人脸识别学习笔记一:入门篇
一、人脸识别概述
1.人脸识别的困难之处
- 不同个人之间的区别不大:大部分人脸的结构都很相似,甚至人脸器官的结构外形都很相似。
- 人脸的外形很不稳定:人的面部表情多变,不同的观察角度、光照条件等都会影响人脸的视觉图像。
2.人脸识别的典型流程
-
人脸检测(Face Detection):人脸检测用于确定人脸在图像中的大小和位置,即解决“人脸在哪里”的问题,把真正的人脸区域从图像中裁剪出来,便于后续的人脸特征分析和识别。
![中星微AI刷新WIDER FACE人脸检测世界纪录]()
-
人脸对齐(Face Alignment):同一个人在不同的图像序列中可能呈现出不同的姿态和表情,这种情况是不利于人脸识别的。所以有必要将人脸图像都变换到一个统一的角度和姿态,这就是人脸对齐。
![人脸对齐例子]()
-
人脸特征表示(Feature Representation):人脸特征表示是人脸识别中最为重要的一步,它接受的输入是标准化的人脸图像,通过特征建模得到向量化的人脸特征,最后通过分类器判别得到识别的结果。
![一个完整的人脸识别流程]()



二、常用数据集
LFW:5749 人的13233张人脸图像,其中有1680人有两张或以上的图像。
YouTube Faces DB:面部视频数据集,包含3425个视频,1595个不同的人。
CASIA-FaceV5:500个人的25000张亚洲人脸图片。
其他数据集及其下载链接:都是百度云下载
三、人脸检测算法介绍
1.基于模版匹配的算法
早期的人脸检测算法使用了模板匹配技术,即用一个人脸模板图像与被检测图像中的各个位置进行匹配,确定这个位置处是否有人脸。然后可以使用一些机器学习算法用于解决该问题,包括神经网络,支持向量机等。以上都是针对图像中某个区域进行人脸-非人脸二分类的判别。
这种方法的代表性成果是Rowley等人提出来的算法:用一个20*20的人脸模板图像和被检测图像的各个位置进行匹配,每次在被检测图像上截取出一个20*20的滑动窗口,将模板和窗口进行比较,就可以检测窗口中是否包含人脸(模型参数的响应值高就说明包含人脸)。这种方法只能解决近似正面的人脸检测问题,在其他角度的人脸检测效果并不好。

为了解决多角度检测问题,Rowly等人提出来了一个新的方法:整个系统由两个神经网络构成,第一个网络用于估计人脸的角度,第二个用于判断是否为人脸。角度估计器输出一个旋转角度,然后用整个角度对检测窗进行旋转,然后用第二个网络对旋转后的图像进行判断,确定是否为人脸。

Rowley的方法有不错的精度,由于分类器的设计相对复杂而且采用的是密集滑动窗口进行采样分类导致其速度太慢。
2.基于AdaBoost框架的算法
boost算法是基于PAC学习理论(Probably Approximately Correct,概率近似正确)而建立的一套集成学习算法。其根本思想在于通过多个简单的弱分类器,构建出准确率很高的强分类器,PAC学习理论证实了这一方法的可行性。
在2001年Viola和Jones设计了一种人脸检测算法。它使用简单的Haar-like特征和级联的AdaBoost分类器构造检测器,检测速度较之前的方法有2个数量级的提高,并且保持了很好的精度,这就是著名的VJ框架。VJ框架是人脸检测历史上第一个最具有里程碑意义的一个成果,奠定了基于AdaBoost目标检测框架的基础。
用级联AdaBoost分类器进行目标检测的思想是:用多个AdaBoost分类器合作完成对候选框的分类,这些分类器组成一个流水线,对滑动窗口中的候选框图像进行判定,确定它是人脸还是非人脸。
在这一系列AdaBoost分类器中,前面的强分类器设计很简单,包含的弱分类器很少,可以快速排除掉大量的不是人脸的窗口,但也可能会把一些不是人脸的图像判定为人脸。如果一个候选框通过了第一级分类器的筛选即被判定为人脸,则送入下一级分类器中进行判定,以此类推。如果一个待检测窗口通过了所有的强分类器,则认为是人脸,否则是非人脸。

3.基于深度学习的算法
卷积神经网络在图像分类问题上取得成功之后很快被用于人脸检测问题,在精度上大幅度超越之前的AdaBoost框架,当前已经有一些高精度、高效的算法。直接用滑动窗口加卷积网络对窗口图像进行分类的方案计算量太大很难达到实时,使用卷积网络进行人脸检测的方法采用各种手段解决或者避免这个问题。
- Cascade CNN(Cascade Convolutional Neural Networks,级联卷积神经网络):Cascade CNN可以认为是传统技术和深度网络相结合的一个代表,和VJ人脸检测器一样,其包含了多个分类器,这些分类器采用级联结构进行组织,然而不同的地方在于,Cascade CNN采用卷积网络作为每一级的分类器。
算法流程:
-
构建多尺度的人脸图像金字塔,12-net将密集的扫描这整幅图像(不同的尺寸),快速的剔除掉超过90%的检测窗口,剩下来的检测窗口送入12-calibration-net调整它的尺寸和位置,让它更接近潜在的人脸图像的附近。
-
采用非极大值抑制(NMS)合并高度重叠的检测窗口,保留下来的候选检测窗口将会被归一化到24x24作为24-net的输入,这将进一步剔除掉剩下来的将近90%的检测窗口。和之前的过程一样,通过24-calibration-net矫正检测窗口,并应用NMS进一步合并减少检测窗口的数量。
-
将通过之前所有层级的检测窗口对应的图像区域归一化到48x48送入48-net进行分类得到进一步过滤的人脸候选窗口。然后利用NMS进行窗口合并,送入48-calibration-net矫正检测窗口作为最后的输出。

-
MTCNN(Multi-task Cascaded Convolutional Networks,多任务卷积神经网络):MTCNN是多任务的一个方法,它将人脸区域检测和人脸关键点检测放在了一起。同Cascade CNN一样也是基于cascade的框架,但是整体思路更加巧妙合理。MTCNN总体来说分为三个部分:PNet、RNet和ONet。
![MTCNN网络结构]()

算法流程:
- 首先按不同比例缩放照片,形成图片的特征金字塔作为P-Net输入。
- P-Net主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过NMS来合并高度重叠的候选框。
- 然后将候选框输入R-Net网络训练,利用边界框的回归值微调候选窗体,再利用NMS去除重叠窗体。
- O-Net功能与R-Net作用类似,只是在去除重叠候选窗口的同时显示五个人脸关键点定位。
四、人脸识别算法介绍
1.早期算法
- 基于几何特征的算法:人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。但是这类方法的精度一般都比较差。
- 基于模板匹配的算法:从数据库当中提取人脸模板,接着采取一定模板匹配策略,使抓取人脸图像与从模板库提取图片相匹配,由相关性的高低和所匹配的模板大小确定人脸大小以及位置信息。
- 子空间算法:子空间算法将人脸图像当成一个高维的向量,将向量投影到低维空间中,投影之后得到的低维向量达到对不同的人具有良好的区分度。子空间算法的典型代表是PCA(Principal Component Analysis,主成分分析)和LDA(Linear Discriminant Analysis,线性判别分析)。PCA的核心思想是在进行投影之后尽量多的保留原始数据的主要信息,降低数据的冗余信息,以利于后续的识别。LDA的核心思想是最大化类间差异,最小化类内差异,即保证同一个人的不同人脸图像在投影之后聚集在一起,不同人的人脸图像在投影之后被用一个大的间距分开。PCA和LDA最后都归结于求解矩阵的特征值和特征向量。PCA和LDA都是线性降维技术,但人脸在高维空间中的分布是非线性的,因此可以使用非线性降维算法,典型的代表是流形学习和核(kernel)技术。流形学习假设向量点在高维空间中的分布具有某些几何形状,然后在保持这些几何形状约束的前提下将向量投影到低维空间中,这种投影是通过非线性变换完成的。
2.人工特征+分类器
第二阶段的人脸识别算法普遍采用了人工特征 + 分类器的思路。分类器有成熟的方案,如神经网络,支持向量机,贝叶斯等。这里的关键是人工特征的设计,它要能有效的区分不同的人。
描述图像的很多特征都先后被用于人脸识别问题,包括HOG(Histogram of oriented gradient,方向梯度直方图)、SIFT(Scale-invariant Feature Transform,尺度不变特征转换 )、LBP(Local Binary Patterns,局部二值模式)等。它们中的典型代表是LBP特征,这种特征简单却有效。LBP特征计算起来非常简单,部分解决了光照敏感问题,但还是存在姿态和表情的问题。
联合贝叶斯是对贝叶斯人脸的改进方法,选用LBP和LE作为基础特征,将人脸图像的差异表示为相同人因姿态、表情等导致的差异以及不同人间的差异两个因素,用潜在变量组成的协方差,建立两张人脸的关联。文章的创新点在于将两个人脸表示进行联合建模,在人脸联合建模的时候,又使用了人脸的先验知识,将两张人脸的建模问题变为单张人脸图片的统计计算,更好的验证人脸的相关性,该方法在LFW上取得了92.4%的准确率。
人工特征的巅峰之作是出自2013年MSRA的"Blessing of Dimisionality: High Dimensional Feature and Its Efficient Compression for Face Verification" ,这是一篇关于如何使用高维度特征在人脸验证中的文章。作者主要以LBP为例子,论述了高维特征和验证性能存在着正相关的关系,即人脸维度越高,验证的准确度就越高。

3.基于深度学习的算法
第三个阶段是基于深度学习的方法,自2012年深度学习在ILSVRC-2012大放异彩后,很多研究者都在尝试将其应用在自己的方向,这极大的推动了深度学习的发展。卷积神经网络在图像分类中显示出了巨大的威力,通过学习得到的卷积核明显优于人工设计的特征+分类器的方案。在人脸识别的研究者利用卷积神经网络(CNN)对海量的人脸图片进行学习,然后对输入图像提取出对区分不同人的脸有用的特征向量,替代人工设计的特征。
在前期,研究人员在网络结构、输入数据的设计等方面尝试了各种方案,然后送入卷积神经网络进行经典的目标分类模型训练;在后期,主要的改进集中在损失函数上,即迫使卷积网络学习得到对分辨不同的人更有效的特征,这时候人脸识别领域彻底被深度学习改造了!
DeepFace由Facebook提出,是深度卷积神经网络在人脸识别领域的奠基之作,文中使用了3D模型来做人脸对齐任务,深度卷积神经网络针对对齐后的人脸Patch进行多类的分类学习,使用的是经典的交叉熵损失函数进行问题优化,最后通过特征嵌入得到固定长度的人脸特征向量。Backbone网络使用了多层局部卷积结构,原因是希望网络的不同卷积核能学习人脸不同区域的特征,但会导致参数量增大,要求数据量很大,回过头去看该策略并不是十分必要。
DeepFace在LFW上取得了97.35%的准确率,已经接近了人类的水平。相比于1997年那篇基于卷积神经网络的40个人400张图的数据规模,Facebook搜集了4000个人400万张图片进行模型训练。

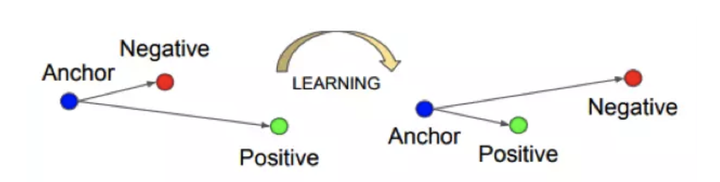
之后Google推出FaceNet,使用三元组损失函数(Triplet Loss)代替常用的Softmax交叉熵损失函数,在一个超球空间上进行优化使类内距离更紧凑,类间距离更远,最后得到了一个紧凑的128维人脸特征,其网络使用GoogLeNet的Inception模型,模型参数量较小,精度更高,在LFW上取得了99.63%的准确率,这种损失函数的思想也可以追溯到早期的LDA算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号