击debug调试:

可以看到刚开始时,groups数组的所有值都是-1
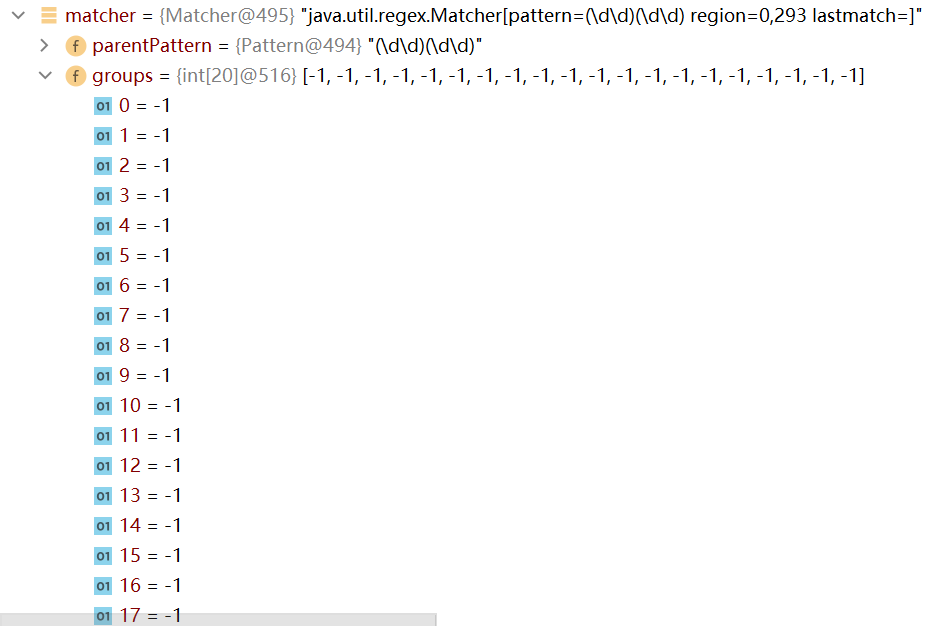
点击step over,可以看到groups数组的变化如下:

//源码:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
在源码中,返回语句 return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
中,[group * 2] 和 [group * 2 + 1]计算的就是groups数组的下标位置
如果我们想要取出第一组括号匹配的子字符串,即groups下标为[2]和[3],只需要将传入的参数改为1即可
groups[1 * 2]=groups[2] , groups[1 * 2 + 1]=groups[3]
取出第二组括号匹配的字符串同理,将传入的参数改为2即可
groups[2 * 2]=groups[4] , groups[2 * 2 + 1]=groups[5]
小结:
- 如果正则表达式有括号(),即分组
- 取出匹配的字符串规则如下:
matcher.group(0)表示匹配到的子字符串matcher.group(1)表示匹配到的子字符串的第1组字串matcher.group(2)表示匹配到的子字符串的第2组字串- 以此类推,注意分组的数不能越界
5.4正则表达式语法
-
基本介绍
如果想要灵活地运用正则表达式,必须了解其中各种元字符(Metacharacter)的功能,元字符从功能上大致分为:
- 限定符
- 选择匹配符
- 分组组合和反向引用符
- 特殊字符
- 字符匹配符
- 定位符
5.4.1元字符-转义符 \\\
\\符号的说明:在我们使用正则表达式去检索某些特殊字符时,需要用到转义符号\\,否则检索不到结果,甚至会报错。
注意:在Java的正则表达式中,两个\\表示其他语言中的一个\
需要用到转义符号的字符有如下:
. * + () $ / \ ? [] ^ {}
例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示转义字符的使用
public class RegExp02 {
public static void main(String[] args) {
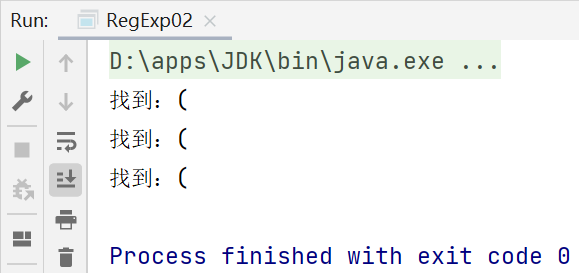
String content = "abc$(a.bc(123(";
//匹配 ( ==> \\(
//匹配 ( ==> \\.
//String regStr = "\\(";
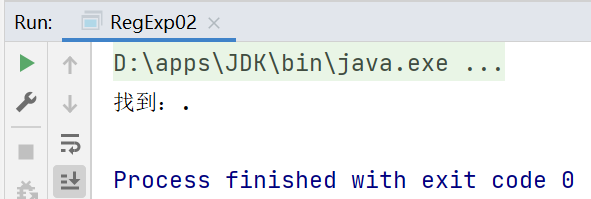
String regStr = "\\.";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
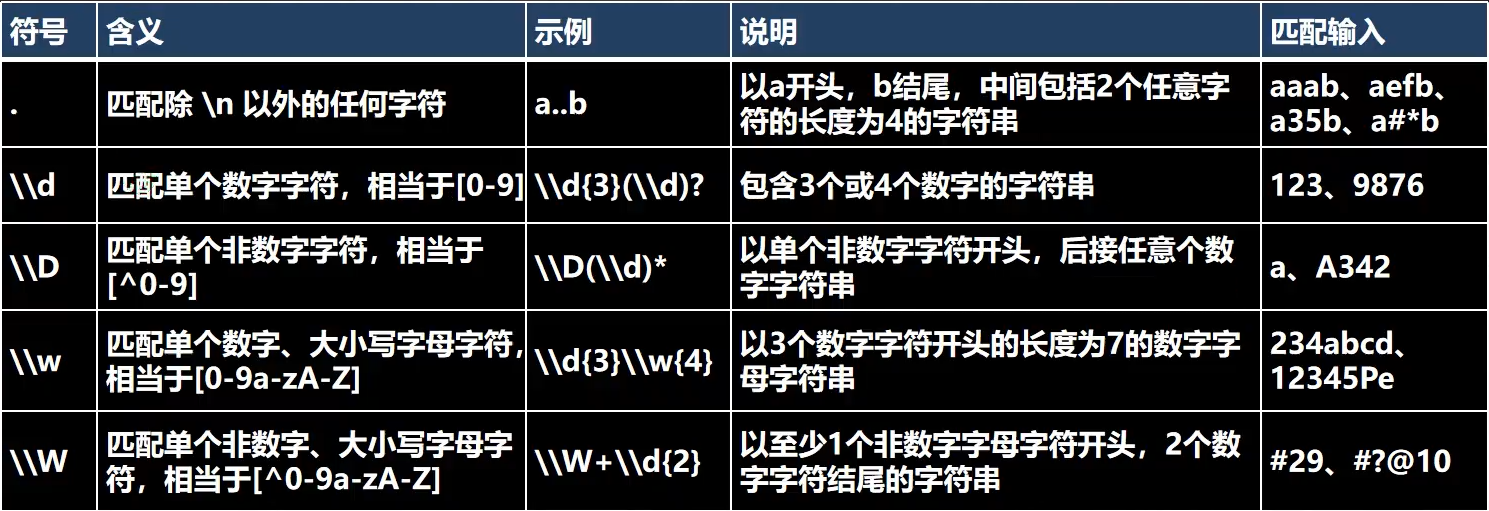
5.4.2元字符-字符匹配符

- 应用实例
-
[a-z]说明:[a-z]表示可以匹配 a-z 之间任意的一个字符[A-Z]表示可以匹配 A-Z 之间任意的一个字符[0-9]表示可以匹配 0-9 之间任意的一个字符比如[a-z]、[A-Z]去匹配“a11c8”会得到什么结果?结果是:a、c
-
java正则表达式默认是区分大小写的,如何实现不区分大小写?
(?i)abc表示abc都不区分大小写a(?i)bc表示bc不区分大小写a((?i)b)c表示只有b不区分大小写Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
-
[^a-z]说明:[^a-z]表示可以匹配不是a-z中的任意一个字符[^A-Z]表示可以匹配不是A-Z中的任意一个字符[^0-9]表示可以匹配不是0-1中的任意一个字符如果用 [^a-z]去匹配“a11c8”会得到什么结果?结果:1、1、8
用 [^a-z]{2}又会得到什么结果?结果是:11
-
[abcd]表示可以匹配abcd中的任意一个字符 -
[^abcd]表示可以匹配不是abcd中的任意一个字符 -
\\d表示可以匹配0-9的任意一个数字,相当于[0-9] -
\\D表示可以匹配不是0-9的任意一个数字,相当于[^0-9],即匹配非数字字符 -
\\w表示可以匹配任意英文字符、数字和下划线,相当于[a-zA-Z0-9_] -
\\W相当于[^a-zA-Z0-9_],与\\w相反 -
\\s匹配任何空白字符(空格,制表符等) -
\\S匹配任何非空白字符,与\\s相反 -
.匹配除\n和\r之外的所有字符,如果要匹配.本身则需要使用\\
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示字符匹配符的使用
public class RegExp03 {
public static void main(String[] args) {
String content = "a1 1\r@c^8ab_c\nA BC\r\n";
//String regStr = "[a-z]";//匹配 a-z 之间任意的一个字符
//String regStr = "[A-Z]";//匹配 A-Z 之间任意的一个字符
//String regStr = "[0-9]";//匹配 0-9 之间任意的一个字符
//String regStr = "abc";//匹配 abc 字符串[默认区分大小写]
//String regStr = "(?i)abc";//匹配 abc 字符串[不区分大小写]
//String regStr = "[^a-z]";//匹配不在 a-z 之间任意的一个字符
//String regStr = "[^0-9]";//匹配不在 0-9 之间任意的一个字符
//String regStr = "[abcd]";//匹配在 abcd 中任意的一个字符
//String regStr = "\\D";//匹配不在 0-9 中的任意的一个字符[匹配非数字字符]
//String regStr = "\\w";//匹配任意英文字符、数字和下划线
//String regStr = "\\W";//\[^a-zA-Z0-9_]
//String regStr = "\\s";//匹配任何空白字符(空格,制表符等)
//String regStr = "\\S";//匹配任何非空白字符
String regStr = ".";//.匹配除\n之外的所有字符,如果要匹配.本身则需要使用\\
//说明:当创建Pattern对象时,指定Pattern.CASE_INSENSITIVE,表示匹配是不区分字母大小写的
//Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.3元字符-选择匹配符
在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个,这时需要用到选择匹配符号|

例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp04 {
public static void main(String[] args) {
String content ="hangshunping 韩 寒冷";
String regStr="han|韩|寒";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
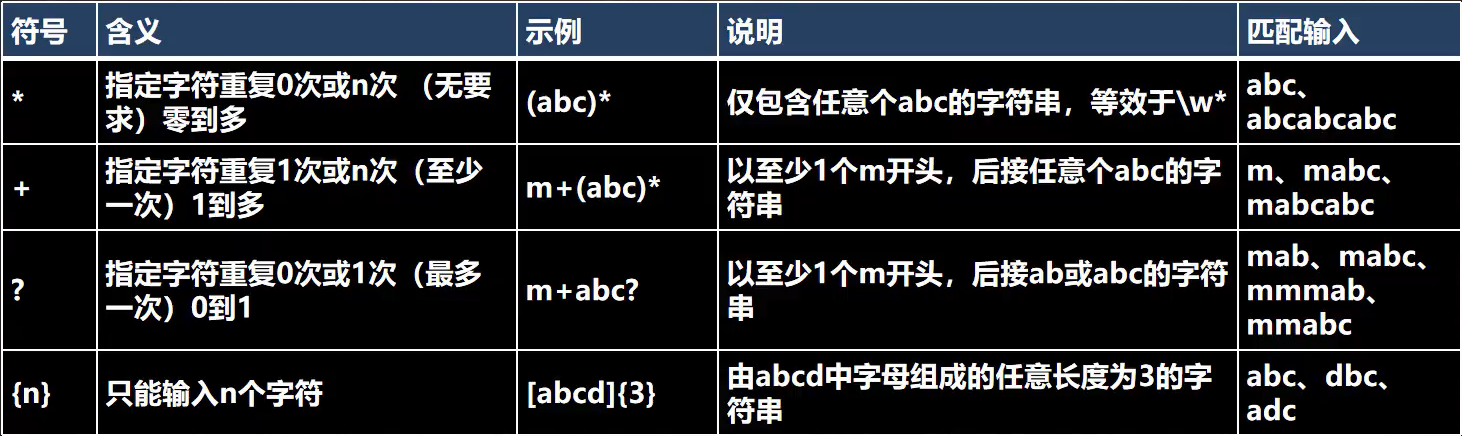
5.4.4元字符-限定符
用于指定其前面的字符和组合项连续出现多少次

-
{n}说明:n表示出现的次数,比如a{3},1{4},(\\d)
但是这里要注意一点,1{3}去匹配1111111的话,会得到什么结果呢?结果是:111,111
-
{n,m}说明:表示至少出现n次,最多出现m次。
细节:java匹配默认是贪婪匹配,即尽可能匹配多的
比如a{3,4},1{4,5},\\d{2,5}
如果 用1{3,4}去匹配1111111的话,会得到什么结果呢?结果是:1111,111
-
+ 说明:+ 号表示出现1次到任意多次。比如a+,1+,\\d+
如果用1+去匹配1111111的话,会得到什么结果呢?结果是:1111111
-
* 说明:* 号表示出现0次到任意多次,比如a*,1*,\\d*
如果用a1*去匹配a111的话,会得到什么结果呢?结果是:a111
-
? 说明:? 表示出现呢0次到1次,比如a?,1?,\\d?
如果用a1?去匹配a1111的话,会得到什么结果?结果是:a1
匹配a2111呢?结果是:a
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp05 {
public static void main(String[] args) {
String content = "1111111aaaaaahello";
//a{3},1{4},(\\d){2}
//String regStr="a{3}";//表示匹配 aaa
//String regStr="1{4}";//表示匹配 1111
//String regStr="(\\d){2}";//表示匹配 两位任意的数字字符
//a{3,4},1{4,5},\\d{2,5}
//细节:java匹配是贪婪匹配,即尽可能匹配多的
//String regStr="a{3,4}";//表示匹配 aaa 或者 aaaa 优先匹配数量多的
//String regStr="1{4,5}";//表示匹配 1111 或者 11111 优先匹配数量多的
//String regStr="\\d{2,5}";//表示匹配 2个至 5个数字 优先匹配数量多的
//a+,1+,\\d+
//String regStr="1+";//表示匹配 一个1或者多个1 优先匹配数量多的
//String regStr="\\d+";//表示匹配 一个数字或者多个数字 优先匹配数量多的
//a*,1*,\\d*
//String regStr="1*";//表示匹配 零个1或者多个1 优先匹配数量多的
//a?,1?,\\d?
String regStr = "a1?";//匹配 a 或者 a1 优先匹配数量多的
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.5元字符-定位符
定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,非常有用
注意:这里的位置是指进行匹配的整个文本(整串),而不是其子串。比如用^[0-9]+[a-z]*去匹配a123abc,返回空,什么都匹配不到
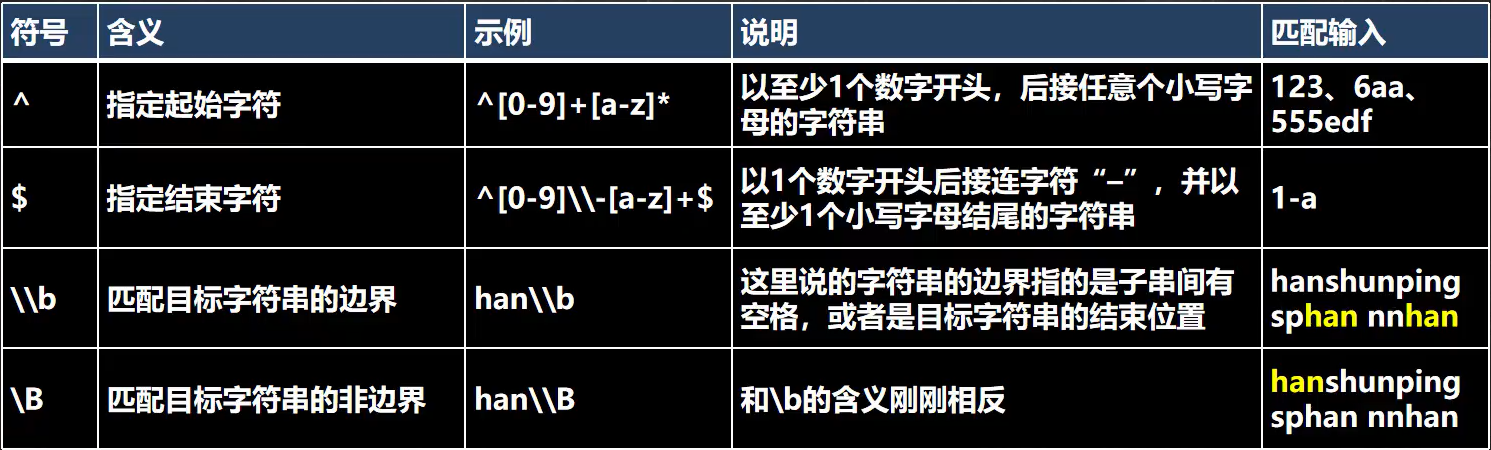
边界指的是被匹配的整串的最后,或者是空格/逗号/句号(只要不是数字字母和下划线都可以)的子字符串的后面
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示定位符的使用
public class RegExp06 {
public static void main(String[] args) {
String content = "123-abc";
String content2 = "hanshunping sphan nnhan";
//以至少1个数字开头,后接任意个小写字母的字符串
//String regStr="^[0-9]+[a-z]*";
//至少以一个数字开头,同时以至少一个小写字母结尾的字符串
//String regStr="^[0-9]+[a-z]+$";
//至少以一个数字开头,同时中间必须带有-号,且至少一个小写字母结尾的字符串
//String regStr="^[0-9]+\\-[a-z]+$";
//表示匹配边界的 han,边界指的是被匹配的整串的最后,
// 或者是空格/逗号/句号(只要不是数字字母和下划线都可以)的子字符串的后面
//String regStr="han\\b";
//和\\b含义相反
String regStr = "han\\B";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content2);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号