



假设场景如下:我们有两个数据库,分别为数据库1和数据库2 。数据库1为用户服务模块相关数据库,数据库2为商品相关服务数据库。在数据库1中存在一个user表 。在数据库2中存在一个product表。我们现在需要对这两个表做一个join查询。应该如何实现呢?
首先,Oracle不需要考虑该问题,众所周知,Oracle是收费的,而且费用很可观。所以呢,掏钱的大爷们是不需要考虑Oracle集群的多数据库join的,因为Oracle本身是可以设置集群的,直接用就可以了。
那么,在使用mysql的时候,如果是一个数据库集群,想要查询多个数据库下的不同表的连表查询,应该怎么做呢?
不卖关子,直接说,在高可用场景下,最常用的是第三种,创建一个搜索引擎 。使用的是solr 或者es
下面具体说下几种常见的实现方式,欢迎补充。
1.多个sql查询。实现方式为:我们把sql语句进行拆分,然后把所有数据都查到内存,然后去实现多个库的关联查询。例如:我们需要查询的一个sql语句为:
select a.a from a,b where a .id = b.id and b.name = ‘test’
这时,我们直接查的话是不行的,因为a表和b表不在同一个数据库。那么我们可以将sql进行拆分,首先从b表中把符合条件的数据全部查出来,然后,将查到的结果作为条件去a表再次进行查询。sql如下:
select b.id from b where b.name = test select a.a from a where a.id in ();
在第一行sql执行完毕后,得到的id作为条件,再次去a表做查询操作。
这种操作的优点是实现比较简单;缺点是:需要把数据都查入到内存,多次进行数据库的访问。
2.数据做冗余操作。
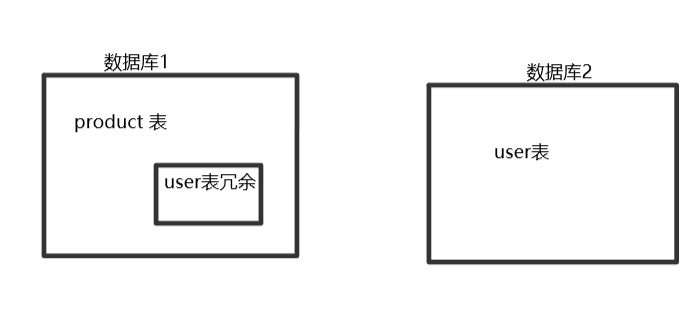
实现方式:我们在a数据库中,将需要的b数据库数据做冗余,这样在查询的时候,只需要查询a一个数据库即可。具体实现的时候有字段冗余和表冗余。
这样做的好处是,我们可以直接用一个表实现数据查询,查的时候效率较高。缺点是更新的时候,需要连带更新冗余的表,会对数据的一致性造成影响。一般会把基本不发生修改的数据进行冗余,如dict表。
3.搜索引擎。
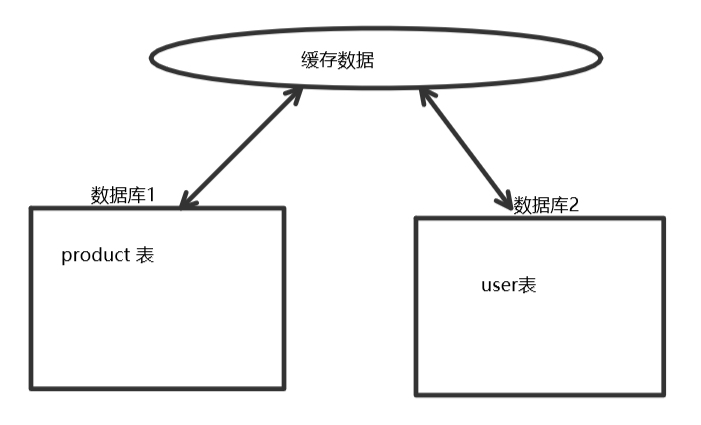
实现方式:在solr或者es中,把数据库里的相关的关键数据做成一个字典,把相关的数据放入缓存,作为一个内存中的一级查询缓存。
这种实现的优点是查询效率较高,可用性好。缺点是当数据的一致性比较高的时候,需要不断地去从数据库把最新数据更新到缓存。在数据量大的时候,重建数据索引开销极大。
4.链接表
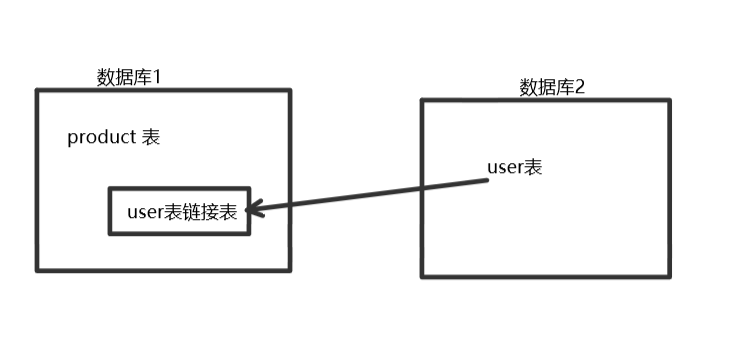
实现方式:在mysql中,数据库1中可以创建一个数据库2中表的链接表,类似于一个快捷方式,这个表不存有实际数据,但是可以通过它访问到数据库2的数据。使用时,要求本地的表结构必须与远程一致。
建表语句:
CREATE TABLE TABLE2 (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://192.168.1.2:3307/DB2/TABLE2';
该方案的优点是不需要存储数据,也不用创建缓存。缺点是:黑盒,不知道具体原理。 仅限于mysql数据库,无法跨平台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号