Java面试题180309
面试岗位:Java后端开发实习生
面试时间:2018年3月9日下午3:00
1.面向对象的特征有哪些方面?
原文链接:https://www.cnblogs.com/xilichenbokeyuan/p/6382627.html
1.封装:封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面,面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治,封装的对象,这些对象通过一个受保护的接口访问其他对象 2.继承:继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表达共性的方法,对象的一个新类可以从现在的类中派生,这个过程成为继承,新类继承了原始类的特性,新类成为原始类的派生类,而原始类称为新类的基类,派生类可以从他的基类那里继承方法和实例变量,并且类可以修改或增加新的方法使之更加适合特殊的需求 3.抽象:抽象就是忽略一个主题中与当前目标无关的那些方面,以便充分的注意与当前目标有关的方面,抽象包括两个方面,一个是过程抽象,二是数据抽象 4.多态性:多态性是指允许不同类的对象对同一消息作出响应,多态性包括参数化多态性和包含多态性,多态性语言具有灵活,抽象,行为共享,代码共享的优势,很好的解决了应用程序函数同名的问题
2.访问修饰符public、private、protected,以及不写(默认)时的区别?
原文链接:https://www.cnblogs.com/jiangyi-uestc/p/5743600.html

类的成员不写访问修饰符默认为default,默认对于同一个包的其他类相当于公开(public),对于不是同一个包的其他类相当于私有(private)。
受保护(protected)对子类相当于公开,对于不是同一个包没有父子关系的类相当于私有。
Java中,外部类的修饰符只能是public或默认,类的成员(包括内部类)的修饰符可以是以上四种。
3.基本数据类型有哪些?
原文链接:http://blog.csdn.net/hz_lizx/article/details/54928915
问:String 是最基本的数据类型吗? 答:不是。 Java中的基本数据类型只有8个:byte、short、int、long、float、double、char、boolean; 除了基本类型(primitive type)和枚举类型(enumeration type), 剩下的都是引用类型(reference type),包括(字符串)String,(类)class、(接口)interface、(数组)Array,Map也只能算是引用数据类型了。
4.int和Integer有什么区别?&和&&的区别?
原文链接:https://www.cnblogs.com/guodongdidi/p/6953217.html
int和Integer的区别 1、Integer是int的包装类,int则是java的一种基本数据类型 2、Integer变量必须实例化后才能使用,而int变量不需要 3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值 4、Integer的默认值是null,int的默认值是0 延伸: 关于Integer和int的比较 1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。 Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false 2、Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较) Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true 3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同) Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false 4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false Integer i = 100; Integer j = 100; System.out.print(i == j); //true Integer i = 128; Integer j = 128; System.out.print(i == j); //false 对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下: public static Integer valueOf(int i){ assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <= IntegerCache.high){ return IntegerCache.cache[i + (-IntegerCache.low)]; } return new Integer(i); } java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了 如果有错误的地方,还请指正。 参考: http://blog.csdn.net/you23hai45/article/details/50734274 http://www.cnblogs.com/liuling/archive/2013/05/05/intAndInteger.html
5.用最有效率的方法计算2乘以8?
原文链接:http://blog.csdn.net/lihaiyun718/article/details/6881164
Java中用最有效率的方法算出2 乘以8 等於几? 2 << 3, 因为将一个数左移n 位,就相当于乘以了2 的n 次方,那么,一个数乘以8 只要将其左移3 位 即可,而位运算cpu 直接支持的,效率最高,所以,2 乘以8 等於几的最效率的方法是2 << 3。 //计算2*8=2*23 System.out.println(2<<3);//8=2的3次方为8 //计算2*16=2*24 System.out.println(2<<4);//16=2的4次方为16 //计算3*8=2*23 System.out.println(3<<3);//8=2的3次方为8 //计算5*8=5*23 System.out.println(5<<3);//8=2的3次方为8 //计算6*4=6*22 System.out.println(6<<2);//4=2的2次方为4 JavaCode int i = 1; System.err.println(i-=i+=i-=i+=i-=i--);
6.String和StringBuilder、StringBuffer的区别?
原文链接:https://www.cnblogs.com/su-feng/p/6659064.html
最近在学习Java的时候,遇到了这样一个问题,就是String,StringBuilder以及StringBuffer这三个类之间有什么区别呢,自己从网上搜索了一些资料,有所了解了之后在这里整理一下,便于大家观看,也便于加深自己学习过程中对这些知识点的记忆,如果哪里有误,恳请指正。 这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。 首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String String最慢的原因: String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。以下面一段代码为例: 1 String str="abc"; 2 System.out.println(str); 3 str=str+"de"; 4 System.out.println(str); 如果运行这段代码会发现先输出“abc”,然后又输出“abcde”,好像是str这个对象被更改了,其实,这只是一种假象罢了,JVM对于这几行代码是这样处理的,首先创建一个String对象str,并把“abc”赋值给str,然后在第三行中,其实JVM又创建了一个新的对象也名为str,然后再把原来的str的值和“de”加起来再赋值给新的str,而原来的str就会被JVM的垃圾回收机制(GC)给回收掉了,所以,str实际上并没有被更改,也就是前面说的String对象一旦创建之后就不可更改了。所以,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢。 而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。 另外,有时候我们会这样对字符串进行赋值 1 String str="abc"+"de"; 2 StringBuilder stringBuilder=new StringBuilder().append("abc").append("de"); 3 System.out.println(str); 4 System.out.println(stringBuilder.toString()); 这样输出结果也是“abcde”和“abcde”,但是String的速度却比StringBuilder的反应速度要快很多,这是因为第1行中的操作和 String str="abcde"; 是完全一样的,所以会很快,而如果写成下面这种形式 1 String str1="abc"; 2 String str2="de"; 3 String str=str1+str2; 那么JVM就会像上面说的那样,不断的创建、回收对象来进行这个操作了。速度就会很慢。 2. 再来说线程安全 在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的 如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。 3. 总结一下 String:适用于少量的字符串操作的情况 StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况 StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
7.重载(Overload)和重写(Override)的区别。重载的方法能否根据返回类型进行区分?
原文链接:https://www.cnblogs.com/jiangyi-uestc/p/5743636.html
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
8.Java中会存在内存泄露吗,请简单描述。
原文链接:https://www.cnblogs.com/zhangkai0106/p/5011086.html
理论上Java因为有垃圾回收机制(GC)不会存在内存泄露问题(这也是Java被广泛使用于服务器端编程的一个重要原因);然而在实际开发中,可能会存在无用但可达的对象,这些对象不能被GC回收,因此也会导致内存泄露的发生。例如Hibernate的Session(一级缓存)中的对象属于持久态,垃圾回收器是不会回收这些对象的,然而这些对象中可能存在无用的垃圾对象,如果不及时关闭(close)或清空(flush)一级缓存就可能导致内存泄露。下面例子中的代码也会导致内存泄露。 import java.util.Arrays; import java.util.EmptyStackException; public class MyStack<T> { private T[] elements; private int size = 0; private static final int INIT_CAPACITY = 16; public MyStack() { elements = (T[]) new Object[INIT_CAPACITY]; } public void push(T elem) { ensureCapacity(); elements[size++] = elem; } public T pop() { if(size == 0) throw new EmptyStackException(); return elements[--size]; } private void ensureCapacity() { if(elements.length == size) { elements = Arrays.copyOf(elements, 2 * size + 1); } } } 上面的代码实现了一个栈(先进后出(FILO))结构,乍看之下似乎没有什么明显的问题,它甚至可以通过你编写的各种单元测试。然而其中的pop方法却存在内存泄露的问题,当我们用pop方法弹出栈中的对象时,该对象不会被当作垃圾回收,即使使用栈的程序不再引用这些对象,因为栈内部维护着对这些对象的过期引用(obsolete reference)。在支持垃圾回收的语言中,内存泄露是很隐蔽的,这种内存泄露其实就是无意识的对象保持。如果一个对象引用被无意识的保留起来了,那么垃圾回收器不会处理这个对象,也不会处理该对象引用的其他对象,即使这样的对象只有少数几个,也可能会导致很多的对象被排除在垃圾回收之外,从而对性能造成重大影响,极端情况下会引发Disk Paging(物理内存与硬盘的虚拟内存交换数据),甚至造成OutOfMemoryError。
9.阐述静态变量和实例变量的区别。
原文链接:http://blog.csdn.net/liangzhongqin/article/details/6401611
ava类的成员变量有俩种: 一种是被static关键字修饰的变量,叫类变量或者静态变量 另一种没有static修饰,为实例变量 类的静态变量在内存中只有一个,java虚拟机在加载类的过程中为静态变量分配内存,静态变量位于方法区,被类的所有实例共享。静态变量可以直接通过类名进行访问,其生命周期取决于类的生命周期。 而实例变量取决于类的实例。每创建一个实例,java虚拟机就会为实例变量分配一次内存,实例变量位于堆区中,其生命周期取决于实例的生命周期。 public class Temp { int t; //实例变量 public static void main(String args[]){ int t=1; //局部变量 System.out.println(t ); //打印局部变量 Temp a= new Temp(); //创建实例 System.out.println(a.t ); //通过实例访问实例变量 } } 结果为: 1 0 (成员变量具有缺省值 而局部变量则没有 ) 把代码改为 public class Temp { static int t; //类变量 public static void main(String args[]){ System.out.println(t ); //打印类变量 int t=1; //局部变量 System.out.println(t ); //打印局部变量 Temp a= new Temp(); //创建实例 System.out.println(a.t ); //通过实例访问实例变量 } } 结果则为 0 1 0
10.阐述JDBC操作数据库的步骤。
原文链接:http://blog.csdn.net/Hpu_A/article/details/51354867
JDBC操作数据库的基本步骤: 1)加载(注册)数据库驱动(到JVM)。 2)建立(获取)数据库连接。 3)创建(获取)数据库操作对象。 4)定义操作的SQL语句。 5)执行数据库操作。 6)获取并操作结果集。 7)关闭对象,回收数据库资源(关闭结果集-->关闭数据库操作对象-->关闭连接)。 [java] view plain copy package com.yangshengjie.jdbc; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class JDBCTest { /** * 使用JDBC连接并操作mysql数据库 */ public static void main(String[] args) { // 数据库驱动类名的字符串 String driver = "com.mysql.jdbc.Driver"; // 数据库连接串 String url = "jdbc:mysql://127.0.0.1:3306/jdbctest"; // 用户名 String username = "root"; // 密码 String password = "mysqladmin"; Connection conn = null; Statement stmt = null; ResultSet rs = null; try { // 1、加载数据库驱动( 成功加载后,会将Driver类的实例注册到DriverManager类中) Class.forName(driver ); // 2、获取数据库连接 conn = DriverManager.getConnection(url, username, password); // 3、获取数据库操作对象 stmt = conn.createStatement(); // 4、定义操作的SQL语句 String sql = "select * from user where id = 100"; // 5、执行数据库操作 rs = stmt.executeQuery(sql); // 6、获取并操作结果集 while (rs.next()) { System.out.println(rs.getInt("id")); System.out.println(rs.getString("name")); } } catch (Exception e) { e.printStackTrace(); } finally { // 7、关闭对象,回收数据库资源 if (rs != null) { //关闭结果集对象 try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if (stmt != null) { // 关闭数据库操作对象 try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if (conn != null) { // 关闭数据库连接对象 try { if (!conn.isClosed()) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } } } }
11.MyBatis中使用#和$书写占位符有什么区别?
原文链接:http://blog.csdn.net/qq_31094101/article/details/72794298
#{}占位符:占位 如果传入的是基本类型,那么#{}中的变量名称可以随意写 如果传入的参数是pojo类型,那么#{}中的变量名称必须是pojo中的属性.属性.属性… ${}拼接符:字符串原样拼接 如果传入的是基本类型,那么${}中的变量名必须是value 如果传入的参数是pojo类型,那么${}中的变量名称必须是pojo中的属性.属性.属性… 注意:使用拼接符有可能造成sql注入 <!-- id:sql语句唯一标识 parameterType:指定传入参数类型 resultType:返回结果集类型 #{}占位符:起到占位作用,如果传入的是基本类型(string,long,double,int,boolean,float等),那么#{}中的变量名称可以随意写. #{}:如果传入的是pojo类型,那么#{}中的变量名称必须是pojo中对应的属性.属性.属性..... --> <select id="findUserById" parameterType="int" resultType="cn.itheima.pojo.User"> select * from user where id=#{id} </select> <!-- ${}拼接符:字符串原样拼接,如果传入的参数是基本类型(string,long,double,int,boolean,float等),那么${}中的变量名称必须是value ${}:如果传入的参数是pojo类型,那么`${}`中的变量名称必须是pojo中的属性.属性.属性... 注意:拼接符有sql注入的风险,所以慎重使用 --> <select id="findUserByUserName" parameterType="string" resultType="user"> select * from user where username like '%${value}%' </select>
12.简述一下你了解的设计模式。(3种)
创建型模式设计对象的实例化,这类模式的特点是,不让用户依赖于对象的创建或排列方式,避免用户直接使用new运算符创建对象。 GOF的23中模式中的下列5种模式属于创建型模式: (1)工厂方法模式:定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method使一个类的实例化延迟到其子类。 (2)抽象工厂模式:提供一个创建一系列或相互依赖对象的接口,而无须指定它们具体的类。 (3)生成器模式:将一个复杂对象的创建与它的表示分离,使得同样的创建过程可以创建不同的表示。 (4)原型模式:将原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。 (5)单件模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 行为模式涉及怎样合理地设计对象之间的交互通信,以及怎样合理为对象分配职责,让设计富有弹性,易维护和易复用。 GOF的23种模式中的下列11种模式属于创建型模式: (1)责任链模式:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。 (2)命令模式:将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。 (3)解释器模式:给定一个语言,定义它文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。 (4)迭代器模式:提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。 (5)中介者模式:用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显示地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。 (6)备忘录模式:在不破坏封装性的情况下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可将该对象恢复到原先保存的状态。 (7)观察者模式:定义对象间的一种一对多的依赖关系,当一个对象的状态发生变化时,所有依赖于它的对象都得到通知并被自动更新。 (8)状态模式:允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。 (9)策略模式:定义一系列算法,把它们一个个封装起来,并且可使它们可以相互替换。策略模式使算法可独立于使用它的客户而变化。 (10)模板方法模式:定义一个操作中算法的骨架,而将一些步骤延迟到子类中。模板方法使子类可以不改变一个算法的结构即可定义该算法的某些特定步骤。 (11)访问者模式:表示一个作用于某对象结构中的各个元素的操作。它可以在不改变各个元素的类的前提下定义作用于这些元素的新操作。 结构型模式涉及如何组合类和对象以形成更大的结构,和类有关的结构型模式设计如何合理地使用继承机制;和对象有关的结构型模式涉及如何合理地使用对象组合机制。 GOF的23种模式中的下列7种模式属于创建型模式: (1)适配器模式:将一个类的接口转换成客户希望的另外一个接口。Adapter模式使原本由于接口不兼容而不能一起工作的那些类可以一起工作。 (2)组合模式:将对象组合成数形结构以表示”部分-整体“的层次结构。Composite使用户对单个对象和组合对象的使用具有一致性。 (3)代理模式:为其他对象提供一种代理以控制对这个对象的访问。 (4)享元模式:运用共享技术有效地支持大量细粒度的对象。 (5)外观模式:为系统的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使这一子系统更加容易使用。 (6)桥接模式:将抽象部分与它的实现部分分离,使它们都可以独立地变化。 (7)装饰模式:动态地给对象添加一些额外的职责,就功能来说装饰模式相比生成子类更为灵活。
13.什么是IoC和DI?DI是如何实现的?
原文链接:https://www.cnblogs.com/guxia/p/6842647.html
IoC叫控制反转,是Inversion of Control的缩写,控制反转是把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的"控制反转"就是对组件对象控制权的转移,从程序代码本身转移到了外部容器,由容器来创建对象并管理对象之间的依赖关系。
控制反转——Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象,是容器在对象初始化时不等对象请求就主动将依赖传递给它。通过IOC反转控制DI依赖注入完成各个层之间的注入,使得层与层之间实现完全脱耦,增加运行效率利于维护。
14.Spring中Bean的作用域有哪些?阐述Spring框架中Bean的生命周期?
原文链接:https://www.cnblogs.com/zhanglei93/p/6231882.html
- Bean的作用域
Spring 3中为Bean定义了5中作用域,分别为singleton(单例)、prototype(原型)、request、session和global session,5种作用域说明如下:
- singleton:单例模式,Spring IoC容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,始终指向同一对象。Singleton作用域是Spring中的缺省作用域,也可以显示的将Bean定义为singleton模式,配置为:prototype:原型模式,每次通过Spring容器获取prototype定义的bean时,容器都将创建一个新的Bean实例,每个Bean实例都有自己的属性和状态,而singleton全局只有一个对象。根据经验,对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
- <bean id="userDao" class="com.ioc.UserDaoImpl" scope="singleton"/>
- request:在一次Http请求中,容器会返回该Bean的同一实例。而对不同的Http请求则会产生新的Bean,而且该bean仅在当前Http Request内有效。
- <bean id="loginAction" class="com.cnblogs.Login" scope="request"/>,针对每一次Http请求,Spring容器根据该bean的定义创建一个全新的实例,且该实例仅在当前Http请求内有效,而其它请求无法看到当前请求中状态的变化,当当前Http请求结束,该bean实例也将会被销毁。
- session:在一次Http Session中,容器会返回该Bean的同一实例。而对不同的Session请求则会创建新的实例,该bean实例仅在当前Session内有效。global Session:在一个全局的Http Session中,容器会返回该Bean的同一个实例,仅在使用portlet context时有效。
- <bean id="userPreference" class="com.ioc.UserPreference" scope="session"/>,同Http请求相同,每一次session请求创建新的实例,而不同的实例之间不共享属性,且实例仅在自己的session请求内有效,请求结束,则实例将被销毁。
- Bean的生命周期
经过如上对Bean作用域的介绍,接下来将在Bean作用域的基础上讲解Bean的生命周期。
Spring容器可以管理singleton作用域下Bean的生命周期,在此作用域下,Spring能够精确地知道Bean何时被创建,何时初始化完成,以及何时被销毁。而对于prototype作用域的Bean,Spring只负责创建,当容器创建了Bean的实例后,Bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的Bean的生命周期。Spring中Bean的生命周期的执行是一个很复杂的过程,读者可以利用Spring提供的方法来定制Bean的创建过程。Spring容器在保证一个bean实例能够使用之前会做很多工作:
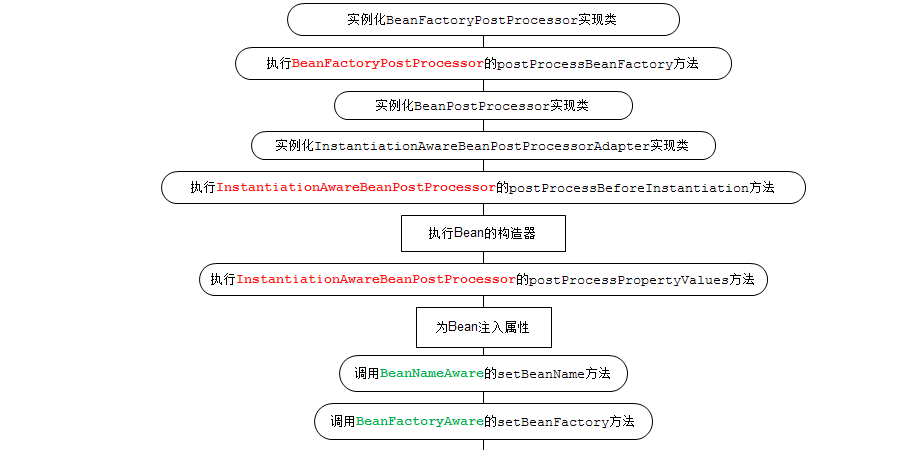

15.用Java写一个冒泡排序。
package com.liuzhen.chapterThree; public class BubbleSort { public static void getBubbleSort(int[] a){ int temp; //打印输出未排序前数组序列 System.out.print("排序前: "); for(int p = 0;p < a.length;p++) System.out.print(a[p]+"\t"); System.out.println(); for(int i = 0;i < a.length-1;i++){ for(int j = 0;j < a.length-1-i;j++){ if(a[j+1] < a[j]){ //交换a[j]和a[j+1]的值 temp = a[j]; a[j] = a[j+1]; a[j+1] = temp; } } //打印输出每一次选择排序结果 System.out.print("排序第"+(i+1)+"趟:"); for(int p = 0;p < a.length;p++) System.out.print(a[p]+"\t"); System.out.println(); } } public static void main(String args[]){ int[] a = {89,45,68,90,29,34,17}; getBubbleSort(a); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号