
ElasticSearch文档及分布式文档存储
1、什么是文档?
文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的分片,文档内容为Json格式的文档体,注意文档中的字段名称不能包含英文的句号,实际处理过程中这里最好不要包含符号,索引名称要用小写
规则:
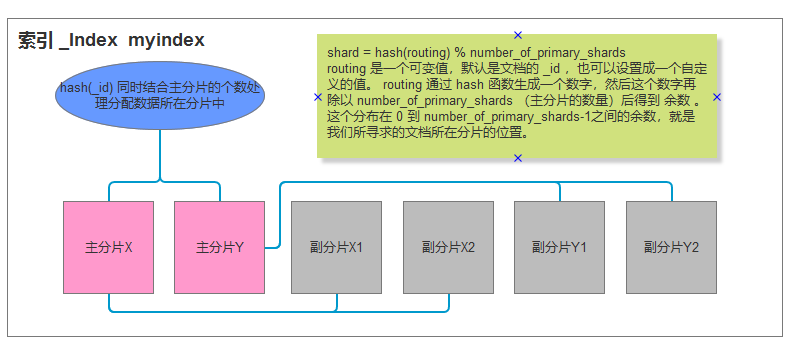
值得注意的是:
我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了
2、主分片与副分片之前的数据怎么同步呢?
如下 定义三个节点,我们有2个主分片,每个分片有2个副分片,为了保证数据完整性,ES会进行如下分布,这里我们用绿色标识主分片,矩形标识副分片,那么会出现如下分布,保证每个节点上都有完成的分片(主1 和主2 )数据.
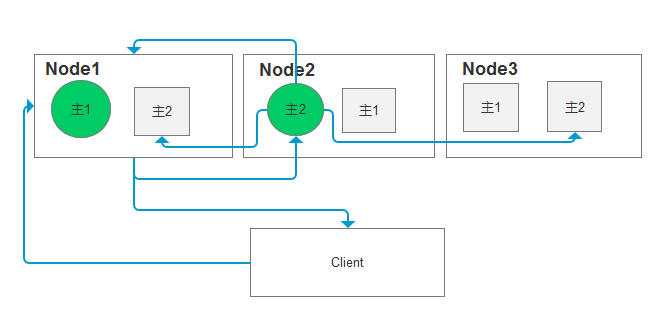
1、Client 发送写操作到Node1
问题:为什么要发到Node1,比如新加入了一个节点,这节点间的有编排编号吗?,如果是访问带有主节点的,也可以访问Node2也可以,这之间有什么关联吗?
答:每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上,一开始进来都是任意一个节点,这个节点知道位置后,会作为协调节点转发请求到对应的节点上。这里请求Node1是随机节点,知道文档存储在主分片2上转发到Node2,如果一开始就是Node2节点就不需转发了,然后协调数据同步后,返回Node1再返回客户端,写操作都会直接找主分区所在的节点,我有点怀疑直接进入Node3呢?
2、根据_id发现数据应该存在存在主分片2上,于是转到Node2,写入数据
问题:新建、索引和删除 请求都是 写 操作, 必须在主分片上面完成之后才能被复制到相关的副本分片,ES应该每个节点上有应该有一个记录主分片分布的节点记录,如果设置的自动生成_id的情况,那么怎么去判断位置?
3、数据同步,写入Node2中的主分片2成功后,并行写入2个副分片,等待两个副分片都应答成功后,然后通知客户端,防止网络或者其他问题带来的数据不一致
那么在数据一致性上Elasticsearch是怎么去处理的?
ES会要求有一定的副分片数量才会执行写操作,结合上面的 同步副分区,可以设置
int( (primary + number_of_replicas) / 2 ) + 1 ,consistency 参数也可以设置 one(主分区ok即可写入) 、all(所有主、副分区全部ok才执行写入)、quorum 默认(大多数的主、副分区没问题即可写入,及上面的公式)
出现分布式就需要注意大数据一致性的问题以及,多修改数据丢失的问题?虽然上面的同步能处理数据最终一致性的问题,但是如果出现多个人修改,会导致数据掉丢失的情况。在实际过程我们又怎么来避免这种情况呢?如又这么一组数据
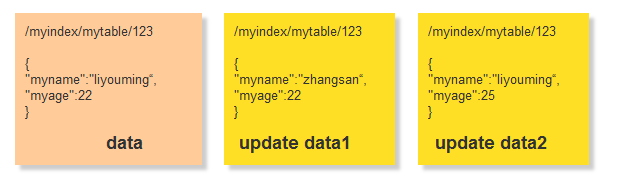
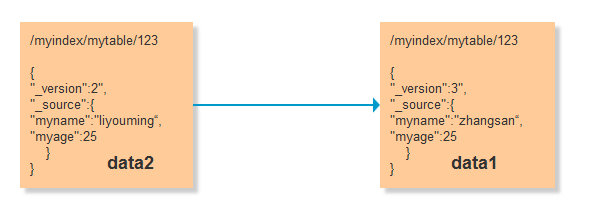
数据data 在 update data1 update data2 2个同时操作的时候会导致数据丢失,加入先get到数据 都是data 但是在update1 update2无论哪个先那个后实际上都会存在数据丢失 如果update1先,update2后,最后数据是 update2的 /myindex/mytable/123 { "myname":"liyouming“, "myage":25 } 如果update2先,update1后,最后数据是 update1的 /myindex/mytable/123 { "myname":"zhangsan“, "myage":22 } 但是实际上我们需要的数据应该是这样 /myindex/mytable/123 { "myname":"zhangsan“, "myage":25 } 其实仔细想想在我们的实际业务管理系统中也会有这样的问题,如果两个人同时打开一个编辑界面同时修改,操作1 在不知道 操作2 修改内容的情况下直接修改,其中会覆盖一部分的数据丢失掉了
那么ElasticSearch是怎么来处理这个问题的呢?
每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略,我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。
那么我们在来看下上面的demo
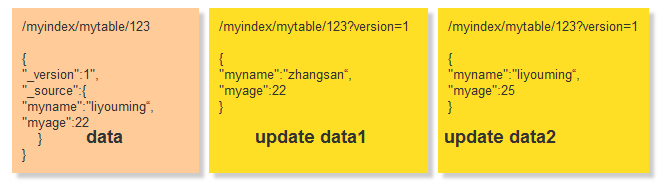
在我们查询出来的时候获取到版本号 _version 为1,在进行update1 或update2的时候带上我们的版本号,那么其中后面执行的那个会出现修改失败,这么就能保证数据丢失的情况了,假定数据update2修改成功了,那么我们得到的数据会是这样 data2 ,upate1失败后再次获取信息 得到版本为2 再次修改成功得到data1最终修改
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!
本文版权归作者和博客园共有,来源网址:http://www.cnblogs.com/liyouming欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号