Python 网络爬虫之 Ajax 数据爬取
Ajax 概述
Ajax是利用 JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
Ajax基本原理
- 发送请求
- 解析内容
- 渲染页面
查看请求
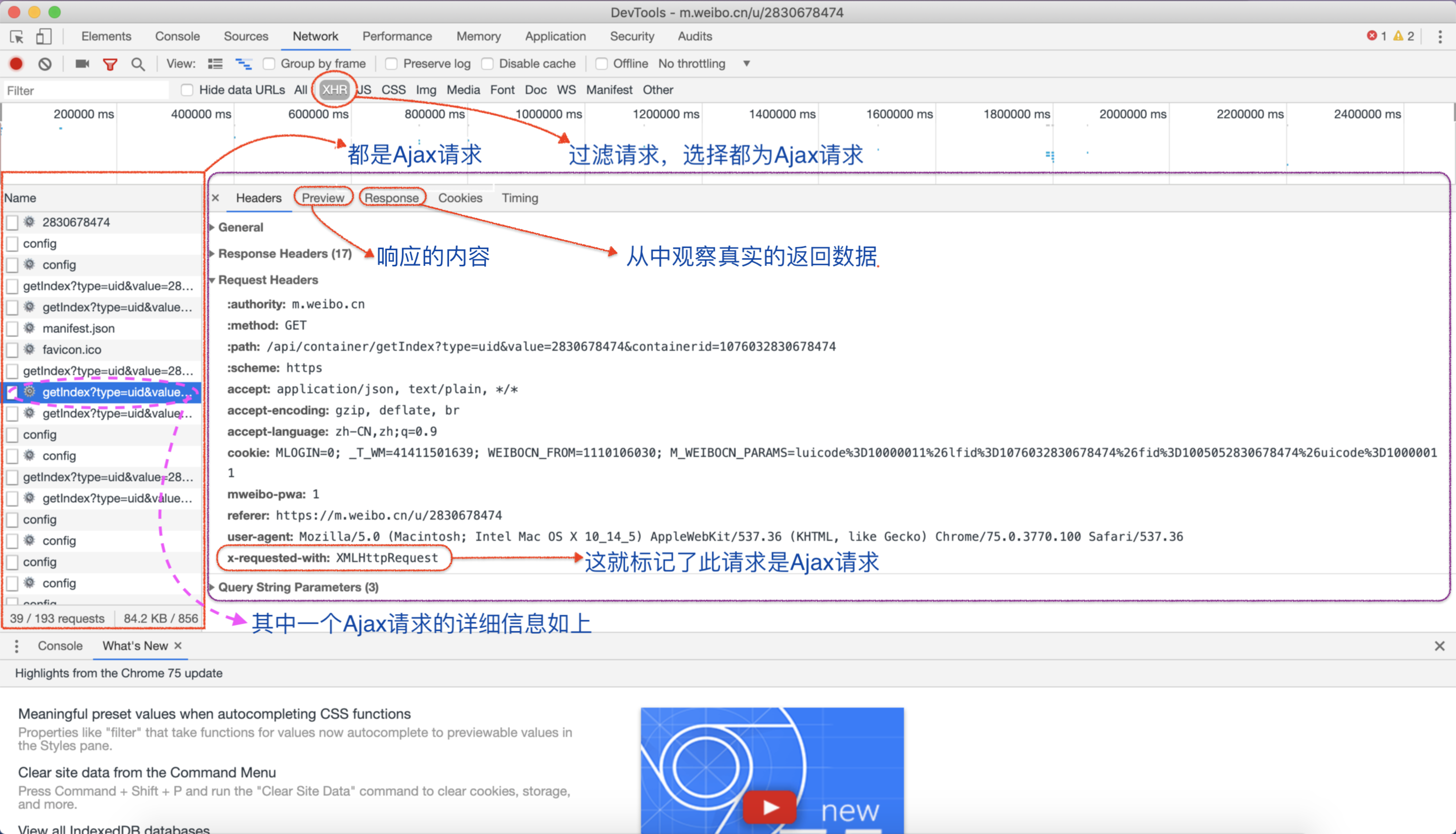
Ajax结果提取
爬取一个人微博的前面10页
分析过程

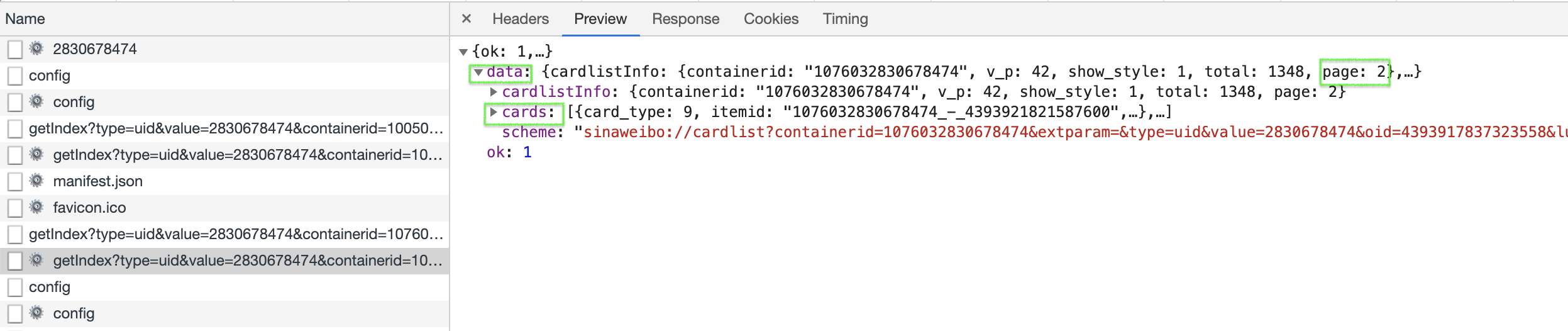

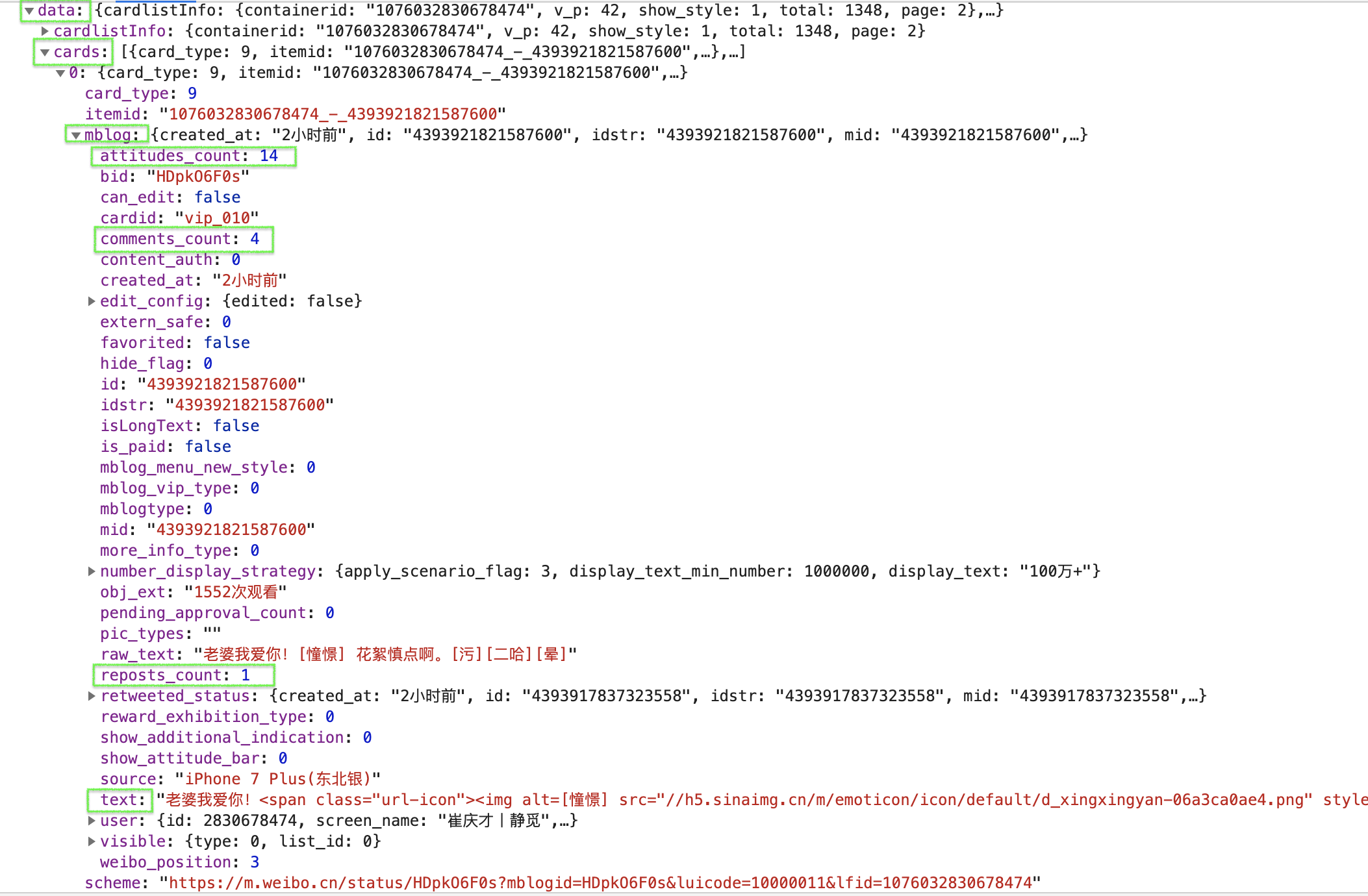
Python代码实现
from urllib.parse import urlencode
import requests
# 对https://m.weibo.cn/u/2830678474网页审查分析
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2830678474',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/75.0.3770.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# page 为页码,返回每一页响应的JSON编码内容(如果有)
def get_page(page):
params = {
'type': 'uid',
'value': '2830678474',
'containerid': '1076032830678474',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200: # response.status_code获取网页状态码
return response.json() # response.json()返回响应的JSON编码内容
except requests.ConnectionError as e: # 出现异常,捕获并输出其异常信息
print('Error:', e.args)
from pyquery import PyQuery
# 根据获取的json编码,筛选出我们需要的内容
def parse_page(json):
if json:
items = json.get('data').get('cards') # 获取json编码中的data里面的cards的内容,返回结果是一个迭代器
for item in items: # 遍历每条cards内容
item = item.get('mblog') # 获取mblog中的内容
weibo = {}
weibo['id'] = item.get('id') # 获取'id'内容
weibo['text'] = PyQuery(item.get('text')).text()
# 利用get()获取'text'内容,再利用PyQuery()方法初始化Json编码形式,再利用text()获取子节点的文本表示形式。
weibo['attitudes'] = item.get('attitudes_count') # 获取'赞'的个数
weibo['comments'] = item.get('comments_count') # 获取'评论'数
weibo['reposts'] = item.get('reposts_count') # 获取'分享'次数
yield weibo
from pymongo import MongoClient
client = MongoClient() # 连接MongoDB
db = client['weibo'] # 指定weibi数据库
collection = db['weibo'] # 指定weibo集合
# 将数据插入Mongo数据库
def save_to_mongo(result):
if result:
collection.insert_one(result) # 调用insert_one()方法,将一条数据插入到数据库中
print('Saved to Mongo')
if __name__ == '__main__':
for page in range(1, 11): # 获取10页
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)
save_to_mongo(result)
结果
-
部分输出
{'id': '4393921821587600', 'text': '老婆我爱你! 花絮慎点啊。', 'attitudes': 16, 'comments': 4, 'reposts': 1} Saved to Mongo {'id': '4393850371867195', 'text': '执行力非常重要,做一个实干者。', 'attitudes': 1, 'comments': 0, 'reposts': 3} Saved to Mongo {'id': '4393608914828988', 'text': '欧耶!!!!!@长泽牙妹\n济南', 'attitudes': 9, 'comments': 15, 'reposts': 0} Saved to Mongo {'id': '4393563145925473', 'text': '叔叔要和我喝酒了。\n我好慌。 济南', 'attitudes': 10, 'comments': 20, 'reposts': 0} Saved to Mongo -
MongoDB数据库查看数据

异步(Ajax)爬取今日头条街拍美图
类似上面爬微博的方法,爬取今日头条街拍美图
import requests
from urllib.parse import urlencode
base_url = 'https://www.toutiao.com/api/search/content/?'
headers = {
'Host': 'www.toutiao.com',
'Referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/75.0.3770.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 一个关于offset和timestamp数据的列表
def offset_timestamp():
offsets = [offset for offset in range(8)]
timestamps = [1563094062541, 1563094066268, 1563094068231, 1563094069948, 1563094071549, 1563094073370,
1563094075154, 1563094077384]
tuple_list = []
for i in range(8):
tuple_list.append(
(offsets[i], timestamps[i])
)
return tuple_list
# 获取页面Json编码
def get_page(tuple_):
params = {
'aid': '24',
'app_name': 'web_search',
'offset': tuple_[0],
'format': 'json',
'keyword': '%E8%A1%97%E6%8B%8D',
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': tuple_[1]
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error:', e.args)
return None
# 获取图片URL
def get_images(json):
if json.get('data'):
data = json.get('data')
if data.get('abstract'):
for item in data.get('data'):
abstract = item.get('abstract')
images = item.get('image_list')
for image in images:
yield {
'image': image.get('url'),
'abstract': abstract
}
import os
from hashlib import md5
# 保存图片
def save_image(item):
if not os.path.exists(item.get('abstract')): # os.path.exists(path)方法,测试路径是否存在
os.mkdir(item.get('abstract')) # os.mkdir()方法,创建一个目录
try:
response = requests.get(item.get('image')) # 对获取的image_URL发送请求
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('abstract'), md5(response.content).hexdigest(), 'jpg')
# 图片的名称可以使用MD5值,这样可以去除重复。
# response.content属性返回响应内容。
# hexdigest()方法,以十六进制数字的字符串形式返回摘要值。
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content) # 将响应的内容以二进制的形式写入文件file_path中
else:
print('Already Downloaded', file_path)
except requests.ConnectionError as e:
print(
'Error:', e.args,
'\nFailed to Save Image'
)
if __name__ == '__main__':
tuple_list = offset_timestamp()
for tuple_ in tuple_list:
json = get_page(tuple_)
for item in get_images(json):
print(item)
save_image(item)
本文来自博客园,作者:LeeHua,转载请注明原文链接:https://www.cnblogs.com/liyihua/p/11182862.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号