


第五部分开始,我新写的随笔是从python核心编程上总结的,详细查找可以在书中。
正则表达式是在书籍的第一章节。
之前写过一些爬虫的程序,所以对这方面还是挺熟悉的。不过既然是笔记就截取点容易忘的,当做笔记了。
在python中主要的正则表达式的库是re模块,但是对于爬虫来说,针对html的结构的爬取还有其他更方便的库,例如Xpath等,这在我写的新浪爬虫中都有。
以下贴以下正则的用法:
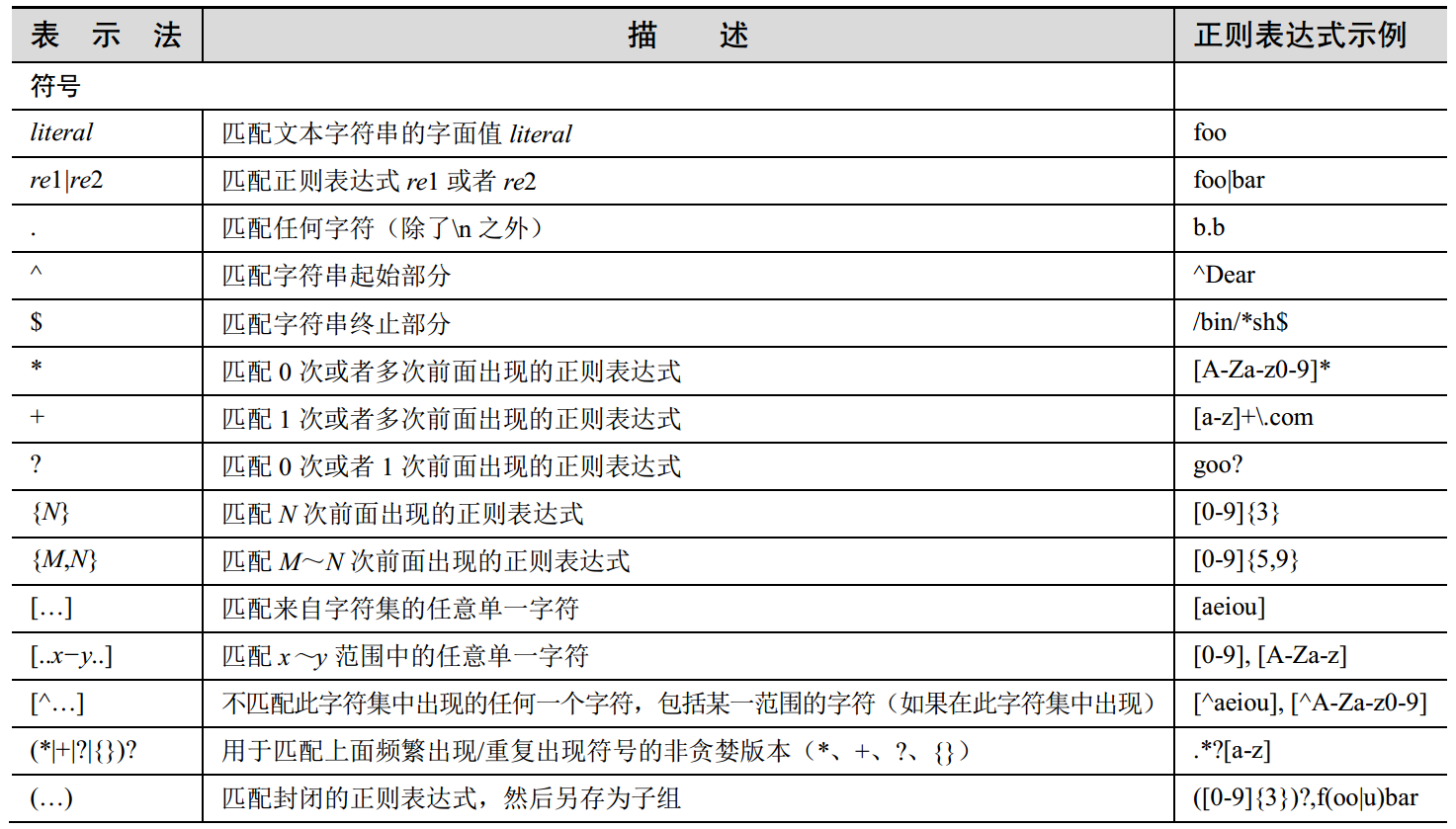
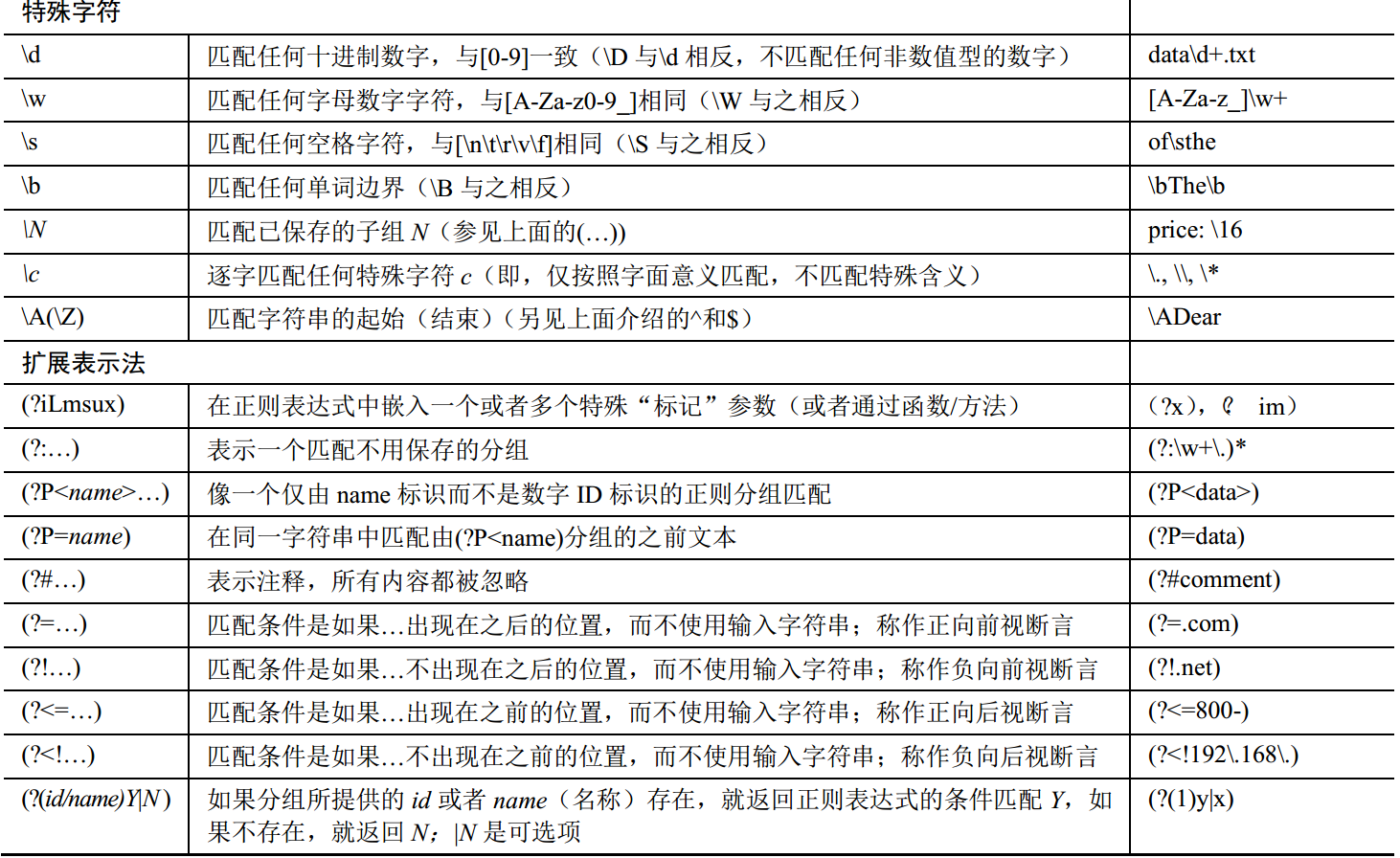
以上就是一些正则的表达式的意义。
特别需要注意的一点是,在匹配特殊字符的时候需要使用转义符号\,比如匹配点时候要用\.,否则就会和上边图中的.所冲突。
以下是re模块中的一些常用的函数:
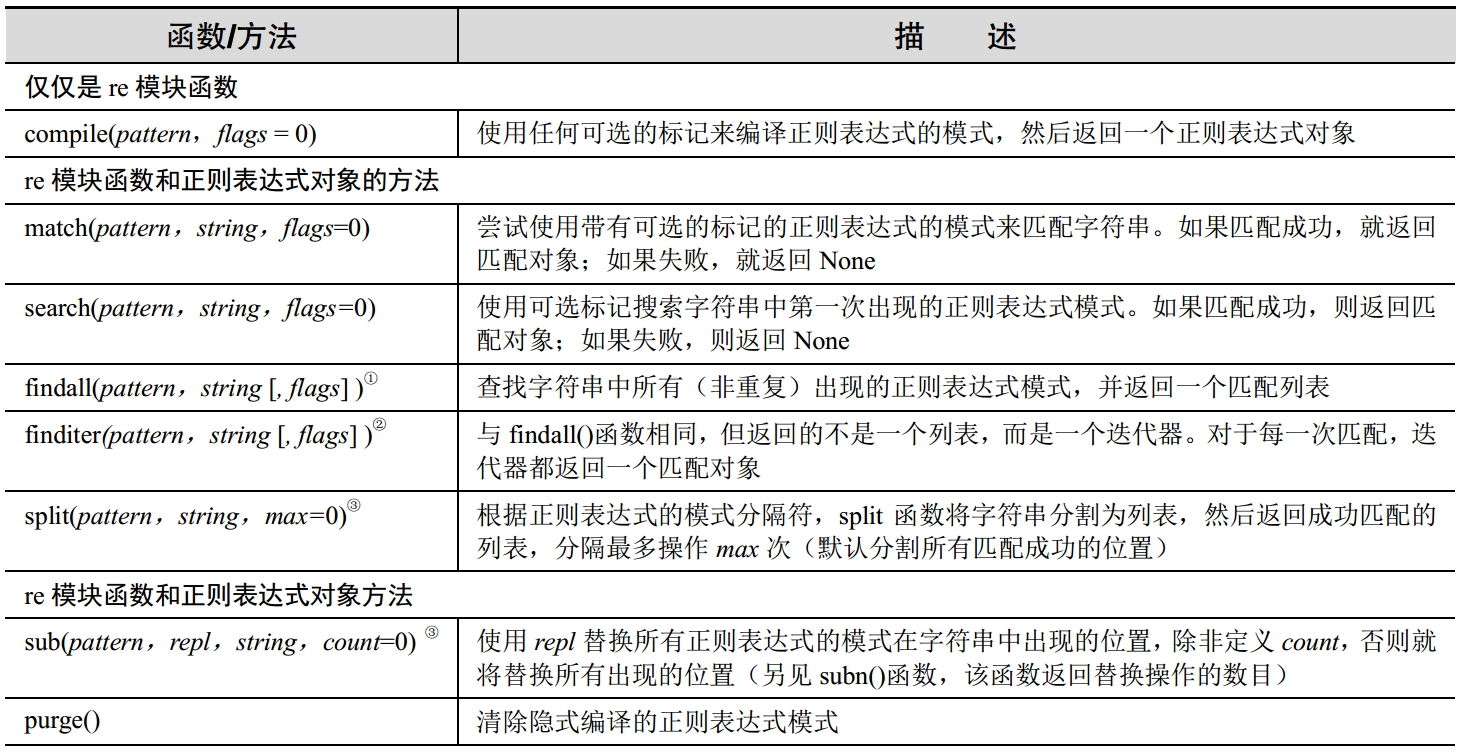
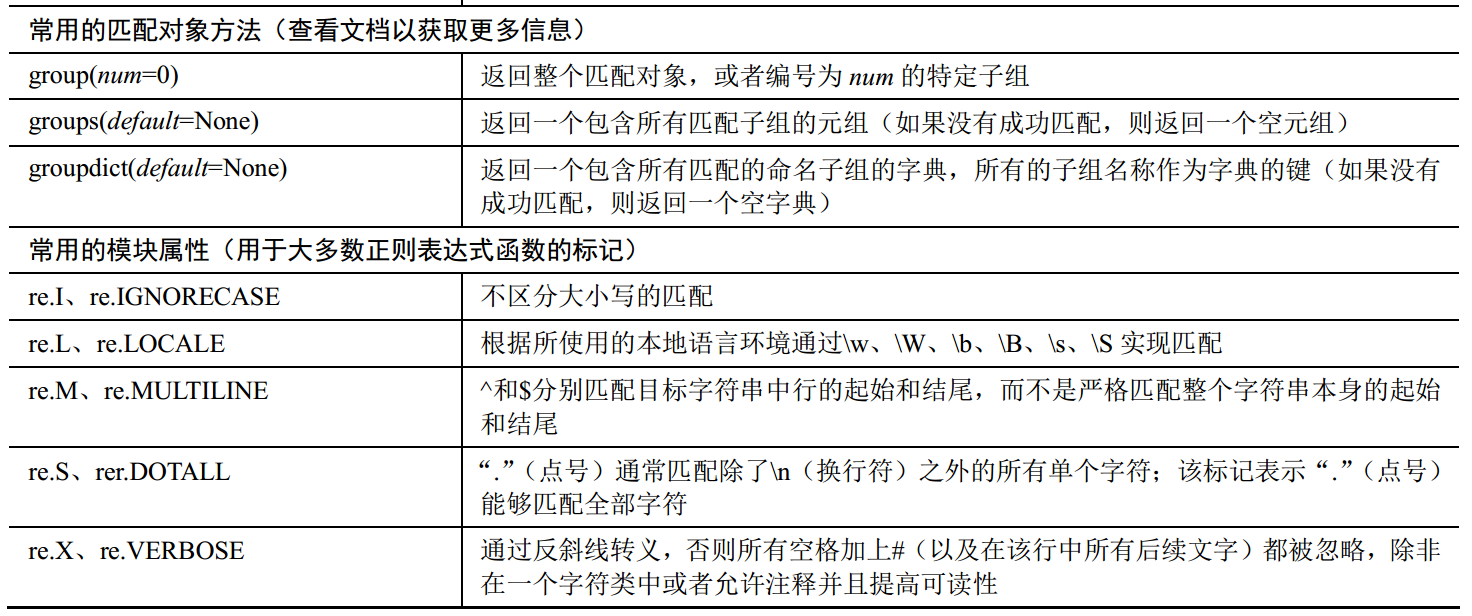
还有就是默认情况下,正则表达式将进行贪婪匹配。所谓“贪婪”,其实就是在多种长度的匹配字符串中,选择较长的那一个。例如,如下正则表达式本意是选出人物所说的话,但是却由于“贪婪”特性,出现了匹配不当:
1 >>> sentence = """You said "why?" and I say "I don't know".""" 2 >>> re.findall(r'"(.*)"', sentence) 3 ['why?" and I say "I don\'t know'] 4 5 再比如,如下的几个例子都说明了正则表达式“贪婪”的特性: 6 7 >>> re.findall('hi*', 'hiiiii') 8 ['hiiiii'] 9 >>> re.findall('hi{2,}', 'hiiiii') 10 ['hiiiii'] 11 >>> re.findall('hi{1,3}', 'hiiiii') 12 ['hiii']
当我们期望正则表达式“非贪婪”地进行匹配时,需要通过语法明确说明:
{2,5}? 捕获2-5次,但是优先次数少的匹配
在这里,问号?可能会有些让人犯晕,因为之前他已经有了自己的含义:前面的匹配出现0次或1次。其实,只要记住,当问号出现在表现不定次数的正则表达式部分之后时,就表示非贪婪匹配。
还是上面的那几个例子,用非贪婪匹配,则结果如下:
1 >>> re.findall('hi*?', 'hiiiii') 2 ['h'] 3 >>> re.findall('hi{2,}?', 'hiiiii') 4 ['hii'] 5 >>> re.findall('hi{1,3}?', 'hiiiii') 6 ['hi'] 7 8 另外一个例子中,使用非贪婪匹配,结果如下: 9 10 >>> sentence = """You said "why?" and I say "I don't know".""" 11 >>> re.findall(r'"(.*?)"', sentence) 12 ['why?', "I don't know"]
?=表示的意义是
这个叫断言,只匹配一个位置
比如,你想匹配一个“人”字,但是你只想匹配中国人的人字,不想匹配法国人的人
就可以用一下表达式
(?=中国)人
所以,表达式与其他通配符连用才能起到效果。
(?=.*[a-z])\d+
这个就表示 匹配以“任意字符连着一个小写字母”开头的数字,只匹配数字。
与之相对的是(?<=exp)这个是放后面的。
另外还需要注意的一点是在字符串前加上r,表示原始字符串,即字符串中的所有符号都表示一个字符,而没有特殊含义。
例如:r'\tss' 输出之后为\ss,而没有r则输出为 ss,即前边一个tab,后边两个ss。
最后,对于想要更深入研究正则表达式的,建议阅读由 Jeffrey E. F. Friedl.编写的
Mastering Regular Expressions

 浙公网安备 33010602011771号
浙公网安备 33010602011771号