关于预训练和表示学习的部分文章简读
目录
1 Mask R-CNN (ICCV2017, 本文旨在学习写作和创新点的定位思考)
2 Masked Autoencoders Are Scalable Vision Learners (arXiv2021)
3 SimMIM: A Simple Framework for Masked Image Modeling (arXiv 2021)
4 Masked Feature Prediction for Self-Supervised Visual Pre-Training (arXiv 2021)
5 TS2Vec: Towards Universal Representation of Time Series (AAAI 2022)
6 Generative Semi-supervised Learning for Multivariate Time Series Imputation (AAAI 2021)
本文主要讲述六篇文章,前两篇是出自大神何凯明之手,第一篇做图像分割,第二篇做图像的预训练。接着讲两篇图像的掩码预测训练文章;最后两篇是关于时序的文章,其中一篇是做预训练,另一篇做缺失填补。
1 Mask R-CNN (ICCV2017, 本文旨在学习写作和创新点的定位思考)
动机
实例分割需要正确地检测出图像中的所有对象,并且同时要精确地分割每个实例,是一个充满挑战的问题。实例分割一般可以分为两个阶段:目标检测和目标分类。
贡献
本文提出的方法Mask-R-CNN能够有效地检测图像中的对象,同时为每个实例生成一个高质量的分割掩码,即再在每个实例目标中,在像素层面上,来区分哪些像素点是目标位置区域,哪些像素点是背景,相当于一个二分类问题(像素级目标分割)。
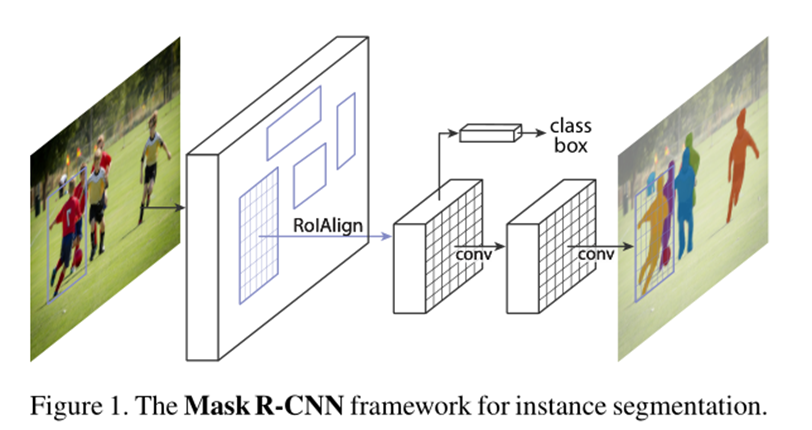
本文模型的学习目标也是一个多任务学习:
具体的细节阐述可以参考以下文章的讲解:
[1] https://blog.csdn.net/jiongnima/article/details/79094159
[2] https://zhuanlan.zhihu.com/p/57759536
实验分析
我的想法
本文将实例分割中的像素点识别定义为一个二分类的掩码任务,这个预训练任务中的掩码预测在概念上有些类似,但是这种掩码二分类任务的创新简单的同时也是觉得脑洞很开阔。
2 Masked Autoencoders Are Scalable Vision Learners (arXiv2021)
动机
深度学习见证了容量和能力不断增长的架构爆发式发展,然而已有的模型很容易对百万级别的图像数据过拟合或者缺乏有效的标注数据。与此同时,在自然语言处理领域的无监督预训练学习模型取得了重大的成功,比如自回归语言建模GPT以及掩码自编码器的BERT模型。已有研究表明,掩码自回归架构在计算视觉领域也可以很自然地被应用。
贡献
本文解决一个疑问:究竟是什么使得masked autoencoding在视觉和语言数据处理方面不同?
1)两者的基本架构有很大的差异,即模型代沟。在视觉领域,卷积神经网络模型一直占据主导地位,卷积模块通过在固定的网格空间进行操作,而不会直接结合mask tokens或者位置编码等指示器到卷积网络。然而,最近提出的Vision Transormer解决了这一模型代沟问题,打通了视觉和语言数据的基础架构。
2)视觉和语言视觉的信息稠密度不同。由人类生成的语言信号一般具有很高的语义和信息稠密度,当采用模型进行缺失单词预测时,能够引起老练的语言理解。与此相反,视觉图像数据拥有很多空间冗余,一个缺失的patch很难获取其邻近的高水平物体或者目标的语义信息。针对上述问题,本文提出了一种mask random patches策略,能够有效地减少冗余信息,并提高在图像领域的无监督学习效果。
3)自动编码器的解码器在视觉和语言数据方面扮演的角色不同。在视觉领域,解码器需要将潜在表示解码到低语义信息的像素级输出。然而,在语言方面,解码器则扮演了预测缺失的单词,拥有较高的语义信息。因此,对于视觉领域的数据,如何设计一个decoder将很大程度上决定了学习的潜在表示的语义水平。
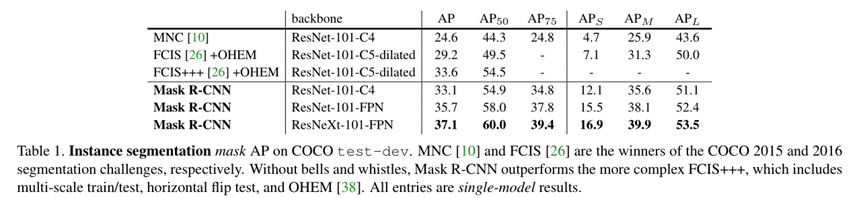
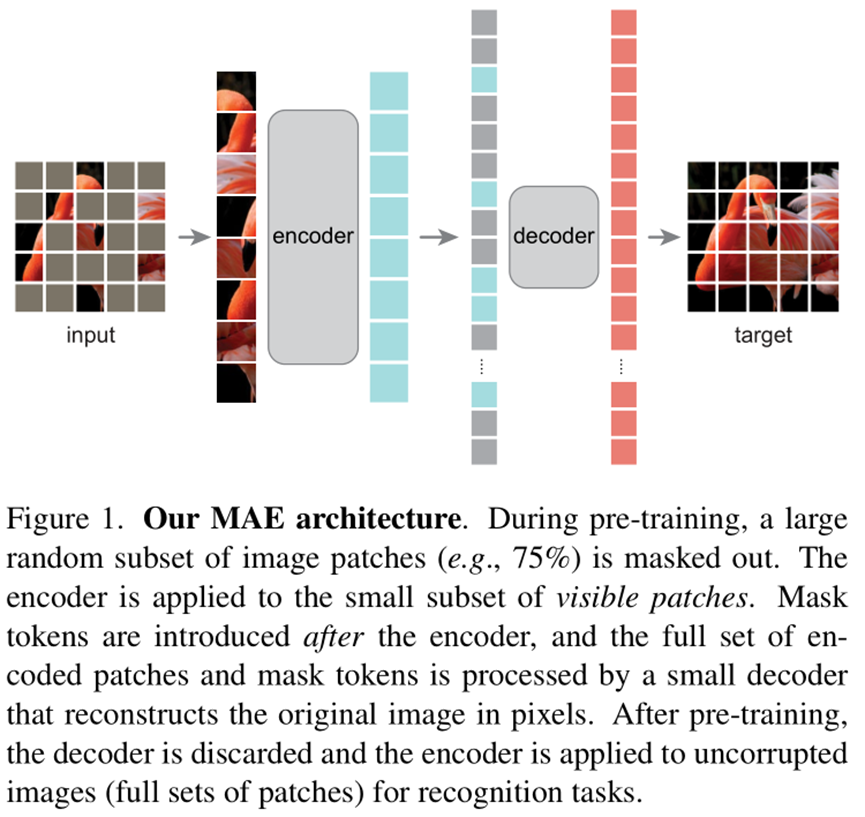
依据上述分析,本文提出了一种简单高效可拓展的masked autoencoder(MAE)模型,用于视觉领域的表示学习。MAE模型随机掩码大部分的patches,并且拥有非对称的编码-解码结构设定。其中编码器只处理没有被掩码的可观察部分数据,而解码器则把编码器学习的表示和掩码位置的数据进行像素级的重构。实验表明,当掩码率在75%时,对下游任务有高效的性能提升。具体模型示意图如下:
实验分析
在patches缺失率达到80%情形下,即重构的数据能够有效地恢复原始图的语义信息。
然而,当patches缺失率达到了85%或者95%时,重构得到的图像分布信息和原始图有较大的区别,但是也说明了模型有较强的泛化能力。
此外,本文分析不同缺失率对有监督微调和线性探测下游任务性能的影响,具体如下:
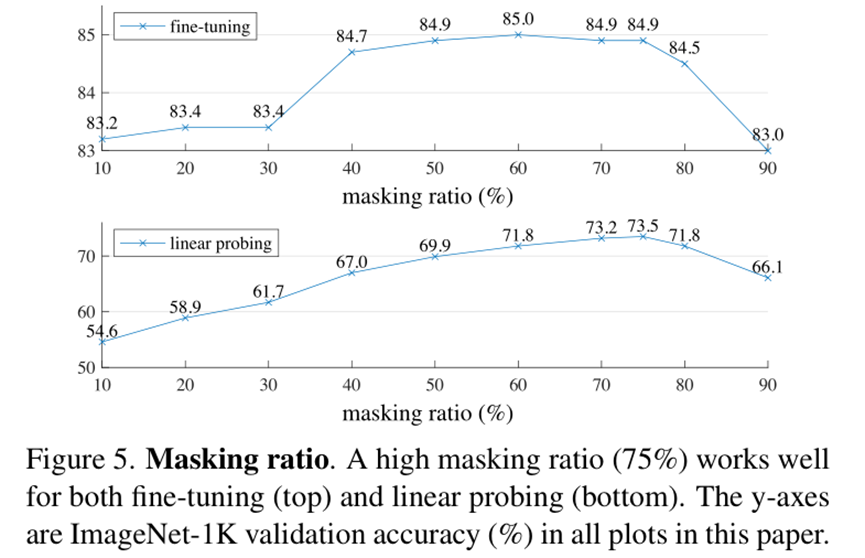
我的想法
本文的想法很简洁,其最大的亮点在于其对decoder的设计,使得encoder最终学习的潜在表示更加有利于下游任务建模。该模块设计的核心在于能够有效捕捉视觉数据的高效语义信息,借助这一点启发,是否可以采用类似的架构设计一种符合时间序列数据场景的masked time-series的decoder呢?
3 SimMIM: A Simple Framework for Masked Image Modeling (arXiv 2021)
动机
在NLP领域,掩码再预测的任务学习在无监督预训练方面取得很大的成功。在计算机视觉领域,虽然当前已有掩码预测用于预训练,但是已有的研究几乎是被对比学习机制占据主导。对比学习和掩码预测两种路线有较大不同,此外掩码预测在NLP和视觉领域,由于原始数据的特性差异,两者学习机制也存在较大不同,具体可以归纳如下:
1) 图像具有更强的局部性:相邻的像素往往具有高度相关的,因此可以通过复制接近的像素来很好地完成任务,而不是通过语义推理。
2) 视觉信号是原始的、低级的,而文本标记是由人类生成的高级概念。这就提出了一个问题,即对低水平信号的预测是否对高级视觉识别任务有用。
3) 视觉信号是连续的,文本标记是离散的。如何采用基于分类的掩蔽语言建模方法来处理连续的视觉信号是一个未知的问题。
贡献
本文提出了一种简单的masked图像建模方法,能够在视觉领域数据集上学习到有利于下游任务建模的表示。具体发现有三点:
1)采用随机mask机制,并结合大小为32的patch能够达到很强的预训练效果
2)直接对原始的RGB级的像素值进行回归预测,而不需要设计复杂的patch分类模块
3)预测head采用很轻量级的线性层,并且相比heavier的设计,其下游任务性能并不会变差
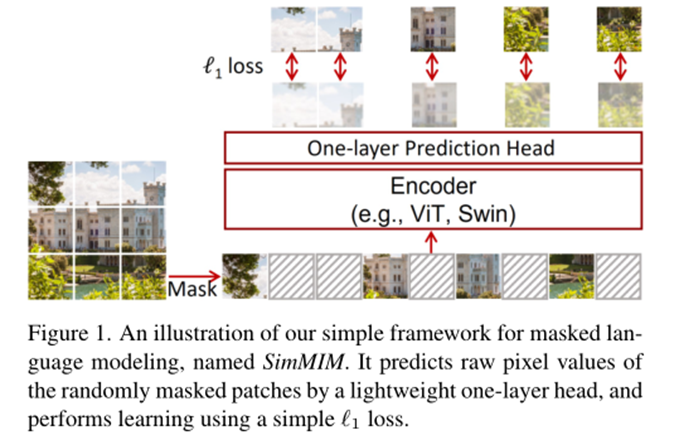
在掩码机制方面,本文讨论分析了Square, Block-wise, Random三种方式对下游任务性能的影响。
在Encoder方面,本文采用了vanilla ViT和Swin Transformer进行了实验分析。
在Prediction head方面,本文采用了一种线性层,并和两层的MLP等复杂的head作了比较分析。
在学习目标方面,本文采用了像素重构的l1-loss,具体表示如下:

实验分析
作者在引言中表明虽然我们提倡将图像补绘作为一种强自我监督前文本任务,但我们也发现,较强的补绘能力并不一定会导致较强的下游任务的微调性能。
在对比学习方法中,头部设计是一项重要的探索,但对于掩蔽图像建模而言,这可能是不必要的。
另外,本文对三种不同mask机制,以及不同的缺失率大小对下游任务性能进行分析比较,实验结果表明采用random的50%掩码,patch size设定为32时,下游任务性能表现最好。
在表4中,我们已经展示了通过掩蔽预测任务(我们的方法)和联合掩蔽预测和可见信号重构任务学习的表示的比较,这表明纯掩蔽预测任务的性能明显更好。如下:

图5比较了两种方法的恢复效果。这表明后一种方法看起来更好,但是,可能在恢复未隐藏区域时浪费了模型容量,这对微调可能没有那么有用。

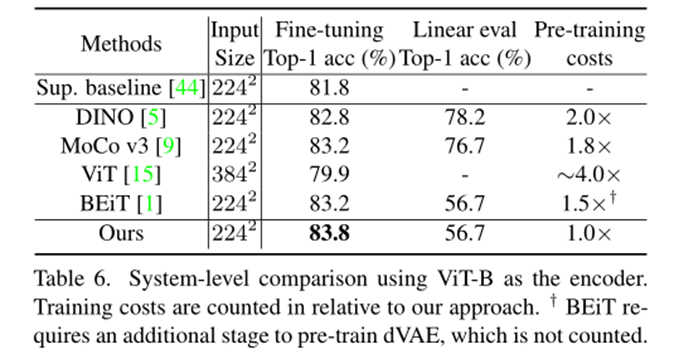
与已有的strong baseline的性能对比分析:
我的想法
本文的实验表明,在图像修复任务上表现好,但是不一定有利于微调的下游任务性能。此外,在mask的patch选取的size大小方面,size越小,修复效果越好,但是下游学习的表示迁移效果缺变差,这也进一步说明了缺失位置修复的好,并不一定有利于下游任务性能。另外,本文对自动编码器在mask像素级别的实验做的很详细,包括mask的缺失率大小,patch的size大小,分类器的设计以及相关超参数设定等,这样的实验设定和对比分析值得学习和借鉴。
4 Masked Feature Prediction for Self-Supervised Visual Pre-Training (arXiv 2021)
代码:暂无
动机
基于掩码和预测思想的Transformer架构,在自然语言处理领域的无监督预训练方面取得了很大成功。人类拥有看到局部信息能够推测物体整体轮廓的能力,基于这一思想可以利用掩码的思路用于无监督视觉预训练。
视觉和语言之间的一个本质区别是,视觉没有预先存在的词汇表来将预测任务塑造成一个定义良好的分类问题。相比之下,原始时空视觉信号的连续性和密集性对掩蔽视觉预测提出了重大挑战。一个直接的解决方案是通过构建视觉词汇表来模仿语言词汇表,该词汇表将框架块离散为标记。然而,这需要一个外部的分词器,这在计算密集的视频理解场景中是有限的。
贡献
本文提出了一种掩码特征预测(MaskFeat)无监督预训练模型。该模型采用vision Transformer来预测被掩蔽的特征,通过这种方式,预先训练的模型获得了对密集视觉信号中复杂时空结构信息的充分理解。
我们研究了广泛的特征类型,从像素颜色和手工制作的特征描述符,到离散的视觉token,激活的深度网络,以及来自网络预测的伪标签。具体贡献如下:
1) 简单的定向梯度直方图(图1中中间一列)是MaskFeat在性能和效率方面的一个特别有效的目标。
2) 掩蔽视觉预测并不需要视觉信号离散化(标记化),连续特征回归的信号(即MaskFeat)可以很好地工作。
3) 人类注释的语义知识并不总是对MaskFeat有帮助,但描述局部模式似乎很重要。例如,从经过标记数据训练的cnn或vit预测监督特征会导致性能下降。
我们的方法在概念上和实践上都很简单。相比之下,对比方法需要一个连体结构和两个或多个视图的每个训练样本(例如,[17,34,44]),MaskFeat使用单个网络和每个样本的单个视图;与强烈依赖于精心设计的数据增强的对比方法不同,MaskFeat在最小的增强下工作得相当好。
本文的核心则是让Decoder去预测HOG特征。
MaskFeat模型:

上述模型将masked的原图输入到encoder后进行linear预测maked原图的HOG,并最小化缺失部分的预测HOG和真实原图的HOG特征分布差异。
实验分析

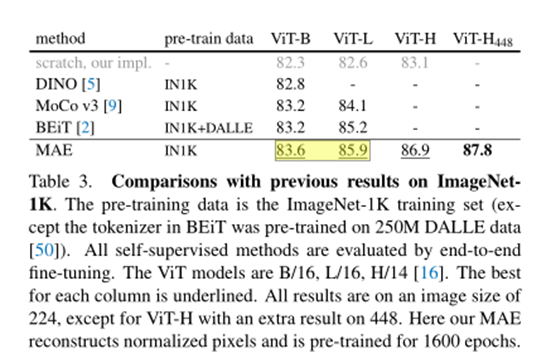
我的想法
本文采用的HOG给视觉无监督预训练带来了很大的性能提升,这让现有深度学习模型需要开始重视手工提取特征在深度网络学习(生成式模型)中的作用。另外,在时间序列数据方面,是否可以找到有利于下游任务的手工提取特征进行目标学习还值得进一步调研和思考。
MAE是预测归一化后的图像像素原始,本文是预测经过手工提取的HOG特征,BERT是预测maked词,那么在时间序列数据领域,可以考虑选取某一个序列片段?
5 TS2Vec: Towards Universal Representation of Time Series (AAAI 2022)
动机
学习时间序列的普遍表示是一个基本而又具有挑战性的问题。已有研究专注于学习实例级(instance-level)表示,它描述了输入时间序列的整个片段,在聚类和分类等任务中取得了巨大的成功。此外,最近的工作采用对比损失来学习时间序列的内在结构。然而,现有的方法仍有明显的局限性,具体如下:
1) 实例级表示可能不适合需要细粒度表示的任务,例如时间序列预测和异常检测。
2) 现有的方法很少区分不同粒度的多尺度语境信息。
3) 现有的时间序列表示方法大多受到CV和NLP领域经验的启发,具有很强的归纳偏差,如变换不变性和分割不变性。
贡献
本文提出了一种用于学习时间序列在任意语义层次表示的通用框架TS2Vec。与现有的方法不同,TS2Vec在增强的上下文视图上以分层的方式执行对比学习,从而为每个时间戳提供健壮的上下文表示。此外,为了得到时间序列中任意子序列的表示,我们可以对相应时间戳的表示进行简单的聚合。
本文在时序分类、异常检测和预测任务上均达到了SOTA效果,并且时间消耗较低。
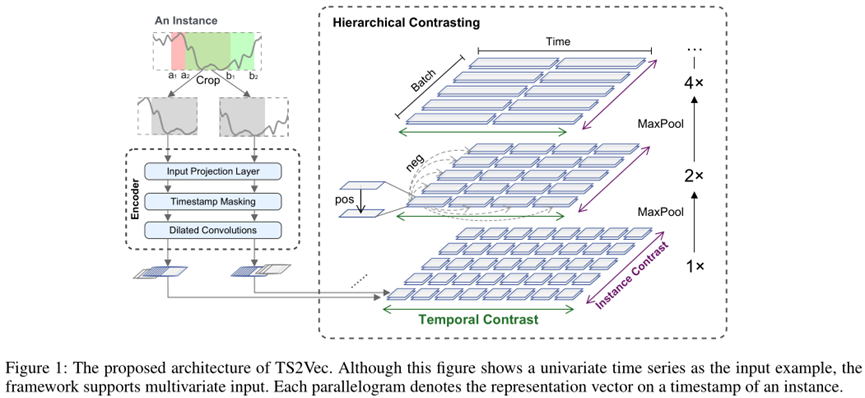
本文的对比学习方式:
1) 实例级别层次,instance-wise
2) 时序维度层次,temporal dimension
通过上述两者的协作,可以使得TS2Vec能够学习到任意粒度的时序表示信息。具体的模型结构如下图所示:
实验分析
本文方法在分类任务上准确率和训练耗时:

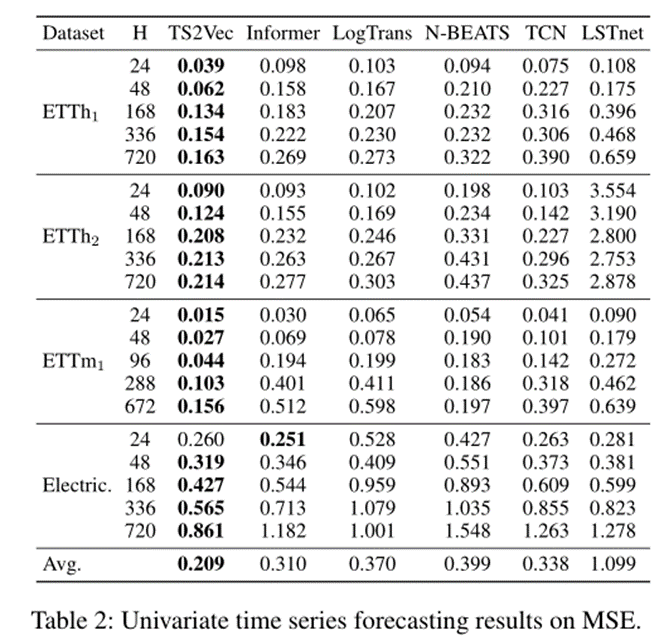
在预测任务上的MSE结果:
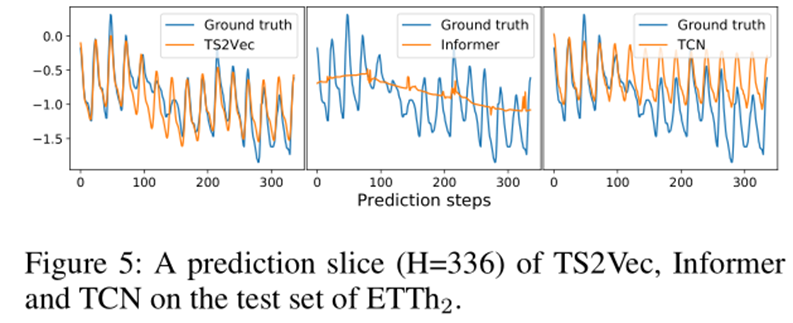
此外,可视化实验表明,Informer在细粒度的短期预测上表现不好:
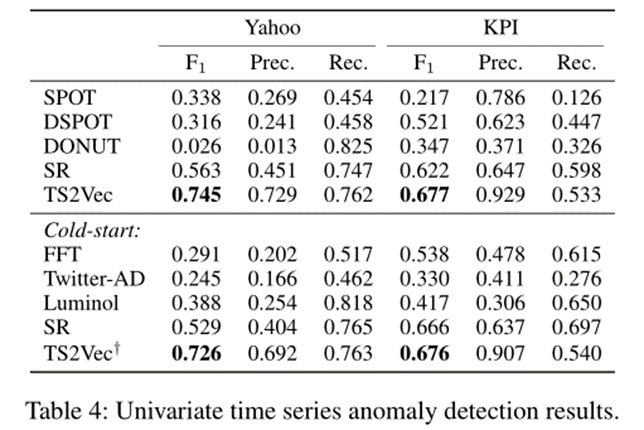
在异常检测任务上的表现:
消融实验结果表明,Transformer基本架构能够有效提高下游任务准确率。此外,相比Mask策略,random cropping策略能够有效提高下游任务准确率。与此同时,子序列的一致性比时序一致性在下游任务提升性能方面更佳。
我的想法
本文有效地利用了IJCAI2021 (Time-Series Representation Learning via Temporal and Contextual Contrasting)的双向增强对比学习思想,并在本文进行了扩展,在概念解释时,将不同视角的对比学习定义为层次的概念。另外,本文最大的亮点在于其做的实验和任务非常充分,基本囊括了时序领域任务常用的基准数据集,本文的对比学习策略可以考虑作为相关任务的预训练应用。
6 Generative Semi-supervised Learning for Multivariate Time Series Imputation (AAAI 2021)
动机
多元时间序列数据中普遍存在缺失值,影响了数据的有效分析。现有的时间序列归并方法没有充分利用现实生活中时间序列数据中的标签信息。
例如,PhysioBank存档(Goldberger et al. 2000)包含超过40g字节的心电图医学时间序列数据,其中有一些缺失的值和一小部分标注标签。由于法律上的原因,医院通常会将更多没有标签的心电图数据存档。
贡献
本文提出了一种新的半监督生成对抗网络模型,命名为SSGAN,用于多变量时间序列数据的缺失值输入。它由三个参与者组成,即一个生成者、一个鉴别者和一个分类者。分类器预测时间序列数据的标签,因此它驱动生成器估计缺失的值(或组件),条件是同时观察到的组件和数据标签。
我们引入时间提醒矩阵来帮助鉴别器更好地区分观测分量和输入分量。此外,我们从理论上证明,当达到纳什均衡时,SSGAN利用时间提醒矩阵和分类器确实学会了估计收敛于真实数据分布的缺失值。
在三个公开的真实数据集上进行的大量实验表明,与最先进的方法相比,SSGAN在性能上获得了超过15%的增益。
我的想法
本文的实验结果表明采用半监督或者监督学习,能够有效提高填补任务的效果。本文有开源代码,到时有时间可以看看复现效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号