
JavaScript语言是如何构建起来的
JavaScript语言构建的核心-> 静态语法的核心 -> 声明的核心 -> 标识符和值的绑定
1. JavaScript 销毁
-
什么是引用类型呢?
引用它是一个数据结构,存储了一个计算的结果,以及可以传递这些结果。 -
delete 删除
delete 运算符尝试删除值数据时,会返回 true,用于表示没有错误
delete是在删除 一个表达式的(本质是求值)、引用类型的result-> 结果是一个值/一个引用。- delete 0 本质是删除一个表达式的值
- delete x 本质是删除一个表达式的引用;
- delete其实只能删除一种引用,即对象的成员( obj.x),
所以,只有在delete x等值于delete obj.x时 delete 才会有执行意义。
2. 声明语句与语法
- 声明和语句的区别
在于发生的时间点不同,声明发生在编译期,语句发生在运行期。
声明发生在编译期,由编译器为声明的变量在相应的变量表增加一个名字,没有返回值(empty)。--静态语言的处理
语句是在运行时执行的程序代码。因此,如果声明不带初始化,那么可以完全由编译器完成。--动态语言的处理。 - 变量声明在引擎的处理上被分成两个部分:
一部分是静态的、基于标识符的词法分析和管理,它总是在相应上下文的环境构建时作为名字创建的;
另一部分是表达式执行过程,使用初始器对名字赋值绑定。 - 变量泄露
“向一个不存在(未声明)的变量赋值”所导致的变量泄露是不可避免的 => 隐式声明了全局变量 y = 100 - 例:var x=y=100中,x 和 y 是两个不同的东西,前者是声明的名字,后者是一个赋值过程可能创建的变量名。
3. 表达式
-
表达式执行与语句声明区别:
表达式左侧的操作数可以是另一个表达式, x=y=100中 y=100是赋值运算,x=...是表达式,
“var 声明”语句中的等号左边,x作为标识符, var x=100是值绑定操作 -
a.x=a={n:2}结果?
var a={n:1},ref=a;
a.x=a={n:2};
console.log(ref.x);//-->{n:2}
console.log(a.x);//-->undefined
// 产生一个新的a覆盖原始的变量a;“原始的变量a,“a.x”在引用传递中丢失了。
// 如果有变量、属性或者闭包等,持有了这个“原始的变量a”,那么“a, a.x”不会丢失。
4. 模块&匿名函数表达式
- 模块导出的内容
名字和值: 标识符(名字);字面量(由字面含义决定的值);模板(可计算结果的字符串值)
export default ...值'default'是收敛到的唯一的名字 - 导出语句的处理逻辑:
导出一个名字,以及为其绑定一个值 - 导出名字与导出值的差异
本质上并没有差异,在静态装配的阶段,它们都表达为一个名字。// 两者等价 export default function(){} - 模块装载执行和标识符绑定全过程
首先export语句声明 初始化名字,再依赖 import形成依赖树,
执行顶层代码(import),遍历依赖树,给名字绑定值,进行‘变量提升’。
全程没有表达式被执行!(源代码被理解为静态的,没有逻辑的) - export default function(){}:
并不是导出了一个匿名函数表达式,而是导出了一个匿名函数定义,名字是“default”
无法导出一个匿名函数表达式.(源代码被理解为静态的,没有逻辑的 - 所谓匿名函数,仅仅是当它直接作为操作数时,才是真正匿名的
5. 块级作用域的识别与处理
-
for循环并不比使用函数递归节省开销
循环与函数递归在语义上等价,所以for语句(多行循环体,有大括号)本质上与“在函数参数中传递循环变量的递归过程”完全等价,在开销上也是完全一样的。 -
块级作用域->解决变量提升存在的变量覆盖、变量污染问题
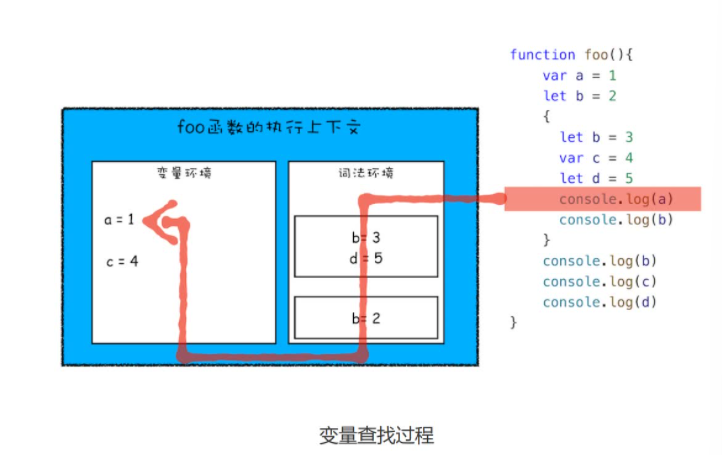
- 如何支持变量提升和块级作用域?- 执行上下文构成: 变量环境+词法环境+可执行代码
- 变量环境 管理var声明和函数声明(代码块)的标识符,变量提升是通过变量环境来实现,在更外围的作用域中登记名字行为就称为“提升”
- 词法环境 管理其它情况下的标识符/变量声明(let/const),通过词法环境的栈结构来实现的,
![]()
-
单语句没有块级作用域,不支持词法声明
-
块语句在每次迭代都会创建一次块级作用域副本。
循环体越大,支持的层次越多,环境的创建也就越频繁,代价越高昂。
加上可以使用函数闭包将环境传递出去,或交给别的上下文引用,负担就更是雪上加霜了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号