
Python高级应用程序设计任务
2019-12-21 15:31 QW`ER 阅读(290) 评论(0) 收藏 举报Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
豆瓣电影排行榜
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取的内容
电影名,种类,导演,来源地,时间等
2.2数据特征分析
分析不同电影的评价
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1、通过requests的get方法请求网站地址,并进行头部信息验证
2、BeautifulSoup网页解析
3、判断所要的数据是否存在,并进行切片处理
4、并通过循环进行翻页处理
5、通过os、DataFrame进行数据的保存,以便后期进行数据分析和数据清洗
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
使用bs4提供的find_all()方法,按照条件返回标签内容。
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests import xlwt from bs4 import BeautifulSoup from collections import Counter import collections import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['font.size'] = 6.0 import time import random import jieba # 中文分词包 from wordcloud import WordCloud # 词云包 import re # 正则表达式包 headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36', 'Host':'movie.douban.com' } ## data needed movie_list_english_name = [] movie_list_chinese_name = [] director_list = [] time_list = [] star_list = [] reviewNum_list = [] quote_list = [] nation_list = [] category_list = [] num = 0 for i in range(0, 10): link = 'https://movie.douban.com/top250?start=' soup = BeautifulSoup(res.text, "lxml") div_title_list = soup.find_all('div', class_ = 'hd') div_info_list = soup.find_all('div', class_ = 'bd') div_star_list = soup.find_all('div', class_ = 'star') div_quote_list = soup.find_all('p', class_ = 'quote') for each in div_title_list: movie = each.a.span.text.strip() # 得到第一个字段 movie_list_chinese_name.append(movie) # 通过css 定位得到第二个字段,从而得到英文名字 div_title_list2 = soup.select('div.hd > a > span:nth-of-type(2)') for each in div_title_list2: movie = each.text #movie = movie.replace(u'\xa0', u' ') movie = movie.strip('\xa0/\xa0') # 去掉英文名字中的空格 movie_list_english_name.append(movie) for each in div_info_list: num += 1 info = each.p.text.strip() if len(info) < 3: # 筛选掉不符合条件的信息 continue # 搜索电影上映年代 lines = info.split('\n') # 将信息按照换行符分割成不同句子 time_start = lines[1].find('20') if time_start < 0: time_start = lines[1].find('19') time_len = lines[1][time_start : time_start + 4] time_list.append(time_len) time_end = time_start + 4 # 搜索电影导演中文名 end = info.find('主') if end < 0: end = info.find('...') director = info[4 : end - 3] director_list.append(director) # 搜索电影来源地 frequent = 0 start = 0 end = 0 line2 = lines[1] for j in range(len(line2)): if line2[j] == '\xa0': frequent += 1 if frequent == 2 and start == 0: start = j + 1 if frequent == 3: end = j break nation = line2[start : end] nation_list.append(nation) # 搜索电影类型 frequent = 0 start = 0 for j in range(len(line2)): if line2[j] == '\xa0': frequent += 1 if frequent == 4 and start == 0: start = j + 1 category = line2[start : len(line2)] category_list.append(category) # 搜索电影评分 for each in div_star_list: info = each.text.strip() star = float(info[0 : 3]) star_list.append(star) end = info.find('人') reviewNum = int(info[3 : end]) reviewNum_list.append(reviewNum) # 搜索电影代表评论 for each in div_quote_list: info = each.text.strip() quote_list.append(info) file = xlwt.Workbook() table = file.add_sheet('sheet1', cell_overwrite_ok = True) table.write( 0, 0, "排名") table.write( 0, 1, "电影中文名") table.write( 0, 2, "电影其他名") table.write( 0, 3, "时间") table.write( 0, 4, "导演") table.write( 0, 5, "国家或地区") table.write( 0, 6, "评分") table.write( 0, 7, "评分人数") table.write( 0, 8, "电影类型") table.write( 0, 9, '代表性评论') for i in range(len(nation_list)): table.write(i + 1, 0, i + 1) table.write(i + 1, 1, movie_list_chinese_name[i]) table.write(i + 1, 2, movie_list_english_name[i]) table.write(i + 1, 3, time_list[i]) table.write(i + 1, 4, director_list[i]) table.write(i + 1, 5, nation_list[i]) table.write(i + 1, 6, star_list[i]) table.write(i + 1, 7, reviewNum_list[i]) table.write(i + 1, 8, category_list[i]) table.write(i + 1, 9, quote_list[i]) # 导出到 xls 文件里 file.save('豆瓣 top 10 电影爬虫抓取.xls')
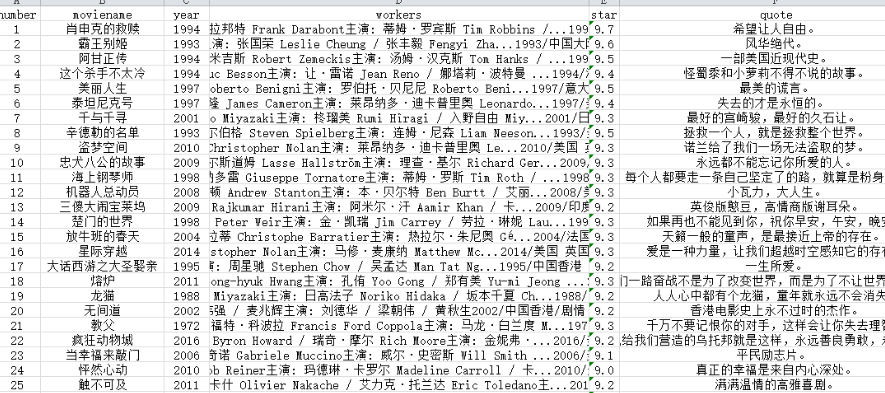
2.对数据进行清洗和处理
3.文本分析(可选):
jieba分词、wordcloud可视化
4.数据分析与可视化
star_dict = dict(zip(movie_list_chinese_name, star_list)) star_sort = sorted(star_dict.items(), key = lambda x: x[1], reverse = True) #排序 star_sort = collections.OrderedDict(star_sort) values = [] labels=[] for i in range(10): labels.append(list(star_sort.keys())[i]) values.append(list(star_sort.values())[i]) bar = plt.barh(range(10), width = values, tick_label = labels, color = 'rgbycmrgby') for i, v in enumerate(values): # 柱状图添加数字 plt.text(v + 0.05, i - 0.1, str(v), color = 'blue', fontweight = 'bold') plt.xlim(xmax = 10, xmin = 8) plt.title('评分最高的十部电影') plt.show()

# 评分人数最多的十部电影 review_dict = dict(zip(movie_list_chinese_name, reviewNum_list)) review_sort = sorted(review_dict.items(), key = lambda x: x[1], reverse = True) #排序 review_sort = collections.OrderedDict(review_sort) values = [] labels=[] for i in range(10): labels.append(list(review_sort.keys())[i]) values.append(list(review_sort.values())[i]) bar = plt.barh(range(10), width = values, tick_label = labels, color = 'rgbycmrgby') for i, v in enumerate(values): # 柱状图添加数字 plt.text(v + 10000, i - 0.1, str(v), color = 'blue', fontweight = 'bold') plt.xlim(xmax = 1450000, xmin = 400000) plt.title('评分人数最多的十部电影') plt.show( )
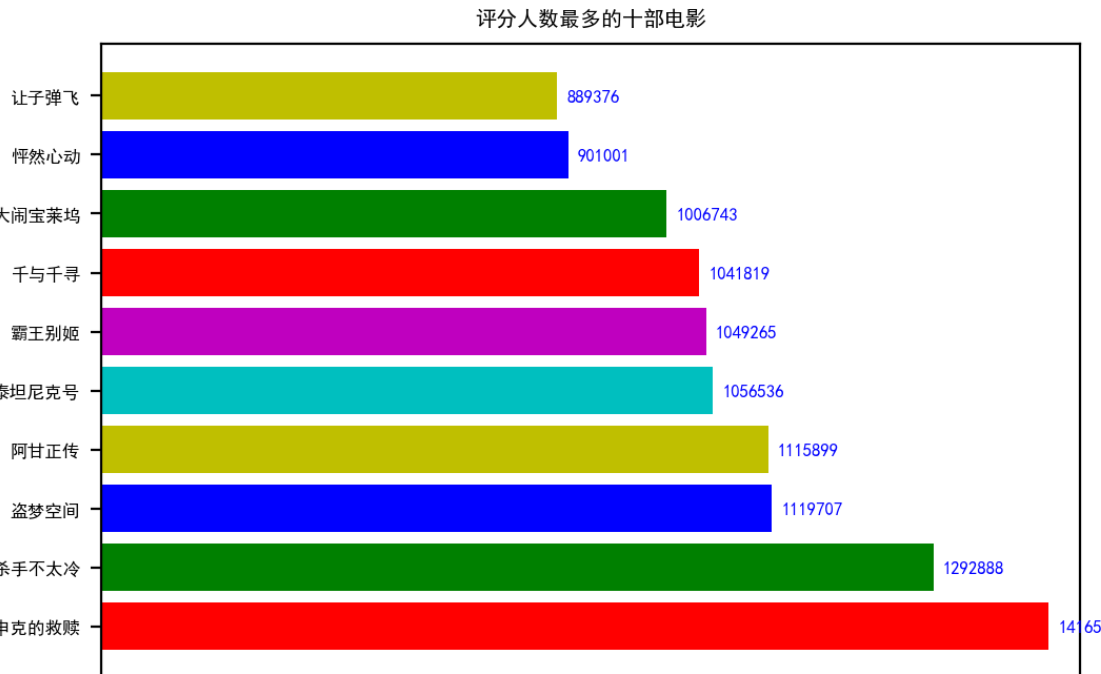
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化
6.附完整程序代码
import requests import xlwt from bs4 import BeautifulSoup from collections import Counter import collections import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['font.size'] = 6.0 import time import random import jieba # 中文分词包 from wordcloud import WordCloud # 词云包 import re # 正则表达式包 headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36', 'Host':'movie.douban.com' } ## data needed movie_list_english_name = [] movie_list_chinese_name = [] director_list = [] time_list = [] star_list = [] reviewNum_list = [] quote_list = [] nation_list = [] category_list = [] num = 0 for i in range(0, 10): link = 'https://movie.douban.com/top250?start=' soup = BeautifulSoup(res.text, "lxml") div_title_list = soup.find_all('div', class_ = 'hd') div_info_list = soup.find_all('div', class_ = 'bd') div_star_list = soup.find_all('div', class_ = 'star') div_quote_list = soup.find_all('p', class_ = 'quote') for each in div_title_list: movie = each.a.span.text.strip() # 得到第一个字段 movie_list_chinese_name.append(movie) # 通过css 定位得到第二个字段,从而得到英文名字 div_title_list2 = soup.select('div.hd > a > span:nth-of-type(2)') for each in div_title_list2: movie = each.text #movie = movie.replace(u'\xa0', u' ') movie = movie.strip('\xa0/\xa0') # 去掉英文名字中的空格 movie_list_english_name.append(movie) for each in div_info_list: num += 1 info = each.p.text.strip() if len(info) < 3: # 筛选掉不符合条件的信息 continue # 搜索电影上映年代 lines = info.split('\n') # 将信息按照换行符分割成不同句子 time_start = lines[1].find('20') if time_start < 0: time_start = lines[1].find('19') time_len = lines[1][time_start : time_start + 4] time_list.append(time_len) time_end = time_start + 4 # 搜索电影导演中文名 end = info.find('主') if end < 0: end = info.find('...') director = info[4 : end - 3] director_list.append(director) # 搜索电影来源地 frequent = 0 start = 0 end = 0 line2 = lines[1] for j in range(len(line2)): if line2[j] == '\xa0': frequent += 1 if frequent == 2 and start == 0: start = j + 1 if frequent == 3: end = j break nation = line2[start : end] nation_list.append(nation) # 搜索电影类型 frequent = 0 start = 0 for j in range(len(line2)): if line2[j] == '\xa0': frequent += 1 if frequent == 4 and start == 0: start = j + 1 category = line2[start : len(line2)] category_list.append(category) # 搜索电影评分 for each in div_star_list: info = each.text.strip() star = float(info[0 : 3]) star_list.append(star) end = info.find('人') reviewNum = int(info[3 : end]) reviewNum_list.append(reviewNum) # 搜索电影代表评论 for each in div_quote_list: info = each.text.strip() quote_list.append(info) file = xlwt.Workbook() table = file.add_sheet('sheet1', cell_overwrite_ok = True) table.write( 0, 0, "排名") table.write( 0, 1, "电影中文名") table.write( 0, 2, "电影其他名") table.write( 0, 3, "时间") table.write( 0, 4, "导演") table.write( 0, 5, "国家或地区") table.write( 0, 6, "评分") table.write( 0, 7, "评分人数") table.write( 0, 8, "电影类型") table.write( 0, 9, '代表性评论') for i in range(len(nation_list)): table.write(i + 1, 0, i + 1) table.write(i + 1, 1, movie_list_chinese_name[i]) table.write(i + 1, 2, movie_list_english_name[i]) table.write(i + 1, 3, time_list[i]) table.write(i + 1, 4, director_list[i]) table.write(i + 1, 5, nation_list[i]) table.write(i + 1, 6, star_list[i]) table.write(i + 1, 7, reviewNum_list[i]) table.write(i + 1, 8, category_list[i]) table.write(i + 1, 9, quote_list[i]) # 导出到 xls 文件里 file.save('豆瓣 top 10 电影爬虫抓取.xls') # 分析电影来源地 locations = [] for i in range(len(nation_list)): nations = nation_list[i].split(' ') for j in range(len(nations)): if nations[j] == '西德': nations[j] = '德国' locations.append(nations[j]) result = Counter(locations) result_sort = sorted(result.items(), key = lambda x: x[1], reverse = True) result_sort = collections.OrderedDict(result_sort) othervalue = 0 for i in range(10, len(result)): othervalue += list(result_sort.values())[i] # 画饼状图 def make_autopct(values): # 定义饼状图中数字显示方式 def my_autopct(pct): total = sum(values) val = int(round(pct*total/100.0)) return '{p:.1f}%({v:d})'.format(p = pct, v = val) return my_autopct values = [] labels = [] for i in range(10): values.append(list(result_sort.values())[i]) labels.append(list(result_sort.keys())[i]) values.append(othervalue) labels.append('其他地区') plt.rcParams['savefig.dpi'] = 200 # 定义图形清晰度 plt.rcParams['figure.dpi'] = 200 #set dpi for figure w, l, p = plt.pie(values, explode = [0.02 for i in range(11)], labels = labels, pctdistance = 0.8, radius = 1, rotatelabels = True, autopct = make_autopct(values)) [t.set_rotation(315) for t in p] # 设置标签旋转 plt.title('豆瓣 TOP10 电影来源地', y = -0.1) plt.show() # 分析电影类型,analysis categories categories = [] for i in range(len(category_list)): category = category_list[i].split(' ') for j in range(len(category)): categories.append(category[j]) result = Counter(categories) result_sort = sorted(result.items(), key = lambda x: x[1], reverse = True) #排序 result_sort = collections.OrderedDict(result_sort) othervalue = 0 for i in range(15, len(result)): othervalue += list(result_sort.values())[i] # draw the pie picture using matplotlib values = [] labels = [] for i in range(15): values.append(list(result_sort.values())[i]) labels.append(list(result_sort.keys())[i]) values.append(othervalue) labels.append('其他类型') plt.rcParams['savefig.dpi'] = 200 # 定义图形清晰度 plt.rcParams['figure.dpi'] = 200 w, l, p = plt.pie(values, explode = [0.02 for i in range(16)], labels = labels, pctdistance = 0.8, radius = 1, rotatelabels = True, autopct = make_autopct(values)) [t.set_rotation(315) for t in p] plt.title('豆瓣 TOP250 电影种类', y = -0.1) plt.show() # word cloud jieba.add_word('久石让') jieba.add_word('谢耳朵') # 一些语气词和没有意义的词 del_words = ['的', ' ', '人', '就是', '一个', '被', '不是', '也', '最', '了', '才', '给', '要', '就', '让', '在', '都', '是', '与', '和', '不', '有', '我', '你', '能', '每个', '不会', '中', '没有', '这样', '那么', '不要', '如果', '来', '它', '对', '当', '比', '不能', '却', '一种', '而', '不过', '只有', '不得不', '再', '不得不', '比', '一部', '啦', '他', '像', '会', '得', '里'] all_quotes = ''.join(quote_list) # 将所有代表性评论拼接为一个文本 # 去掉标点符号 all_quotes = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+", " ", all_quotes) words = jieba.lcut(all_quotes) words_final = [] for i in range(len(words)): # 去掉一些语气词,没有意义的词。 if words[i] not in del_words: words_final.append(words[i]) text_result = Counter(words_final) cloud = WordCloud( font_path = 'FZSTK.TTF', background_color = 'white', width = 1000, height = 860, max_words = 40 ) wc = cloud.generate_from_frequencies(text_result) wc.to_file("豆瓣 TOP 10 词云.jpg") plt.figure() plt.imshow(wc) plt.axis('off') plt.title('豆瓣 TOP 10 电影代表性评论的词云分析') plt.show() # 评分最高的十部电影 star_dict = dict(zip(movie_list_chinese_name, star_list)) star_sort = sorted(star_dict.items(), key = lambda x: x[1], reverse = True) #排序 star_sort = collections.OrderedDict(star_sort) values = [] labels=[] for i in range(10): labels.append(list(star_sort.keys())[i]) values.append(list(star_sort.values())[i]) bar = plt.barh(range(10), width = values, tick_label = labels, color = 'rgbycmrgby') for i, v in enumerate(values): # 柱状图添加数字 plt.text(v + 0.05, i - 0.1, str(v), color = 'blue', fontweight = 'bold') plt.xlim(xmax = 10, xmin = 8) plt.title('评分最高的十部电影') plt.show() # 评分人数最多的十部电影 review_dict = dict(zip(movie_list_chinese_name, reviewNum_list)) review_sort = sorted(review_dict.items(), key = lambda x: x[1], reverse = True) #排序 review_sort = collections.OrderedDict(review_sort) values = [] labels=[] for i in range(10): labels.append(list(review_sort.keys())[i]) values.append(list(review_sort.values())[i]) bar = plt.barh(range(10), width = values, tick_label = labels, color = 'rgbycmrgby') for i, v in enumerate(values): # 柱状图添加数字 plt.text(v + 10000, i - 0.1, str(v), color = 'blue', fontweight = 'bold') plt.xlim(xmax = 1450000, xmin = 400000) plt.title('评分人数最多的十部电影') plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)豆瓣电影top10中评分多为9分以上
(2)豆瓣电影top10中电影评分相对集中
(3)豆瓣电影top10中分数最高的为9.7,最低的为9.3
(4)豆瓣电影top10中评分高的评价人数也会相对多一些
2.对本次程序设计任务完成的情况做一个简单的小结。
在写程序的过程中,发现程序能执行并不仅仅只局限在于所学习到的方法,而是能够根据人的需求不断的健壮,对爬虫的综合应用,更加了解爬虫的好处,更加有针对性的解决自己所碰到的困难,从大数据看出社会的需求。
通过本次程序设计,我知道自己还有很大的提升空间,未来会继续学习研究,不断尝试,让自己能更好的掌握这门语言。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号