glidedsky-爬虫-雪碧图-1
这一次分享的是雪碧图,先看看题目。


这个题目关键的地方其实就是识别出图片中的数字,先看一下源码。

在<style></style>里面找到,这个sprite存的就是图片的信息,将base64后面的字符串解码后,保存成图片格式就可以得到图片了。
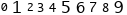 下载下来的图片是这样子的,从0到9。
下载下来的图片是这样子的,从0到9。
那下面来看网页上的数字是怎么对应起来的。
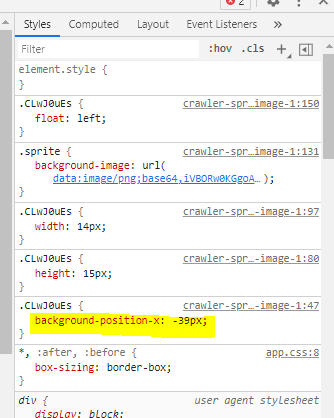
打开开发者模式,定位到某一个数字上,可以看到这些样式,注意到backgrond-position-x这个属性,初步怀疑是图片上的某个点的位置,打开下载下来的图片,使用画图来定位一下。

大概是数字3的位置,但是因为每次刷新图片都是不一样的,所以这个每个数字的backgrond-position-x是会变的。这里有一个做法就是刷新多一点,找到位置的大概范围,然后直接对应上数字,这个方法很暴力,但是我觉得容易出错,所以换了另一种思路。就是先将图片上的数字抠出来,按0-9排列,9个数字就可以通过下标对应起来了,将这一个排列好的数字称为模板,然后再提取每个div中的属性,从图片中提出网页上显示的那个数字,再和模板中的数字进行匹配,匹配上了,那就可以对应上数字了。
首先是提取网页上显示的数字;第一步将<style></style>里面的属性用一个字典的形式保存起来,这里主要用到的是每个class里面的宽度width和偏移的位置position;第二步将sprite里面图片保存下来,然后以一个<div class="col-md-1">为单位遍历它下面的div获得每一个显示数字的class名,再从第一步保存好的字典提取里面的width和position;最后根据width和position在保存下来的图片截取对应的数字。

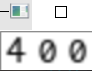





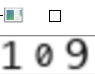


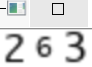
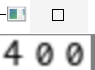
这里第一页的每个数字都提取出来了,为了方便展示,就将每个数字都合并起来了。
下面就是要创建数字的模板,主要方法是找到每个数字的外轮廓,然后通过轮廓计算出它的外界矩形,然后按照从左到右的顺序排列,那么0-9就对应着数字0-9。首先是将图片放大两倍,图片太小对轮廓的计算会有影响,然后将图片从bgr转为灰度的,再通过阈值处理将图片处理成二值图像,因为cv2的findContours函数只能处理二值图像。

这里将轮廓都画了出来,但是有很多是不需要的轮廓,比如最外面的长方形框,还有0,4,6,8,9中间的轮廓,因为每个轮廓保存的是点的信息,这些不需要的轮廓的点都比较少,所以这里只使用长度大于15的轮廓。

那么就剩下0-9,10个数字的轮廓了,但是这里的轮廓不是按照从左到右排序的,所以要先对这10个轮廓进行排序。
def sort_contours(cnts, method="left-to-right"): reverse = False i = 0 if method == "right-to-left" or method == "bottom-to-top": reverse = True if method == "top-to-bottom" or method == "bottom-to-top": i = 1 boundingBoxes = [cv2.boundingRect(c) for c in cnts] # 用一个最小的矩形,把找到的形状包起来x,y,h,w (cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes), key=lambda b: b[1][i], reverse=reverse)) return cnts, boundingBoxes
cnts是findContours函数返回的轮廓列表。
refCnts = sort_contours([c for c in contours if len(c) > 15], method="left-to-right")[0] digits = {} # 遍历每一个轮廓 for (i, c) in enumerate(refCnts): # 计算外接矩形并且resize成合适大小 (x, y, w, h) = cv2.boundingRect(c) roi = ref[y:y + h, x:x + w] # 每一个数字对应每一个模板 digits[i] = roi return digits
这样就可以得到一个模板了,然后将上面提取到的每个数字,按同样的方式处理,首先是放大两倍,然后转为灰度图片,再进行二值化处理,最后使用cv2.mathTemplate函数就可以匹配模板了。
scores = [] for i, roi in digits.items(): result = cv2.matchTemplate(num_ref, roi, cv2.TM_CCOEFF) min_val, max_val, min_indx, max_indx = cv2.minMaxLoc(result) scores.append(max_val) out.append(str(np.argmax(scores)))
最后的np.argmax就是提出最匹配的那个模板的index,就是对应着相应的数字。out用来存储每一组的数字,最后把数字合并起来,就是网页上显示的数字了。

遍历每一页的数字,都加起来,就得到答案了。这里注意的是有时候进行模板匹配的时候会报错,所以我使用了while循环去遍历每一页,加上异常处理,当出错的时候就重新请求一次,没有出错了就把数字加起来,然后页数再加一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号