
一、功能
将大文件拆分成多个小的文件,大部分时候拆分大文件使用split命令。默认情况下,split命令拆分生成每个输出文件的行数是1000行并且文件前缀是字符“x”。那么问题来了,我们什么时候能够用到这个命令呢?
应用场景:一个文件很大,两个主机之间拷贝需要耗时很长时间而且拷贝可能会中断(可能由于网络原因)。这个时候我们将文件查分成多个小文件传输较为方便,传输完成以后在目标主机进行合并,然后验证验证文件md5和源文件md5是否相同。
二、语法
split [OPTION]... [INPUT [PREFIX]]
INPUT : 一般是文件名
PREFIX:指定生成小文件的前缀
三、案例
3.0 数据准备
再开始案例之前需要准备好数据,需要一个有3500行的测试文件。
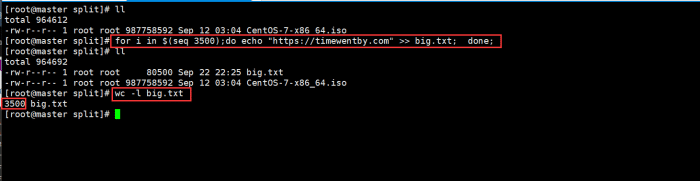
创建名字为big.txt并且写入3500行数据:
for i in $(seq 3500);do echo "https://timewentby.com" >> big.txt; done;
3.1 split命令默认切分情况
split big.txt
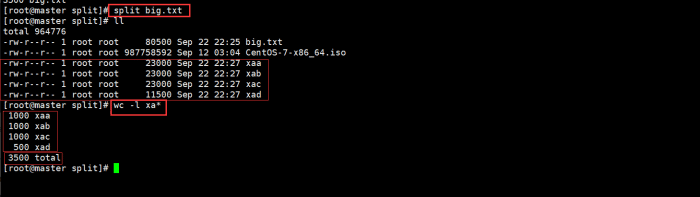
说明:
a. 拆分成文件命名前缀为字母x,后缀是两位字母(aa-zz)。
b. 通过 wc -l xa* 命令查看拆分成文件每个都有1000行,最后1个为500行(因为不足1000行)。
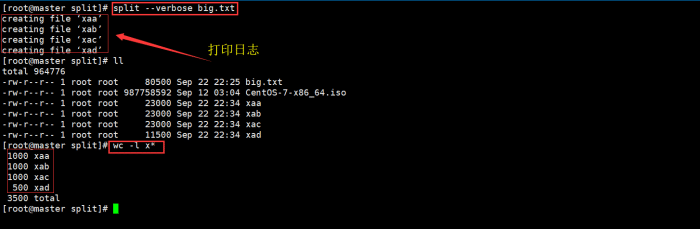
3.2 切分big.txt文件时显示执行过程
选项:
--verbose 每一步执行之前打印日志
命令:
split --verbose big.txt
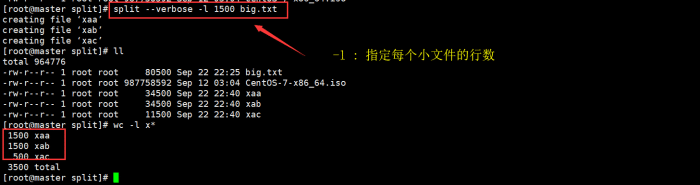
3.3 切分big.txt并指定每1500行保存1个文件
选项:
-l : 指定切分以后生成每个小文件的行数
命令:
split --verbose -l 1500 big.txt
3.4 切分big.txt时,指定每20K保存一个文件
选项:
-b : 指定切分以后生成小文件的大小
# split -b{bytes} {file_name} // 指定每个文件bytes个字节
# split -b nK {file_name} // 指定每个文件nK
# split -b nM {file_name} // 指定每个文件nM
# split -b nG {file_name} // 指定每个文件nG
命令:
split --verbose -b 20K big.txt
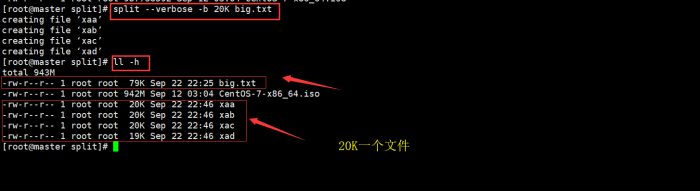
说明:
1. big.txt 文件共79KB,这里将20KB一个文件,所以有4个文件
3.5 切分big.txt时,生成的文件后缀使用数字结尾
选项:
-d : 使用数字替代字母,默认的从0开始。
命令:
split --verbose -d big.txt

3.6 切分big.txt时,指定前缀名称指定为big,并将后缀使用数字
选项:
-d : 使用数字替代字母,默认的从0开始。
命令:
split --verbose -d big.txt big

3.7 切分big.txt时,指定拆分成3个文件
选项:
-n : 指定拆分成小文件的个数
命令:
split --verbose -d -n 3 big.txt big
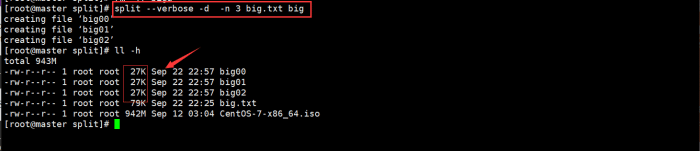
说明:
a. 每个小文件的大小都是27KB。但是我们总文件才79KB。
b. 所有使用-n指定个数时是将文件平均分配到这些小文件中(79 /3 + 1 = 27 )。
3.8 切分big.txt时,不生成空文件
假如有一个小文件,要将它切分成多个小文件。这样就有可能会切分出来空文件。
选项:
-e : 不切分成空文件
命令:
未使用-e选项
echo "elfgirl.top" >> small.txt
split -n20 small.txt
wc -l x*
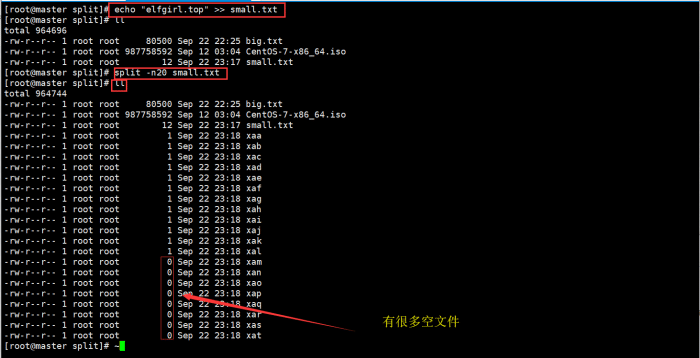
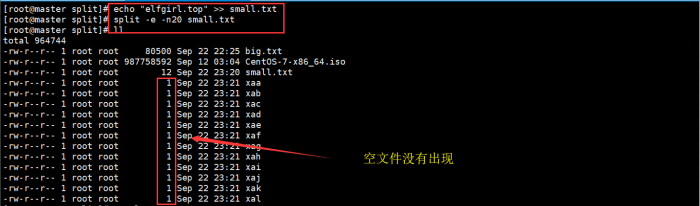
使用 -e 选项:
echo "elfgirl.top" >> small.txt
split -e -n20 small.txt
ll
3.9 切分big.txt时,指定每20K保存一个文件并且文件的后缀的长度为4
选项:
-a : 指定生成小文件后缀的长度(默认长度为2)
命令:
split -n3 -a4 big.txt

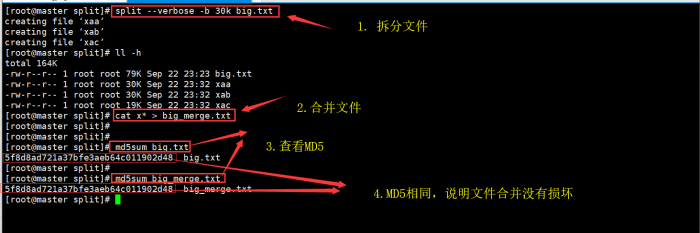
3.10 切分big.txt文件,指定每个切分以后的文件大小为30K,切分完成以后在将文件合并成big._merge.txt,并验证合成文件的MD5和源文件是否相同。
命令:
split --verbose -b 30k big.txt
ll -h
md5sum big.txt
md5sum big_merge.txt
四、总结
上面的案例基本上能够包含工作中能够使用到的所有情况,下面在总结一个split命令常用的参数(大部分上面的案例都涉及到了)。
|
选项 |
功能 |
|
--verbose |
每一步执行之前打印日志 |
|
-l |
指定切分以后生成每个小文件的行数 |
|
-b |
指定切分以后生成小文件的大小 # split -b{bytes} {file_name} // 指定每个文件bytes个字节 # split -b nK {file_name} // 指定每个文件nK # split -b nM {file_name} // 指定每个文件nM # split -b nG {file_name} // 指定每个文件nG |
|
-d |
使用数字替代字母,默认的从0开始。 |
|
-n |
指定拆分成小文件的个数 |
|
-e |
不切分成空文件 |
|
-a |
指定生成小文件后缀的长度(默认长度为2) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号