
第三次作业:卷积神经网络 part 3
第三次作业:卷积神经网络 part 3
代码部分
HybridSN 高光谱分类
对原来代码进行修改后,在模型训练时加入net.train(),在测试时加入net.eval(),模型测试时稳定。model.train()
在训练模型时会在前面加上,而model.eval()在测试模型时在前面使用同时发现,如果不写这两个程序也可以运行,这是因为这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout。
- 训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,模型测试时要使用训练好后固定的均值和方差,如果不使用eval(),则每次运行均值和方差会改变。
- 模型训练时,需要使用dropout的方法,丢掉一半的参数,防止模型过拟合,而在测试时,所有的模型参数都必须保留。
class_num = 16
class HybridSN(nn.Module):
# ''' your code here '''
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
self.conv4 = nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0)
self.linear1 = nn.Linear(18496, 256)
self.drop = nn.Dropout(0.4)
self.linear2 = nn.Linear(256, 128)
self.linear3 = nn.Linear(128, 16)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out.view(out.size(0), -1, out.size(3), out.size(4))
out = F.relu(self.conv4(out))
out = out.view(out.size(0), -1)
out = F.relu(self.drop(self.linear1(out)))
out = F.relu(self.drop(self.linear2(out)))
out = self.linear3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
运行结果,模型的准确率为95.17%
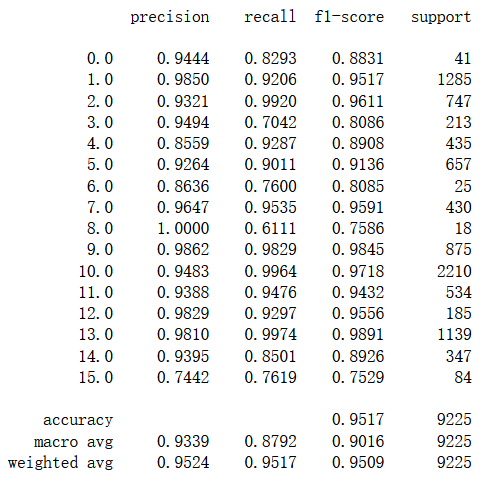
加入BatchNorm
class_num = 16
class HybridSN(nn.Module):
# ''' your code here '''
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.bn1 = nn.BatchNorm3d(8)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.bn2 = nn.BatchNorm3d(16)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
self.bn3 = nn.BatchNorm3d(32)
self.conv4 = nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(64)
self.linear1 = nn.Linear(18496, 256)
self.drop = nn.Dropout(0.4)
self.linear2 = nn.Linear(256, 128)
self.linear3 = nn.Linear(128, 16)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = F.relu(self.bn3(self.conv3(out)))
out = out.view(out.size(0), -1, out.size(3), out.size(4))
out = F.relu(self.bn4(self.conv4(out)))
out = out.view(out.size(0), -1)
out = F.relu(self.drop(self.linear1(out)))
out = F.relu(self.drop(self.linear2(out)))
out = self.linear3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
模型的测试结果为98.82%,相较于不加之前提高了不少。
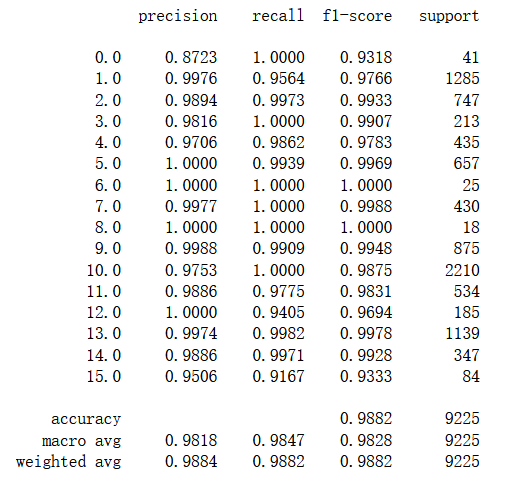
加入SENet
class SEBlock(nn.Module):
def __init__(self, inputs):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(inputs, inputs // 16, bias=False),
nn.ReLU(),
nn.Linear(inputs // 16, inputs, bias=False),
nn.Sigmoid()
)
def forward(self, x):
ba, h = x.size(0), x.size(1)
y = self.avg_pool(x)
y = y.view(ba, h)
y = self.fc(y)
y = y.view(ba, h, 1, 1)
return x * y.expand_as(x)
class_num = 16
class HybridSN(nn.Module):
# ''' your code here '''
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
self.conv4 = nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0)
self.se = SEBlock(64)
self.linear1 = nn.Linear(18496, 256)
self.drop = nn.Dropout(0.4)
self.linear2 = nn.Linear(256, 128)
self.linear3 = nn.Linear(128, 16)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out.view(out.size(0), -1, out.size(3), out.size(4))
out = F.relu(self.conv4(out))
out = self.se(out)
out = out.view(out.size(0), -1)
out = F.relu(self.drop(self.linear1(out)))
out = F.relu(self.drop(self.linear2(out)))
out = self.linear3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
运行测试结果,准确率为98.24%。
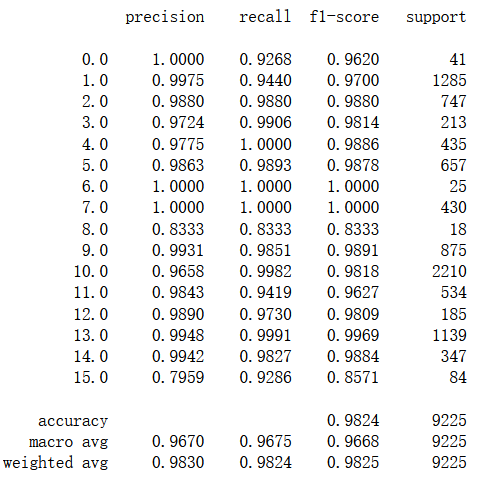
视频部分
语义分割中的自注意力机制和低秩重建
语义分割是计算机视觉几大主任务之一,被广泛应用到自动驾驶、遥感监测等领域中。语义分割研究中的若干成果,也被诸多相关领域沿用。自注意力机制继在 NLP 领域取得主导地位之后,近两年在计算机视觉领域也开始独领风骚。视频主要介绍自注意力机制在语义分割网络中的应用,并介绍由之衍生出的一系列低秩重建相关的方法。
注意力机制继在 NLP 领域取得主导地位之后,近两年在 CV 领域也开始独领风骚。率先将之引入的是 Kaiming He 组的 Nonlocal。此后层出不穷的文章,引发了一波研究注意力机制的热潮。仅2018年,在语义分割领域就有多篇高影响力文章出炉,如 PSANet,DANet,OCNet,CCNet。此外,针对 注意力数学形式的优化,又衍生出A2Net,CGNL。而 A2Net 又开启了本人称之为“低秩”重建的探索,同一时期的SGR,Beyonds Grids,GloRe,LatentGNN都可以此归类。
Non-local Neural Networks
卷积只能对局部区域进行context modeling,导致感受野受限制,但其实全局的信息对于图像的任务更有价值,比如短视频分类任务等等,目前全局信息的使用就是FC,但是这会带来大量的参数。这篇文章提出了一个nonlocal的操作,他把position当成了一个权重,这里的position可以指空间,时间,或者时空关系,计算全局的关联性。nonlocal可以被封装成一个block,用于任何网络,它是一个类似attention的机制,根据各像素之间的相关性,对所有像素进行加权。权重越大,说明这个区域越重要。
具体实例为:
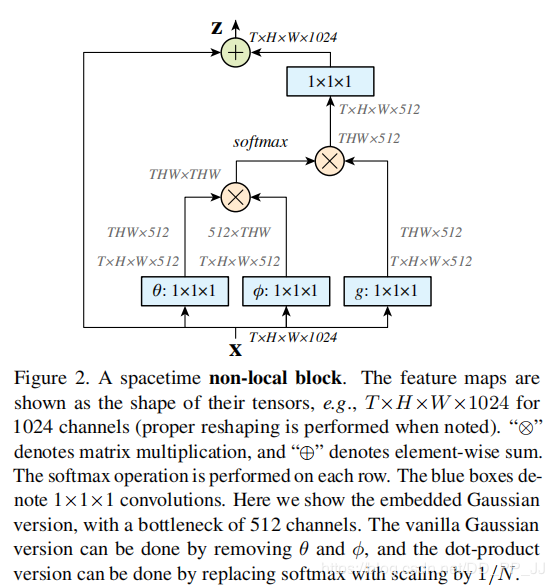
首先网络输入是X= (batch, h, w, 1024) ,经过Embedded Gaussian中的两个嵌入权重变换,权重变换得到(batch, h, w, 512),(batch, h, w, 512),其实这里的目的是降低通道数,减少计算量;然后分别对这两个输出进行reshape操作,变成(batch, hw, 512),后对这两个输出进行矩阵乘(其中一个要转置),计算相似性,得到(batch, hw, hw),
然后在第2个维度即最后一个维度上进行softmax操作,得到(batch, hw, hw),这样做就是通道注意力,相当于找到了当前图片或特征图中每个像素与其他所有位置像素的归一化相关性;然后将g也采用一样的操作,先通道降维,然后reshape;然后和(batch, hw, hw)进行矩阵乘,得到(batch, h, w, 512),即将通道注意力机制应用到了所有通道的每张特征图对应位置上,本质就是输出的每个位置值都是其他所有位置的加权平均值,通过softmax操作可以进一步突出共性。最后经过一个1x1卷积恢复输出通道,保证输入输出尺度完全相同。
PSANet: Point-wise Spatial Attention Network for Scene Parsingf
PSANet和 Nonlocal 最大的区别在于,相关度矩阵f的计算。此外,PSANet 包含两路 attention,相当于transformer中的两个head。两路分别起到 collect 和distribute 的作用。

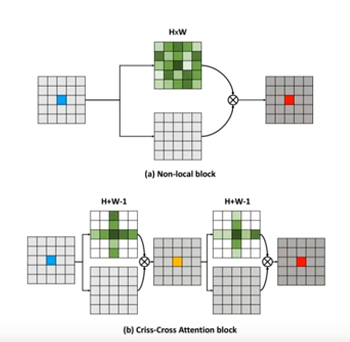
CCNet: Criss-Cross Attention for Semantic Segmentation
CCNet将全图计算分解为两步,一步是按行计算,一步是按列计算。
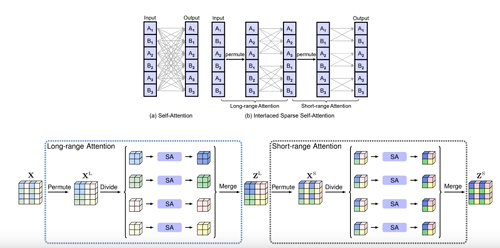
Interlaced Sparse Self-Attention for Semantic Segmentation
ISA也是将attention map的全图计算分解为两步:第一步长距离attention,第二步短距离。中间夹着一步permute操作。
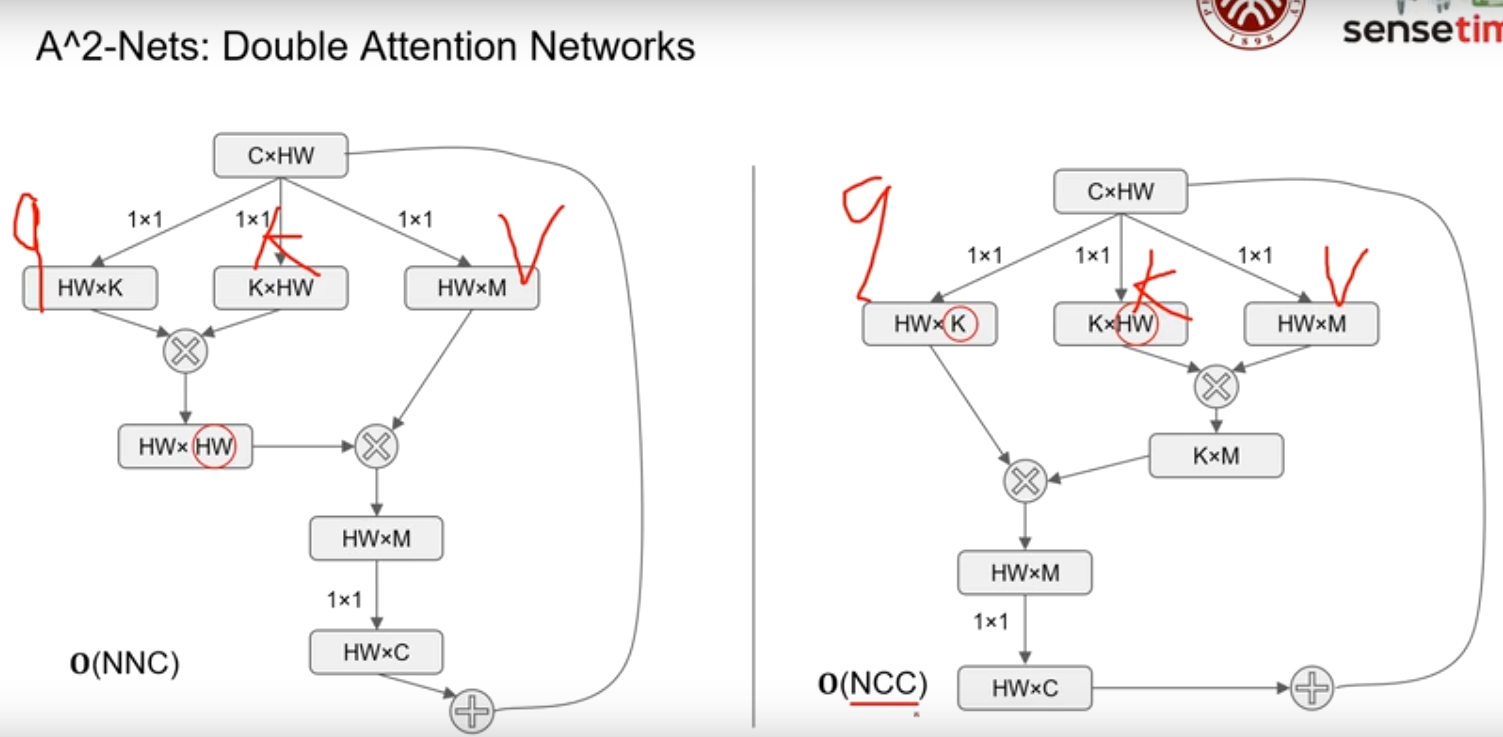
A2 -Nets: Double Attention Networks
从另一个角度优化了 Nonlocal 的复杂度,Nonlocal 高昂的复杂度O(N2xC)成为制约其应用的关键瓶颈,而A2Net使用下乘法结合律,先算后两者的乘积,便可以得到O(NxC2)的复杂度,由于C远远小于N,复杂度减少了整整一个量级。
Expectation-Maximization Attention Networks for Semantic Segmentation
提出的期望最大化注意力机制(EMA),摒弃了在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,从而大大降低了复杂度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号